
机器学习(ML)被称为技术债务的高利率信用卡。对于特定的业务问题,使用适用的模型会相对容易一些,但是要使该模型在可伸缩的生产环境中运行,并能够处理不断变化的混乱数据语义和关系,以及以可靠的自动化方式演进模式,则完全是另一回事。
对于机器学习生产系统而言,只有5%的实际代码是模型本身。将一组机器学习解决方案转变为端到端的机器学习平台的,是一种运用了加速建模、自动化部署和确保生产中的可伸缩性和可靠性的技术的架构。
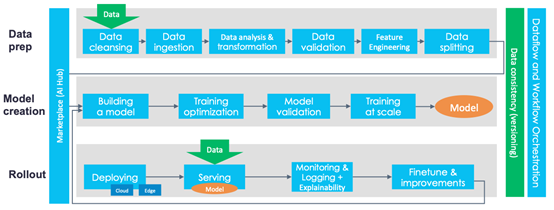
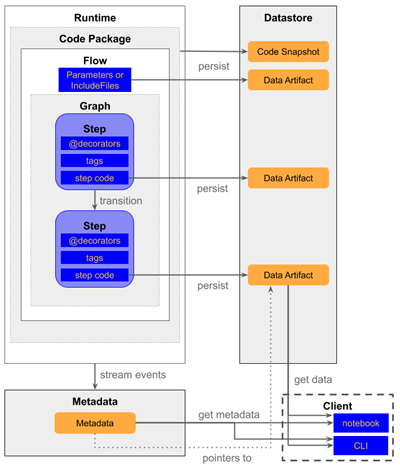
笔者此前讲过lean D/MLOps,数据和机器学习操作,因为没有数据的机器学习操作是没有意义的,所以端到端机器学习平台需要进行整体构建。CI/CD基金会启动了一个MLOps特别兴趣小组(SIG)。其端到端机器学习平台确定的步骤如下图所示:
不过,其中掩盖了一些不太重要的细节。例如,服务可能需要不同的技术取决于它是否是实时完成的。可伸缩的解决方案通常将模型放在一个负载均衡器后的服务集群的多个机器上的容器内运行。因此,上述图表中的单个框并不意味着实际平台的单个步骤、容器或组件。
这并不是对图中步骤进行批评,而是一个警示:看似简单的事情在实践中可能并不那么容易。
图表中没有模型(配置)管理。可以考虑诸如版本控制、实验管理、运行时统计、用于培训、测试和验证数据集的数据沿袭跟踪,从头开始或从模型快照、超参数值、精度度量等等对模型进行再培训的能力。
此外,图中缺失的另一个关键点是检查模型偏差的能力,例如,根据不同的维度来分割模型的关键性能指标。许多公司也需要能够热交换一个模型或并行运行多个模型。前者至关重要,可以避免模型在后台更新时,用户的请求进入服务器时失败。而后者对于A/B测试或模型验证也举足轻重。
从CI/CD中我们可以得出另一个观点,它提到了版本化数据和代码的需要,这一点经常被忽略。
谷歌:TFX
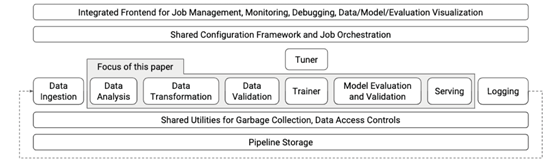
谷歌开发TensorFlow eXtended(TFX)的主要动机是将机器学习模型的生产时间从数月缩短到几周。谷歌工程师和科学家为此焦头烂额,因为“当机器学习需要应用于生产时,实际的工作流程将变得更加复杂。”
TensorFlow和TFX均可免费使用,不过后者在2019年才发布,比谷歌提供的ML基础设施晚了两年,远不如前者成熟。
模型性能度量用于部署安全服务模型。因此,如果新模型的性能不如现有模型,它就无法投入生产。按照TFX的说法,该模型并非幸运儿。有了TFX,整个过程都是自动化的。
以下是一个开源TFX组件的基本概述:
- ExampleGen提取并分割输入数据集。
- StatisticsGen为数据集计算统计数据。
- SchemaGen检查统计数据并创建数据模式。
- ExampleValidator在数据集中查找异常值和缺失值。
- Transform对数据集执行特征工程。
- Trainer使用TensorFlow对模型进行训练。
- Evaluator分析训练结果。
- ModelValidator确保模型的高安全性。
- Pusher将模型部署到服务基础设施中。
TensorFlow服务是一个c++后端,服务于TensorFlow SavedModel文件。为了最小化训练/服务偏差,TensorFlow转换会“冻结”计算图中的值,这样在训练中发现的相同值会在服务中使用。当训练在运行时间是单一的固定值时,DAG可能会有若干个操作。
图源:unsplash
Uber: Michelangelo
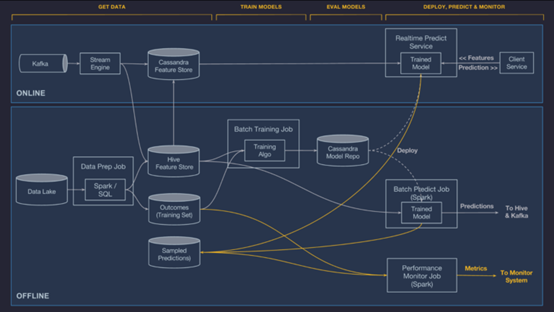
大约在2015年,Uber的ML工程师注意到机器学习系统中隐藏的技术债务。Uber已经建立了一个一次性的自定义系统,与ML模型集成在一起,这在大型工程组织中不是很容易扩展。用他们自己的话来说,没有合适的系统来建立可靠、统一和可重复的管道以创建和管理大规模的训练和预测数据。
这就是他们创造Michelangelo的原因。它依赖于Uber的数据湖——事务性和日志数据,支持离线(批处理)和在线(流)预测。对于脱机预测,包含的Spark作业生成批预测,而对于在线部署,模型在预测服务集群中提供服务,该集群通常由负载均衡器后面的数百台机器组成,客户机将单个或批预测请求作为rpc发送到该集群。
为每个实验存储与模型管理相关的元数据,例如,训练师的运行时统计信息、模型配置、沿袭、分布和特性的相对重要性、模型评估指标、标准评估图表、学习的参数值和汇总统计信息等。
Michelangelo可以在同一个服务容器中部署多个模型,这允许从旧模型版本到新模型版本的安全转换,以及对模型的并行A/B测试。
Michelangelo的最初版本并不支持深度学习在GPU上进行训练,但其开发团队解决了这一遗漏问题。当前平台使用了Spark的ML管道序列化,但是有一个用于在线服务的附加接口,该接口添加了一个单例(在线)评分方法,可以既轻量级又能够处理紧密型SLA,例如用于欺诈检测和预防。它通过绕过Spark SQL的Catalyst优化器的开销来实现这一点。
值得注意的是,谷歌和Uber都为服务构建了内部协议缓冲区解析器和表示物,避免了默认实现中存在的瓶颈。
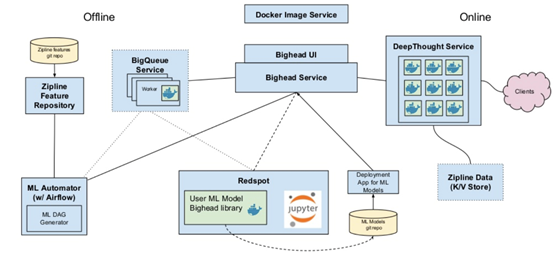
Airbnb: Bighead
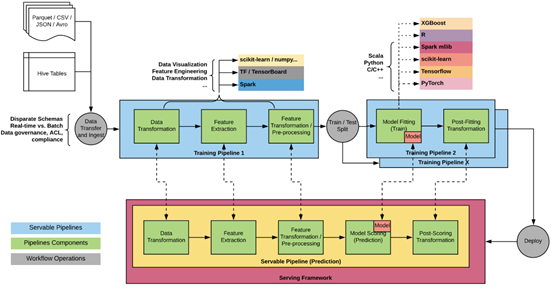
基于类似原因,Airbnb在2016/2017年建立了自己的ML基础架构团队。首先,尽管他们只有几款模型正在构建中,但每一款模型的构建都可能需要长达三个月的时间。第二,模型之间不存在一致性。第三,线上和线下的预测差异极大。Bighead是其努力的顶峰:
数据管理由内部工具Zipline处理。Redspot是一个托管的、集装的、多用户的Jupyter Notebook服务。Bighead库用于数据转换和管道提取,为通用模型框架提供了包装器。其通过转换保存元数据,因此可用于跟踪沿袭。
Deep Thought是一个用于在线预测的REST API。Kubernetes对服务进行精心优化。对于离线预测,Airbnb则使用他们自己的自动装置。
Netflix也面临着与上述公司类似的问题。他们的解决方案是运用Metaflow,这是一个为数据科学家提供的Python库,用于处理数据管理和模型训练,而不提供预测服务。因此,它不是用于机器学习的端到端平台,可能更适合于公司内部的用例,而不是面向用户的用例。当然,它可以与由Kubernetes或AWS SageMaker支持的Seldon结合转化为一个成熟的解决方案。
数据科学家将工作流程写成DAG步骤,就像数据工程师使用Airflow一样。和Airflow一样,可以使用任何数据科学库,因为Metaflow只执行Python代码。Metaflow在后台分布处理和训练。所有的代码和数据都会自动快照到S3中,以确保每个模型和实验都有版本历史。Pickle是默认的模型序列化格式。
开源版本还没有内置的调度器。其鼓励用户“主要依赖于垂直可伸缩性”,尽管他们可以使用AWS SageMaker实现水平可伸缩性,它与AWS紧密耦合。
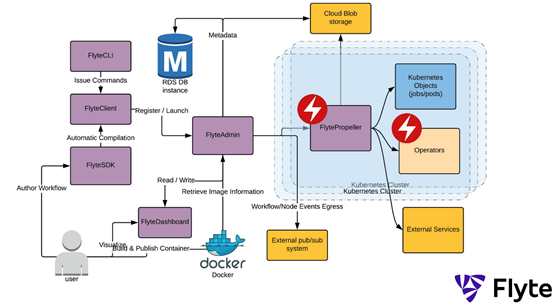
Lyft:Flyte
图源:unsplash
Lyft已开放了其云本地平台Flyte,在这个平台上数据和机器学习操作融合在一起。这与我的D/MLOps方法相一致——数据(Ops)之于MLOps就像燃料之于火箭:没有它将徒劳无功。
Flyte是建立于Kubernetes之上。它是由Lyft内部使用的,可以扩展到至少7000个独特的工作流,每个月执行超过100,000次,100万个任务和1000万个容器。
Flyte中的所有实体都是不可变的,因此可以跟踪数据沿袭、重现实验和削减部署。重复任务可以利用任务缓存来节省时间和金钱。目前支持的任务包括Python、Hive、Presto和Spark以及sidecars。从源代码来看,似乎是EKS。他们的数据目录也是Amundsen,这与Spotify的Lexikon很像。
AWS、Azure、GCP和Co
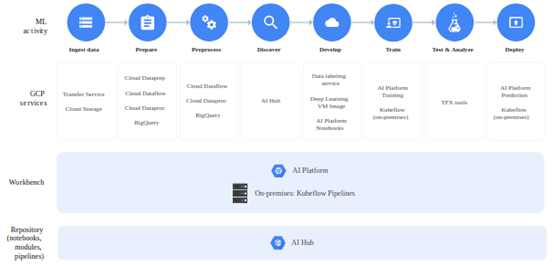
公共云领域的主要参与者都有自己的机器学习平台,除了Oracle,他们只为特定的用例和行业提供封闭的基于机器学习的模型。
AWS SageMaker是一个全堆栈的机器学习解决方案,支持TensorFlow、Keras、PyTorch和MXNet。使用SageMaker Neo,可以将模型部署到云端和边缘。它有一个内置的功能,可以通过Amazon MechanicalTurk对S3中存储的数据附上标签。
谷歌没有托管平台,但是通过TFX、Kubeflow和AI平台,可以将在CPU、GPU和TPUs上运行的模型所需的组件组合在一起,调优超参数,并自动部署到生产环境中。Spotify甚至选择了TFX/Kubeflow-on-GCP选项。
除了TensorFlow,还有对scikit-learn和XGBoost的支持。自定义容器允许使用任何框架,如PyTorch。SageMaker Ground Truth的标签服务目前处于测试阶段。
Azure机器学习支持多种框架,如scikit-learn、Keras、PyTorch、XGBoost、TensorFlow和MXNet。其拥有自己的D/MLOps套件,其中包含大量的图形。喜欢模型开发的人可以使用拖放界面,不过也附带了各种警告。模型和实验管理,如预期的那样由微软通过注册表完成。使用Azure Kubernetes服务进行生产部署,控制转出也是可能的。
IBM Watson ML提供了指向和点击机器学习选项(SPSS)和对常见框架组的支持。作为两大主要参与者之一,模型是在CPU或GPU上训练的,超参数调优也包含在框中。该平台没有很多关于数据和模型验证的细节,因为这些在其他IBM产品中是可用的。
尽管阿里巴巴的人工智能机器学习平台标榜着两个流行词,但它并没有改进文档,关于最佳实践的部分写的是用例而非建议。
不管怎样,它在拖放方面下了功夫,特别是在数据管理和建模方面,这可能对一个自动化的端到端ML平台帮助不大。该平台支持诸如TensorFlow、MXNet和Caffe等框架,但它也支持大量的传统算法。正如所料,它还包括一个超参数调谐器。
模型序列化使用PMML、TensorFlow的SavedModel格式或Caffe格式完成。请注意,采用PMML、ONNX或PFA文件的评分引擎可能会支持快速部署,但它有引入培训/服务倾斜的风险,因为服务的模型是从不同的格式加载的。
其他平台
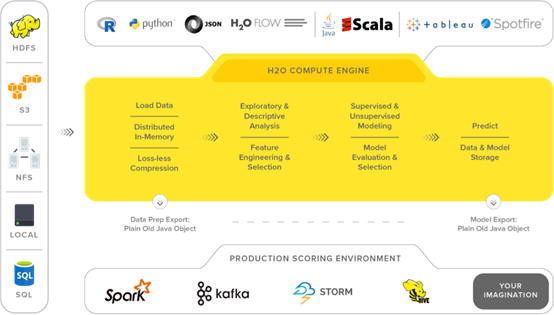
H2O提供了一个使用POJO或MOJO进行数据操作、多种算法、交叉验证、超参数调优网格搜索、特性排序和模型序列化的平台。
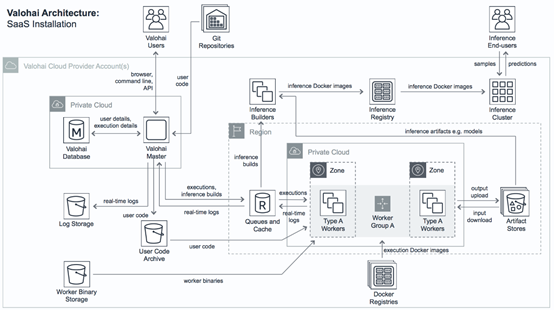
valohai——芬兰语:轻鲨,是一个管理机器学习平台,其可在私有、公共、混合或多云设置上运行。
每个操作(或执行)都对Docker Image运行一个命令,类似于Kubeflow。二者主要区别在于,Valohai直接管理Kubernetes部署集群,而Kubeflow要求开发人员执行这一任务。
然而,Kubeflow和TFX认为他们提供了一些与TensorFlow相关的工具。使用Valohai,需要重用现有的Docker Image,或者滚动自己的Docker Image,这意味着可使用任何机器学习框架,但是自由度必须与可维护性考虑相权衡。
因此,可以通过Spark、Horovod、TensorFlow或任何适配个人需求和基础设施的工具来分配训练,但这些都由个人决定。这还意味着要负责确保数据转换的兼容性,以避免训练/服务倾斜。注意,它目前只支持对象存储。
Iguazio提到了从笔记本或IDE在几秒钟内部署的能力,尽管这似乎错过了最常见的场景:CI/CD管道,甚至是包含TFX的Pusher组件的平台本身。它使用Kubeflow进行工作流编制。
Iguazio确实具备功能商店,可为键值对和时间序列提供统一的API。尽管大多数大型科技公司都有特色商店,但许多可用的产品却并不具备。
功能商店处于核心位置,具有可在多个模型之间共享以加速模型开发的可随时重用的功能。它可以在企业规模上实现特性工程自动化。例如,可以从时间戳中提取许多特性:年、季节、月、星期、时间、是否为本地假日、自最新相关事件以来所经过的时间、特定事件在固定窗口中发生的频率,等等。
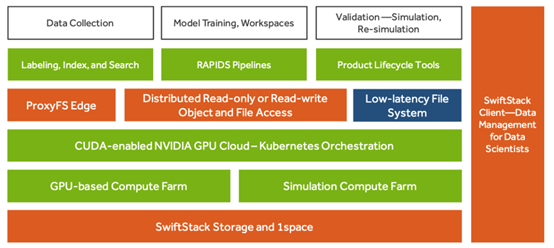
SwiftStack AI通过RAPIDS套件面向NVIDIA gpu的高吞吐量深度学习。RAPIDS提供了库,比如cuML,允许人们使用熟悉的scikit-learn API,但受益于GPU加速支持的算法,以及用于GPU驱动的图形分析的cuGraph。
AI层是D/MLOps的API,其内置了对多个数据源、编程语言和机器学习框架的支持。
MLflow由Databricks支持,这解释了与Spark的紧密集成。它提供了一组有限的部署选项。例如,在PySpark中将模型导出为矢量化的UDF的能力对实时系统来说不是最合理的,因为Python UDF带来了Python运行时环境和JVM之间的通信开销。
尽管开销没有使用标准PySpark UDFs那么大,因在Python和JVM之间的传输中使用了Apache Arrow(一种内存中的柱状格式),也不是无关紧要的。如果使用Spark Sreaming作为默认的数据提取解决方案,那么使用Spark的微批处理模型可能很难实现亚秒延迟。
对日志记录的支持仍然处于实验阶段,这对于D/MLOps来说是非常重要的。从文档可以看出,MLflow并不关注数据和模型验证,至少不是平台的标准部分。有一个MLflow的托管版本(在AWS和Azure上)提供了更多的特性。
D2iQ的KUDO for Kubeflow是一个基于Kubeflow的面向企业客户的平台。与开源的Kubeflow不同,它自带Spark和Horovod,以及对TensorFlow、PyTorch和MXNet等主要框架进行预构建和完全测试的CPU/GPU图像。数据科学家可以在笔记本中部署表单,而不需要切换情景。
图源:unsplash
默认情况下,它支持多用户使用。集成了Istio和Dex以实现额外的安全性和身份验证。Kubeflow的KUDO位于Konvoy之上,是D2iQ的托管Kubernetes平台。它可以运行在云、On-Prem、混合或在边缘,还可用于气隙集群的端口。
在Kubernet中,Kubeflow中的KUDO是用KUDO定义的操作符集合,KUDO是一个声明性工具包,用于使用YAML创建Kubernetes操作符,而非Go。Kubernetes统一声明操作符(KUDOs)的Cassandra、Elastic、Flink、Kafka、Redis等都是开源的,可以与平台集成。








![[[340153]]](https://s2.51cto.com/oss/202009/01/ee623887ed8663b96f09d8c7a6246978.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[[340154]]](https://s3.51cto.com/oss/202009/01/4d3e24610a0198db43af4a42b7c6938c.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[[340155]]](https://s1.51cto.com/oss/202009/01/d0786c7b64b777c9f2cb6f9e52f3b390.jpg){kind=link}