
本篇内容介绍了“Python内置数据结构列表与元组的详细介绍”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
目录
序列
列表
1 列表的特性
1.1 列表的连接操作符和重复操作符
1.3 列表的索引
1.4 列表的切片
1.5 列表的循环(for)
2 列表的基本操作(增删改查)
2.1 列表的增加
2.2 列表的修改
2.3 查看
2.4 列表的删除
2.5 其他操作
元组
1 元组的创建
2 元组的特性
3 元组的命名
深拷贝和浅拷贝
1 值的引用
2 浅拷贝
3 深拷贝
is 和 ==的对比
总结
1. 序列
序列:成员有序排列,可以通过下标偏移量访问到它的一个或者几个成员,这类类型统称为序列。
序列数据包括:字符串、列表和元组类型。
特点:都支持索引和切片操作符;成员关系操作符(in,not in);连接符(+)&重复操作符(*)
2. 列表
数组array:存储同种数据类型的数据结构。[1,2,3],[1.1,2.2,3.1]
列表list:打了激素的数组,可以存储不同数据类型的数据结构。[1,2.2,‘hello']
列表的创建:
li = []#空扩列表print(li, type(li))li1 = [1]#只有一个元素的列表print(li1, type(li1))2.1 列表的特性
2.1.1 列表的连接操作符和重复操作符
print([1,2] + [2,3]) #[1,2,2,3]print([1,2] *3) #[1,2,1,2,1,2]2.1.2 列表的成员操作符(in,not in)
print(1 in [1,2,3]) #True"""#返回的数据类型为bool型布尔类型: True: 1 False: 0"""print(1 in ["a", True, [1,2]]) #由于此处有True所以会默认认为1属于该列表print(1 in ["a", False, [1,2]]) #False2.1.3 列表的索引
根据索引来返回索引到的值;
li = [1,2,3,[1,2,3]]print(li[0]) #返回数值1print(li[-1]) #返回倒数第一个值[1, 2, 3]li1 = [1,2,3,[1,"b",3]]print(li1[-1]) #返回倒数第一个值[1, 'b', 3]print(li1[-1][0]) #返回倒数第一个元素中的第一个元值 1print(li1[3][-1]) #返回第四个元素中的倒数第一个值 32.1.4 列表的切片
li = ['172','25','254','100']print(li[:2]) #拿出列表中的前两个元素['172', '25']print(li[1:]) #拿出列表中的第二个到最后一个元素['25', '254', '100']print(li[::-1]) #将列表反转['100', '254', '25', '172']如已知一个列表信息为 [‘172',‘25',‘254',‘100'],现在需要输出'100-254-25“;
print('-'.join(li[3:0:-1]))#表示从第四个元素开始,倒序依次拿出然后再拼接起来print('-'.join(li[:0:-1]))#表示从最后一个元素开始,倒序依次拿出然后再拼接起来print('-'.join(li[1:][::-1]))#表示从第二个元素开始,全部拿出之后在倒序拼接2.1.5 列表的循环(for)
names = ['小张','张哥','张师']for name in names: print(f"zxk的别名是:{name}")
2.2 列表的基本操作(增删改查)
2.2.1 列表的增加
追加
追加默认是在列表的最后添加;
li = [1,2,3]li.append(4)print(li)#[1, 2, 3, 4]在列表开头添加
li = [1,2,3]li.insert(0,'cat')print(li)#['cat', 1, 2, 3]li = [1,2,3]li.insert(2,'cat')print(li)#在索引2前面添加cat[1, 2, 'cat', 3]一次追加多个元素
li = [1,2,3] #添加4,5,6,li.append([4,5,6]) print(li)#[1, 2, 3, [4, 5, 6]]li.extend([4,5,6]) print(li)#[1, 2, 3, 4, 5, 6]2.2.2 列表的修改
通过索引和切片重新赋值的方式去修改;
li = [1,2,3]li[0] = 'cat' print(li)#['cat', 2, 3]li[-1] = 'westos' print(li)#['cat', 2, 'westos']li = [1,2,3]li[:2] = ['cat','westos'] #表示从第一个开始修改两个['cat', 'westos', 3]print(li)2.2.3 查看
通过索引和切片查看元素,查看索引值和出现次数;
li = [1,2,3,4,3,2,3]print(li.count(1)) #查看数字1出现的次数print(li.index(3)) #查看元素对应的索引2.2.4 列表的删除
根据索引删除
li = [1,2,3]#print(li.pop(1)) #将缩索引的第一个删除,[1, 3]delete_num = li.pop(-1)print(li)print("删除的元素是:",delete_num) #删除的元素是: 3根据value值删除
li = [1,2,3]li.remove(3) print(li)#[1, 2]全部清空
li =[1,2,3]li.clear() print(li) #[]2.2.5 其他操作
除了上面的之外还有反转,排序,复制等操作;
li =[5,4,13,20]li.reverse() print(li)#反转 [20, 13, 4, 5]li.sort() print(li) #从小到大排序[4, 5, 13, 20]#sort默认从小到大,如果想要从大到小,需要用reverse来反转li.sort(reverse=True) print(li) #从大到小排序[20, 13, 5, 4]li1 = li.copy()print(id(li),id(li1)) #复制前后两个列表的ID不一样 2097933779264 2097933779648print(li,li1) #[20, 13, 5, 4] [20, 13, 5, 4]3. 元组
元组tuple:带了紧箍咒的列表,和列表的唯一区别是不能增删改。
3.1 元组的创建
元组中只有一个元素时一定要添加逗号,不然会将其试做对应的信息,
t1 = () #空元组print(t1,type(t1))t2 = (1) #只有单个元素时不是元组,当要是元组是要加逗号print(t2,type(t2))#1 <class 'int'>t3 = (1,2.2,True,[1,2,3,]) print(t3,type(t3))##(1, 2.2, True, [1, 2, 3]) <class 'tuple'>3.2 元组的特性
由于元组是带了紧箍咒的列表,所以没有增删改的特性;
1. 连接符和重复操作符print((1,2,3)+(3,)) #(1, 2, 3, 3)print((1,2,3) *2) #(1, 2, 3, 1, 2, 3)2. 成员操作符print(1 in (1,2,3)) #True3. 切片和索引t = (1,2,3)print(t[0]) #1print(t[-1]) #3print(t[:2]) #(1, 2)print(t[1:]) #(2, 3)print(t[::-1]) #(3, 2, 1)查看:通过索引和切片查看元素,查看索引值和出现次数;
t = (1,4,5,2,3,4)print(t.count(4)) #统计4出现的次数,返回值为2print(t.index(2)) #查看元素2 的,返回的索引值为33.3 元组的命名
Tuple还有一个兄弟,叫namedtuple。虽然都是tuple,但是功能更为强大。collections.namedtuple(typename, field_names)typename:类名称field_names: 元组中元素的名称实例化命名元组
# import datetime# today = datetime.date.today()# print(today)tuple = ('name','age','city')#普通的元组格式,当需要取出时,需要一个一个取出信息print(tuple[0],tuple[1],tuple[2])# name age city可以从collections模块中导入namedtuple工具:
from collections import namedtuple#1.创建命名元组对象UserUser = namedtuple('User',('name','age','city'))#2.给命名元组传值user1 = User("zxk",24,"西安")#3.打印命名元组print(user1) #User(name='zxk', age=24, city='西安')# 4. 获取命名元组指定的信息print(user1.name) #zxkprint(user1.age) #24print(user1.city) #西安4. 深拷贝和浅拷贝
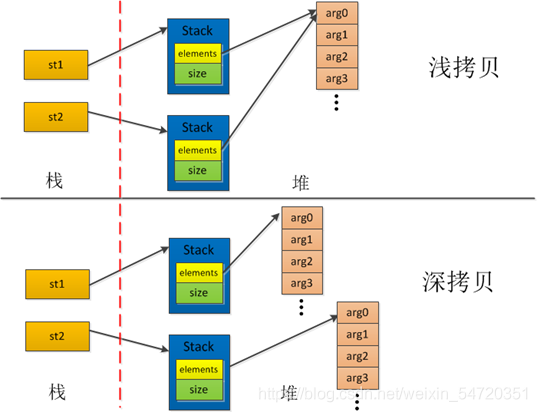
问题: 深拷贝和浅拷贝的区别? python中如何拷贝一个对象?
赋值: 创建了对象的一个新的引用,修改其中任意一个变量都会影响到另一个。(=)
浅拷贝: 对另外一个变量的内存地址的拷贝,这两个变量指向同一个内存地址的变量值。(li.copy(), copy.copy())
公用一个值;
这两个变量的内存地址一样;
对其中一个变量的值改变,另外一个变量的值也会改变;
深拷贝: 一个变量对另外一个变量的值拷贝。(copy.deepcopy())
两个变量的内存地址不同;
两个变量各有自己的值,且互不影响;
对其任意一个变量的值的改变不会影响另外一个;
4.1 值的引用
nums1 = [1,2,3]nums2 = nums1nums1.append(4)print(nums2) # [1, 2, 3, 4]因为num1和num2指向同一个内存空间,所以当nums1添加值时,相当于nums2也添加了值。
4.2 浅拷贝
n1 = [1,2,3]n2 = n1.copy() #n1.copy和n1[:]都可以实现拷贝。print(id(n1),id(n2))#2708901331648 2708901331264n1.append(4)print(n2) #n1和n2的内存地址不同,修改并不互相影响 [1, 2, 3]加粗样式
4.3 深拷贝
有列表嵌套时,或者说列表中包含可变数据类型时,一定要选择深拷贝.
可变数据类型(可增删改的):列表(list)
不可变数据类型:数值,字符串(str),元组(tuple) namedtuple;变量指向内存空间的值不会改变。
n1 = [1,2,[1,2]]n2 = n1.copy()#n1和n2的内存地址:的确拷贝了 #2859072423168 2859072422336print(id(n1),id(n2))#n1[-1]和n2[-1]的内存地址: #最后一个元素的地址:2859072425664 2859072425664print(id(n1[-1]),id(n2[-1]))n1[-1].append(4)print(n1)#[1, 2, [1, 2, 4]]print(n2) #[1, 2, [1, 2, 4]]深拷贝和浅拷贝最根本的区别在于是否真正获取一个对象的复制实体,而不是引用。
假设B复制了A,在修改A的时候,看B是否发生变化:
如果B跟着也变了,说明是浅拷贝,拿人手短!(修改堆内存中的同一个值)
如果B没有改变,说明是深拷贝,自食其力!(修改堆内存中的不同的值)
如何实现深拷贝 copy.deepcopy
import copyn1 = [1,2,[1,2]]n2 = copy.deepcopy(n1)#n1和n2的内存地址:的确拷贝了print(id(n1),id(n2)) #2894603422016 2894603421056#n1[-1]和n2[-1]的内存地址:print(id(n1[-1]),id(n2[-1])) #最后一个元素的地址:2894603422272 2894603419776n1[-1].append(4) #n1 = [1, 2, [1, 2, 4]]print(n2) #n2 = [1, 2, [1, 2]]5. is 和 ==的对比
在 python 语言中 :
==:判断类型和值是否相等
is: 类型和值是否相等,内存地址是否相等
== is和==两种运算符在应用上的本质区别是:
1). Python中对象的三个基本要素,分别是:id(身份标识)、type(数据类型)和value(值)。
2). is和==都是对对象进行比较判断作用的,但对对象比较判断的内容并不相同。
3). ==用来比较判断两个对象的value(值)是否相等;(type和value)
is也被叫做同一性运算符, 会判断id是否相同;(id, type 和value)
print(1 == '1') #由于数据类型不一致Falseli = [1,2,3]li1 = li.copy()print(li == li1) #True#类型和值相等,但是内存地址不相等print(id(li),id(li1))print(li is li1) #False快速注释代码的快捷键:ctrl+/
快速缩进的快捷键:选中需要缩进的代码+tab
快速取消缩进的快捷键:选中需要缩进的代码 ,按shift+tab
练习:云主机管理系统
编写一个云主机管理系统:
- 创建云主机(IP,hostname,IDC)
- 搜索云主机(顺序查找)
- 删除云主机
-查看所有云主机信息
from collections import namedtuplemenu = """ 云主机管理系统 1).添加云主机 2).搜索云主机(IP搜索) 3).删除云主机 4).云主机列表 5). 退出系统请输入您的选择:"""# 1. 所有云主机信息如何存储?选择哪种类型存储? 选择列表# 2. 每个云主机信息该如何存储?IP,hostname.IDC 选择命名元组hosts = []Host = namedtuple('Host',('ip','hostname','idc'))while True: choice = input(menu) if choice == '1': print("添加云主机".center(50,"*")) ip = input("ip:") hostname = input("hostname:") idc = input("idc(eg:ali,huawei...):") host1 = Host(ip,hostname,idc) hosts.append(host1) print(f"添加{idc}的云主机成功。IP地址为{ip}") elif choice == '2': #怎么搜索:for循环(for..else),判断,break print("搜索云主机".center(50,"*")) for host in hosts: ipv4 = input("please input ipv4:") if ipv4 == host.ip: print(f'{ipv4}对应的主机为{host.hostname}') else: break elif choice == '3': print("删除云主机".center(50,"*")) for host in hosts: delete_hostname = input("please input delete hostname:") if delete_hostname == host.hostname: hosts.remove(host) print(f'对应的主机{delete_hostname}已经删除') else: break elif choice == '4': print("云主机列表".center(50,"*")) print("IP\t\t\thostname\tidc") count = 0 for host in hosts: count +=1 print(f"{host.ip}\t{host.hostname}\t{host.idc}") print(f'云主机总个数为:{count}') elif choice == '5': print("系统正在退出,欢迎下次使用......") exit() else: print("请输入正确的选项!")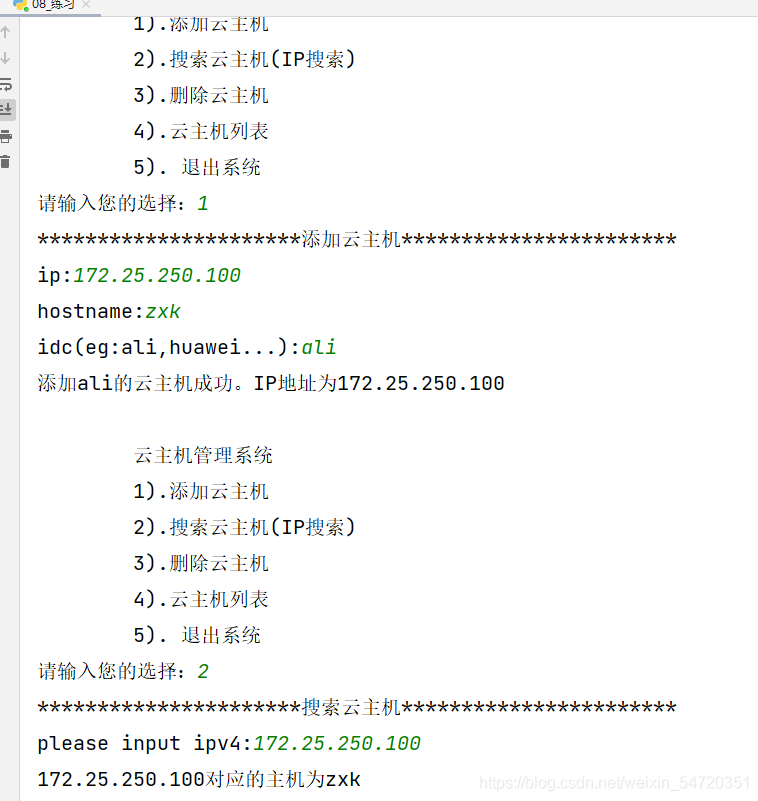
“Python内置数据结构列表与元组的详细介绍”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注编程网网站,小编将为大家输出更多高质量的实用文章!







