
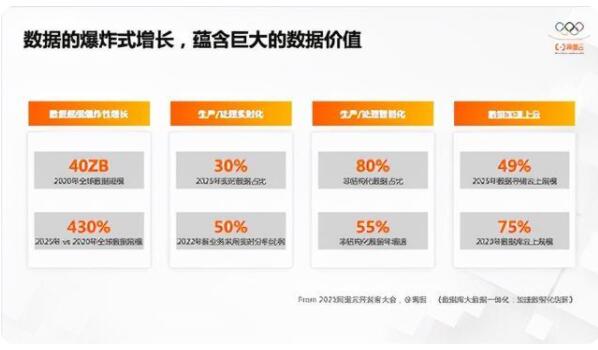
2021年开发者大会上,我们的一位研究员分享的一个议题,提到了很多数据,主要想阐述的是行业发展到现在这个阶段,数据的膨胀非常厉害,数据增速非常可怕。无论是数据规模还是生产处理的实时化,到生产处理的智能化,以及数据加速上云的云化过程。
这些数据来自Gartner、IDC的分析,都是行业最权威的分析报告里沉淀总结出来的。这就意味着我们在数据领域尤其是分析领域的机遇和挑战都很大。
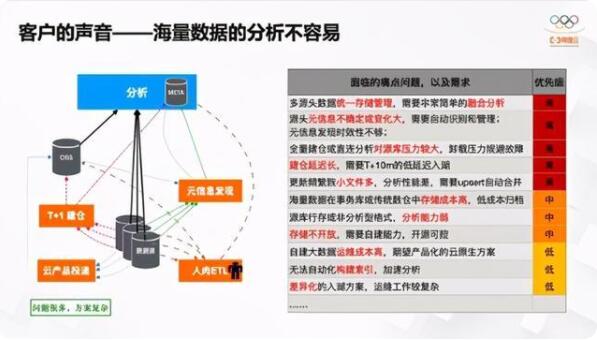
在海量的数据上,我们要真正做好数据价值的挖掘和使用会面临很多挑战,第一是现有的架构慢慢都要往云上架构迁移;第二个是数据量;第三个是Serverless按量付费,慢慢从尝试性的选择成为默认选择;第四是还有多样化的应用、异构数据源。相信大家接触过云都知道,无论是哪个云厂商都有很多种云服务可供,尤其是数据类服务数量繁多。这时候,大量数据源一定会带来一个问题:分析难度大,尤其是想做关联分析的时候,异构数据源怎么连接起来是很大的问题。其次是差异化的数据格式,通常我们做数据写入会时选择方便、简单的格式,比如CSV、Json格式,但对分析来讲,这些格式往往是非常低效的,尤其是数据到了TB、PB级的时候,根本没法分析。这时候Parquet、ORC等面向分析的列存格式就衍生出来了。当然还包括链路安全以及差异化群体等等,数据量膨胀的过程中又增加了很多的分析难度。
在真实的客户场景里,很多数据已经上云了和“入湖”了。湖是什么?我们对湖的定义和理解更像AWS的S3或者阿里云OSS这种对象存储,是简单易用的API形式,可以存各种各样差异化的数据格式,有无限的容量、按量付费等非常多的好处。之前想基于湖做分析非常麻烦,很多时候要做T+1的建仓和各种云服务投递。有时候数据格式不对就要人肉做ETL,如果数据已经在湖里要做元信息发现分析等等,整个运维链路很复杂,问题也很多。这里都是线上客户实际面临的离线数据湖问题,有些优先级偏高,有些低些,总而言之问题非常多。
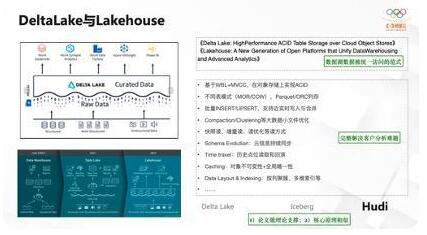
其实Databricks大概19年就开始将研究重点从Spark方向,慢慢往Lakehouse方向调整了。他们发表了两篇论文,这两篇论文为数据湖怎么被统一访问、怎么被更好地访问提供了理论层面的定义。
基于Lakehouse的新概念,想做到的是屏蔽格式上的各种差异,为不同的应用提供统一的接口以及更加简化的数据访问、数据分析能力。架构说实现数据仓、数据湖、Lakehouse一步步演进。
他的两篇论文阐述了很多新概念:第一,怎么设计和实现MVCC,能让离线数仓也有像数据库一样的MVCC能力,从而满足大部分对批事务的需求;第二,提供不同的存储模式,能够适应不同的读和写Workload;第三,提供一些近实时的写入和合并能力,为数据量提供链路能力。总之,他的思路能够较好解决离线数据分析的难题。
目前业界有三款产品相对比较流行,第一个是Delta Lake,它是Databricks自己发布的数据湖管理协议;第二个是Iceberg,Iceberg也是Apache的一个开源项目;第三个是Hudi,Hudi最早由Uber内部研发,后来开源的项目(早期用得比较多的是Hive的ACID)。目前这三个产品因为可以对接HDFS的API,可以适配底层的湖存储,而OSS又可以适配到HDFS存储接口。由于核心原理相似,三个产品各方面的能力都在逐渐靠近,同时有了论文做理论支撑,我们才会有方向去实践。
对我们来说,当时选择Hudi也是因为其产品成熟度方面的原因,还有它面向数据库方面的数据入湖能力,形态上比较满足我们在数据库团队做CDC方面的业务需求。
Hudi早期的定义是Hadoop Updates anD Incrementals的缩写,后面是面向Hadoop的Update、Delete、Insert的概念,核心逻辑是事务版本化、状态机控制和异步化执行,模拟整个MVCC的逻辑,提供对于内部列存文件比如Parquet、ORC等对象列表的增量式管理,实现高效的存储读写。它和Databricks定义的Lakehouse概念很相似,不谋而合,Iceberg也是一样,它的能力也在逐步往这个方向提升。
Hudi官方网站对外提供的架构是这样的形态。之前我们做技术选型、调研的时候发现很多同行也已经充分使用Hudi做数据入湖和离线数据管理的方案选型。第一,因为产品比较成熟;第二,它符合我们CDC的需求;第三,Delta Lake有一套开源版本,一套内部优化版本,对外只提供开源版本,我们认为它不一定把最好的东西呈现。Iceberg起步比较晚,早期相比其他两个产品能力不太完全,所以没有考虑它。因为我们都是Java团队,也有自己的Spark产品,Hudi正好比较契合我们用自己的runtime支持数据入湖的能力,因此也就选择了Hudi。
当然我们也一直在关注这三个产品的发展,后来国内的一个开源项目StarLake,也是做类似的事情。每种产品都在进步,长期来看能力基本对齐,我觉得会和论文里定义的能力慢慢吻合。
“以开源Hudi为列式、多版本格式为基础,将异构数据源增量、低延迟入湖,存储在开放、低成本的对象存储上,并且在这个过程中要实现数据布局优化、元信息进化的能力,最终实现离线数据统一管理,无差别支持上面的计算和分析能力,这是整体的方案。”这是我们对Lakehouse的理解,以及我们的技术探索方向。
二、阿里云Lakehouse实践
下面介绍一下阿里云Lakehouse的技术探索和具体的实践。首先,大概介绍一下阿里云数据库团队近年来一直提的概念“数据库、仓、湖一体化”战略。
大家都知道数据库产品分为四个层次:一是DB;二是NewSQL/NoSQL产品;三是数仓产品;四是湖数据产品。越往上数据的价值密度越大,会以元表元仓形式的数据关联到分析中去,比如DB数据格式非常简单、清晰; 越往下数据量越来越庞大,数据形式越来越复杂,有各种各样的存储格式,数据湖形式有结构化、半结构化、非结构化,要分析就必须要做一定的提炼、挖掘,才能真正把数据价值用起来。
四个存储方向有各自的领域,同时又有关联分析诉求,主要就是要打破数据孤岛,让数据一体化,才能让价值更立体化。如果只是做一些日志分析,例如关联的地域、客户来源的话,也只是使用了GroupBy或者是Count等相对简单的分析能力。对于底层数据,可能要做多次清洗、回流,才能往向在线化、高并发的场景一层层分析。这里不仅仅直接将数据从湖到库写入,也可以到仓,到NoSQL/NewSQL的产品里,到KV系统里去,利用好在线化的查询能力,等等。
反过来也是一样,这些数据库/NewSQL产品甚至数仓中的数据也会向下流动,构建低成本、大容量的存储备份、归档,降低上面的存储压力、分析吞吐压力,且可以形成强大的联合分析能力。这也是我自己对数据库、仓、湖一体化的理解。
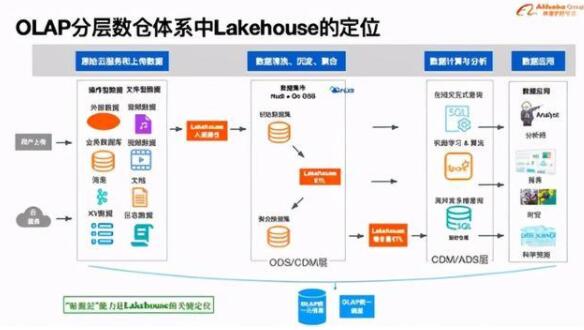
刚才讲了数据库的发展方向和定位,再看看数据库下面OLAP本身的分层数仓体系中Lakehouse是怎样的定位。做过数仓产品的同学都比我熟悉,(PPT图示)基本上是这样的分层体系,最开始各种各样的形态非数仓或者非数据湖系统外面有各种各样的形式存储数据,我们理解通过Lakehouse的能力,做入湖、建仓,通过清洗、沉淀和聚合,形成ODS或者是CDM层,这里做了初步的数据聚合和汇总能力,形成数据集市的概念。
这些数据在阿里云上我们会基于Hudi的协议,基于Parquet文件格式存到整个OSS上面,内部通过ETL把初始数据集进一步聚合为更清晰、更面向业务的数据集上,然后再构建ETL,往实时数仓里导入,等等。或者这些数据集直接面向低频的交互式分析、BI分析,或面向Spark等引擎做机器学习,最终输出到整个数据应用上,这是整体的分层体系。
整个过程中,我们会接入统一的元信息体系。因为如果系统的每个部分都有自己的术语,都要保留一份自己的元信息,对OLAP体系来讲是分裂的,因此元信息一定要统一,调度也是一样。不同数据仓层次的表在不同的地方要串联起来,一定要有完整、统一的调度能力。以上是我理解Lakehouse在OLAP体系中的的定位,主要是贴源层,汇聚离线数据的能力。
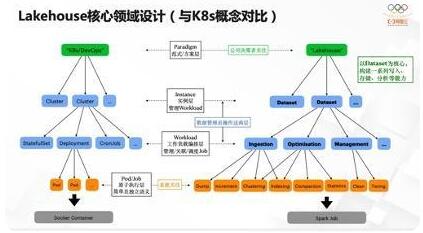
前面介绍了Lakehouse在数据库和OLAP团队里的定位,后面重点介绍一下Lakehouse在我们的领域设计是怎样的形态。因为之前我自己用过K8s做分析系统上云,所以对K8s的很多理念还是比较清楚。
在我们自己设计的时候也试图参考、学习一下K8s的体系。K8s有我们经常提到的DevOps概念,这是一种实践范式。在这个范式下会创建很多实例,在实例里会管理很多应用,这些应用最终通过Pod方式被原子性调度执行,Pod里再跑一些业务逻辑,各种各样的Container。
我们认为Lakehouse也是一种范式,一种处理离线数据的范式。在这里,数据集是我们的核心概念,比如要构建一套面向某种场景、某个方向的数据集。我们能要定义A、B、C不同数据集,在我们看来这是一个实例。围绕这个数据集编排各种各样的Workload工作负载,比如做DB入湖。还有分析优化类的Workload,比如索引构建,比如像z-ordering、Clustering、Compaction等技术,查询优化能力提升得更好。还有就是Management类型的Workload,比如定期把历史数据清理了,做冷热存储分层,因为OSS提供了很多这样的能力,把这些能力用好。最下面一层是各种Job,我们内部是基于Spark建设离线计算能力,我们把Workload前后编排成小的job,原子的job全部弹性到Spark上执行,以上是我们对于Lakehouse在技术实践中的领域设计。
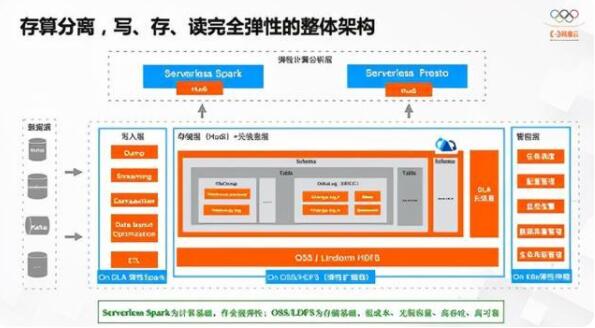
这是整体的技术架构。首先,在云上有各种各样的数据源,通过编排定义各种各样的Workload,跑在我们自己的Spark弹性计算上。核心的存储是基于Hudi+OSS,我们也支持别的HDFS系统,比如阿里云的LindormDFS,内部元信息系统管理库、表、列等元信息。后面基于K8s调度所有的管控服务。上层通过原生的Hudi接口,对接计算、分析能力。这是整个弹性架构。
其实Serverless Spark是我们的计算基础,提供作业级弹性,因为Spark本身也支持Spark Streaming,通过短时间弹出一个Spark作业实现流计算。选择OSS和LindormDFS做存储基础,主要利用低成本、无限容量的好处。
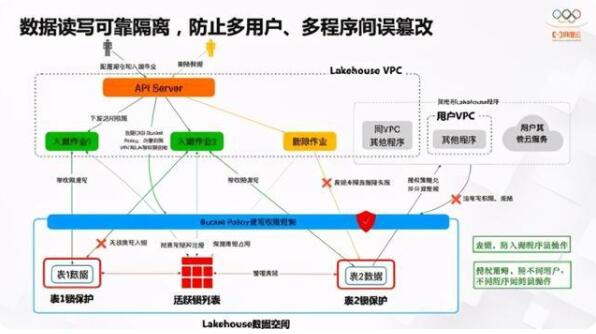
在这个架构上,怎么连通用户的数据实现数据入湖到存储、到分析的能力呢?以上是我们基于VPC构建的安全方案。首先我们是共享集群模式,用户侧可以通过SDK和VPDN网络连接过来,再由阿里云内部网关打通计算集群,实现管理和调度;再通过阿里云弹性网卡技术,联通用户的VPC实现数据通路,同时实现路由能力和网络隔离能力,不同用户还可能有子网网段冲突问题,通过弹性网卡技术可以实现相同网段同时连接同一个计算集群的能力。
用过阿里云OSS的同学都知道,OSS本身是阿里云VPC网络里的公网,它是共享区,不需要复杂的网络。而RDS和Kafka是部署在用户的VPC里,通过一套网络架构就可以实现多种网络打通。对比VPC网段冲突,共享区域没有这样的问题。其次,数据之间隔离,ENI有端到端的限制,比如VPC有ID标志、有不同的授权要求,非法用户尝试连接VPC,如果不是这个网卡则网络包无法联通,就可以实现安全的隔离和数据的通路。
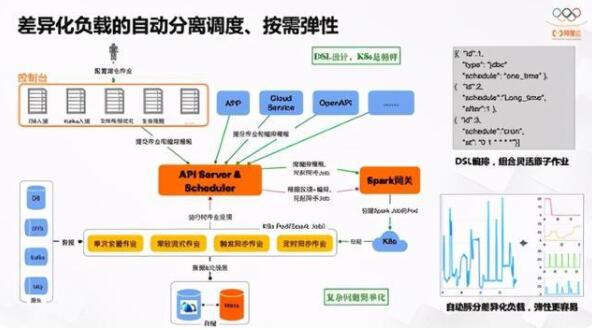
网络架构已经确定了,怎么运行执行呢?在整个设计里,我们会以K8s的DSL设计为榜样,前面提到会定义很多入湖任务,一个Workload可能有很多小任务,这时候需要类似定义DSL的编排能力,job1、job2、再到job3,定义一套编排脚本;这些编排脚本,通过SDK、控制台等入口提交过来,再通过API Server接收并由Scheduler调度起来。这个Scheduler会和Spark的网关之间打通,实现任务管理、状态管理、任务分发等,最终调度内部的K8s拉起作业来执行。有些全量作业跑一次,比如DB拉一次就行了,还有常驻的流式作业、有触发式的异步作业、定时异步作业等等,不同的形态相同的调度能力,从而可以扩展。过程中有作业状态持续反馈状态、间隙性统计等等。在K8s里,K8s Master承担了这样的角色,同样有API Server和Scheduler的角色。在我们这里也是类似,也是通过一主多从架构实现调度能力HA机制等等。
在这里,为什么我们要把一个Workload面向用户侧的任务拆成N个不同的job?因为这些任务完全放在一个进程里跑,整个Workload的水位变化非常大,做弹性调度非常难。全量任务跑一次就可以了,但是配多少资源合适呢?很多时候Spark没有那么灵活,尤其是异步任务和定时任务拉起来消耗很大,但是用完之后又不知道下一次什么时候来,很难预测。就像很多信号系统处理里,需要做傅里叶变换一样,把复杂的波型拆成多个简单的波型,信号处理就简单起来。我们也是有这样感性的理解。用不同的Job来执行Workload中不同角色的任务,就很容易实现弹性能力。像定时或临时性的触发Job,临时拉一个job,资源消耗与常驻的流式任务完全无关,就可以完全不影响流式任务的稳定性、入湖延迟等等。这是设计背后的思考,就是让复杂的问题简单化。因为基于弹性的角度来讲,拆得波形越简单,弹性就会更好做,预测也会简单一点。
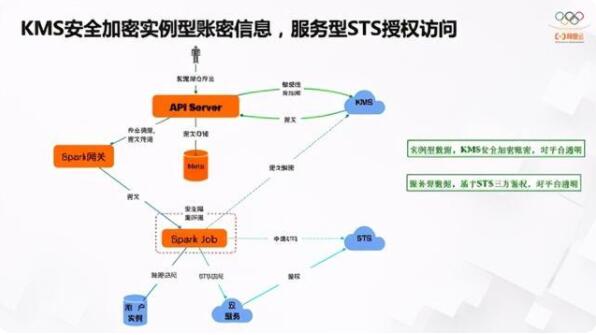
入湖里会涉及很多用户的账密信息,因为不是所有云产品都以AWS的IAM或阿里云的RAM等系统来构建完全云化的资源权限控制。很多产品还是以账密方式做认证和授权管理,包括用户自建的系统,数据库系统等等。这样,用户要把所有的连接账密都交给我们,怎么更安全的管理它们?我们是基于阿里云的两套体系:一套是KMS,以硬件级数据加密体系来加密用户数据;第二套是STS,完全云化的三方鉴权能力,实现用户数据的安全访问,尤其是敏感数据的隔离或者保护的机制,这就是我们现在的整个体系。
还有一个问题,不同用户之间通过各种机制完全隔离开了,但是同一个用户有很多的任务。在Lakehouse概念中有四层结构,一个数据集下面有多个库,库下面有多个表,表下面有不同的分区,分区下面是不同的数据文件。用户有子账号体系、有各种不同的作业,因此操作数据时可能会出现相互影响。
比如不同的入湖任务都想要写同一张表,线上A任务已经正常运行了,结果另外的用户配置了B任务,也要写入同一个空间,这就有可能把已经上线的A任务数据全部冲掉,这是很危险的事情。还有其他用户删除作业的行为,可能会删掉线上正在运行任务的数据,有可能其他任务还在访问,但又不能感知它;还比如通过别的云服务、或是VPC内别的程序、自己部署的服务等等,都可能操作这个表,导致数据出问题。因此我们设计了一整套机制,一方面是在表级别实现锁的机制,如果有任务最早就占有一张数据写入权限时,后面的任务在这个任务生命周期结束之前,都不允许再写入,不可以写脏了。
另一方面基于OSS的Bucket Policy能力,构建不同程序的权限校验能力。只允许Lakehouse的的任务有权限写数据,而其他程序不允许写,但其他程序可以读。同一个账号的这些数据本来就是为了共享、为了分析,为了各种应用场景的接入,就是可以读,但绝对不可以污染它。我们在这些方面做了可靠性工作。
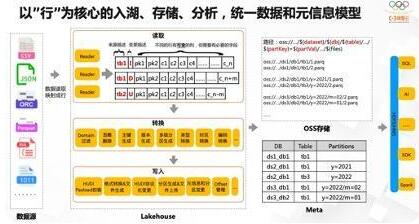
我们更多讲的架构体系,回到整体看一下怎么理解数据模型,我们认为整个过程是以行为中心(因为数仓还是一行行的数据,存储在表的范围内),以行数据构建统一入湖、存储、分析,元信息模型等。首先有各种各样的数据源(有文本或二进制,binlog就是二进制的数据;或者类似Kafka中可以存储各种二进制),这些数据最终通过各种各样Connector、Reader(不同的系统有不同的叫法),把数据读过来,映射成行数据。在这些行数据中,有关键的描述信息,比如来源信息、变更类型等等,还有可变的列集合。再通过一系列的规则转化,比如滤掉某些数据,要为数据生成主键,要段定义版本、类型转换等等;最后再通过Hudi Payload封装、转换、元信息信息维护、文件生成等等方式,最终写到湖存储里。
在存储里通过元信息、分区等数据维护,并对接后续计算和分析,就无缝看到湖、仓里所有存的数据的元信息,无缝对接不同形态的应用场景。
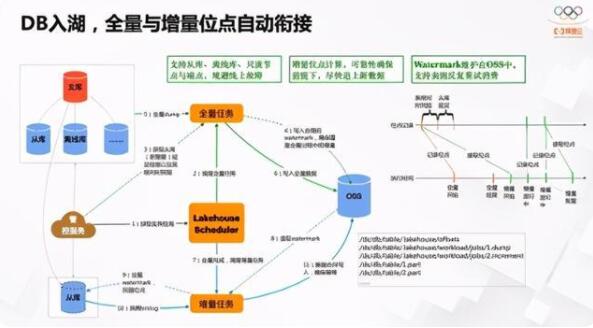
下面介绍一下我们对常见数据源接入形式的支持。DB入湖是最常见的场景,在阿里云上,有RDS和PolarDB等产品。以MySQL引擎举例,一般都是有主库、从库、离线库等架构,可能还有主从接入点,但是万变不离其宗。DB入湖要先做一次全量同步,再做增量同步。对用户来讲,DB入湖是明确的Workload,但对系统来讲要先做好全量同步这件事情,再自动对接增量同步这件事情,数据还要通过一定的机制把位点衔接住,确保数据的正确性。整个调度过程通过统一的管控服务获取DB信息,自动选择从库或线上压力最小的实例,进行全量同步写到库里,并维护好相应的Watermark,记录全量从什么时间点开始的、从库和主库之间有多少延迟等。全量做完之后,开始做增量任务,利用DTS等同步binlog服务,基于前面的Watermark做数据回溯,开始做增量。利用Hudi里的Upsert能力,以用户定义的PK和版本按照一定逻辑把数据合并,确保数据最终一致,分析侧的正确性。
在整个Watremark维护上需要考虑很多,如果全量挂了,再重试一下,位点应该从哪里开始,如果增量挂了,不仅要考虑增量之前已经进行到哪里,还要渐进式的维护增量位点,不能每次增量一挂就回退到最开始全量前的位点,那后面数据延迟太严重了。在Lakehouse表级别维护这些信息,在Workload运行时、重启、重试等过程可以自动衔接,对用户透明。
第二个是像类消息产品的入湖,我们也做了一些技术探索和业务尝试,它的数据不像DB一样Schema都很明确。像阿里云现有的Kafka服务里,它的Schema只有两个字段,Key和Value,Key描述消息Id,value自定义,大部分时候是一个Json,或者是二进制串。首先要解决怎么映射成行,会有很多逻辑处理,比如先做一些Schema推断,得到原始的结构。Json原来的嵌套格式比较容易存储,但是分析起来比较费劲,只有打平成一个宽表分析才方便,所以还要做一些嵌套打平、格式展开等等逻辑,再配合前面提到的核心逻辑,最终实现文件写入、元信息合并等等。这个元信息合并就是指,源头的列的个数不确定,对于不同的行有时候有这个列,有时候没有。而对于Hudi来讲,需要在应用层把元信息维护好。Lakehouse里的Schema Evolution,就是Schema的合并、列的兼容处理、新增列的自动维护等等。
我们内部有基于Lindorm的方案。Lindorm是我们自研兼容HBase、Cassandra等大宽表接口的KV行存。它有很多的历史文件和很多Log数据,通过内部的LTS服务调,把全量和增量数据通过Lakehouse方式存在转换成列存文件,支持分析。
对Kafka、SLS系统中都有分片(Partition、Shard)概念,流量变化很大时需要自动扩缩容,因此消费侧要主动感知变化,不影响数据正确性的持续消费。并且这种数据都是偏Append-Only,正好可以利用好Hudi小文件合并能力,让下游分析更简单、更快、更高效。
三、客户最佳实践
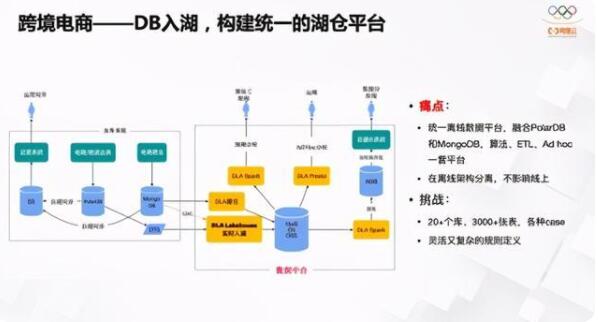
以上是技术探索的分享,接下来会介绍一下在客户的应用。之前一个跨境电商的客户,他们问题就是DB数据不容易分析,目前有PolarDB和MongoDB系统,希望把所有数据近实时入湖到OSS上做分析。现在业界联邦分析FederatedAnalytics,问题在于直连查询数据时原库的压力很大,最好的方式就是入湖到离线湖中里做分析。通过Lakehouse方式构建离线湖仓,再对接计算和分析,或者对接ETL清晰,规避对线上数据的影响,同一架构把整体数据平台构建起来,应用、分析百花齐放,不影响任何东西。
这个客户的难点是他们有很多库、表以及各种各样的应用case,我们在Hudi上做了很多优化,也完成了20多个patch贡献到社区里完善Hudi,包括元信息打通、部分Schema Evolution能力,在客户侧也应用起来。
另一个客户数是Kafka日志近实时分析。原来他们的方案需要人肉做很多步骤,包括入湖、数据管理、小文件合并等。通过Lakehouse方案,对接客户数据,自动合并入湖,维护元信息,客户直接应用就可以了,内部直接打通了。
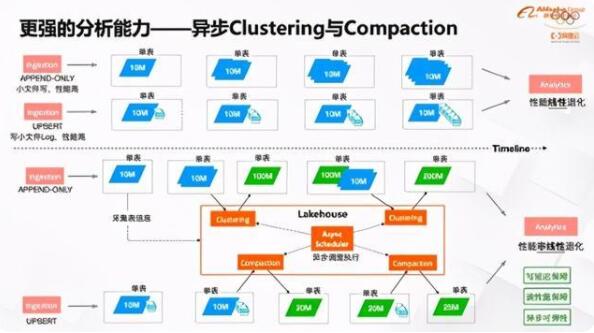
还有一个问题小文件,在他们的场景里与Hudi社区一起参与Clustering技术的建设。Clustering就是自动将小文件合并成大文件,因为大文件利于分析。其次,在合并过程中,可以按照某些特定列把数据排序,后续访问这些数据列时,性能会好很多。
四、未来展望
最后,我再分享一下我们团队对未来的思考,Lakehouse可以怎么应用起来。
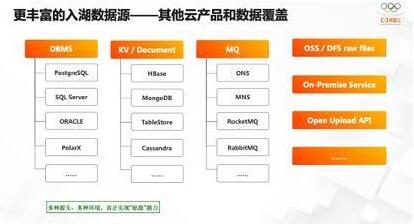
第一,更丰富的入湖数据源。Lakehous重要的价值在于屏蔽各种数据差异,打破数据孤岛。在云上很多系统中有各种各样的数据,有很大的分析价值,未来要统一更多的数据源,只支持一个DB或Kafka,客户价值不是最大化的。只有把足量的数据汇总到一起,形成大的离线湖仓,并且屏蔽复杂度,对用户的价值才愈发明显。除了云产品,还有其他形式的入湖,像专有云、自建系统、自主上传场景等。主要还是强化贴源层的能力。
第二,更低成本、更可靠的存储能力,围绕数据生命周期管理。因为阿里云OSS有非常丰富的计费方式,支持多种存储(标准存储、低频存储、冷存储以及更冷的存储)等等,计费逻辑里几十项,一般人不完全清楚。但对用户来讲,成本永远是设计中心心,尤其是构建海量的离线湖仓,因为数据量越来越大、成本就越来越多。
之前接触过一个客户,他需要存储三十年的数据,他们的业务是股票分析,要把交易所、券商的所有数据全部爬下来,传到大的湖仓里。因为要做三十年的分析,成本优化是非常关键的。原来选择在线系统,存几个月就扛不住了,因为数据量太大了。分析数据是有从冷到热、从相对低频到高频访问的特点,Lakehouse利用这些特点,通过定义规则和逻辑,自动屏蔽用户对哪些目录需要冷存储、哪些目录需要热存储的复杂维护,帮用户走得更进一步。
第三,更强的分析能力。在Hudi加速分析的能力里,除了前面提到的Clustering,还有Compaction。Clustering就是小文件合并,比如日志场景,每写入一批就产生一个文件,这些文件一般都不是很大,但文件越小越碎分析时的访问代价很大。访问一个文件就要做鉴权、建连接、元信息访问。访问一个大文件这些过程只做一次,而访问小文件则成倍放大,开销非常大。在Append场景,通过Clustering快速合并小文件成大文件,规避因为写入而导致的分析性能线性退化问题,确保分析高效。
在Hudi中如果是Merge On Read类型的表,比如Delete、Update都会快速写到log文件,在后续读的时候Merge数据,形成完整的逻辑的数据视图。这里问题也很明显,如果有1000个log文件,每次读需要合并1000次,分析能力退化肯定非常严重。这时Hudi的Compaction能力就会定期把log文件合并起来。前面提到,如果完全要在同一个入湖作业里实现,尤其是文件合并,计算开销很大,在做这些重负载的时候,对入湖链路的延迟影响很大,一定要通过异步化调度的方式,实现写延迟保障。并且这些过程都是可弹性的,不论是100个文件要合还是1万个文件要合,都是可以快速弹性而不影响延迟,非常有优势。
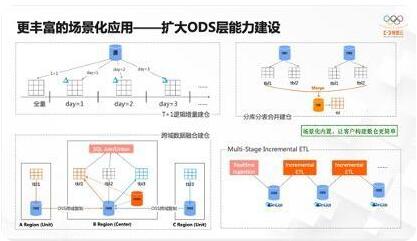
第四,更丰富的场景化应用。个人觉得Lakehouse还是面向贴源层的能力,配合做一定程度的聚合。因为更高层次的聚合性和实时性,有更多实时数仓选择,现在业界比较火的DorisDB、ClickHouse对实时的高频分析有很大优势。基于Hudi、Lakehouse、OSS做实时分析没有太多优势,所以还是以构建贴源层的能力为主。
原来都是近实时入湖场景,但是可能有些用户没有这么多实时性要求,周期性的T+1逻辑建仓可以满足,可以利用Hudi+Lakehouse能力,每天查询一部分逻辑增量数据并写入Hudi,并维护分区,和实现Schema Evolution能力。
早期数据量越来越大,客户通过分库分表实现逻辑拆分。分析的时候发现库、表太多了,分析、关联难度大,这时候可以通过构建多库多表合并建仓能力,汇总到一张表后做分析。
然后是跨区域融合分析,有很多客户提这样的需求,尤其是海外。有些客户要服务海外用户,必须有部分业务在海外,特别在跨境电商的场景,而它的采购体系、仓储体系、物流体系、分销体系等又都在国内建设,很多数据想要融合分析怎么办?首先OSS提供了跨域复制,但也只是到数据层面,没有任何逻辑,在这里可以通过Lakehouse做逻辑层建设,把不同region数据混合在一起,汇总到同一个区域之后,提供统一的SQL join、union等能力。
最后Hudi有TimeTravel、Incremental query的能力,这时候构建incremental ETL清洗不同的表,在一定程度上通用化,让用户用得更简单。未来内置更多场景化能力,让用户构建和应用湖仓更加简单!








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}