
✅作者简介:大家好,我是Philosophy7?让我们一起共同进步吧!🏆 📃个人主页:Philosophy7的csdn博客
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门
💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博>主哦🤞
文章目录
一、Hive介绍
hive: 由 Facebook 开源用于解决海量结构化日志的数据统计工具。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能。
Hive的优缺点
优点:
- 类似于SQL语句,简单学习易上手
- 避免了去写 MapReduce,减少开发人员的学习成本
- Hive 的执行延迟比较高,因此 Hive 常用于数据分析,对实时性要求不高的场合
- Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较
高 - Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
缺点:
- Hive 的 HQL 表达能力有限
- Hive 的效率比较低
- Hive本质是一个MR
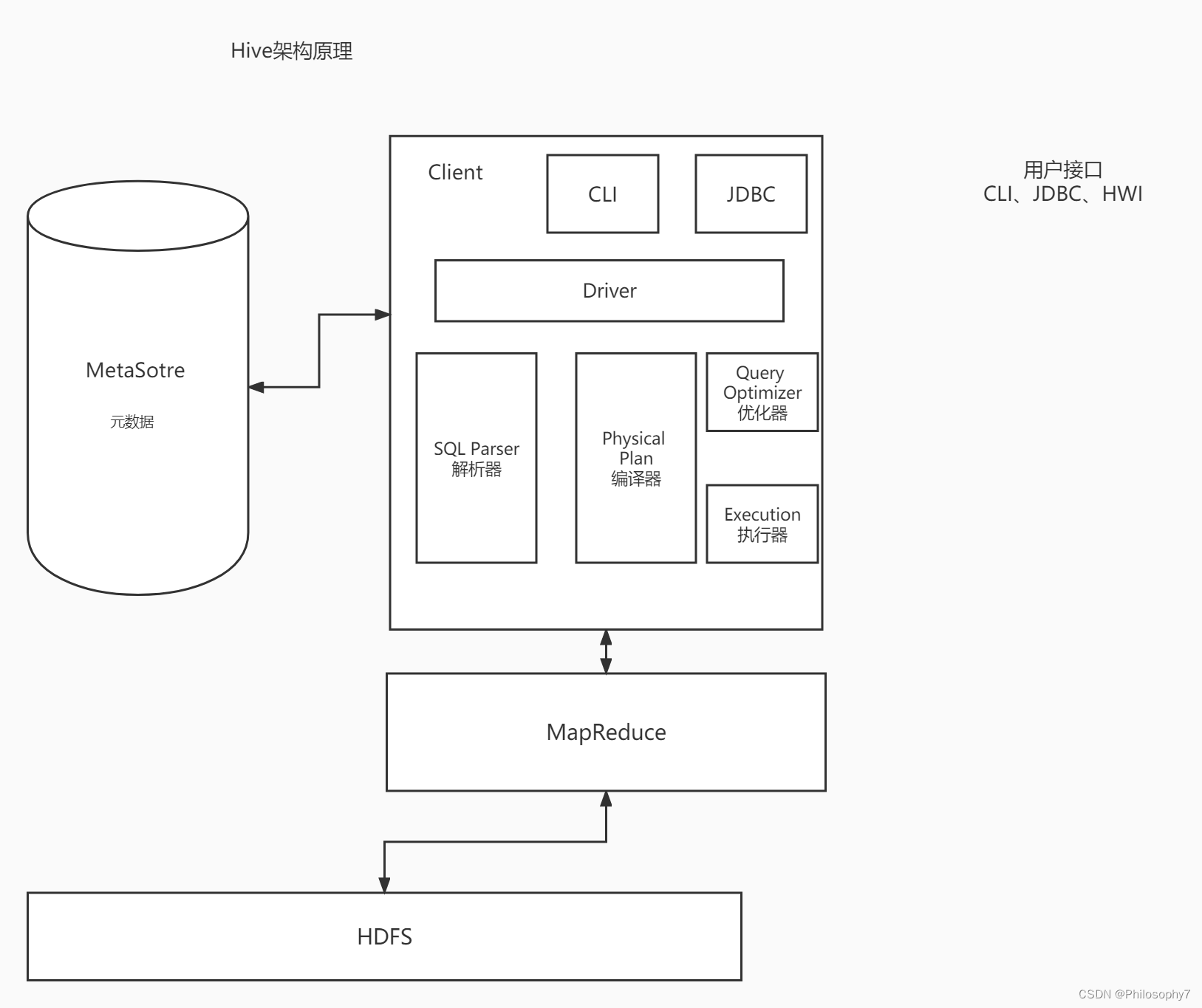
Hive架构
Hive用户接口
- Hive CLI(Hive Command Line) Hive的命令行
- HWI(Hive Web Interface) HiveWeb接口
- Hive提供了Thrift服务,也就是Hiveserver。
Hive元数据的三种存储模式
- 单用户模式 : Hive安装时,默认使用的是Derby数据库存储元数据,这样不能并发调用Hive。
- 多用户模式 : MySQL服务器存储元数据
- 远程服务器模式 : 启动MetaStoreServer
Hive数据存储
Hive数据可区分为表数据和元数据,表数据我们都知道是表中的数据,而元数据是用来存储表的名字、列、表分区以及属性
Hive是基于Hadoop分布式文件存储的,它的数据存储在HDFS中。现在我们介绍Hive中常见的数据导入方式
- 本地文件系统中导入数据到Hive
- 从HDFS上导入数据到Hive表
- 从其他表中查询出相应的数据并导入Hive表中
- 在创建表的时候通过从其他表中查询出相应的记录并插入到所创建的表中
#1.演示从本地装载数据到hive#1.1创建表create table student(id string, name string) row format delimited fields terminated by '\t';#1.2加载本地的文件到hive load data local inpath '/root/student.txt' into table default.student; #default.test 数据库.表名 也可直接表名#2.演示加载HDFS文件到hive中#2.1 将文件上传到HDFS根目录dfs -put /root/student.txt /;#2.2加载HDFS上的数据load data inpath '/student.txt' into table test.student;#3.加载数据覆盖表中原有的数据#3.1上传文件到HDFS中dfs -put /root/student.txt /; #将文件装载到表下 文件就相当于Windows中的剪切操作#3.2加载数据覆盖表中原有数据load data inpath '/student.txt' overwrite into table test.student;#4.查询表select * from student;#通过查询语句向表中插入数据(insert)#1.1创建表create table student_par(id int,name String)row format delimited fields terminated by '\t';#1.2通过insert插入数据insert into table student_par values(1,'zhangsan'),(2,'lisi');架构原理
用户接口
CLI(command-line interface)、JDBC/ODBC(jdbc 访问 hive)、WEBUI(浏览器访问 hive)
元数据
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、
表的类型(是否是外部表)、表的数据所在目录等
Hadoop
使用 HDFS 进行存储,使用 MapReduce 进行计算。
驱动器:Driver
(1)解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第
三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL
语义是否有误。
(2)编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来
说,就是 MR/Spark。
Hive文件格式
- TextFile
- 这是默认的文件格式。数据不会压缩处理,磁盘开销大,数据解析开销也大。
- SequenceFile
- 这是HadooAPI提供的一种二进制文件支持,以二进制的形式序列化到文件中。
- RCFile
- 这种格式是行列存储结构的存储方式。
- ORC
- Optimized Row Columnar ORC文件格式是一种Hadoop生态圈中的列式存储格式。
ORC的优势:
- 列示存储,有多种文件压缩方式
- 文件是可分割的。
- 提供了多种索引
- 可以支持复杂的数据结构 比如Map
ORC文件格式是以二进制方式存储的,所以是不可直接读取的。
Hive本质
将HQL转换成MapReduce程序。
- Hive处理的数据存储在HDFS上
- Hive分析数据底层的实现是MapReduce
- 执行程序运行在Yarn上
Hive工作原理
简单来说Hive就是一个查询引擎。当Hive接受到一条SQL语句会执行如下操作:
- 词法分析和语法分析。使用antlr将SQL语句解析成抽象语法树
- 语义分析。从MetaStore中获取元数据信息,解释SQL语句中的表名、列名、数据类型
- 逻辑计划生成。生成逻辑计划得到算子树
- 逻辑计划优化。对算子树进行优化
- 物理计划生成。将逻辑计划生成出的MapReduce任务组成的DAG的物理计划
- 物理计划执行。将DAG发送到Hadoop集群进行执行
- 将查询结果返回。
Hive展现的MapReduce任务设计到组件有:
- 元存储 : 该组件存储了Hive中表的信息,其中包括了表、表的分区、模式、列及其类型、表映射关系等
- 驱动 : 控制HiveQL生命周期的组件
- 查询编辑器
- 执行引擎
- Hive服务器
- 客户端组件 提供命令行接口Hive CLI、Web UI、JDBC驱动等

Hive数据类型
Hive支持两种数据类型,一种原子数据类型、还有一种叫复杂数据类型。
原子数据类型
基本数据类型 类型 描述 示例 TINYINT 1字节有符合整数 1 SMALLINT 2字节有符号整数 1 INT 4字节有符号整数 1 BIGINT 8字节有符号整数 1 FLOAT 4字节单精度浮点数 1.0 DOUBLE 8字节双精度浮点数 1.0 BOOLEAN true/false true STRING 字符串 “hive”,‘hive’
Hive类型中的String数据类型类似于MySQL中的VARCHAR。该类型是一个可变的字符串。
Hive支持数据类型转换,Hive是用Java编写的,所以数据类型转换规则遵循Java :
隐式转换 --> 小转大
强制转换 --> 大传小
Hive复杂数据类型
类型 描述 示例 ARRAY 有序的字段。字符类型必须相同 ARRAY(1,2) MAP 无序的键值对。建的类型必须是原子的,值可以是任何类型。 Map(‘a’,1,‘b’,2) STRUCT 一组命名的字段。字段类型可以不同 STRUCT(‘a’,1,1,0)
来源地址:https://blog.csdn.net/ChengXuTeng/article/details/124842026








