
背景
大数据(BigData)最重要的是数据,没有数据其他的就无从谈起(如今GPT大热,也是得益于海量数据的采集、存储、计算及治理能力的提升)。大数据项目开发的首要任务就是采集海量数据,这就要求我们具备海量数据采集的能力。
在实际工作中,数据一般有两种来源,一种来自日志文件,一种来自数据库。每种数据源的采集技术有很多种,一般使用Flume、Logstash、Filebeat等工具采集日志文件数据,使用Sqoop、Canal、DataX等工具采集数据库中的数据。
然而,前面提到的这些数据采集或集成工具,基本是面向开发者的,要求使用者具备较高的技术能力,使用时我们开发者面对的一般都是命令行、配置文件、接口等,在目标达成的过程中效率较低,稍不留神就可能因一项错误配置导致迁移失败或者数据服务中断。如今,有一款多源异构数据集成工具横空出世,ETLCloud:新一代(智能)全域数据集成平台,兼容主流的数据库、数据仓库、数据湖甚至消息中间件等产品,全面国产化适配,提供可视化的自动化处理流程,用户只需要单击几下即可创建数据处理任务,轻松在多个异构数据源中实现数据同步以及数据清洗传输。
实际生产中,我们曾把MySQL数据的多个关联表通过DataX工具同步到ClickHouse这款OLAP数据库中,最终实现了多表关联的高效查询;这里,就以一个诗词数据库从MySQL到ClickHouse的迁移任务为例,快速体验下ETLCloud社区版实现零代码、可视化、高效数据迁移的使用过程。
数据集说明
MySQL数据库中的库表poetry结构如下,数据量:311828。
CREATE TABLE `poetry` (`id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,`title` VARCHAR(150) NOT NULL COLLATE 'utf8mb4_unicode_ci',`yunlv_rule` TEXT NOT NULL COLLATE 'utf8mb4_unicode_ci',`author_id` INT(10) UNSIGNED NOT NULL,`content` TEXT NOT NULL COLLATE 'utf8mb4_unicode_ci',`dynasty` VARCHAR(10) NOT NULL COMMENT '诗所属朝代(S-宋代, T-唐代)' COLLATE 'utf8mb4_unicode_ci',`author` VARCHAR(150) NOT NULL COLLATE 'utf8mb4_unicode_ci',PRIMARY KEY (`id`) USING BTREE)COLLATE='utf8mb4_unicode_ci'ENGINE=InnoDBAUTO_INCREMENT=311829;
基础环境
数据库服务部署在多云环境下,共涉及到3台云主机,操作系统及配置如下:
- MySQL所在主机(阿里云)
操作系统:Ubuntu16
root@hostname:~# uname -aLinux hostname 4.4.0-62-generic #83-Ubuntu SMP Wed Jan 18 14:10:15 UTC 2017 x86_64 x86_64 x86_64 GNU/Linuxroot@iZuf69c5h89bkzv0aqfm8lZ:~# cat /etc/os-releaseNAME="Ubuntu"VERSION="16.04.2 LTS (Xenial Xerus)"ID=ubuntuID_LIKE=debianPRETTY_NAME="Ubuntu 16.04.2 LTS"VERSION_ID="16.04"…基本配置:2C8G
数据库版本:5.7.22-0ubuntu0.16.04.1
- ClickHouse所在主机(华为云)
操作系统:CentOS 6
[root@ecs-xx-0003 ~]# uname -aLinux ecs-xx-0003 2.6.32-754.15.3.el6.x86_64 #1 SMP Tue Jun 18 16:25:32 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux[root@ecs-xx-0003 ~]# cat /proc/version Linux version 2.6.32-754.15.3.el6.x86_64 (mockbuild@x86-01.bsys.centos.org) (gcc version 4.4.7 20120313 (Red Hat 4.4.7-23) (GCC) ) #1 SMP Tue Jun 18 16:25:32 UTC 2019基本配置:4C8G
数据库版本:19.9.5.36
[root@ecs-xx-0003 clickhouse-server]# clickhouse-server --versionClickHouse server version 19.9.5.36.- ETLCloud所在主机(腾讯云)
操作系统:CentOS 7
基本配置:2C2G
Note:这里选择的是ETLCloud社区版,采用Docker部署的方式轻量、快速启动;作为入门体验,ETLCloud所在的主机配置较低,实际生产建议提升主机配置。
迁移实践
接下来,进入我们的迁移实践:全程零代码、可视化、拖拉拽,鼠标点一点即可完成从MySQL到ClickHouse的诗词数据快速复制操作。
数据源配置
配置我们的数据源之前,我们先看下ETLCloud社区版目前已经支持的数据源列表。

- 配置Source:MySQL
我直接在左侧提供的数据源上改了一个MySQL的,填写IP: 端口以及用户密码信息。
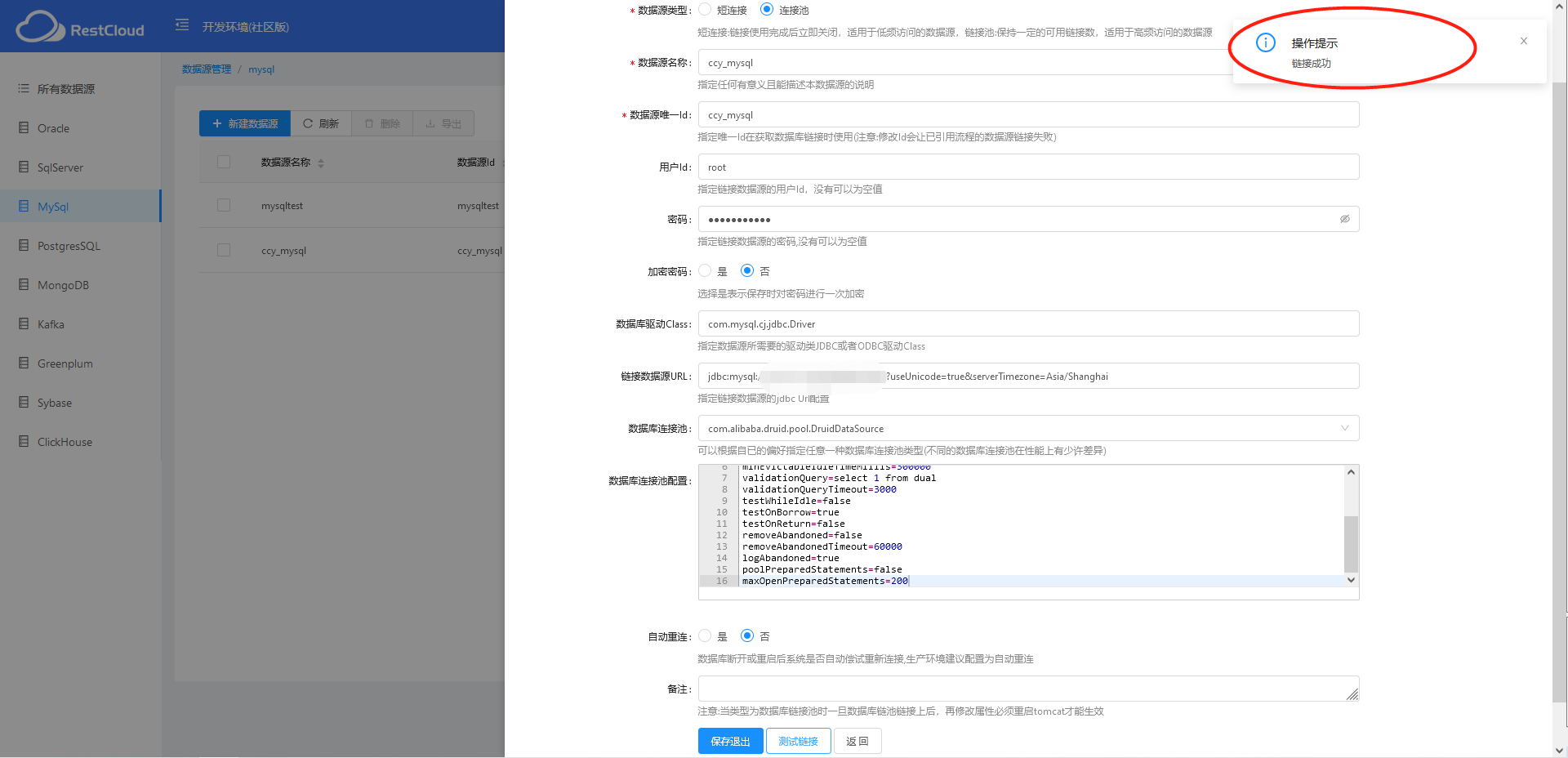
测试连接成功~
- 配置Sink:ClickHouse
我直接在左侧提供的数据源上改了一个ClickHouse的,填写IP: 端口以及用户密码信息。
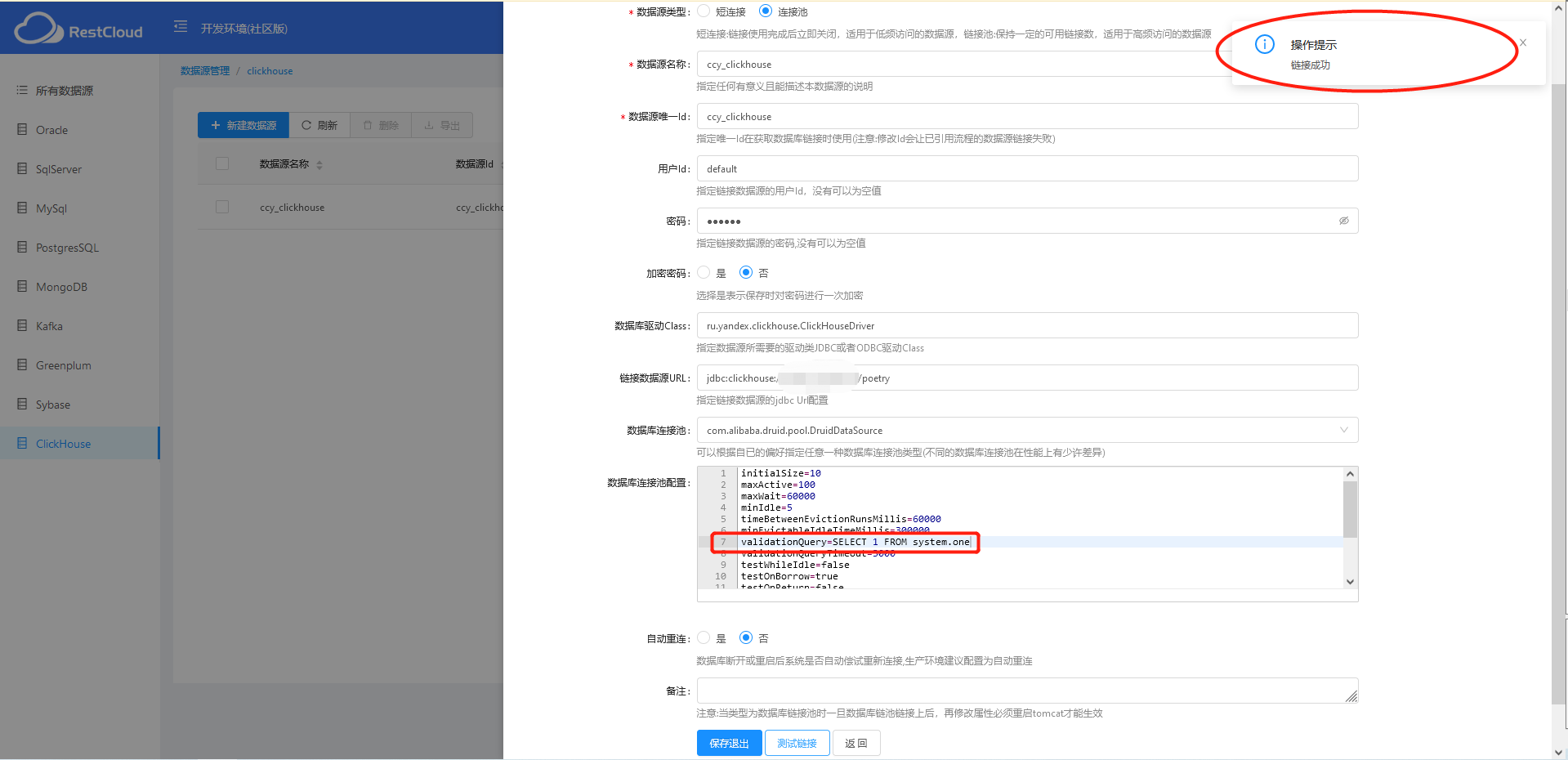
测试连接成功~
创建应用与流程
创建应用,填写基本的应用配置信息(注意应用的ID唯一不可变)。

接着,创建数据流程,填写信息即可。
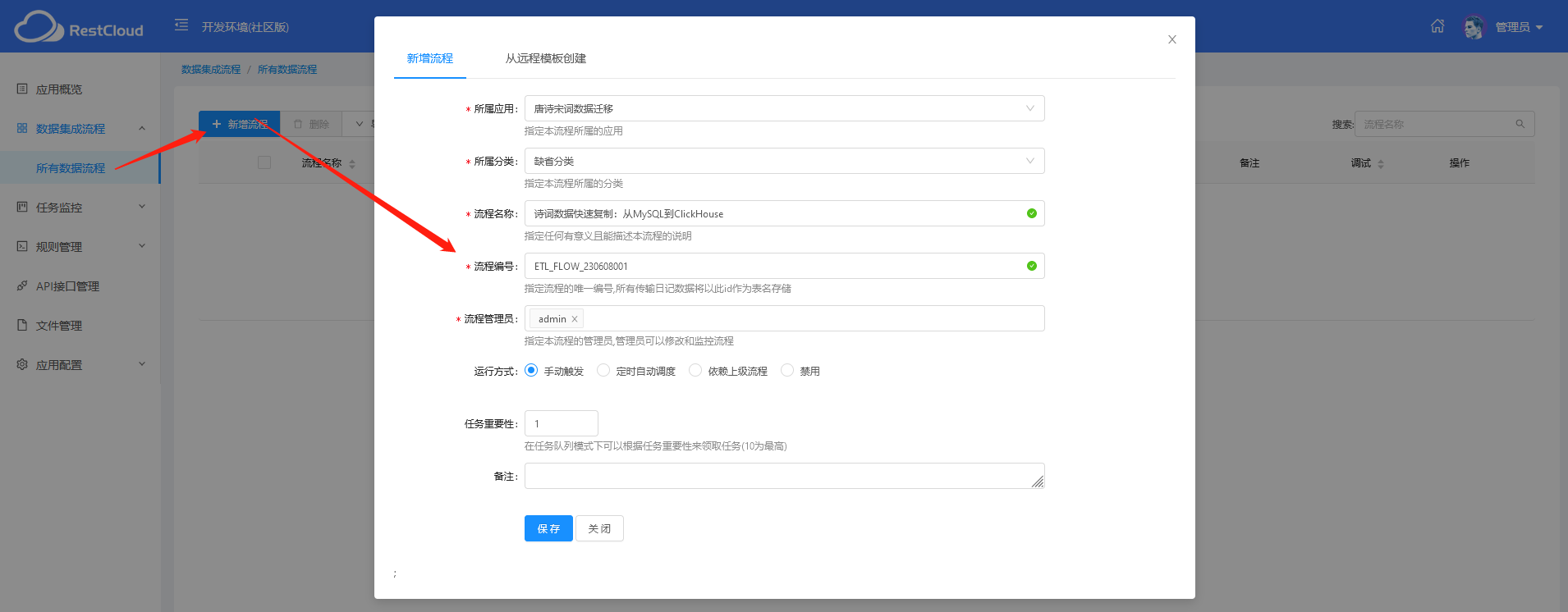
创建好流程后,可以通过点击“流程设计”按钮,进入流程可视化的配置页面。

可视化配置流程
在配置流程前,简单介绍下这个配置页面的各个区:左侧是组件区,中间顶部是功能区,中间的大部分为流程绘制区,双击绘制区的组件,可以看到以抽屉风格弹出的组件详细配置项区。
- 库表输入:MySQL
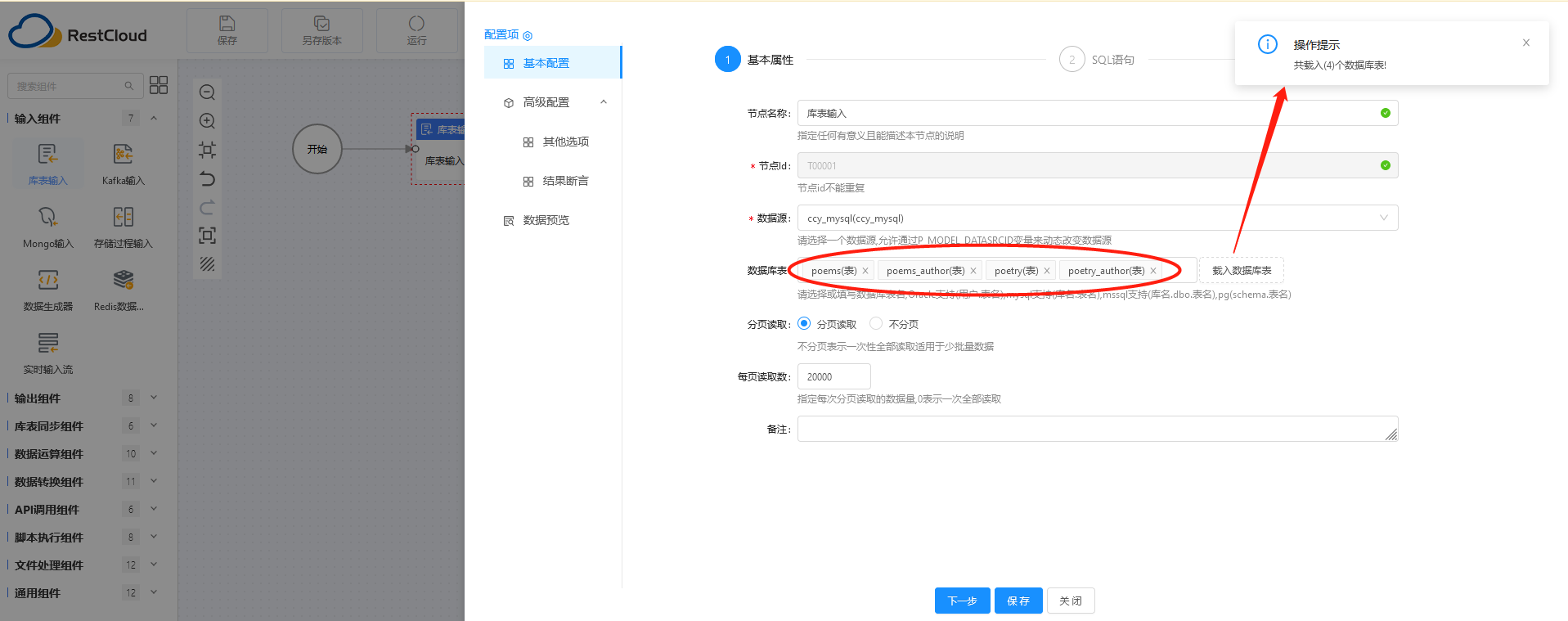
在左侧的输入组件中,选择“库表输入”,拖至中央的流程绘制区,双击进入配置阶段。
选择我们配置好的MySQL数据源,可以载入MySQL中已有的表。
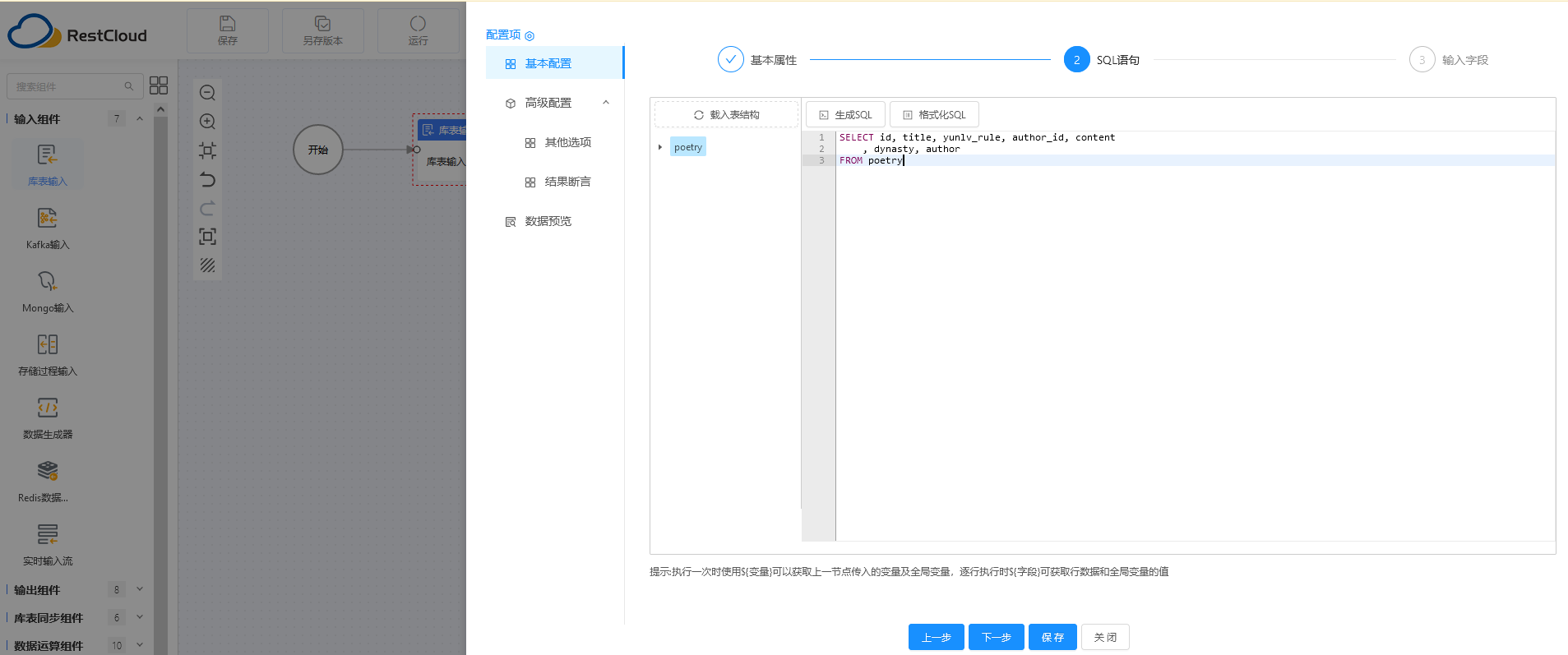
第二步:可以根据选择的表,生成SQL语句(这里其实可以联合多个表查询后形成一个大宽表)。
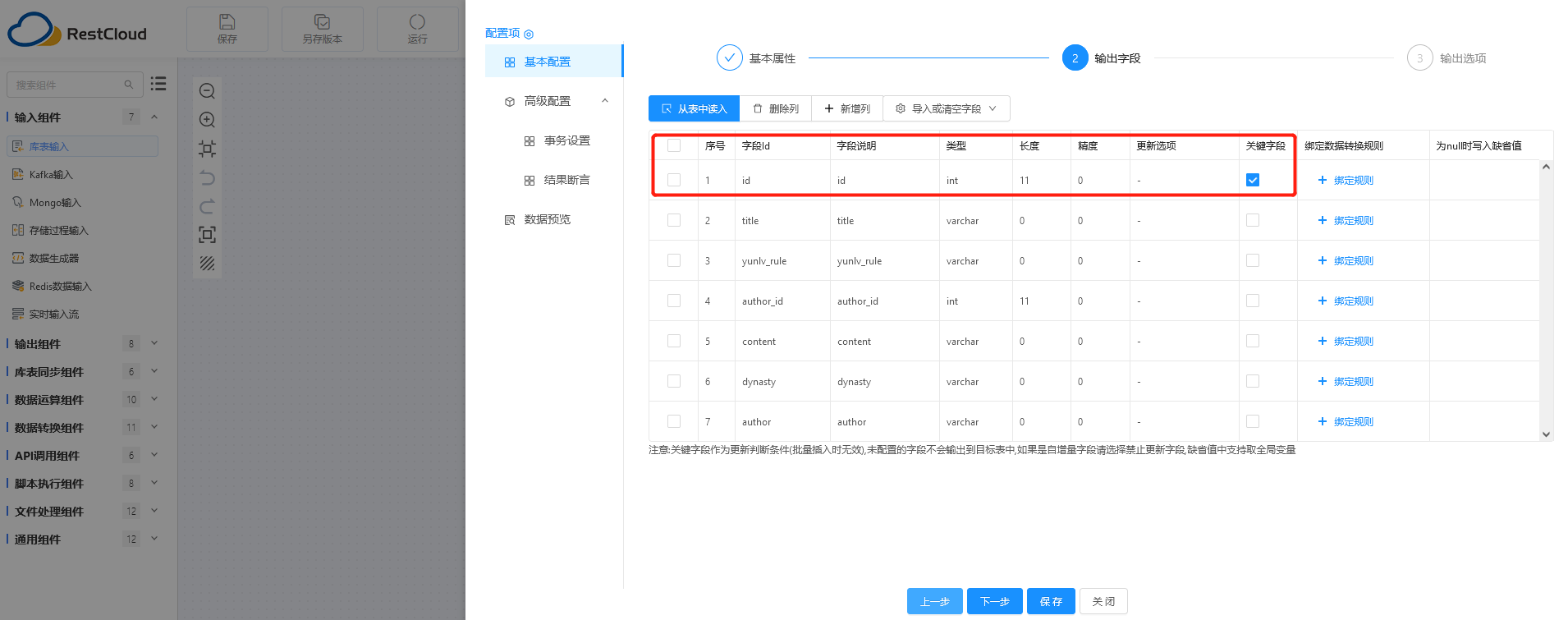
第三步:可从表中读取到各个字段的定义,支持添加、删除字段。

第四步:根据SQL语句自动进行了数据预览,这样的一个检查操作,保证了后续操作的正常执行。

最后:在第三步中,可以对不同的字段应用一些转换规则来实现数据的预处理与清洗操作,ETLCloud内置了不少常用的规则。

- 库表输出:ClickHouse
在左侧的输出组件中,选择“库表输出”,拖至中央的流程绘制区,双击进入配置阶段。
选择我们配置好的ClickHouse数据源,由于刚开始ClickHouse中没有对应的表,这里先手动输入表名,在第三步中可以选择自动建表(将表结构自动从MySQL映射至ClickHouse,赞~)一开始我不知道是否可以自动建表,先通过ETLCloud中的另一个库表同步组件实现了表结构同步。
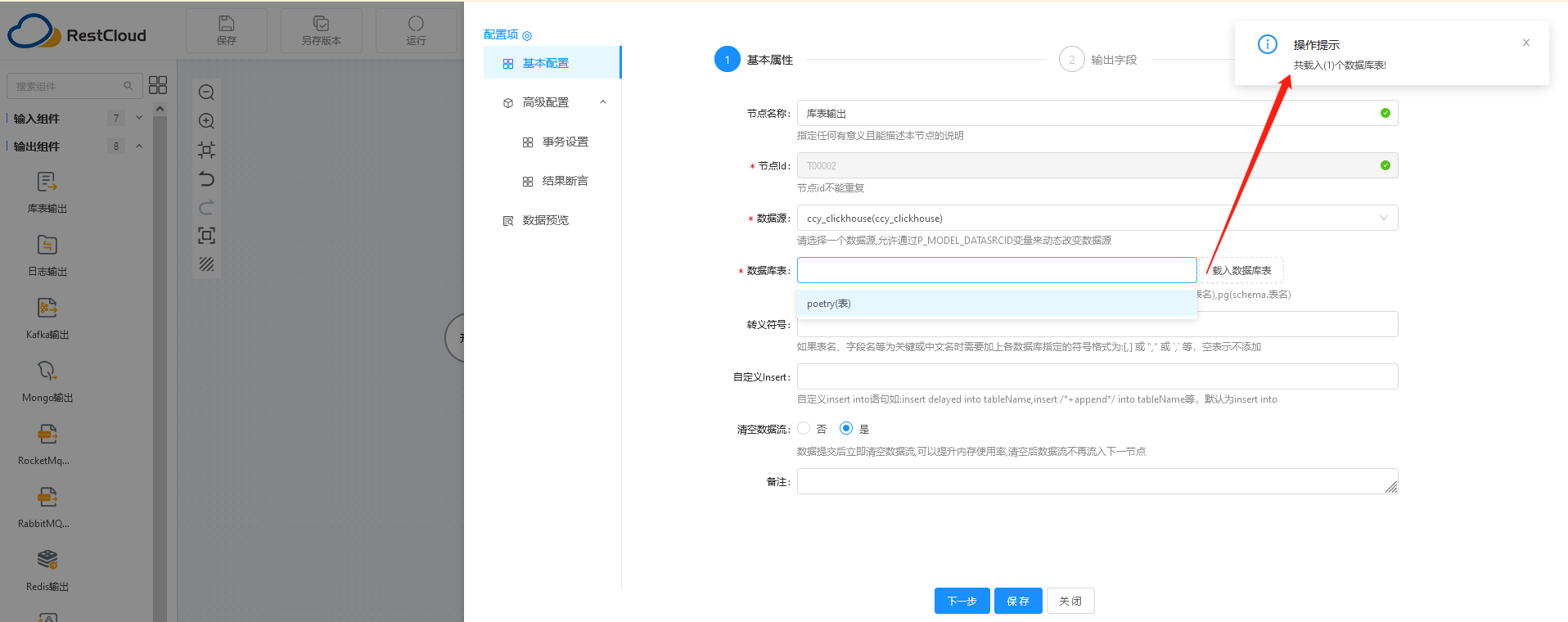
第二步:可从表中读取到各个字段的定义,支持添加、删除字段、绑定规则。
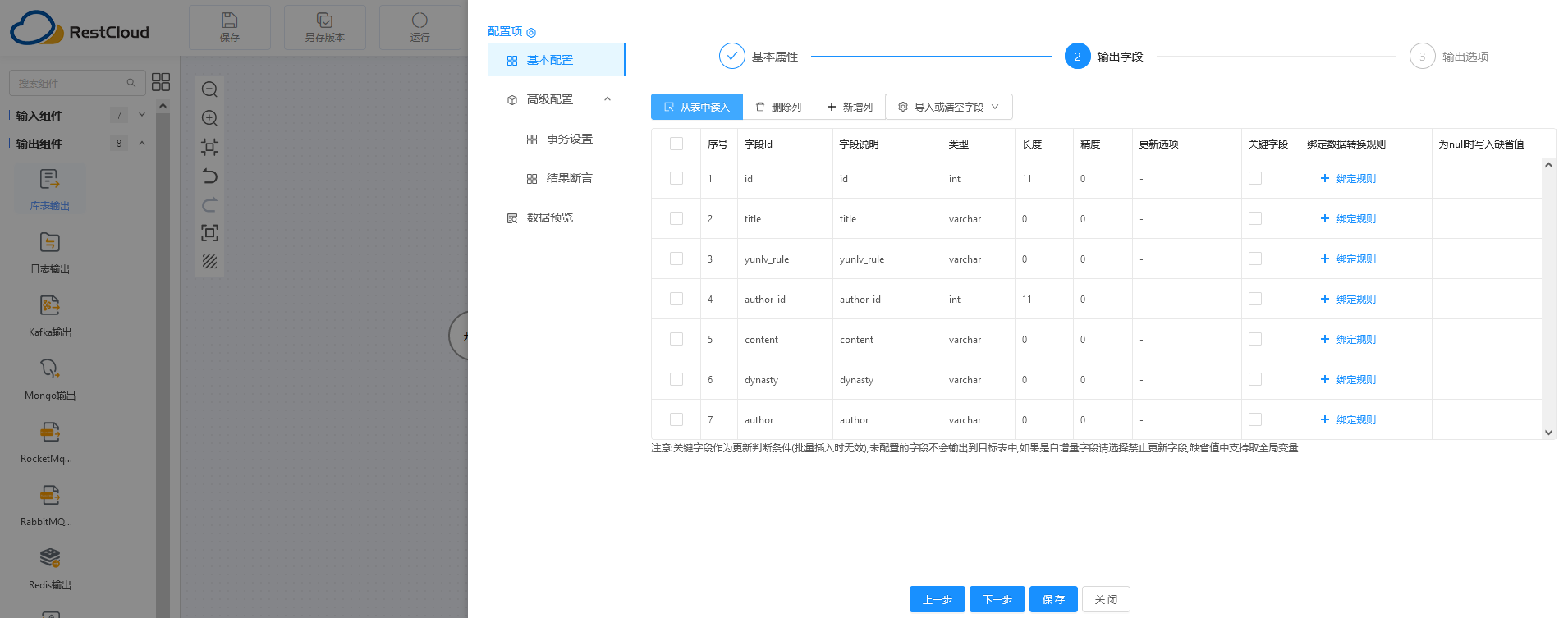
第三步:配置下输出选项:是否清空表数据、是否自动建表等。
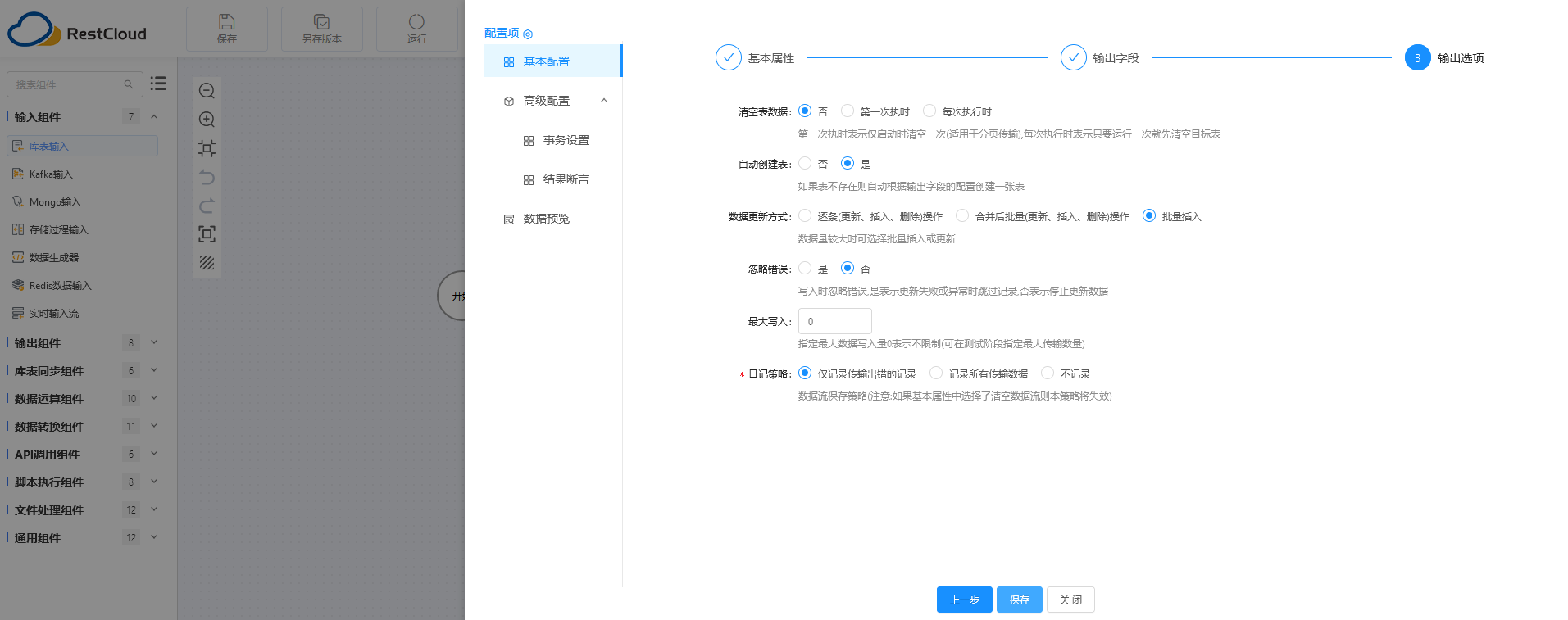
最后通过 流程线 将开始、库表输入、库表输出、结束组件分别连接起来,数据迁移的可视化配置便告完成,Done~
问题记录
- ClickHouse数据源使用连接池方式时报错
问题描述:DB:: Exception: Table helloworld.dual doesn’t exist. (version 19.9.5.36) )
问题分析:ClickHouse中没有dual虚拟表,它的虚拟表是system.one
解决方法:validationQuery=SELECT 1 FROM system.one
- 在ClickHouse输出这边没有配置主键,导致数据抽取流程失败
问题描述:在ClickHouse输出这边没有配置主键,导致数据抽取流程失败。
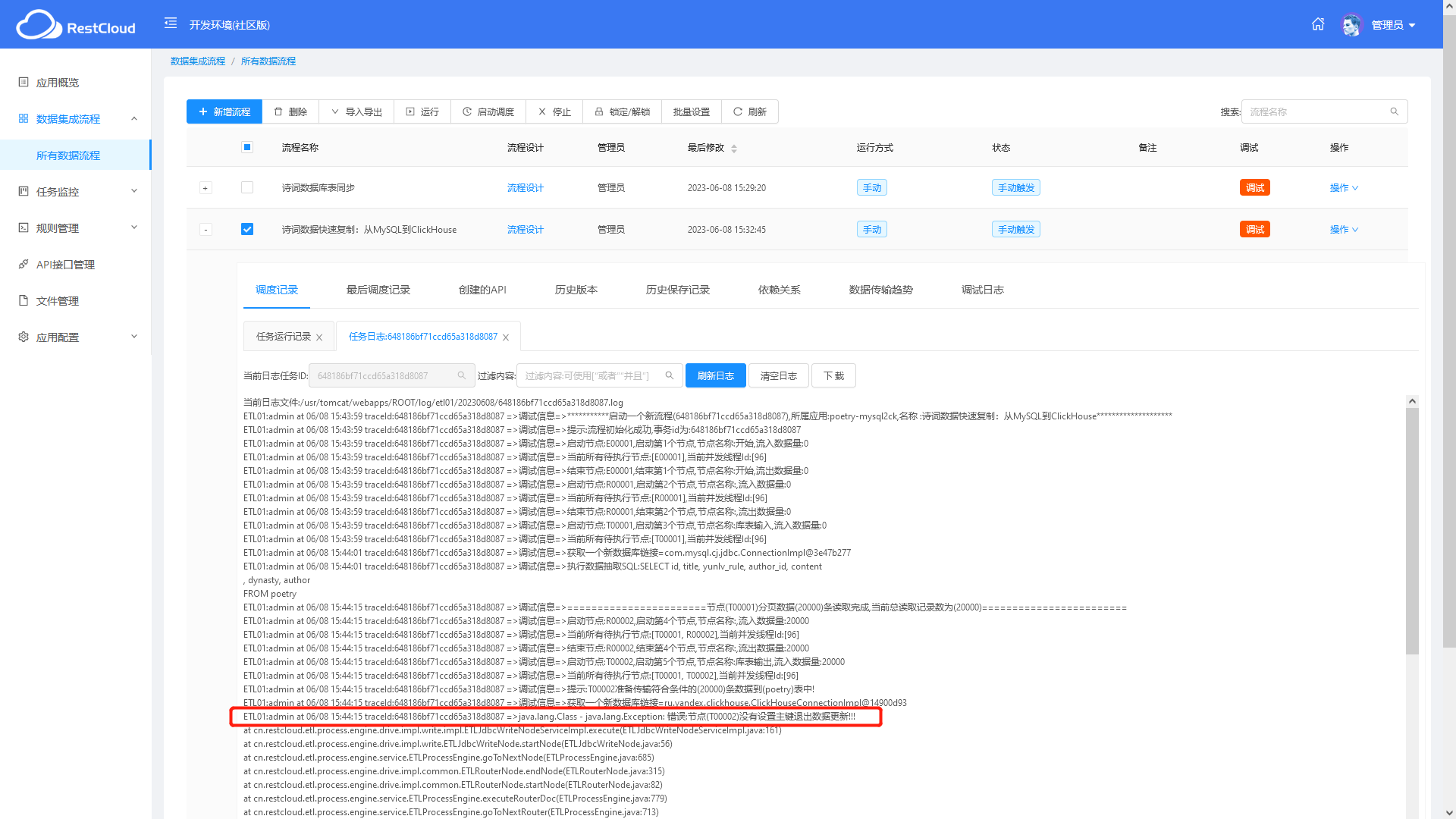
解决方法:库表输出:ClickHouse的第二步,指定表的主键。
总结
以上就是入门级的ETLCloud数据迁移实践,以零代码、可视化、拖拉拽的方式快速完成从MySQL到ClickHouse的数据迁移,在整个实践过程中,最大的感受除了高效完成迁移目标外,还有这么几个点:傻瓜式、可视化、详细的日志、动态的流程监控以及丰富的文档说明。这款异构数据集成的利器,值得一试。
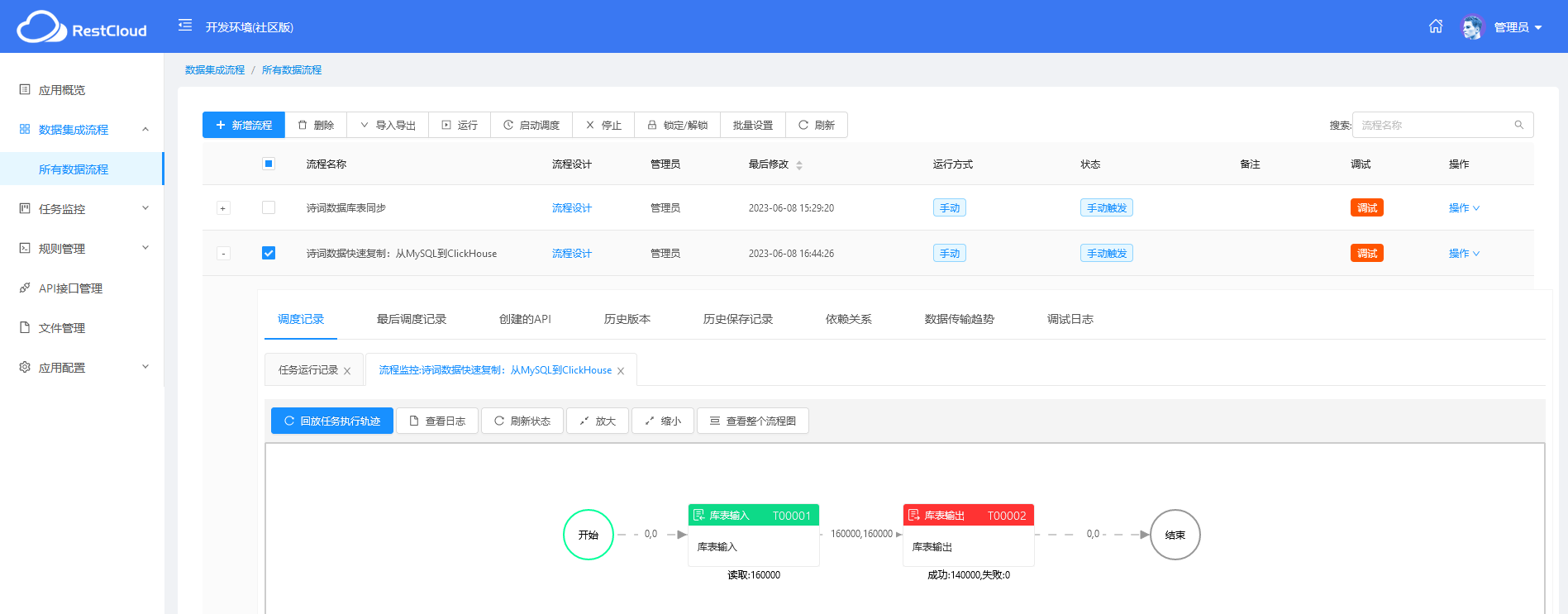
任务监控看板,全局把控。

动态监控数据同步进度,一目了然。
Reference
If you have any questions or any bugs are found, please feel free to contact me.
Your comments and suggestions are welcome!
来源地址:https://blog.csdn.net/u013810234/article/details/131150450







