
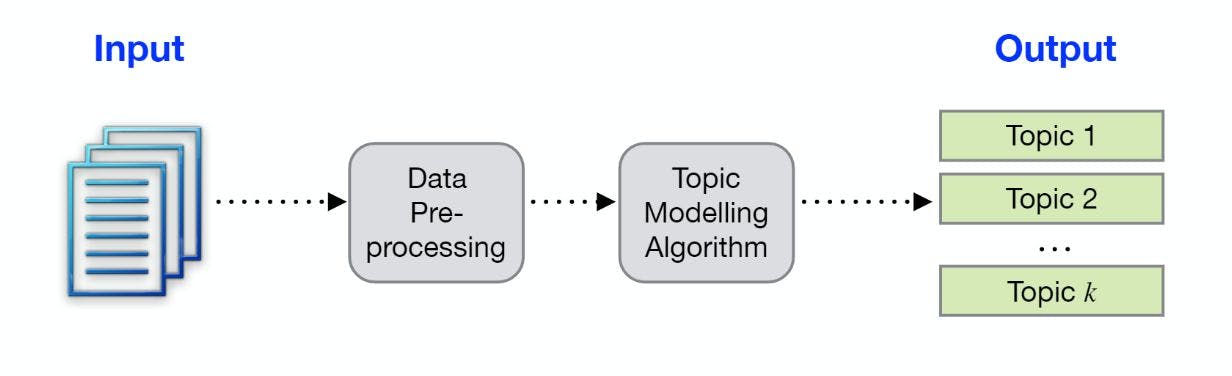
执行主题建模有不同的技术(如LDA),但是在本NLP教程中,你将学习如何使用Maarten Grootendorst开发的BerTopic技术。
什么是 BerTopic?
BerTopic是一种主题建模技术,它使用转换器(BERT嵌入)和基于类的TF-IDF来创建密集集群。它还允许您轻松地解释和可视化生成的主题。
BerTopic算法包含三个阶段:
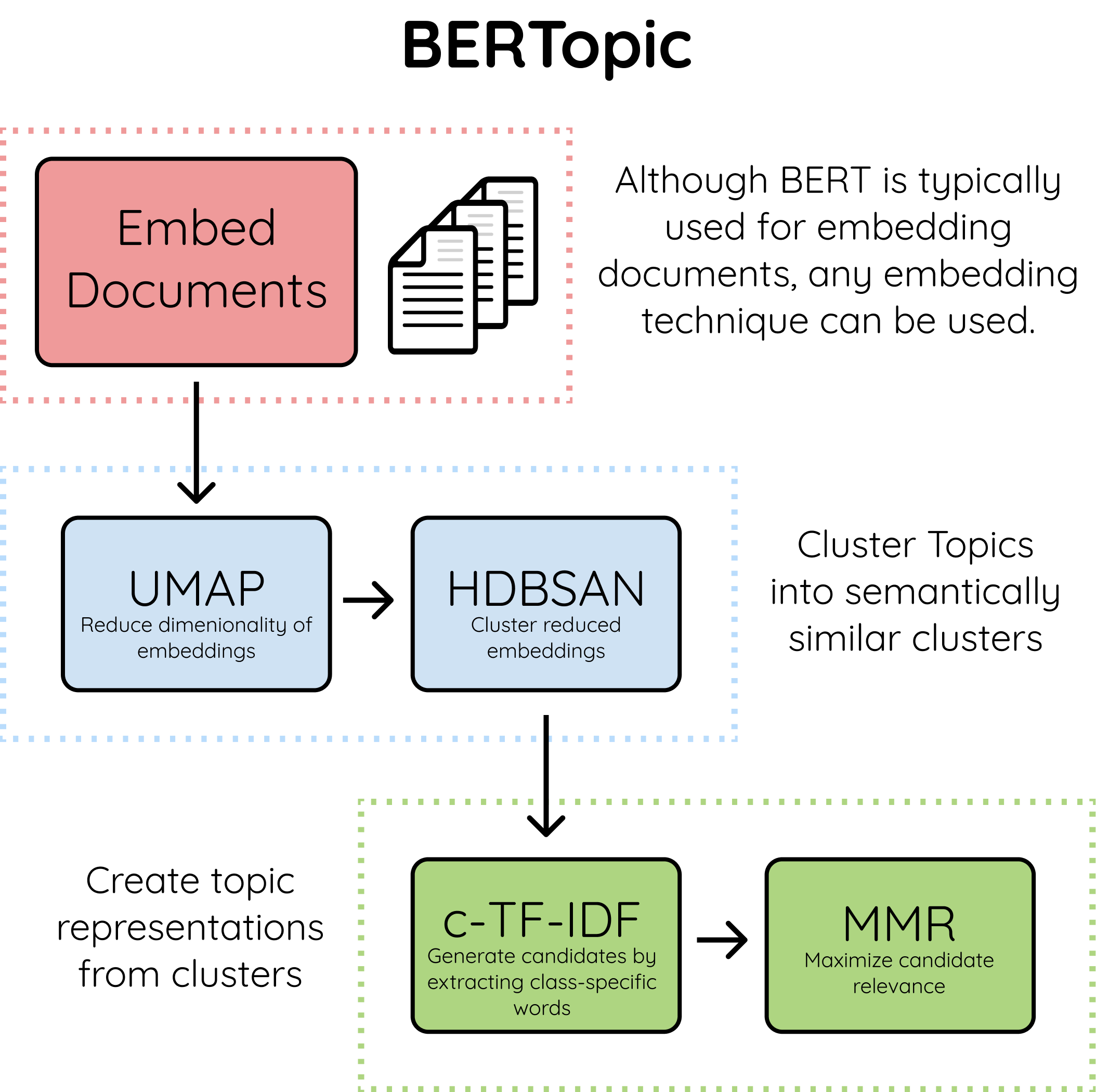
1.嵌入文本数据(文档):此步骤中,算法使用BERT提取文档嵌入,也可以使用其他任何嵌入技术。
默认情况下,它使用下面的句子转换器
- “ paraphrase-MiniLM-L6-v2” - 这是一个基于英语 BERT 的模型,专门针对语义相似性任务进行训练。
- “ paraphrase-multilingual-MiniLM-L12-v2 ” - 这与第一个类似,一个主要区别是 xlm 模型适用于 50 多种语言。
2.Cluster文档:使用UMAP降低嵌入的维数,使用HDBSCAN技术聚类减少嵌入并创建语义相似文档的聚类。
3.创建主题表示:利用基于类的TF-IDF进行主题提取和精简,提高最大边缘关联词的一致性。
如何安装 BerTopic
可以通过 pip 安装软件包:
pip install bertopic如果你对可视化选项感兴趣,你需要按照如下方式安装它们。
pip install bertopic[visualization]BerTopic支持不同的转换器和语言后端,你可以使用它们来创建模型。你可以根据下面可用的选项安装一个。
- pip install bertopic[天赋]
- pip install bertopic[gensim]
- pip install bertopic[spacy]
- pip install bertopic[使用]
库
我们将使用以下库来帮助我们加载数据并从BerTopic创建模型。
#import packages
import pandas as pd
import numpy as np
from bertopic import BERTopic步骤1:加载数据
在本NLP教程中,我们将使用2020年东京奥运会推文,目标是创建一个模型,该模型可以根据推文的主题自动分类。
#load data
import pandas as pd
df = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/data/tokyo_2020_tweets.csv", engine='python')
# select only 6000 tweets
dfdf = df[0:6000]注:出于计算原因,我们只选择了6000条推文。
步骤2:创建模型
要使用BERTopic创建模型,需要将推文作为列表加载,然后将其传递给fit_transform方法。这个方法将做以下工作:
- 在推文集合上拟合模型;
- 生成话题;
- 返回带有主题的推文。
# create model
model = BERTopic(verbose=True)
#convert to list
docs = df.text.to_list()
topics, probabilities = model.fit_transform(docs)步骤3:选择高级主题
训练模型后,可以按降序访问主题的大小。
model.get_topic_freq().head(11)注:Topic -1是最大的,它指的是没有分配给生成的任何主题的离群推文。在本例中,我们将忽略Topic -1。
步骤4:选择一个主题
你可以选择一个特定的主题,并得到该主题的前n个单词和他们的c-TF-IDF分数。
model.get_topic(6)对于这个选定的话题,常用词是瑞典,目标,罗尔夫,瑞典人,目标,足球。很明显,这个话题的重点是“瑞典队的足球”。
步骤5:主题建模可视化
BerTopic允许您以非常类似于LDAvis的方式可视化生成的主题。这会让你对主题的质量有更多的了解。在本文中,我们将介绍三种可视化主题的方法。
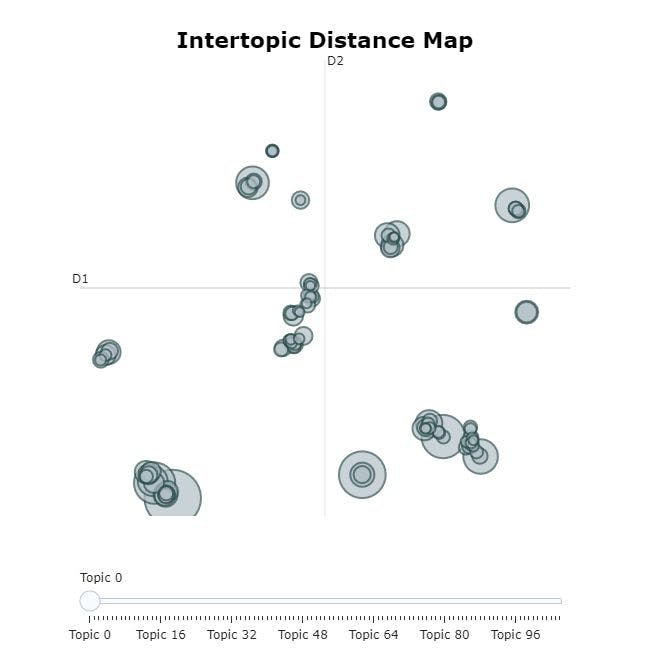
可视化的话题
visualize_topics方法可以帮助您可视化生成的主题及其大小和相应的单词。视觉化的灵感来自于LDavis。
model.visualize_topics()可视化术语
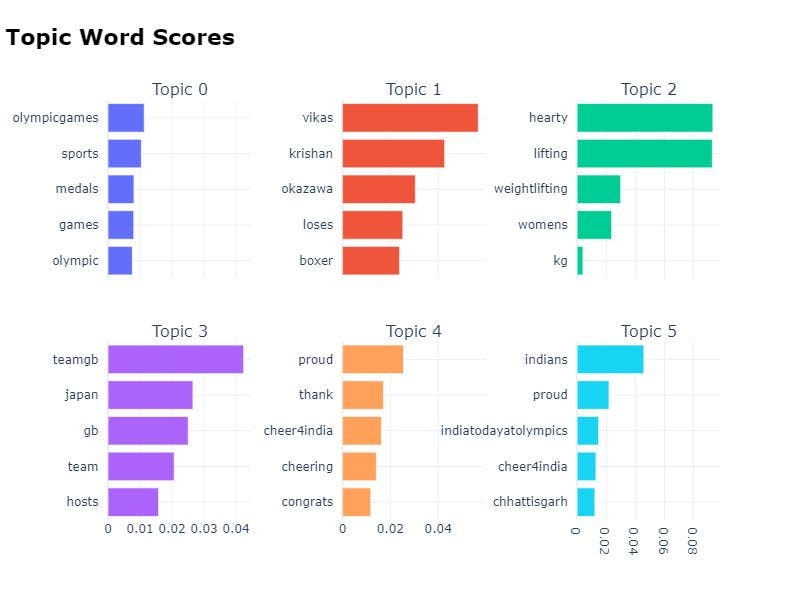
visualize_barchart方法将通过创建c-TF-IDF分数的条形图来显示选定的几个主题术语。然后,您可以比较彼此的主题表示,并从生成的主题中获得更多的见解。
model.visualize_barchart()上面的图表中,你可以看到话题4的热门词是proud, thank, cheer4india, cheer和congrats。
可视化主题相似性
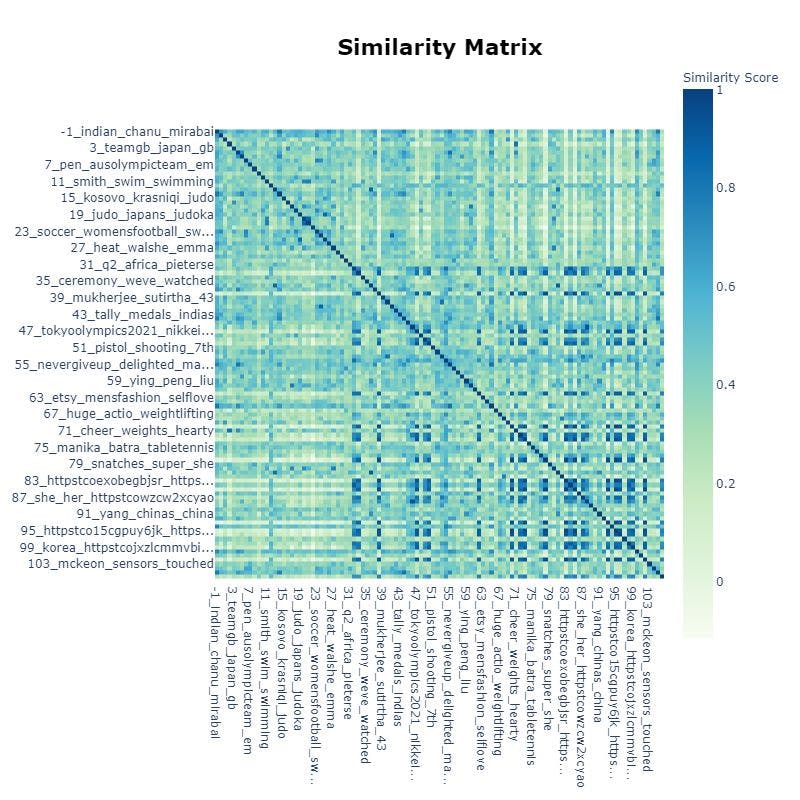
你还可以可视化某些主题之间的相似程度。要可视化热图,只需调用。
model.visualize_heatmap()在上图中,你可以看到topic 93与topic 102相似,相似度为0.933。
主题减少
有时您可能会生成过多或过少的主题,BerTopic为您提供了一种选择,以不同的方式控制这种行为。
(a)你可以通过设置参数nr_topics来设置你想要的主题数量。BerTopic将找到类似的主题并合并它们。
model = BERTopic(nr_topics=20)在上面的代码中,将要生成的主题的数量是20。
(b)另一种选择是自动减少专题的数目。要使用这个选项,你需要在训练模型之前将"nr_topics"设置为"auto"。
model = BERTopic(nr_topics="auto")(c)最后一种选择是减少模型训练后的主题数量。这是一个很好的选择,如果重新培训模型将花费许多小时。
new_topics, new_probs = model.reduce_topics(docs, topics, probabilities, nr_topics=15)在上面的示例中,在训练模型之后,您将主题的数量减少到15个。
步骤6:做出预测
要预测新文档的主题,需要在转换方法上添加一个(或多个)新实例。
topics, probs = model.transform(new_docs)步骤7:保存模型
你以使用save方法保存训练过的模型。
model.save("my_topics_model")步骤8:加载模型
你可以使用load方法来加载模型。
BerTopic_model = BERTopic.load("my_topics_model")最后
在创建模型时,BerTopic提供了许多特性。例如,如果您有一个特定语言的数据集(默认情况下,它支持英语模型),您可以通过在配置模型时设置语言参数来选择语言。
model = BERTopic(language="German")注意:请选择其嵌入模型存在的语言。
如果你的文档中混合了多种语言,你可以设置language="multilingual"以支持超过50种语言。
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}