
大家好,方差分析可以用来判断几组观察到的数据或者处理的结果是否存在显著差异。本文介绍的方差分析(Analysis of Variance,简称ANOVA)就是用于检验两组或者两组以上样本的均值是否具备显著性差异的一种数理统计方法。
根据影响试验条件的因素个数可以将方差分析分为:单因素方差分析、双因素方差分析、多因素方差分析;双因素方差分析则是分析两个因素对试验指标的影响;多因素方差分析则是分析更多因素指标的分析方法。本文是以不同城市的月薪收入在每个月的水平上是否存在差异就是多组数据是否存在差异的示例:
一、单因素方差分析
单因素方差分析只考虑单一因素对试验指标的影响是否显著:
import pandas as pdfrom statsmodels.formula.api import olsfrom statsmodels.stats.anova import anova_lmdata= pd.read_excel('D:/shujufenxi/jpt.xlsx',index_col=0)# 先来看下从城市因素开始分析,df_city=data.melt(var_name='城市',value_name='月薪')#使用melt()函数将读取数据进行结构转换,以满足ols()函数对数据格式的要求,melt()函数能将列标签转换为列数据

使用melt()函数对数据结构,并可视化,我们可以以肉眼观察出差异性明显:
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['KaiTi', 'SimHei', 'FangSong'] # 汉字字体,优先使用楷体,如果找不到楷体,则使用黑体plt.rcParams['font.size'] = 12 # 字体大小plt.rcParams['axes.unicode_minus'] = False # 正常显示负号import pandas as pdimport seaborn as snsdata= pd.read_excel('D:/shujufenxi/jpt.xlsx',index_col=0)data_melt = data.melt()data_melt.columns = ['城市', '月薪']sns.boxplot(x = '城市', y = '月薪', data = data_melt)plt.show()
进行方差分析:
import pandas as pdfrom statsmodels.stats.multicomp import pairwise_tukeyhsdfrom statsmodels.formula.api import olsfrom statsmodels.stats.anova import anova_lmdata= pd.read_excel('D:/shujufenxi/jpt.xlsx',index_col=0)# 先来看下从城市因素开始分析,df_city=data.melt(var_name='城市',value_name='月薪')#使用melt()函数将读取数据进行结构转换,以满足ols()函数对数据格式的要求,melt()函数能将列标签转换为列数据model_city=ols('月薪~C(城市)',df_city).fit()# ols()创建一线性回归分析模型anova_table=anova_lm(model_city)# anova_lm()函数创建模型生成方差分析表print(anova_table)# 进行事后比较分析print(pairwise_tukeyhsd(df_city['月薪'], df_city['城市']))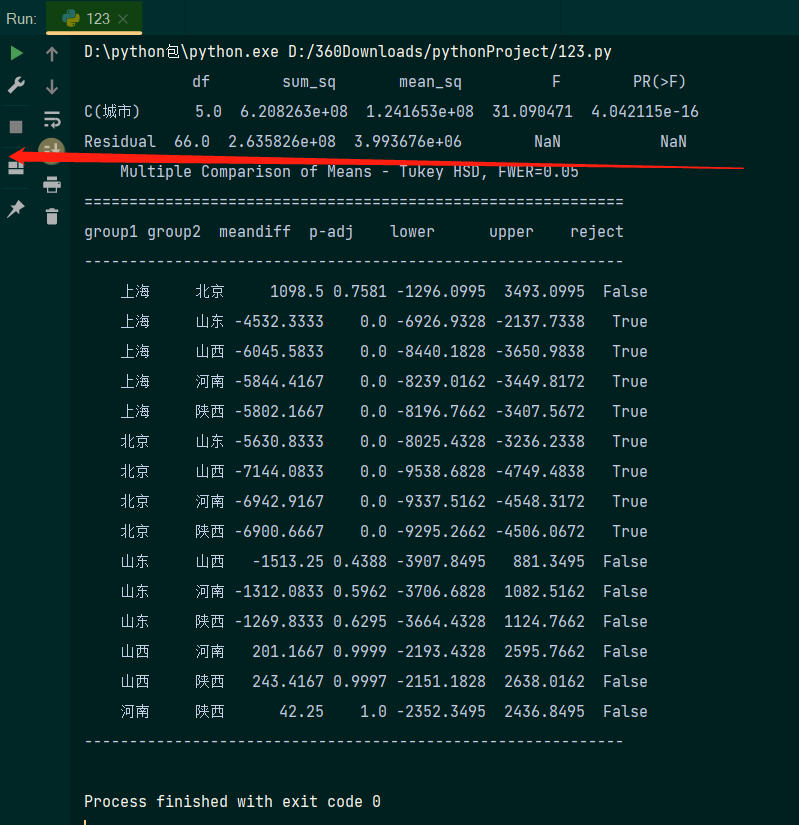
在结果图上半部分中df为自由度,sum_sq为误差平方和,mean_sq为平均平方,F代表统计量F值,PR(>F)代表显著性水平P值;下半部分为多重比较,进行事后分析,group1以及group2表示的是因子的不同水平,然后分析他们两个组是否有显著性差异,最后面的reject表示是否拒绝原假设,True表示的是拒绝原假设,说明两组均值有显著性差异。
二、双因素方差分析
双因素方差分析对数据结构的要求和单因素方差分析不同,代码如下:
import pandas as pdfrom statsmodels.stats.multicomp import pairwise_tukeyhsdfrom statsmodels.formula.api import olsfrom statsmodels.stats.anova import anova_lmdata= pd.read_excel('D:/shujufenxi/jpt.xlsx',index_col=0)df_twoway=data.stack().reset_index()df_twoway.columns=['月份','城市','月薪']model_twoway=ols('月薪~C(月份)+C(城市)',df_twoway).fit()anova_table=anova_lm(model_twoway)print(anova_table
来源地址:https://blog.csdn.net/csdn1561168266/article/details/129216380









