
这篇文章主要介绍“Node.js模块查找,引用及缓存机制是什么”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“Node.js模块查找,引用及缓存机制是什么”文章能帮助大家解决问题。
1. Node.js的模块载入方式与机制
Node.js中模块可以通过文件路径或名字获取模块的引用。模块的引用会映射到一个js文件路径,除非它是一个Node内置模块。Node的内置模块公开了一些常用的API给开发者,并且它们在Node进程开始的时候就预加载了。
其它的如通过NPM安装的第三方模块(third-party modules)或本地模块(local modules),每个模块都会暴露一个公开的API。以便开发者可以导入。如
var mod = require('module_name')
此句执行后,Node内部会载入内置模块或通过NPM安装的模块。require函数会返回一个对象,该对象公开的API可能是函数,对象,或者属性如函数,数组,甚至任意类型的JS对象。
这里列下node模块的载入及缓存机制
载入内置模块(A Core Module)
载入文件模块(A File Module)
载入文件目录模块(A Folder Module)
载入node_modules里的模块
自动缓存已载入模块
一、载入内置模块
Node的内置模块被编译为二进制形式,引用时直接使用名字而非文件路径。当第三方的模块和内置模块同名时,内置模块将覆盖第三方同名模块。因此命名时需要注意不要和内置模块同名。如获取一个http模块
var http = require('http')
返回的http即是实现了HTTP功能Node的内置模块。
二、载入文件模块
绝对路径的
var myMod = require('/home/base/my_mod')
或相对路径的
var myMod = require('./my_mod')
注意,这里忽略了扩展名“.js”,以下是对等的
var myMod = require('./my_mod') var myMod = require('./my_mod.js')三、载入文件目录模块
可以直接require一个目录,假设有一个目录名为folder,如
var myMod = require('./folder')
此 时,Node将搜索整个folder目录,Node会假设folder为一个包并试图找到包定义文件package.json。如果folder 目录里没有包含package.json文件,Node会假设默认主文件为index.js,即会加载index.js。如果index.js也不存在, 那么加载将失败。
假如目录结构如下

package.json定义如下
{ "name": "pack", "main": "modA.js"}此时 require('./folder') 将返回模块modA.js。如果package.json不存在,那么将返回模块index.js。如果index.js也不存在,那么将发生载入异常。
四、载入node_modules里的模块
如果模块名不是路径,也不是内置模块,Node将试图去当前目录的node_modules文件夹里搜索。如果当前目录的node_modules里没有找到,Node会从父目录的node_modules里搜索,这样递归下去直到根目录。
不必担心,npm命令可让我们很方便的去安装,卸载,更新node_modules目录。
五、自动缓存已载入模块
对于已加载的模块Node会缓存下来,而不必每次都重新搜索。下面是一个示例
modA.js
console.log('模块modA开始加载...') exports = function() { console.log('Hi') } console.log('模块modA加载完毕')init.js
var mod1 = require('./modA') var mod2 = require('./modA') console.log(mod1 === mod2)命令行执行:
node init.js
输入如下

可以看到虽然require了两次,但modA.js仍然只执行了一次。mod1和mod2是相同的,即两个引用都指向了同一个模块对象。
2. nodejs 模块查找
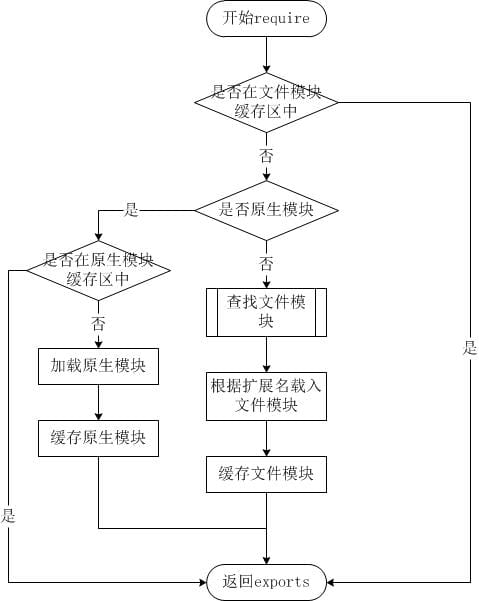
nodejs在加载外部自定义模块时对模块有查找顺序,找到后还会进行缓存。
查找顺序:
相对路径,比如提供./ 或者../这种以'./'和‘..’开始的路径,简单的,就是相对当前位置的路径。
绝对路径,这时候将按以下顺序查找:
在 进入路径查找之前有必要描述一下module path这个Node.js中的概念。对于每一个被加载的文件模块,创建这个模块对象的时候,这个模块便会有一个paths属性,其值根据当前文件的路径 计算得到。我们创建modulepath.js这样一个文件,其内容为:
console.log(module.paths);我们将其放到任意一个目录中执行node modulepath.js命令,将得到以下的输出结果。
[ '/home/ikeepstudying/research/node_modules','/home/ikeepstudying/node_modules','/home/node_modules','/node_modules' ]Windows下:
[ 'c:\\nodejs\\node_modules', 'c:\\node_modules' ]然后是['.']
然后是:
windows下%NODE_PATH%,%USERPROFILE%/.node_modules, %USERPROFILE%/.node_libraries
非windows下$NODE_PATH, $HOME/.node_modules, $HOME/.node_libraries
[NODE_PATH,HOME/.node_modules,HOME/.node_libraries,execPath/../../lib/node]然后是node.exe目录的../../lib/node,所以这个具体取决于node二进制文件放哪里.
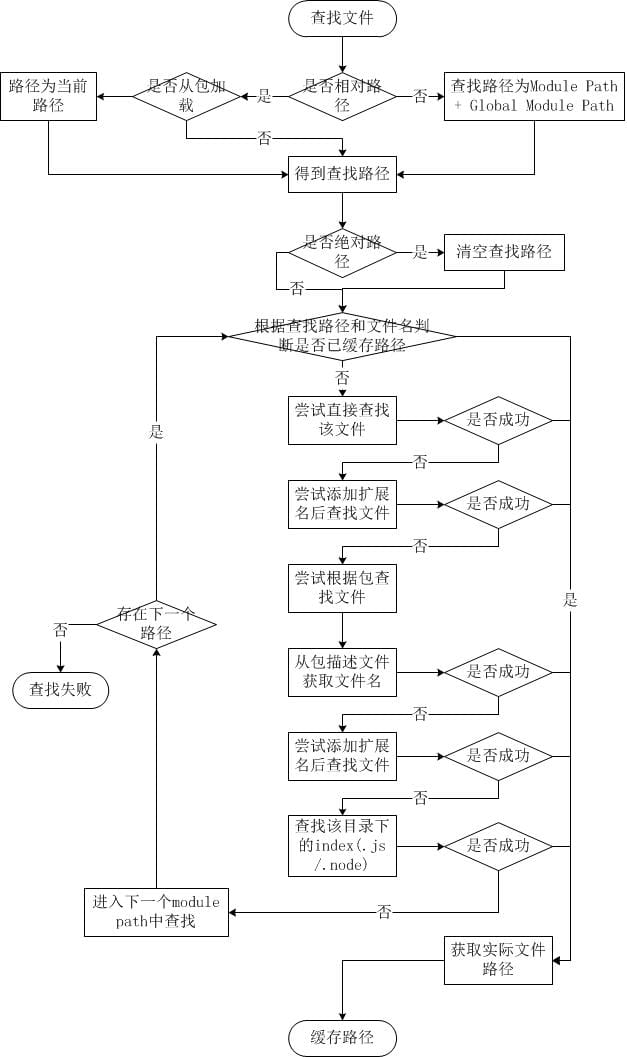
简而言之,如果require绝对路径的文件,查找时不会去遍历每一个node_modules目录,其速度最快。其余流程如下:
从module path数组中取出第一个目录作为查找基准。
直接从目录中查找该文件,如果存在,则结束查找。如果不存在,则进行下一条查找。
尝试添加.js、.json、.node后缀后查找,如果存在文件,则结束查找。如果不存在,则进行下一条。
尝试将require的参数作为一个包来进行查找,读取目录下的package.json文件,取得main参数指定的文件。
尝试查找该文件,如果存在,则结束查找。如果不存在,则进行第3条查找。
如果继续失败,则取出module path数组中的下一个目录作为基准查找,循环第1至5个步骤。
如果继续失败,循环第1至6个步骤,直到module path中的最后一个值。
如果仍然失败,则抛出异常。
整个查找过程十分类似原型链的查找和作用域的查找。所幸Node.js对路径查找实现了缓存机制,否则由于每次判断路径都是同步阻塞式进行,会导致严重的性能消耗。
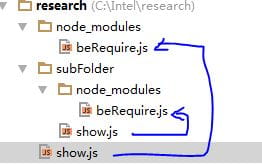
一旦加载成功就以模块的路径进行缓存,这里有一个陷阱。
就是如果父目录包含X模块,且存在引用X模块的代码。而子目录也是相同的情况。那么父目录和子目录下实际引用到的分别是自己目录下的那个X模块,而不是之前那个的复用。也就是要注意他缓存是匹配全路径的。
Nodejs:模块查找,引用及缓存机制
3. 利用nodejs模块缓存机制创建“全局变量”
在《深入浅出nodejs》有这样一段(有部分增减):
nodejs引入模块分四个步骤 路径分析 文件定位 编译执行 加入内存 核心模块部分在node源代码的编译过程中就编译成了二级制文件,在node启动时就直接加载如内存,所以这部分模块引入时,前三步省略,直接加入。 nodejs的模块加载和浏览器js加载一样都有缓存机制,不同的是,浏览器仅仅缓存文件,而nodejs缓存的是编译和执行后的对象(缓存内存)。 基于以上三点:我们可以编写一个模块,用来记录长期存在的变量。例如:我可以编写一个记录接口访问数的模块:
var count = {}; // 因模块是封闭的,这里实际上借用了js闭包的概念exports.count = function(name){ if(count[name]){ count[name]++; }else{ count[name] = 1; } console.log(name + '被访问了' + count[name] + '次。'); };我们在路由里这样引用:
var count = require('count');export.index = function(req, res){ count('index');};4. nodejs清除require缓存 delete require.cache
开发nodejs应用时会面临一个麻烦的事情,就是修改了配置数据之后,必须重启服务器才能看到修改后的结果。
于是问题来了,挖掘机哪家强?噢,no! no! no!
怎么做到修改文件之后,自动重启服务器。
server.js中的片段:
var port = process.env.port || 1337;app.listen(port);console.log("server start in " + port);exports.app = app;假定我们现在是这样的:
app.js的片段:
var app = require('./server.js');如果我们在server.js中启动了服务器,我们停止服务器可以在app.js中调用
app.app.close()
但是当我们重新引入server.js
app = require('./server.js')
的时候会发现并不是用的最新的server.js文件,原因是require的缓存机制,在第一次调用require('./server.js')的时候缓存下来了。
这个时候怎么办?
下面的代码解决了这个问题:
delete require.cache[require.resolve('./server.js')];app = require('./server.js');Node.js的模块查找、引用和缓存机制是其独特的特性之一,它们为开发人员提供了更好的性能和可维护性。了解这些机制的工作原理和使用方法,可以帮助开发人员更好地利用Node.js的优势,提高应用程序的性能和可维护性。
关于“Node.js模块查找,引用及缓存机制是什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注编程网行业资讯频道,小编每天都会为大家更新不同的知识点。







