
这篇文章主要介绍“Java工程师怎么掌握全文搜索引擎”,在日常操作中,相信很多人在Java工程师怎么掌握全文搜索引擎问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Java工程师怎么掌握全文搜索引擎”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
什么是全文搜索
首先搞清楚第一个问题:什么是全文搜索引擎?
百度百科中的定义:
全文搜索引擎是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置
当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
从定义中我们已经可以大致了解全文检索的思路了,为了更详细的说明,我们先从生活中的数据说起。
我们生活中的数据总体分为两种:结构化数据 和 非结构化数据。
结构化数据: 具有固定格式或有限长度的数据,如数据库,元数据等
非结构化数据: 非结构化数据又可称为全文数据,指不定长或无固定格式的数据,如邮件,word文档等
当然有的地方还会有第三种:半结构化数据,如XML,HTML等,当根据需要可按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理。
根据两种数据分类,搜索也相应的分为两种:
结构化数据搜索
非结构化数据搜索
对于结构化数据,我们一般都是可以通过关系型数据库(mysql,oracle等)的 table 的方式存储和搜索,也可以建立索引。对于非结构化数据,也即对全文数据的搜索主要有两种方法:顺序扫描法,全文检索
顺序扫描:通过文字名称也可了解到它的大概搜索方式,即按照顺序扫描的方式查询特定的关键字。
例如给你一张报纸,让你找到该报纸中“RNG”的文字在哪些地方出现过。你肯定需要从头到尾把报纸阅读扫描一遍然后标记出关键字在哪些版块出现过以及它的出现位置。
这种方式无疑是最耗时的最低效的,如果报纸排版字体小,而且版块较多甚至有多份报纸,等你扫描完你的眼睛也差不多了。
全文搜索:对非结构化数据顺序扫描很慢,我们是否可以进行优化?把我们的非结构化数据想办法弄得有一定结构不就行了吗?
我们将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。
这种方式就构成了全文检索的基本思路。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
还以读报纸为例,我们想关注最近英雄联盟 S8 全球总决赛的新闻,假如都是 RNG 的粉丝,如何快速找到 RNG 新闻的报纸和版块呢?
全文搜索的方式:将所有报纸中所有版块中关键字进行提取,如"EDG","RNG","FW","战队","英雄联盟"等。然后对这些关键字建立索引,通过索引我们就可以对应到该关键词出现的报纸和版块。
为什么要用全文搜索引擎
那第二个问题来了,为什么要用搜索引擎?
我们的所有数据在数据库里面都有,而且 Oracle、SQL Server 等数据库里也能提供查询检索或者聚类分析功能,直接通过数据库查询不就可以了吗?
确实,我们大部分的查询功能都可以通过数据库查询获得,如果查询效率低下,还可以通过建数据库索引,优化SQL等方式进行提升效率,甚至通过引入缓存来加快数据的返回速度。如果数据量更大,就可以分库分表来分担查询压力。
那为什么还要全文搜索引擎呢?我们主要从以下几个原因分析:
数据类型
全文索引搜索支持非结构化数据的搜索,可以更好地快速搜索大量存在的任何单词或单词组的非结构化文本。
例如 Google,百度类的网站搜索,它们都是根据网页中的关键字生成索引,我们在搜索的时候输入关键字,它们会将该关键字即索引匹配到的所有网页返回
还有常见的项目中应用日志的搜索等等。对于这些非结构化的数据文本,关系型数据库搜索不是能很好的支持。
索引的维护
一般传统数据库,全文检索都实现的很鸡肋,因为一般也没人用数据库存文本字段。
进行全文检索需要扫描整个表,如果数据量大的话即使对SQL的语法优化,也收效甚微。建立了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。
第三个问题:什么时候使用全文搜索引擎?
搜索的数据对象是大量的非结构化的文本数据。
文件记录量达到数十万或数百万个甚至更多。
支持大量基于交互式文本的查询。
需求非常灵活的全文搜索查询。
对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足。
对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况。
Lucene or Solr or ElasticSearch ?
现在主流的搜索引擎大概就是:Lucene,Solr,ElasticSearch。
它们的索引建立都是根据倒排索引的方式生成索引,何谓倒排索引?
还是先看看维基百科的解释:
维基百科
倒排索引(英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。
接下来我们就来看看,这 3 种主流的使用倒排索引的全文搜索引擎。
Lucene
Lucene是一个Java全文搜索引擎,完全用Java编写。Lucene不是一个完整的应用程序,而是一个代码库和API,可以很容易地用于向应用程序添加搜索功能。
Lucene通过简单的API提供强大的功能:
可扩展的高性能索引
在现代硬件上超过150GB /小时
小RAM要求 - 只有1MB堆
增量索引与批量索引一样快
索引大小约为索引文本大小的20-30%
强大,准确,高效的搜索算法
排名搜索 - 首先返回最佳结果
许多强大的查询类型:短语查询,通配符查询,邻近查询,范围查询等
现场搜索(例如,作者,内容)
按任何字段排序
使用合并结果进行多索引搜索
允许同时更新和搜索
灵活的分面,突出显示,连接和结果分组
快速,内存效率和错误容忍的建议
可插拔排名模型,包括矢量空间模型和Okapi BM25
可配置存储引擎(编解码器)
跨平台解决方案
作为Apache许可下的开源软件提供 ,允许您在商业和开源程序中使用Lucene
100%-pure Java
可用的其他编程语言中的实现是索引兼容的
但是Lucene只是一个框架,要充分利用它的功能,需要使用JAVA,并且在程序中集成Lucene。需要很多的学习了解,才能明白它是如何运行的,熟练运用Lucene确实非常复杂。
Solr
Apache Solr是一个基于名为Lucene的Java库构建的开源搜索平台。它以用户友好的方式提供Apache Lucene的搜索功能。
它提供分布式索引,复制,负载平衡查询以及自动故障转移和恢复。如果它被正确部署然后管理得好,它就能够成为一个高度可靠,可扩展且容错的搜索引擎。
很多互联网巨头,如Netflix,eBay,Instagram和亚马逊(CloudSearch)都使用Solr,因为它能够索引和搜索多个站点。
主要功能列表包括:
全文搜索
分页搜索
实时索引
动态群集
数据库集成
NoSQL功能和丰富的文档处理(例如Word和PDF文件)
ElasticSearch
Elasticsearch是一个开源的基于Apache Lucene库构建的 RESTful 搜索引擎,在Solr之后几年推出的。
它提供了一个分布式,多租户能力的全文搜索引擎,具有HTTP Web界面(REST)和无架构JSON文档。
Elasticsearch的官方客户端库提供Java,Groovy,PHP,Ruby,Perl,Python,.NET和Javascript。
分布式搜索引擎包括可以划分为分片的索引,并且每个分片可以具有多个副本。每个Elasticsearch节点都可以有一个或多个分片,其引擎也可以充当协调器,将操作委派给正确的分片。
Elasticsearch可通过近实时搜索进行扩展。其主要功能之一是多租户。主要功能列表包括:
分布式搜索
多租户
分析搜索
分组和聚合
Elasticsearch vs. Solr,如何选择?
由于Lucene的复杂性,一般很少会考虑它作为搜索的第一选择,排除一些公司需要自研搜索框架,底层需要依赖Lucene。所以这里我们重点分析 Elasticsearch 和 Solr。
Elasticsearch vs. Solr。哪一个更好?他们有什么不同?你应该使用哪一个?
历史比较
Apache Solr是一个成熟的项目,拥有庞大而活跃的开发和用户社区,以及Apache品牌。Solr于2006年首次发布到开源,长期以来一直占据着搜索引擎领域,并且是任何需要搜索功能的人的首选引擎。
它的成熟转化为丰富的功能,而不仅仅是简单的文本索引和搜索; 如分面,分组,强大的过滤,可插入的文档处理,可插入的搜索链组件,语言检测等。
Solr 在搜索领域占据了多年的主导地位。然后,在2010年左右,Elasticsearch成为市场上的另一种选择。那时候,它远没有Solr那么稳定,没有Solr的功能深度,没有思想分享,品牌等等。
Elasticsearch虽然很年轻,但它也自己的一些优势,Elasticsearch 建立在更现代的原则上,针对更现代的用例,并且是为了更容易处理大型索引和高查询率而构建的。
此外,由于它太年轻,没有社区可以合作,它可以自由地向前推进,而不需要与其他人(用户或开发人员)达成任何共识或合作,向后兼容,或任何其他更成熟的软件通常必须处理。
因此,它在Solr之前就公开了一些非常受欢迎的功能(例如,接近实时搜索,英文:Near Real-Time Search)。
从技术上讲,NRT搜索的能力确实来自Lucene,它是 Solr 和 Elasticsearch 使用的基础搜索库。
具有讽刺意味的是,因为 Elasticsearch 首先公开了NRT搜索,所以人们将NRT搜索与Elasticsearch 联系在一起,尽管 Solr 和 Lucene 都是同一个 Apache 项目的一部分,因此,人们会首先期望 Solr 具有如此高要求的功能。
特征差异比较
这两个搜索引擎都是流行的,先进的的开源搜索引擎。它们都是围绕核心底层搜索库 - Lucene构建的
但它们又是不同的。像所有东西一样,每个都有其优点和缺点,根据您的需求和期望,每个都可能更好或更差。
所以,话不多说,先来看下它们的差异清单:
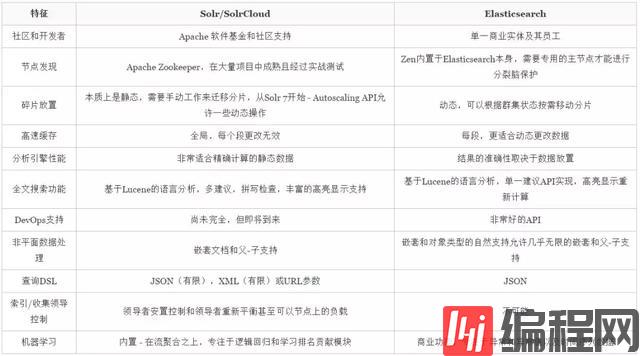
综合比较
另外,我们在从以下几个方面来分析下:
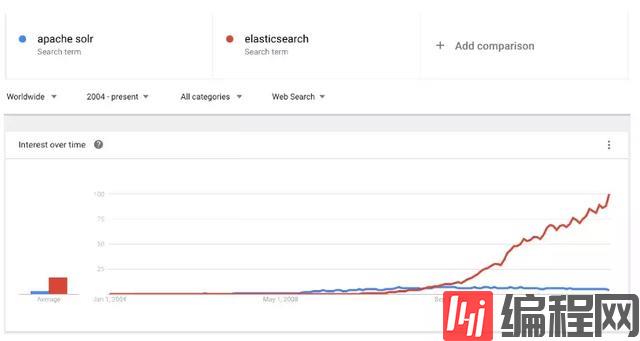
近几年的流行趋势
我们查看一下这两种产品的Google搜索趋势。谷歌趋势表明,与 Solr 相比,Elasticsearch具有很大的吸引力,但这并不意味着Apache Solr已经死亡
虽然有些人可能不这么认为,但Solr仍然是最受欢迎的搜索引擎之一,拥有强大的社区和开源支持。看下图两者的对比:
安装和配置
与Solr相比,Elasticsearch易于安装且非常轻巧。此外,您可以在几分钟内安装并运行Elasticsearch。
但是,如果Elasticsearch管理不当,这种易于部署和使用可能会成为一个问题。基于JSON的配置很简单,但如果要为文件中的每个配置指定注释,那么它不适合您。
总的来说,如果您的应用使用的是JSON,那么Elasticsearch是一个更好的选择。否则,请使用Solr,因为它的schema.xml和solrconfig.xml都有很好的文档记录。
社区
Solr拥有更大的开发者和贡献者社区,ES的社区规模较小,但活跃度高,用户也在不断增长。
Solr是真正的开源社区代码,任何人都可以为Solr做出贡献,并且根据优点选出新的Solr开发人员(也称为提交者)。
Elasticsearch在技术上是开源的,但在精神上却不那么重要。任何人都可以看到来源,任何人都可以更改它并提供贡献,但只有Elasticsearch的员工才能真正对Elasticsearch进行更改。
Solr贡献者和提交者来自许多不同的组织,而Elasticsearch提交者来自单个公司。
成熟度
Solr更成熟,但ES增长迅速,我认为它稳定。
文档
Solr在这里得分很高。它是一个非常有据可查的产品,具有清晰的示例和API用例场景。
Elasticsearch的文档组织良好,但它缺乏好的示例和清晰的配置说明。
到此,关于“Java工程师怎么掌握全文搜索引擎”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注编程网网站,小编会继续努力为大家带来更多实用的文章!








