
今天就跟大家聊聊有关Python中怎么实现语音识别,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
离线转换
对于国内的网络环境,无法用google API来将语音数据转换成文本文件,因为在调用这个包的时候,需要连接到google。当然,你可以租用一个国外的VPS来做这件事情。
这里讲一下如何在不联网的情况下,依然可以通过python来将语音文件转换成文字。这里用到的包为sphinx,sphinx是由美国卡内基梅隆大学开发的大词汇量、非特定人、连续英语语音识别系统。
安装 sphinx
我本人所用的环境为ubuntu。
imyin@develop:~/Downloads/phinx$ lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 16.04.3 LTS Release: 16.04 Codename: xenial在安装sphinx之前需要安装一些软件包
sudo apt-get install gcc automake autoconf libtool bison swig python-dev libpulse-dev之后可以在相关网站上下载sphinxbase安装包,当然也可以直接clone github上的包
下载完之后进行解压
tar zxpf sphinxbase-5prealpha.tar.gz修改文件名
mv sphinxbase-5prealpha sphinxbase ls sphinxbase AUTHORS doc indent.sh Makefile.am README.md src win32 autogen.sh .git LICENSE NEWS sphinxbase.pc.in swig configure.ac include m4 README sphinxbase.sln test现在我们应该运行autogen.sh来生成Makefiles和其他一些脚本以备后续的编译和安装。
./autogen.sh下面开始源码安装
make && sudo make install执行完以上命令之后,如果没有出现什么报错信息,就说明已经安装成功了,但是此时你的命令并不可以生效,在运行命令时会出现这样的错误。
imyin@develop:~/Downloads/phinx/sphinxbase$ sphinx_lm_convert sphinx_lm_convert: error while loading shared libraries: libsphinxbase.so.3: cannot open shared object file: No such file or directory还需要让系统加载目录/usr/local/lib,为了让系统每次启动时都可以自动加载,可以修改系统配置文件ld.so.conf
sudo echo "/usr/local/lib" >> /etc/ld.so.conf sudo ldconfig这时候,就可以通过sphinx_lm_convert命令将模型DMP文件转成bin文件
sphinx_lm_convert -i zh_broadcastnews_64000_utf8.DMP -o zh_CN.lm.bin上面这行代码是将中文的模型DMP文件转成了bin文件。在安装完sphinx后默认只支持英文,在存放模型的路径下只有一个文件名为en-US,所以这里需要添加一个处理中文的模型,相关文件可以在这个网址中下载。

在python中使用sphinx
想要在python中使用sphinx的话,需要安装一些依赖包。
pip install pydub -U # 负责将MP3文件转换为 wav 文件 pip install SpeechRecognition -U # 负责将语音转换成文字 sudo apt -qq install build-essential swig libpulse-dev # 为后面安装 pocketsphinx 做准备 pip install -U pocketsphinx # 为使用 sphinx sudo apt-get install libav-tools # 为解决在调用 pydub 时出现的 warning :RuntimeWarning: Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work warn("Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work", RuntimeWarning)这时候,就可以启动ipython来试试效果了。
file_path = '/home/imyin/Downloads/phinx/test_data' r = sr.Recognizer() hello_zh = sr.AudioFile(os.path.join(file_path, 'test.wav')) with hello_zh as source: audio = r.record(source) r.recognize_sphinx(audio, language='zh_CN') '今天 天气 很'可以看出,这个语音识别器已经生效了。但是我说的是“今天天气好热啊”。
看来sphinx中的模型并非很准呐,而且这只是一个短句子。我们接下来看看长句子的效果,我录了村上春树的《当我谈跑步时我谈些什么》中的一段内容。
那一年的七月里,我去了一趟希腊,要独自从雅典跑到马拉松,将那条原始的马拉松路线——马拉松至雅典——逆向跑上一趟。为什么要逆向跑呢?因为清晨便从雅典市中心出发,在道路开始拥堵、空气被污染之前跑出市区,一路直奔马拉松的话,道路的交通量远远少得多,跑起来比较舒适。这不是正式的比赛,自己一个人随意去跑,当然不能指望有什么交通管制。hello_zh = sr.AudioFile(os.path.join(file_path, 'test2.wav')) with hello_zh as source: audio = r.record(source) r.recognize_sphinx(audio, language='zh_CN') '南 音 扬 的 只有 领 过 球 的 立场 是 希望 让 猪只 处理 垃圾 土木工程 上 打球 运动 充满 温情 能 成功 吗 而 中止 了 对 印尼 商报 称 他 不是 没有 立场 谈 那 一 枚 其中 春天 从 雅典 市中心 出发 寸 厂 都 可 成功 突破 寻求 对 於 能 提升 统筹 署 取缔 一路 直奔 马拉松 和 阿 惹 山 活动 等 二十 个 队 中 重申 这 不是 正常 的 比赛 自己 一个人 却 一直到 当然 不能 说明 什么 这种 共识'呃,看到结果,我觉得可以用一个来形容:差劲。两个字来形容:太差劲!
当然,这个模型只是我直接从网上下载下来的。训练它时所用到的语料不会那么齐全,所以在测试时难免会出现不准确的情况。要想让模型更加准确,需要自己在利用sphnix继续训练模型。
相关办法在其官网上可以找到,也有相应的教程。感兴趣的朋友可以自行研究。
Q: Why my accuracy is poor Speech recognition accuracy is not always great. To test speech recognition you need to run recognition on prerecorded reference database to see what happens and optimize parameters. You do not need to play with unknown values, the first thing you should do is to collect a database of test samples and measure the recognition accuracy. You need to dump speech utterances into wav files, write the reference text file and use decoder to decode it. Then calculate WER using the word_align.pl tool from Sphinxtrain. Test database size depends on the accuracy but usually it’s enough to have 10 minutes of transcribed audio to test recognizer accuracy reliably. The process is described in tutorialtuning.文中提到的教程网址是https://cmusphinx.github.io/wiki/tutorialtuning/
Google API
利用google API来处理语音识别则相当准确,不过需要连接google,以下是我在VPS中执行的一段代码,可以看出,它将我的录音精准地翻译成了文字。
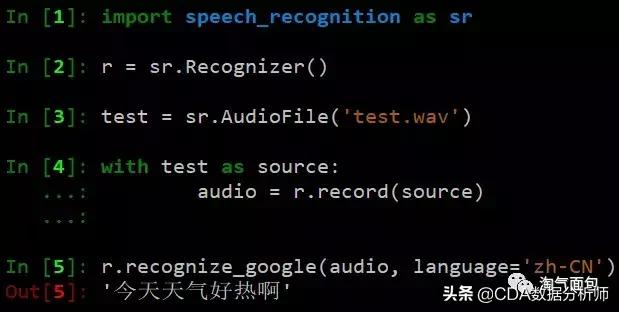
但是如果录音文件较大的话,会运行时间很长,并且会返回一个超时的错误,这很是让我苦恼。
不过幸运的是,speech_recognition支持将语音文件进行截取处理。例如,我可以只处理语音文件中的前15秒钟的内容。
with test as source: audio = r.record(source, duration=15) r.recognize_google(audio, language='zh-CN') '那一年的7月里我去了一趟希腊有独自从雅典跑到马拉松江哪条原始的马拉松路线马拉松直雅典一想跑上一趟'从上面的结果看,简直比sphnix处理的效果好太多了。
通过看帮助文档发现speech_recognition不仅可以截取前面的录音,还可以截取中间的。
In [18]: r.record? Signature: r.record(source, duration=None, offset=None) Docstring: Records up to ``duration`` seconds of audio from ``source`` (an ``AudioSource`` instance) starting at ``offset`` (or at the beginning if not specified) into an ``AudioData`` instance, which it returns. If ``duration`` is not specified, then it will record until there is no more audio input.例如我想处理5秒至20秒之间的内容。
with test as source: audio = r.record(source, offset=5, duration=15) r.recognize_google(audio, language='zh-CN') '要独自从雅典跑到马拉松江哪条原始的马拉松路线马拉松直雅典一项跑上一趟为什么要一想到呢因为星辰变从雅典市中心出发'看完上述内容,你们对Python中怎么实现语音识别有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注编程网行业资讯频道,感谢大家的支持。







