
本篇文章给大家分享的是有关Filebeat优化实践的示例分析,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
Filebeat优化实践
背景介绍
目前比较主流的日志采集系统有ELK(ES+Logstash+Kibana),EFK(ES+Fluentd+Kibana)等。由于Logstash出现较早,大多数日志文件搜集采用了Logstash。但由于Logstash是JRuby实现的,性能开销较大,因此我们的日志搜集采用的Filebeat,然后发送到Logstash进行数据处理(例如:解析json,正则解析文件名称等),最后由Logstash发送到Kafka或者ES。这种方式虽然减轻了每个节点的处理压力,但部署Logstash的节点性能开销依旧很大,而且经常出现Filebeat无法发送数据到Logstash的情况。
抛弃Logstash
由于Logstash性能开销较大,为了提高客户端的日志采集性能,又减少数据传输环节和部署复杂度,并更充分地将 Go 语言的性能优势利用于日志解析,于是决定在 Filebeat 上通过开发插件的方式,实现针对公司日志格式规范的解析,直接作为 Logstash 的替代品。
开发自己的Processor
我们的平台是基于Kubernetes的,因此我们需要解析每一条日志的source,从日志文件名称中获取Kubernetes资源名称,以确定该条日志的发往Topic。解析文件名称需要用到正则匹配,但由于正则性能开销较大,如果每一条日志都用正则解析名称将会带来比较大的性能开销,因此我们决定采用缓存来解决这一问题。即每个文件只解析一次名称,存放到一个Map变量中,如果已经解析过的文件名称则不再解析。这样大大提高了Filebeat的吞吐量。
性能优化
Filebeat配置文件如下,其中kubernetes_metadata是自己开发的Processor。
################### Filebeat Configuration Example ###################################################### Filebeat ######################################filebeat: # List of prospectors to fetch data. prospectors: - paths: - /var/log/containers/* symlinks: true# tail_files: true encoding: plain input_type: log fields: type: k8s-log cluster: cluster1 hostname: k8s-node1 fields_under_root: true scan_frequency: 5s max_bytes: 1048576 # 1M # General filebeat configuration options registry_file: /data/usr/filebeat/kube-filebeat.registry############################# Libbeat Config ################################### Base config file used by all other beats for using libbeat features############################# Processors ######################################processors:- decode_json_fields: fields: ["message"] target: ""- drop_fields: fields: ["message", "beat", "input_type"]- kubernetes_metadata: # Default############################# Output ########################################### Configure what outputs to use when sending the data collected by the beat.# Multiple outputs may be used.output: file: path: "/data/usr/filebeat" filename: filebeat.log测试环境:
性能测试工具使用https://github.com/urso/ljtest
火焰图生成使用uber的go-torch https://github.com/uber/go-torch
CPU通过runtime.GOMAXPROCS(1)限制使用一个核
第一版性能数据如下:
| 平均速度 | 100万条总时间 |
|---|---|
| 11970 条/s | 83.5秒 |
生成的CPU火焰图如下 
从火焰图中可以看出 CPU 时间占用最多的主要有两块。一块是 Output 处理部分,写文件。另一块就比较奇怪了,是 common.MapStr.Clone() 方法,居然占了 34.3% 的 CPU 时间。其中Errorf 占据了21%的CPU时间。看下代码:
func toMapStr(v interface{}) (MapStr, error) {switch v.(type) {case MapStr:return v.(MapStr), nilcase map[string]interface{}:m := v.(map[string]interface{})return MapStr(m), nildefault:return nil, errors.Errorf("expected map but type is %T", v)}}errors.Errorf生成error对象占据了大块时间,把这一块判断逻辑放到MapStr.Clone()中就可以避免产生error,到此你是不是该有些思考?go的error虽然是很好的设计,但不能滥用,不能滥用,不能滥用!否则你可能会为此付出惨痛的代价。
优化后:
| 平均速度 | 100万条总时间 |
|---|---|
| 18687 条/s | 53.5秒 |
处理速度竟然提高了50%多,没想到几行代码的优化,吞吐量竟然能提高这么多,惊不惊喜,意不意外。 再看下修改后的火焰图
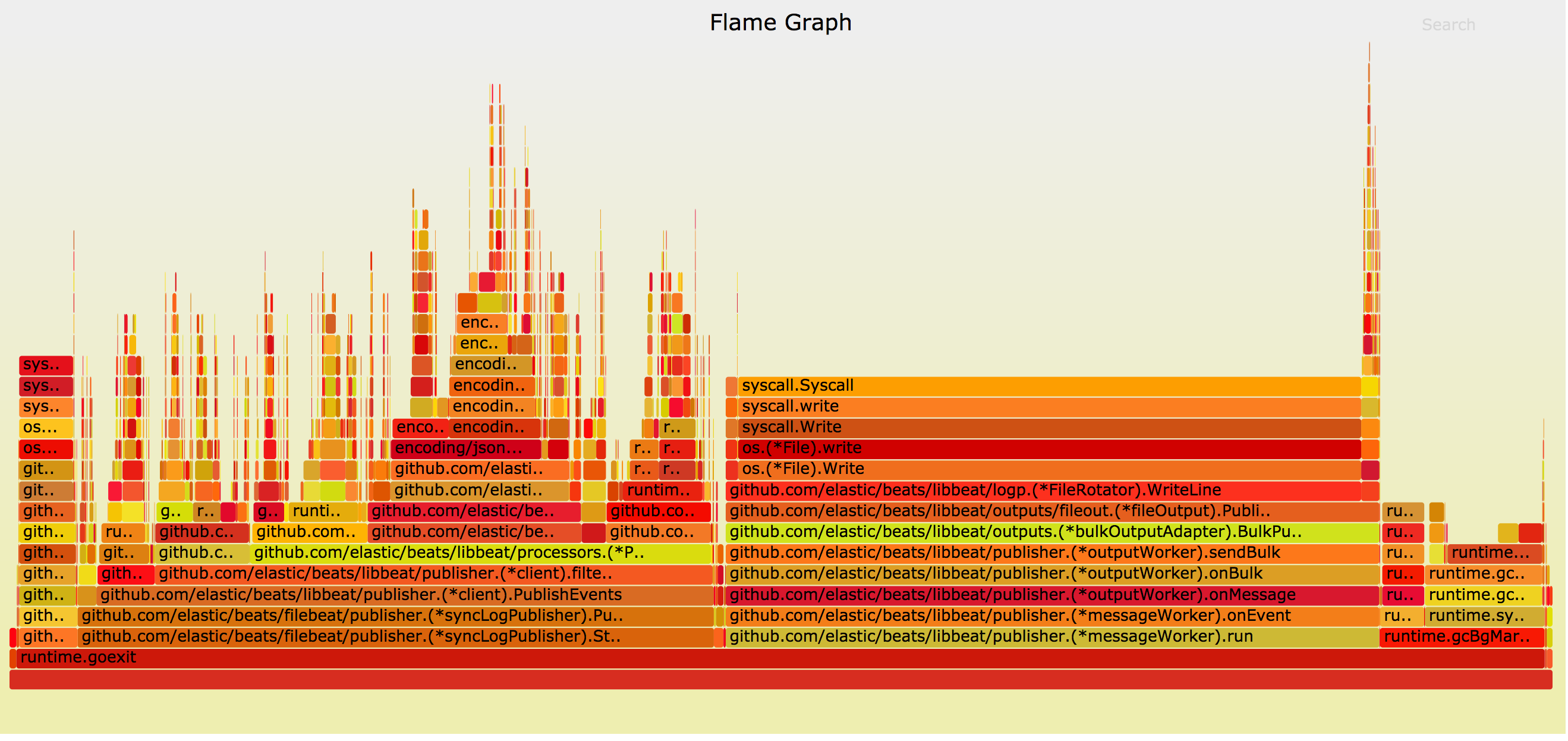
发现MapStr.Clone() 的性能消耗几乎可以忽略不计了。
进一步优化:
我们的日志都是Docker产生的,使用 JSON 格式,而 Filebeat 使用 Go 自带的 encoding/json 包是基于反射实现的,性能有一定问题。 既然我们的日志格式是固定的,解析出来的字段也是固定的,这时就可以基于固定的日志结构体做 JSON 的序列化,而不必用低效率的反射来实现。Go 有多个针对给定结构体做 JSON 序列化 / 反序列化的第三方包,这里使用的是 easyjson:https://github.com/mailru/easyjson。
由于解析的日志格式是固定的,所以提前定义好日志的结构体,然后使用easyjson解析。 处理速度性能提升到
| 平均速度 | 100万条总时间 |
|---|---|
| 20374 条/s | 49秒 |
但这样修改后就会使decode_json_fields 这个processor只能处理特定的日志格式,适用范围会有所降低。所以json解析这块暂时没有修改。
日志处理一直是系统运维中比较重要的环节,无论是传统的运维方式还是基于Kubernetes(或者Mesos,Swarm等)的新型云平台日志搜集都格外重要。无论选用哪种方式搜集日志,都有可能遇到性能瓶颈,但一小段代码的改善就可能完全解决了你的问题,路漫漫其修远兮,优化永无止境。
需要稍作说明的是:
Filebeat 开发是基于 5.5.1 版本,Go 版本是 1.8.3
测试中Filebeat使用runtime.GOMAXPROCS(1)限制只使用一个核
由于测试是在同一台机器上使用相同数据进行的,将日志输出到文件对测试结果影响不大。
以上就是Filebeat优化实践的示例分析,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注编程网行业资讯频道。







