
python在同一个线程中多次执行同一方法时,假设该方法执行耗时较长且每次执行过程及结果互不影响,如果只在主进程中执行,效率会很低,因此使用multiprocessing.Pool(processes=n)及其apply_async()方法提高程序执行的并行度从而提高程序的执行效率,其中processes=n为程序并行执行的进程数。
apply()方法是阻塞的,也就是说等待当前子进程执行完毕后,再执行下一个进程。
示例代码:
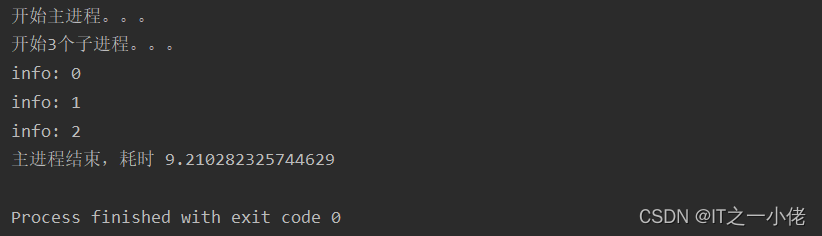
import timeimport multiprocessingdef apply_test(s): time.sleep(3) print('info: %s' % s)if __name__ == '__main__': print('开始主进程。。。') start = time.time() # 使用线程池建立3个子进程 pool = multiprocessing.Pool(3) print('开始3个子进程。。。') for i in range(3): pool.apply(apply_test, [i]) print('主进程结束,耗时 %s' % (time.time() - start))运行结果:
apply_async()是异步非阻塞式,不用等待当前进程执行完毕,随时跟进操作系统调度来进行进程切换,即多个进程并行执行,提高程序的执行效率。
示例代码1:
import timeimport multiprocessingdef apply_test(s): time.sleep(3) print('info: %s' % s)if __name__ == '__main__': print('开始主进程。。。') start = time.time() # 使用线程池建立3个子进程 pool = multiprocessing.Pool(3) print('开始3个子进程。。。') for i in range(3): pool.apply_async(apply_test, [i]) print('主进程结束,耗时 %s' % (time.time() - start)) # 为了演示效果,这儿使用休眠方式 time.sleep(10)运行结果:

示例代码2: 【主进程等待子进程都结束再结束】
import timeimport multiprocessingdef apply_test(s): time.sleep(3) print('info: %s' % s)if __name__ == '__main__': print('开始主进程。。。') start = time.time() # 使用线程池建立3个子进程 pool = multiprocessing.Pool(3) print('开始3个子进程。。。') for i in range(3): pool.apply_async(apply_test, [i]) pool.close() pool.join() print('主进程结束,耗时 %s' % (time.time() - start))运行结果:

示例代码3:
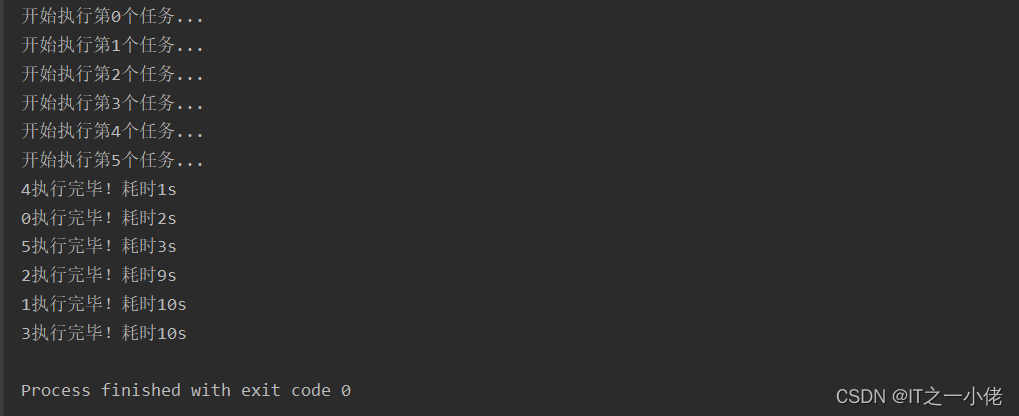
import timeimport randomimport multiprocessingdef func(x): ts = random.randint(1, 10) time.sleep(ts) print(f'{x}执行完毕!耗时{ts}s')if __name__ == '__main__': pool = multiprocessing.Pool(6) for i in range(6): print(f"开始执行第{i}个任务...") pool.apply_async(func, args=(i, )) pool.close() pool.join()运行结果:
在使用apply_async()方法接收多个参数的方法时,在任务方法中正常定义多个参数,参数以元组形式传入即可 但是给apply_async()方法传入多个值获取多个迭代结果时就会报错,因为该方法只能接收一个值,所以可以将该方法放入一个列表生成式中。
示例代码4:
import multiprocessingdef func(x): return x ** 2if __name__ == '__main__': pool = multiprocessing.Pool() res = [pool.apply_async(func, (i, )) for i in range(6)] print([x for x in res]) print([x.get() for x in res]) pool.close() pool.join()运行结果:

有时候在使用多进程或者多线程执行程序时,当程序有bug时,某个进程或者线程可能会挂掉,但是自己又不容易或者很难发现是哪个线程或进程挂掉了。如示例代码5所示:
示例代码5:
import timeimport randomimport multiprocessingdef func(x, y): ret = x / y return retdef task(i): ts = random.randint(1, 10) time.sleep(ts) nums = [-1, 0, 1, 2] x, y = random.choice(nums), random.choice(nums) value = func(x, y) print(f'{i}执行完毕!耗时{ts}s,结果为{value}')if __name__ == '__main__': pool = multiprocessing.Pool(6) for i in range(6): print(f"开始执行第{i}个任务...") pool.apply_async(task, args=(i,)) pool.close() pool.join()运行结果:

在上述例子中,我们是打印了某个进程号,但真正项目中是不会这样打印日志的,就很难发现某个进程或者线程已经挂掉了,这时候需要使用回调函数,打印某个进程或者线程挂掉的error信息,如示例代码6所示。
示例代码6:
import timeimport randomimport multiprocessingdef func(x, y): ret = x / y return retdef task(i): ts = random.randint(1, 10) time.sleep(ts) nums = [-1, 0, 1, 2] x, y = random.choice(nums), random.choice(nums) value = func(x, y) print(f'{i}执行完毕!耗时{ts}s,结果为{value}')def error_callback(error): print(f"Error info: {error}")if __name__ == '__main__': pool = multiprocessing.Pool(6) for i in range(6): print(f"开始执行第{i}个任务...") pool.apply_async(task, args=(i,), error_callback=error_callback) pool.close() pool.join()运行结果:
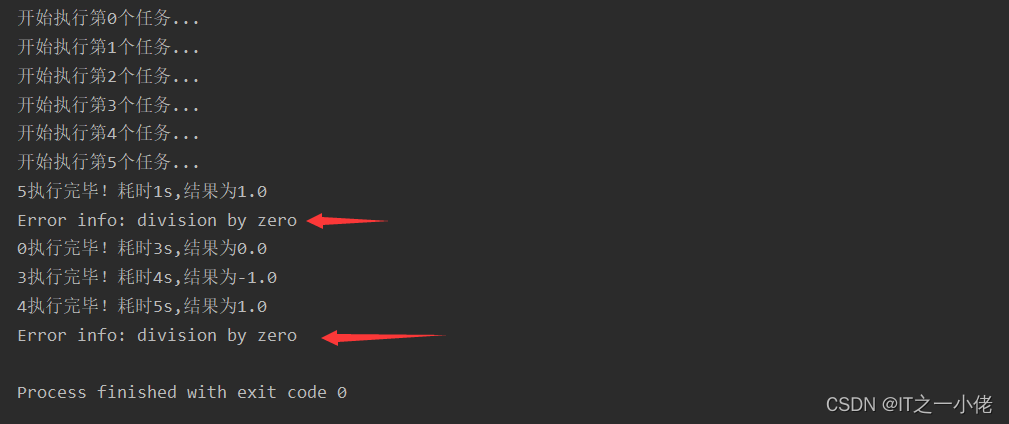
上述执行结果就很容易看出进程或者线程在运行过程中有挂掉的,而且打印出了挂掉的原因,也有利用我们后期排除程序中的bug。
同样的,除了想让报错的程序回调一下,同时也想让异步函数执行完毕也给一个回调响应值,这时可以加上callback参数,响应结果,如示例代码7所示。
示例代码7:
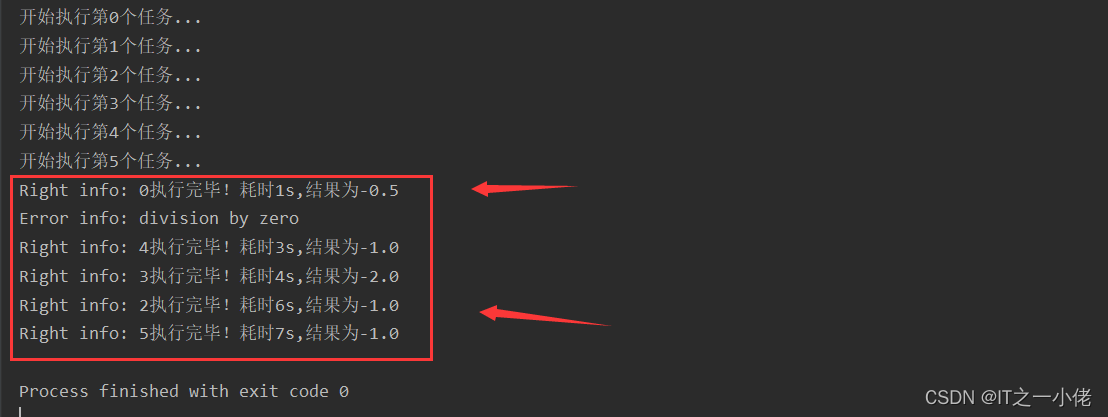
import timeimport randomimport multiprocessingdef func(x, y): ret = x / y return retdef task(i): ts = random.randint(1, 10) time.sleep(ts) nums = [-1, 0, 1, 2] x, y = random.choice(nums), random.choice(nums) value = func(x, y) # print(f'{i}执行完毕!耗时{ts}s,结果为{value}') return f'{i}执行完毕!耗时{ts}s,结果为{value}'def error_callback(error): print(f"Error info: {error}")def call_back(info): print(f"Right info: {info}")if __name__ == '__main__': pool = multiprocessing.Pool(6) for i in range(6): print(f"开始执行第{i}个任务...") pool.apply_async(task, args=(i,), callback=call_back, error_callback=error_callback) pool.close() pool.join()运行结果:
注意:join()等待所有子进程结束后再运行,使用join()前先使用close()关闭它。
来源地址:https://blog.csdn.net/weixin_44799217/article/details/126860696









