
随着人工智能技术的发展,人工智能在很多场景里正逐渐替代或协作着人类的各种劳动,它们可以成为人类的眼睛、耳朵、手臂甚至大脑。其中,机器视觉作为AI时代的基础技术,其背后的AI算法一直是各科技巨头和创业公司共同追逐的热点。然而,这些主流应用场景的背后,往往也藏着由技术性缺陷导致的算法安全风险。
例如,在一些训练数据无法覆盖到的极端场景中,自动驾驶汽车可能出现匪夷所思的决策,导致乘车人安全风险。从2016年至今,Tesla、Uber等企业的辅助驾驶和自动驾驶系统就都曾出现过类似致人死亡的严重事故。并且这类极端情形也可能被恶意制造并利用,发起“对抗样本攻击”,去年7月,百度等研究机构就曾经通过3D打印,能让自动驾驶“无视”的障碍物,使车辆有发生撞击的风险,同样威胁行驶安全。
之所以能攻击成功,主要是机器视觉和人类视觉有着很大的差异。因此可以通过在图像、物体等输入信息上添加微小的扰动改变(即上述故意干扰的“对抗样本”),就能导致很大的算法误差。此外,随着AI的进一步发展,将算法模型运用于更多类似金融决策、医疗诊断等关键核心场景,这类AI“漏洞”的威胁将愈发凸显出来。
近几年来,包括清华大学人工智能研究院院长张钹院士、前微软全球执行副总裁沈向洋等均提倡要发展安全、可靠、可信的人工智能以及负责任的人工智能,其中AI的安全应用均是重点方向。
然而AI安全作为一个新兴领域,尽管对抗样本等攻击手段日益变得复杂,在开源社区、工具包的加持下,高级攻击方法快速增长,相关防御手段的普及和推广却难以跟上。在AI算法研发和应用的过程中,对抗样本等算法漏洞检测存在较高的技术壁垒,目前市面上缺乏自动化检测工具,而大部分企业与组织不具备该领域的专业技能来妥善应对日益增长的恶意攻击。
一、从安全评测到防御升级,RealSafe让AI更加安全可控
为了解决以上痛点,近日,清华大学AI研究院孵化企业RealAI(瑞莱智慧)正式推出首个针对AI在极端和对抗环境下的算法安全性检测与加固的工具平台——RealSafe人工智能安全平台。
据了解,该平台内置领先的AI对抗攻防算法,提供从安全测评到防御加固整体解决方案,目前可用于发现包括人脸比对等在内的常用AI算法可能出错的极端情形,也能预防潜在的对抗攻击。
RealAI表示,就如网络安全时代,网络攻击的大规模渗透诞生出杀毒软件,发现计算机潜在病毒威胁,提供一键系统优化、清理垃圾跟漏洞修复等功能,RealSafe研发团队希望通过RealSafe平台打造出人工智能时代的“杀毒软件”,为构建人工智能系统防火墙提供支持,帮助企业有效应对人工智能时代下算法漏洞孕育出的“新型病毒”。
RealSafe平台目前主要支持两大功能模块:模型安全测评、防御解决方案。
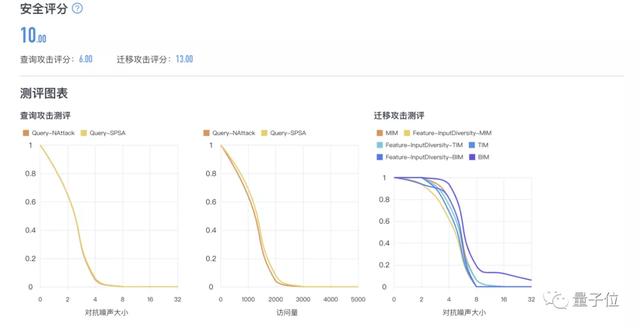
其中,模型安全评测主要为用户提供AI模型安全性评测服务。用户只需接入所需测评模型的SDK或API接口,选择平台内置或者自行上传的数据集,平台将基于多种算法生成对抗样本模拟攻击,并综合在不同算法、迭代次数、扰动量大小的攻击下模型效果的变化,给出模型安全评分及详细的测评报告(如下图)。目前已支持黑盒查询攻击方法与黑盒迁移攻击方法。
防御解决方案则是为用户提供模型安全性升级服务,目前RealSafe平台支持五种去除对抗噪声的通用防御方法,可实现对输入数据的自动去噪处理,破坏攻击者恶意添加的对抗噪声。根据上述的模型安全评测结果,用户可自行选择合适的防御方案,一键提升模型安全性。另外防御效果上,根据实测来看,部分第三方的人脸比对API通过使用RealSafe平台的防御方案加固后,安全性可提高40%以上。
随着模型攻击手段在不断复杂扩张的情况下,RealSafe平台还持续提供广泛且深入的AI防御手段,帮助用户获得实时且自动化的漏洞检测和修复能力。
二、“对抗样本”成“AI病毒”,国外主流人脸识别算法相继被“攻破”
站在人脸识别终端前,通过人脸识别摄像头完成身份校验,类似的人脸识别身份认证已经覆盖到刷脸支付、酒店入住登记、考试身份核验、人证比对等等生活场景中。
考虑到公众对于对抗样本这一概念可能比较模糊,RealSafe平台选取了公众最为熟知的人脸比对场景(人脸比对被广泛用于上述的身份认证场景中)提供在线体验。并且,为了深入研究“对抗样本”对人脸比对系统识别效果的影响,RealAI 团队基于此功能在国外主流 AI 平台的演示服务上进行了测试。
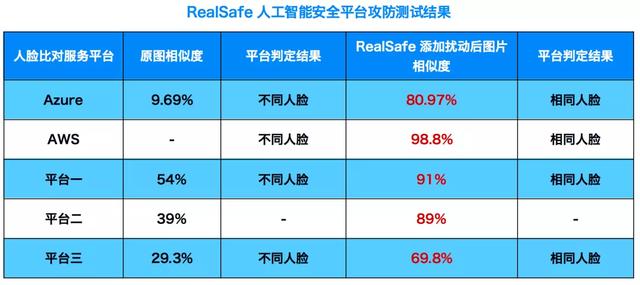
选取一组不同的人脸图片(如下图),通过RealSafe平台对其中一张图片生成对抗样本,但不影响肉眼判断,添加“对抗样本”前后分别输入到第三方人脸比对平台中查看相似度。
最终结果显示,添加“噪声”前,两张图片被 Azure、AWS 判定为不属于同一个人,但添加“噪声”后,以上两个平台的演示服务均给出了错误的结果,认为两张图片属于同一个人,甚至 Azure 平台的演示服务在添加“噪声”前后相似度变化的幅度高达70%以上。
为了探究结果的普适性,RealAI团队又选取了国内三家主流人脸比对平台进行测试,结果同样显示,添加扰动之后,原本判定为“不同人脸”的图片均被错误识别为“相同人脸”,前后相似度的变化幅度可达到20%以上。而通过RealSafe防火墙“去噪”过滤后,这几个人脸比对平台的识别“误差”获得不同程度的纠正,识别效果得到稳定提升。
RealAI团队已经将这种潜在风险以及相关防御方法反馈给上述企业,以帮助降低风险。
实测证明,“对抗样本”可以极大的干扰人脸比对系统的识别结果,据介绍,目前市面上很多中小型企业在落地人脸识别应用时大多会选择采用上文测试的这几家互联网公司开放的人脸比对SDK或者API接口,如果他们人脸比对技术存在明显的安全漏洞,意味着更广泛的应用场景将存在安全隐患。
除了人脸比对外,对抗样本攻击还可能出现在目标检测的应用场景中,延伸来看,这可能会危害到工业、安防等领域的安全风险检测。比如某电网的输电塔的监控系统,由于输电塔的高安全性防护要求,防止吊车、塔吊、烟火破坏输电线路,需要对输电塔内外进行全天候的实时监控,而这实时监控系统背后就是基于目标检测的AI算法来提供保障。
而RealAI研究团队发现,只要通过RealSafe对其中的目标检测算法进行一定的对抗样本攻击,就会造成监控系统失效,导致其无法识别非常明显的烟火情形,类似情形如果真实发生,将可能带来难以估计的损失。
事实上,像以上提到的这些AI安全风险由于都是AI底层算法存在技术缺陷而导致,往往比较隐蔽,但牵一发动全身,这些“难以预见”的风险漏洞最有可能成为被攻破的薄弱环节,而RealSafe平台同步推出的防御解决方案则可以有效增强各应用领域中AI算法的安全性。
三、“零编码”+“可量化”,两大优势高效应对算法威胁
据介绍,RealAI此次推出的算法模型安全检测平台,除了可以帮助企业高效应对算法威胁还具备以下两大优势:
- 组件化、零编码的在线测评:相较于ART、Foolbox等开源工具需要自行部署、编写代码,RealSafe平台采用组件化、零编码的功能设置,免去了重复造轮子的精力与时间消耗,用户只需提供相应的数据即可在线完成评估,极大降低了算法评测的技术难度,学习成本低,无需拥有专业算法能力也可以上手操作。比如上文中针对微软、亚马逊等第三方平台的测试,整个流程按照步骤提示完成,只需几分钟就可以查看到测评结果。
- 可视化、可量化的评测结果:为了帮助用户提高对模型安全性的概念,RealSafe平台采用可量化的形式对安全评测结果进行展示,根据模型在对抗样本攻击下的表现进行评分,评分越高则模型安全性越高。此外,RealSafe平台提供安全性变化展示,经过防御处理后的安全评分变化以及模型效果变化一目了然。
四、落地安全周边产品,为更多场景保驾护航
其实对抗样本原本是机器学习模型的一个有趣现象,但经过不断的升级演化,“对抗样本”已经演变成一种新型攻击手段,并从数字世界蔓延到物理世界:在路面上粘贴对抗样本贴纸模仿合并条带误导自动驾驶汽车拐进逆行车道、胸前张贴一张对抗样本贴纸在监控设备下实现隐身……
所以,除了针对数字世界的算法模型推出安全评测平台,RealAI团队也联合清华大学AI研究院围绕多年来积累的领先世界的研究成果落地了一系列AI攻防安全产品,旨在满足更多场景的AI安全需求。
比如,攻击技术方面,RealAI团队实现了世界首个通过“对抗样本”技术实现破解商用手机刷脸解锁,让手机将佩戴“特制眼镜”的黑客误识为机主。
△ 图:世界唯一通过AI对抗样本技术攻破商用手机人脸解锁案例
通过在目标人服装上张贴特制花纹使AI监控无法检测到该人物,实现“隐身”,以及通过在车辆上涂装特殊花纹,躲避AI对车辆的检测。
△ 图:通过AI对抗样本图案躲避AI车辆检测
在发现以上各种新型漏洞的同时,RealAI也推出相应的防御技术,支持对主流AI算法中的安全漏洞进行检测,并提供AI安全防火墙对攻击AI模型的行为进行有效拦截。
人工智能的大潮滚滚而来,随之而来的安全风险也将越来越多样化,尤其近年来因AI技术不成熟导致的侵害风险也频频发生,可以说,算法漏洞已逐渐成为继网络安全、数据安全后又一大安全难题。
所幸的是,以RealAI为代表的这些顶尖AI团队早已开始了AI安全领域的征程,并开始以标准化的产品助力行业降低应对安全风险的门槛与成本。此次上线RealSafe人工智能安全平台是RealAI的一小步尝试,但对于整个行业而言,这将是人工智能产业迈向健康可控发展之路的一大步。








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}