
本文内容为哔站学习笔记【卷积神经网络-CNN】深度学习(唐宇迪带你学AI):卷积神经网络理论详解与项目实战,计算机视觉,图像识别模块实战_哔哩哔哩_bilibili
目录
加载models中提供的模型,并且直接用训练的好权重当做初始化参数
深度学习基础
什么是深度学习?
深度学习是机器学习的一部分,效果比较好。
神经网络(CNN)不应该称之为一种算法,应该当做一种特征提取的方法。
机器学习流程
数据获取——特征工程——建立模型——评估与应用
特征工程最为重要最核心的一部分。
深度学习一定程度上解决了机器学习上人工的部分问题。可以自行判断提取特征,选择最适合的方法来处理。而机器学习需要人为的提取特征
特征工程的作用
- 数据特征决定了模型的上限。
- 预处理和热证提取是最核心的。
- 算法与参数选择决定了如何逼近这个上限。
特征如何提取

为什么需要深度学习
深度学习是真正能够学什么样的特征是最合适的。
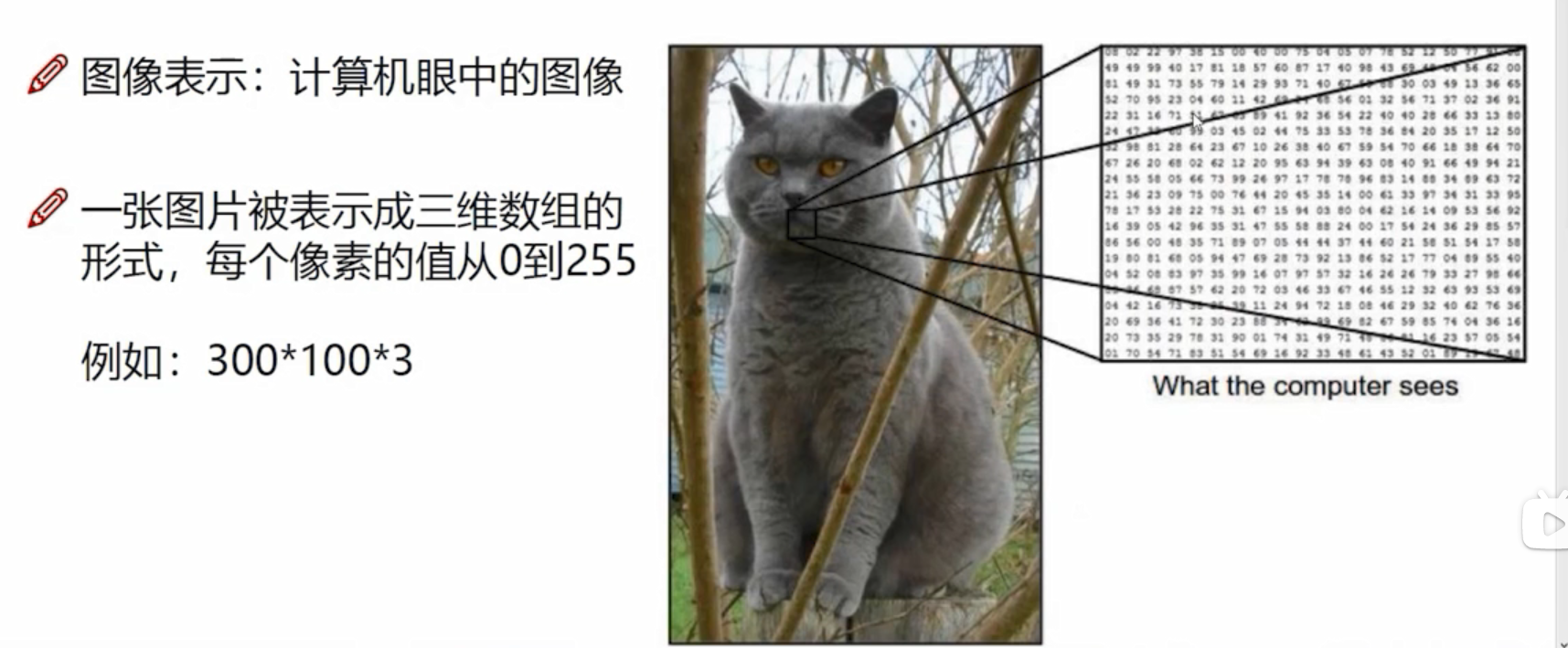
解决的核心是怎么样去提取特征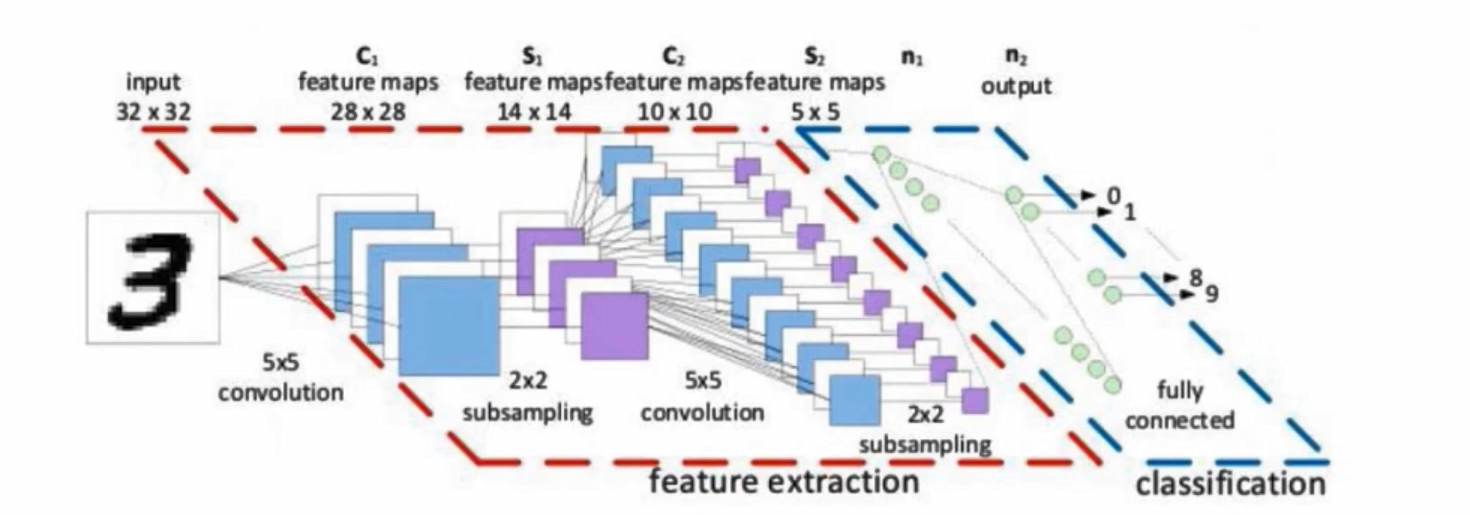
深度学习的应用
可以在计算机视觉及自然语言处理中做一些东西
人脸识别
医学方面的应用
换脸操作
影片复原
应用非常广泛
深度学习缺点
深度学习计算的量非常大,速度可能太慢了。
传统算法与深度学习
计算机视觉

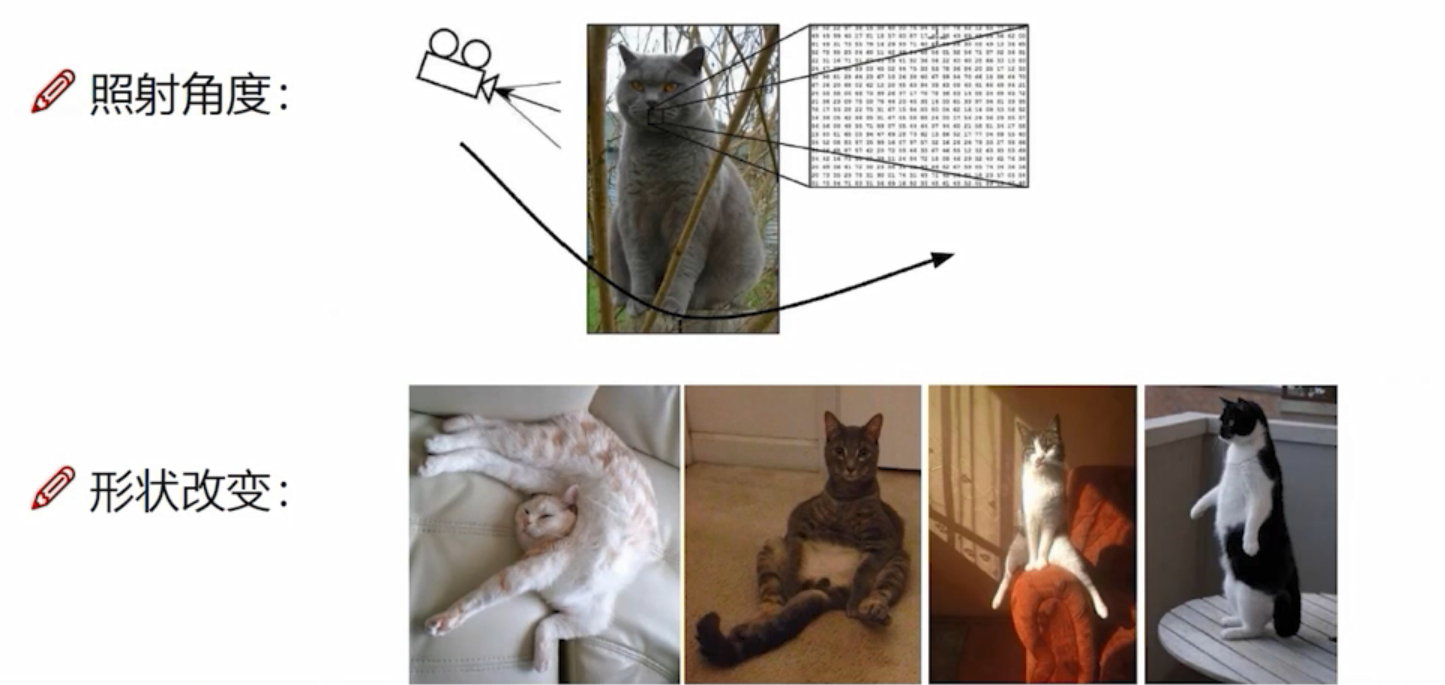
计算机视觉面临的挑战

机器学习常规套路
- 收集数据并给定标签
- 训练一个分类器
- 测试,评估
K近邻
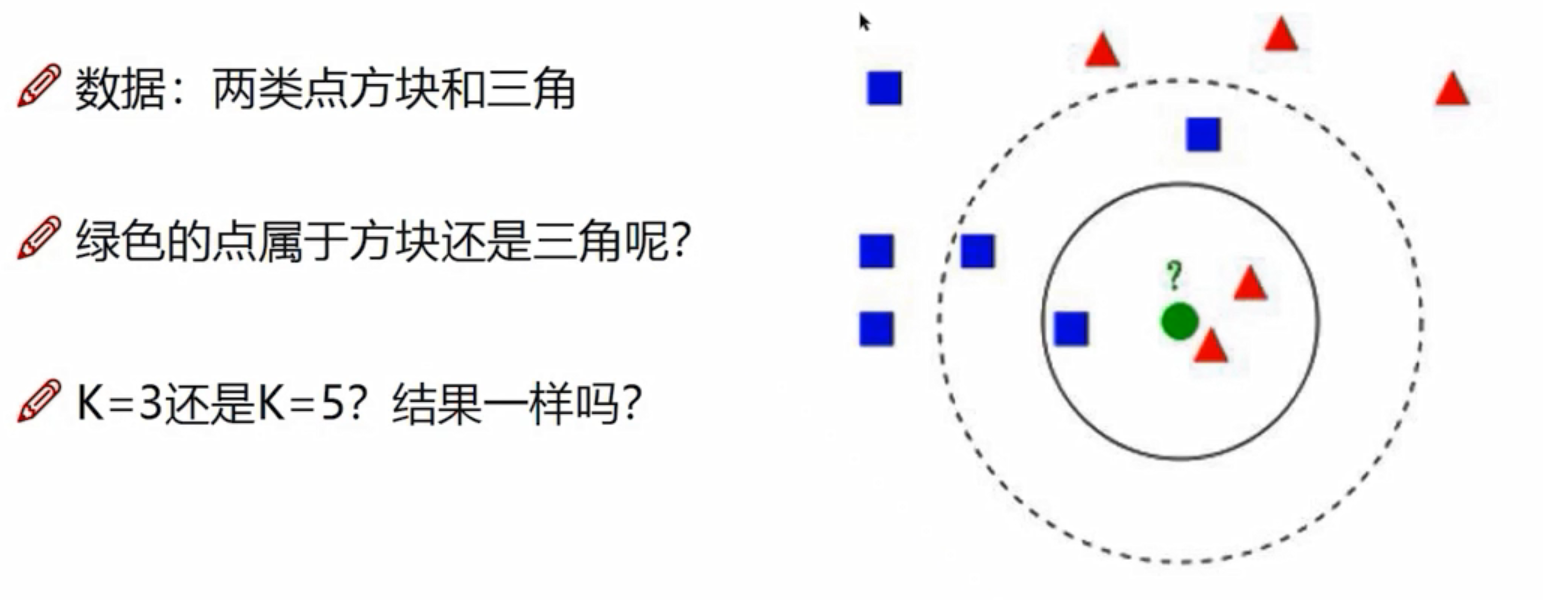 K=3,三角;K=5,方块。
K=3,三角;K=5,方块。
K近邻计算流程
- 计算已知类别数据集中的点与当前点的距离
- 按照距离依次排序
- 选取与当前点距离最小的K个点
- 确定前K个点所在类别的出现概率
- 返回前K个点出现频率最高的类别作为当前点预测分类
K近邻分析
- KNN算法本身简单有效,它是一种lazy-learning算法。
- 分类器不需要使用训练集进行训练,训练时间复杂度为0。
- KNN分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为n,那么KNN的分类时间复杂度为O(n)。
- K值的选择,距离度量和分类决策规则是该算法的三个基本要素
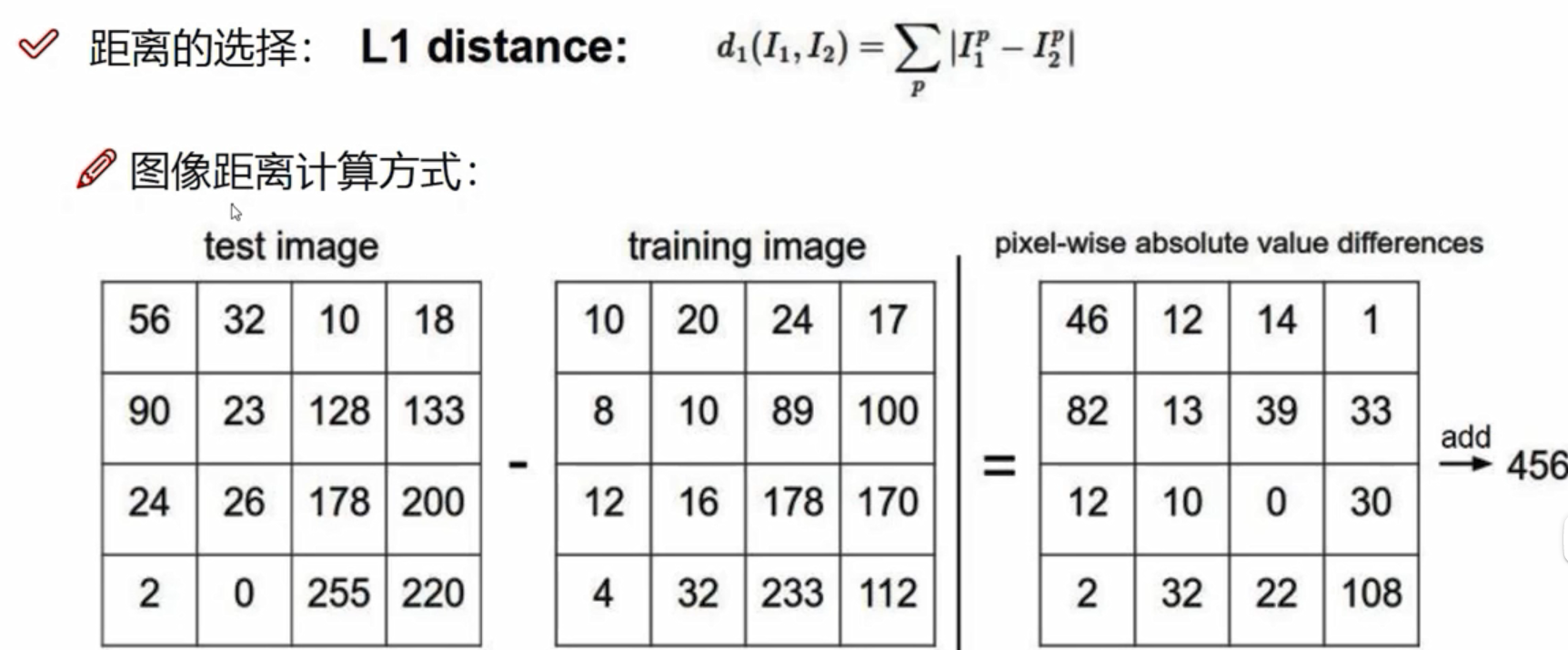
数据库样例:CIFAR-10
K近邻做图像分类


问题在于图像中有些东西没有注意到,没有告诉主体与背景
为什么K近邻不能用来图像分类
- 背景主导是一个最大的问题,我们关注的却是主体(主要成分)
如何才能让机器学习到哪些是重要的成分呢?
神经网络基础
线性函数
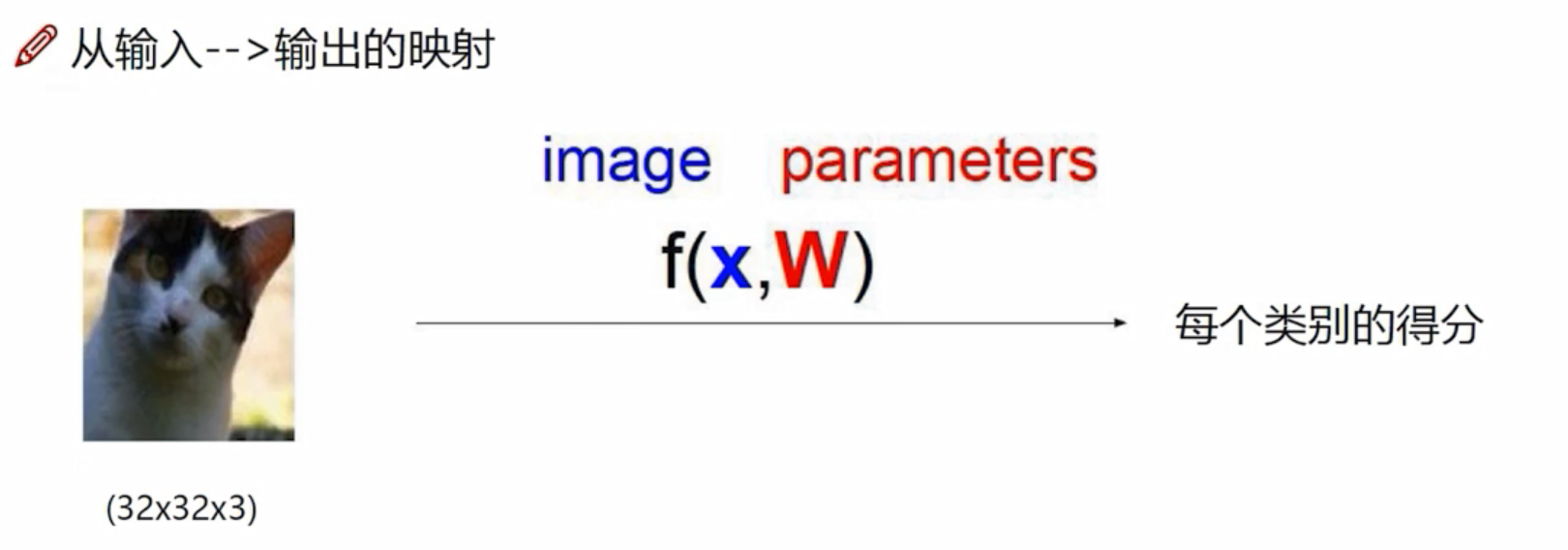
眼睛、耳朵、背景等的像素点对结果的影响是不一样的,有些像素点对于它是猫起到促进作用 ,有些则是抑制作用。所以每个像素点对应的重要程度是不一样的,W称之为权重参数。
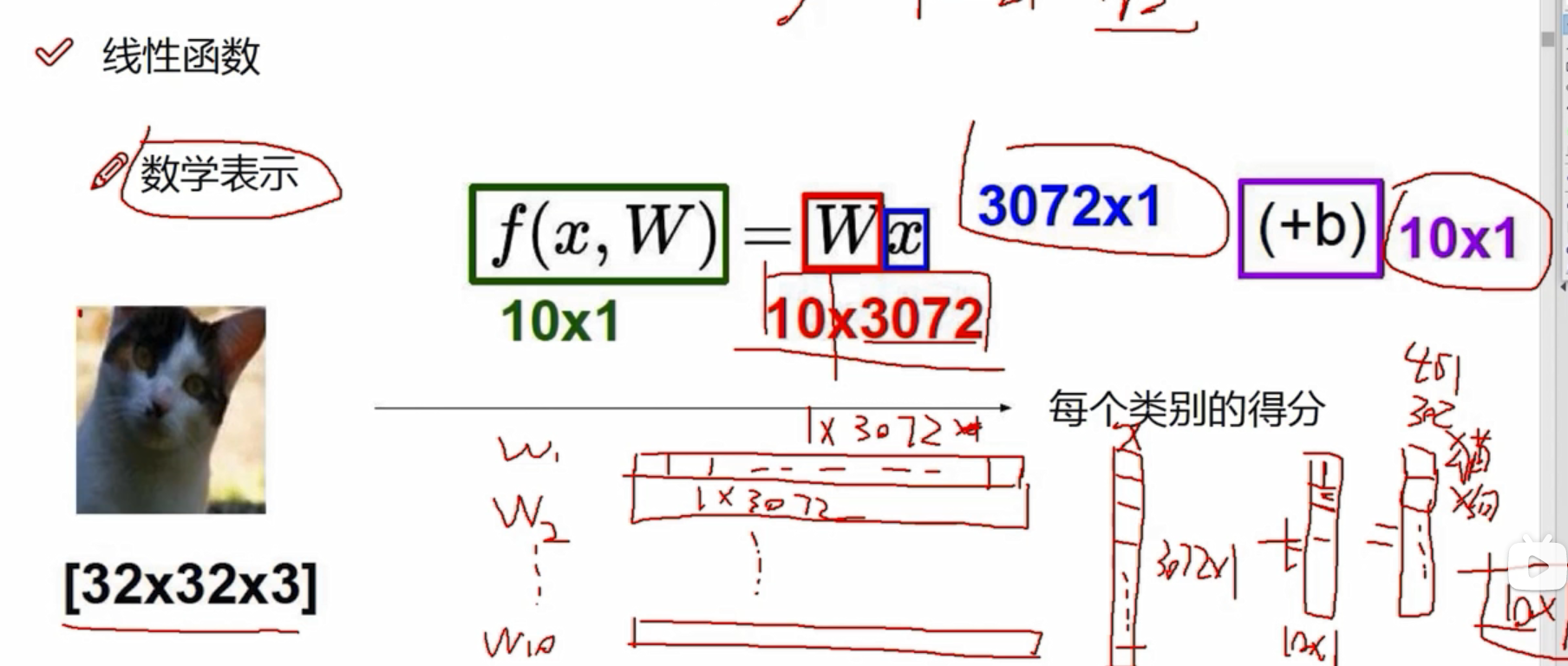
3072个像素点,每个像素点在当前类别都有自己的权重,3072个像素点有3072个权重,比如该像素点在猫类有猫类的权重、在狗类有狗类的权重,只是权重大小值不一样。若分为10个类别,则有10*3072个权重参数,即W是10*3072的矩阵;x代表3072个像素点,是3072*1的矩阵。
W*X是10*1的矩阵,即每个类别的得分的结果。
b是偏置参数,是10*1的矩阵,起微调作用,每个类别有自己的微调值。
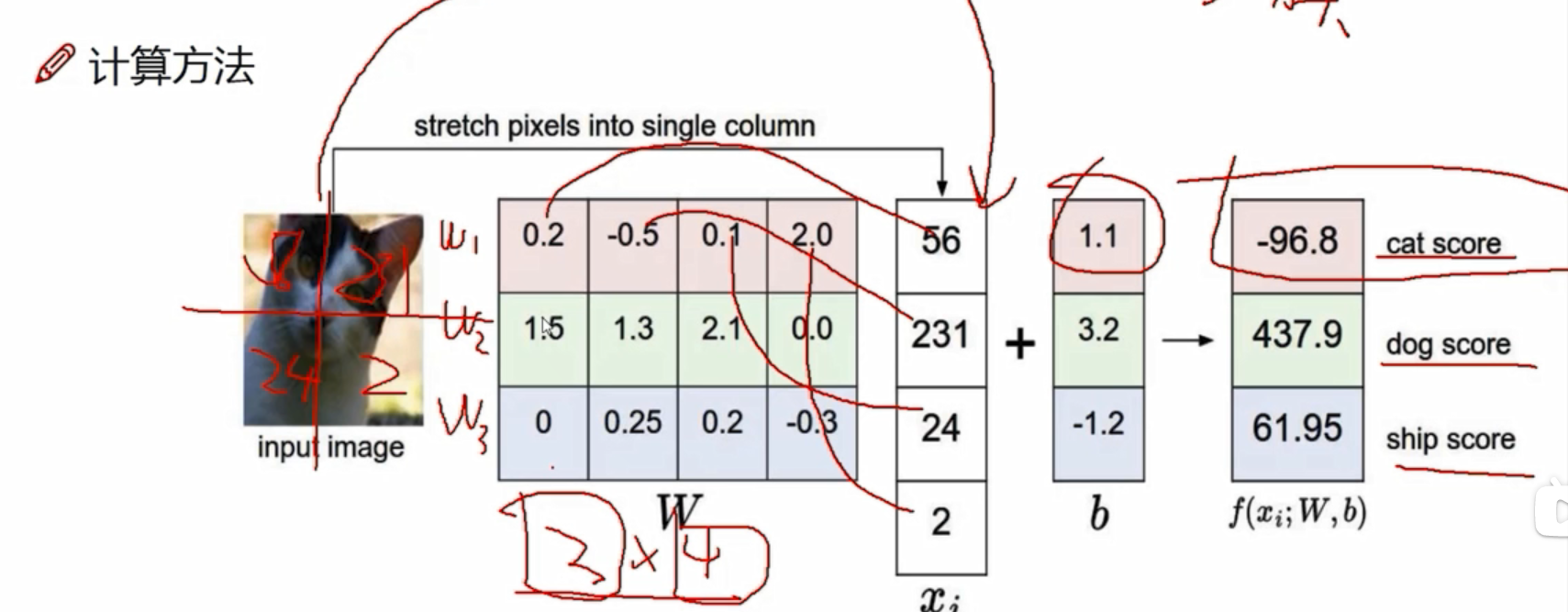
- 假设这个猫由四个像素点构成,x是4*1的矩阵,有三个类别: 猫、狗、船;W是3*4的矩阵,3代表三个类别,4代表4个像素在各类别的权重参数;b是3*1的偏置参数。
- W中较大的值代表:在这种类别中,该像素的影响是比较大的,比如2.1代表在狗这一类中,像素值为24的影响是2.1,0代表不太重要。
- W中±代表:正值代表促进作用,负值代表抑制作用
W中权重值是怎么来的呢?
权重值是优化而来的 ,一开始的权重值可以设为随机数,比如上图,明明是个猫,最后结果分类却是狗。原因何在?
数据是不变的,当图像输入后,x的值是不变的,但是W的值是可以改变的。
神经网络做的事就是优化W,使W能更适合于数据去做当前这个任务。
W一开始可以设随机值。接下来在迭代过程中,想一种优化方法,不断改进W参数。
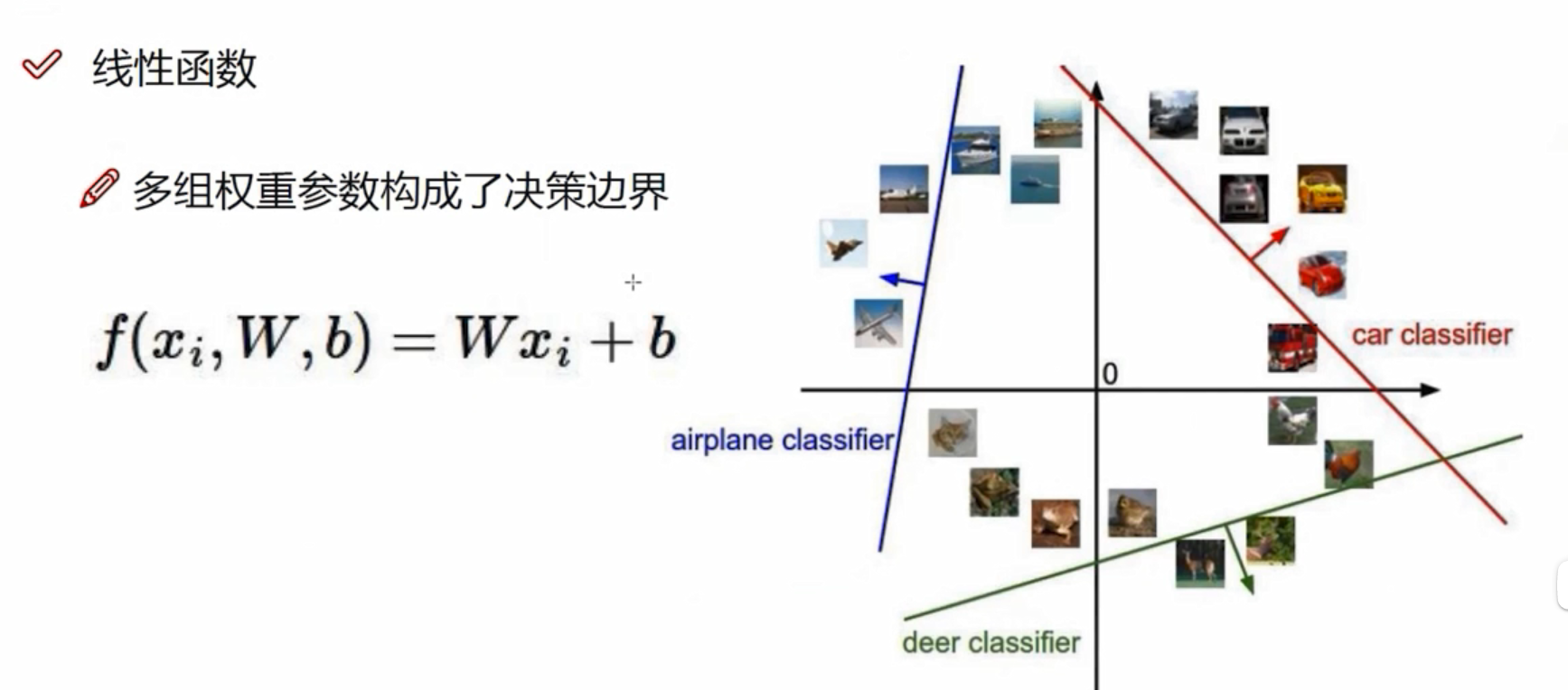 权重参数控制着决策边界的走势,偏置参数只是做一个微调。
权重参数控制着决策边界的走势,偏置参数只是做一个微调。
损失函数


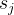 :其他错误类别
:其他错误类别
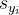 :正确类别
:正确类别
相当于一个容忍程度,0代表无损失,当正确与错误得分相近的时候,有可能区别不出来,这时候+1可以更好地区分错误与正确的结果。

A与B模型不一样,A会产生过拟合,是不希望出现的,所以在构建损失函数当中,还需要加上正则化惩罚项

R(W):只考虑权重参数,10个分类则R(W)=W1平方+W2平方+...+...+W10平方
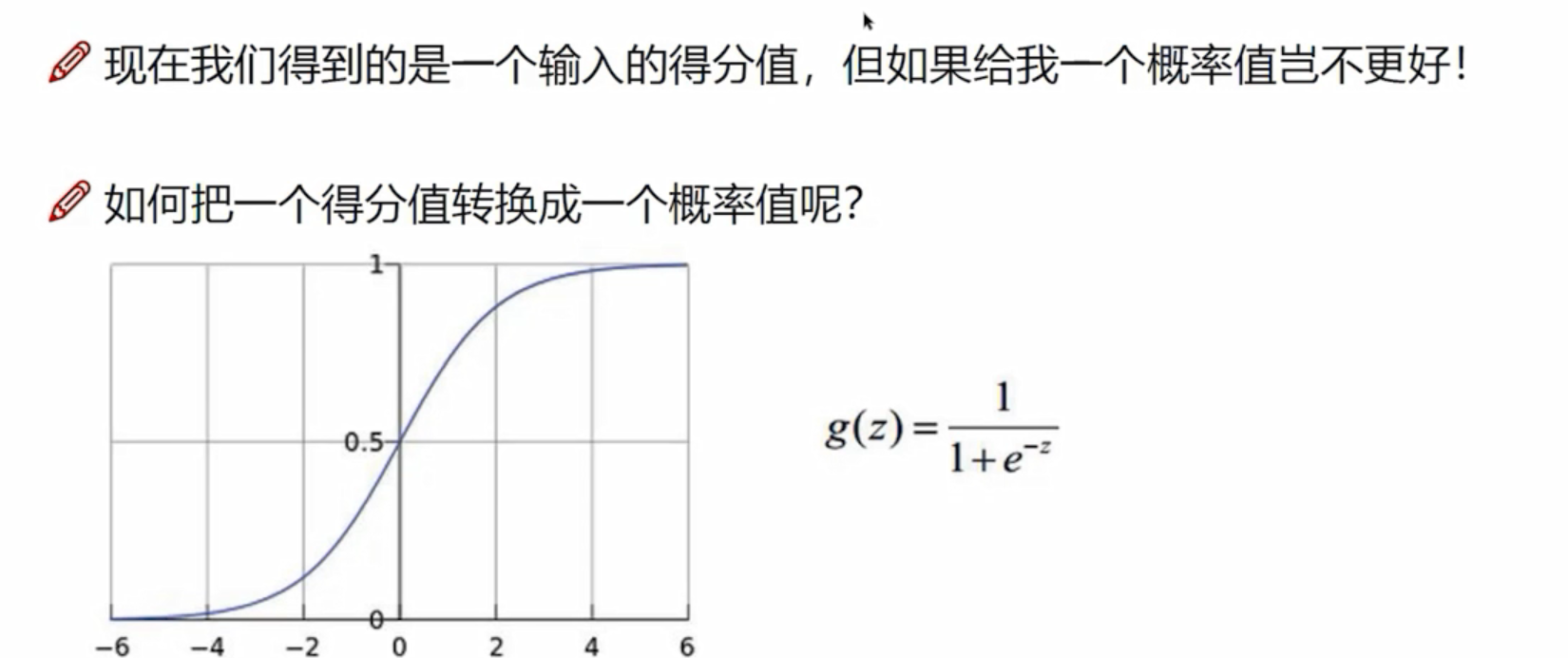
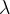 :惩罚系数,值越大代表不希望过拟合,正则化惩罚大一些;
:惩罚系数,值越大代表不希望过拟合,正则化惩罚大一些;
Softmax分类器

exp: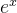 做一个映射,
做一个映射,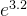 =24.5,5.1映射后成为164,-1.7映射成为0.18
=24.5,5.1映射后成为164,-1.7映射成为0.18
归一化:该项得分/全部加起来
计算损失值:输入的是正确类别的概率值;正确图像本来是一个猫,但是毛的概率值为0.13,所以损失值L=-log(0.13)=0.89
前向传播
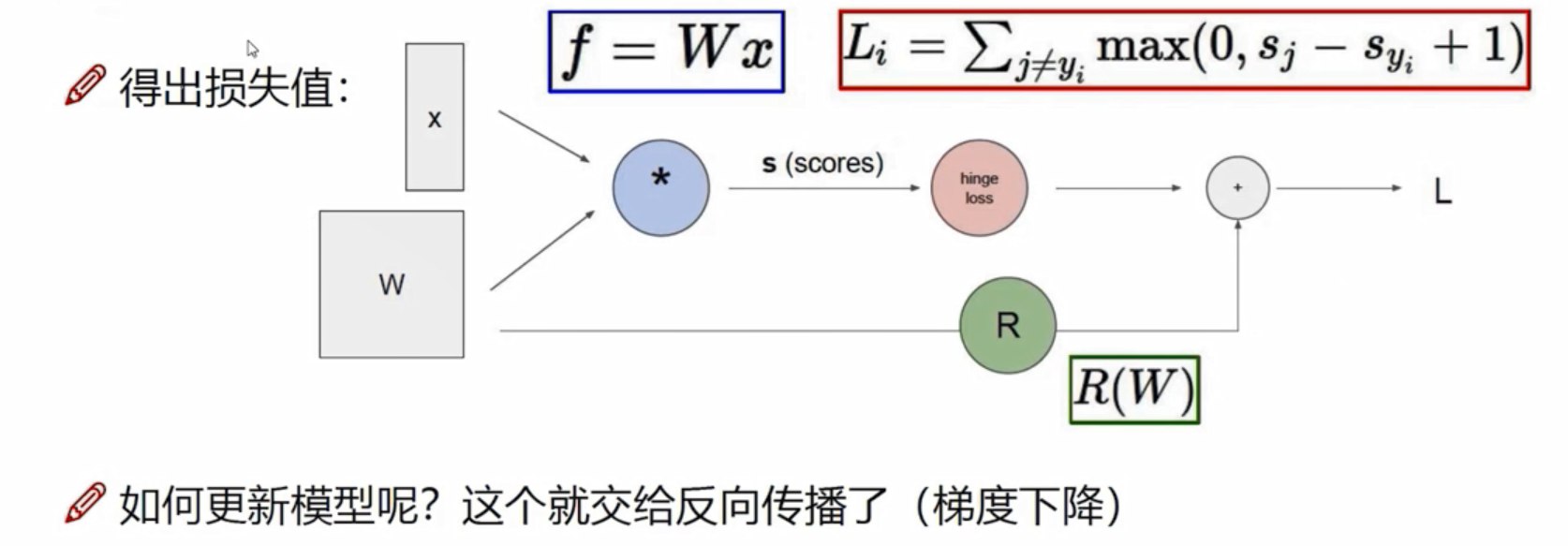 从W,x到最后得到损失值L这一步,叫做前向传播。更新模型,优化W,则需要梯度下降
从W,x到最后得到损失值L这一步,叫做前向传播。更新模型,优化W,则需要梯度下降
卷积神经网络
卷积神经网络能做哪些事情?
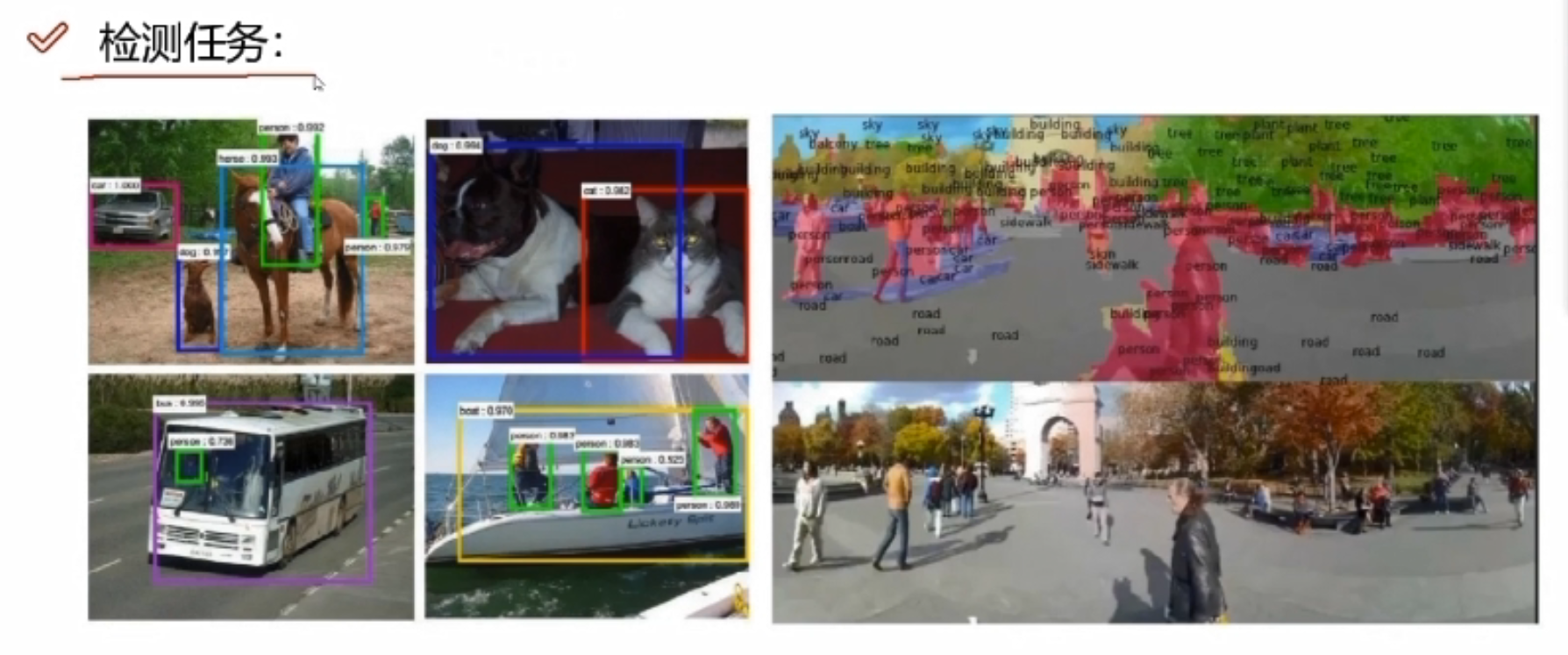

检索:输入一张图像,返回类似结果。


卷积网络与传统网络的区别
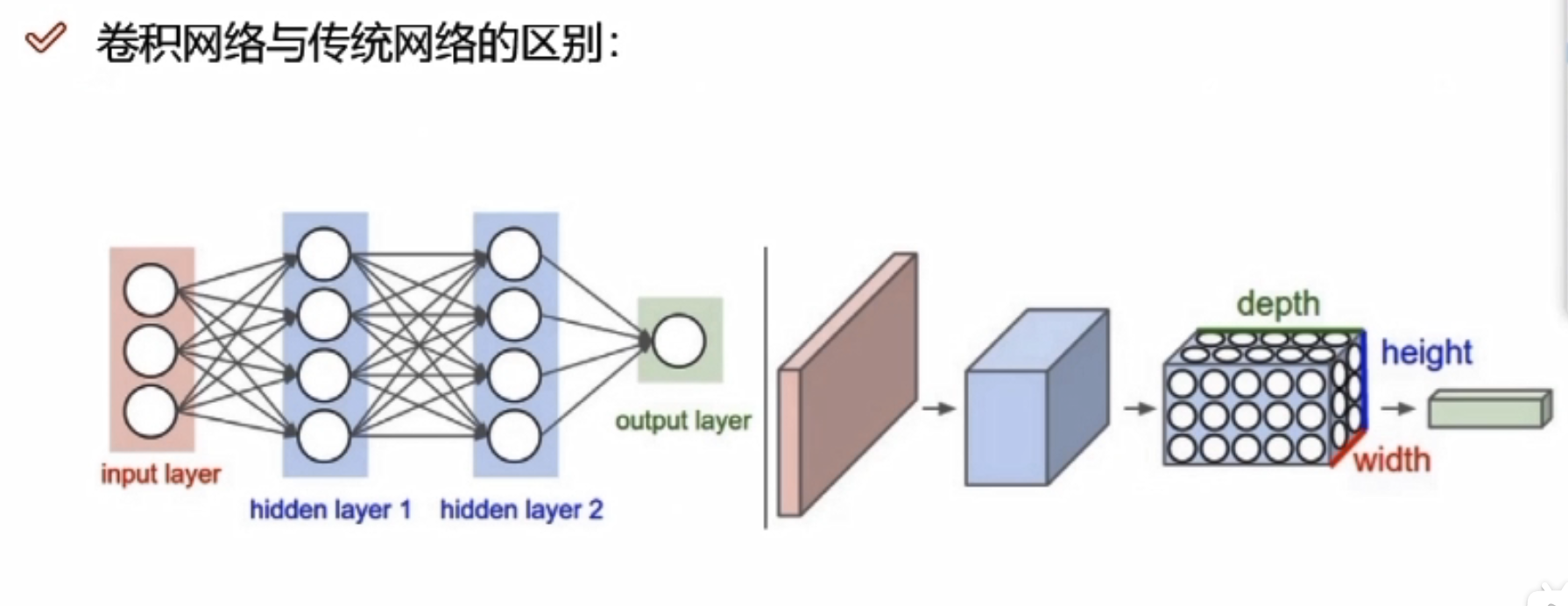
左边是传统网络(NN),右边是卷积网络(CNN),左边输入的是像素点,右边输入是图像
比如左边输入784,是784个像素点,而右边是28*28*1的图像,是三维的
卷积网络不会先把数据拉成一个向量,而是直接对图像数据进行特征提取。是h*w*c的
整体架构
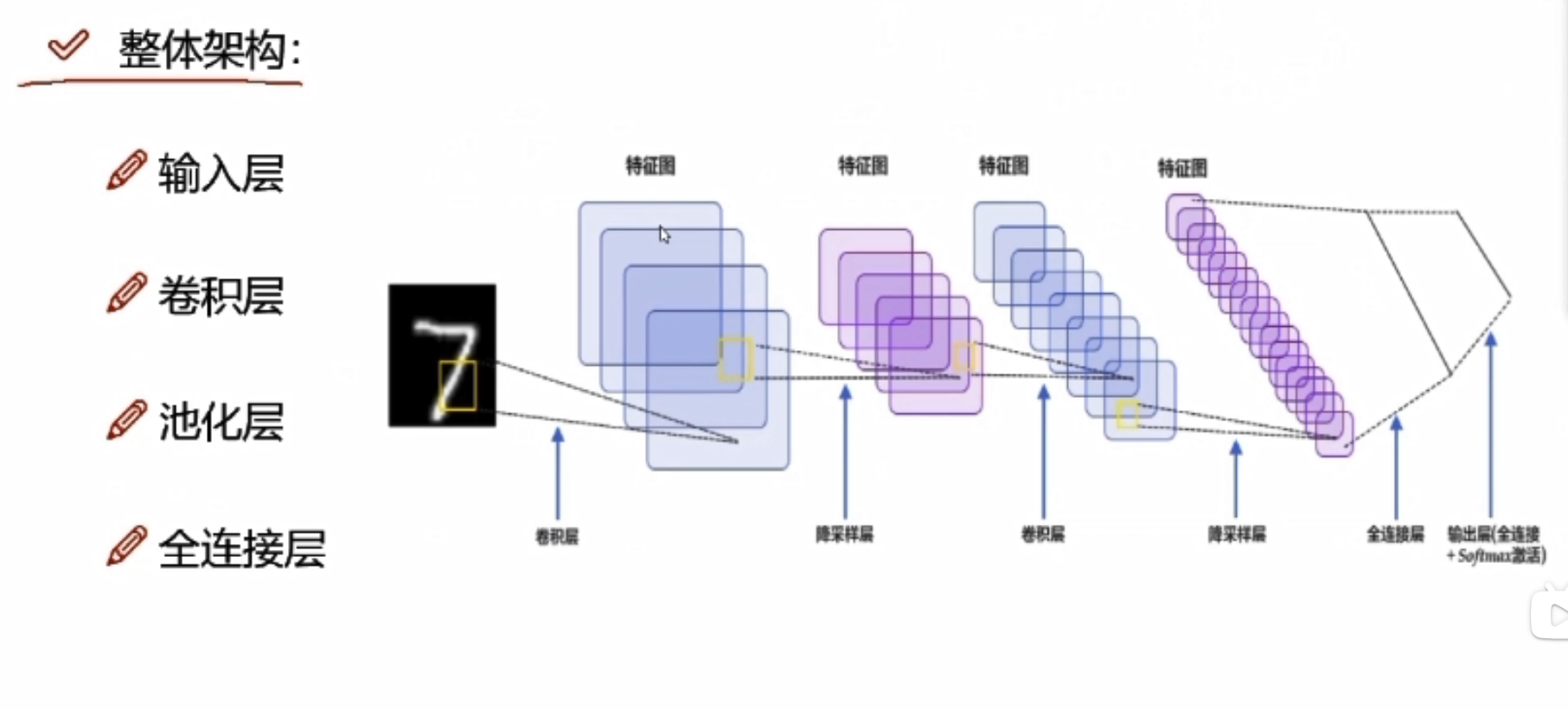
输入层是输入图像,三维的,卷积是提取特征,池化是压缩特征
卷积层
卷积做了什么事?

图像数据不同区域的特征是不一样的,重要程度也是不一样的
先把图像分割成不同的区域,每个区域再提取不同的特征,和神经网络一样,也是用一组权重参数来得到特征值
蓝色图像中的3*3可以当做图像数据中的一个分割后的小区域(每3*3分割),而下标数字则是这个区域对应的权重参数矩阵。最后还是得到一个值12,12是当前这个分割区域的代表值。
绿色图表示执行一次卷积后得到的特征图
 RGB
RGB
32*32*3,3代表三个颜色通道
实际做计算的时候,需要每个颜色通道都算一遍,最终将每个颜色通道卷积完成的结果加起来
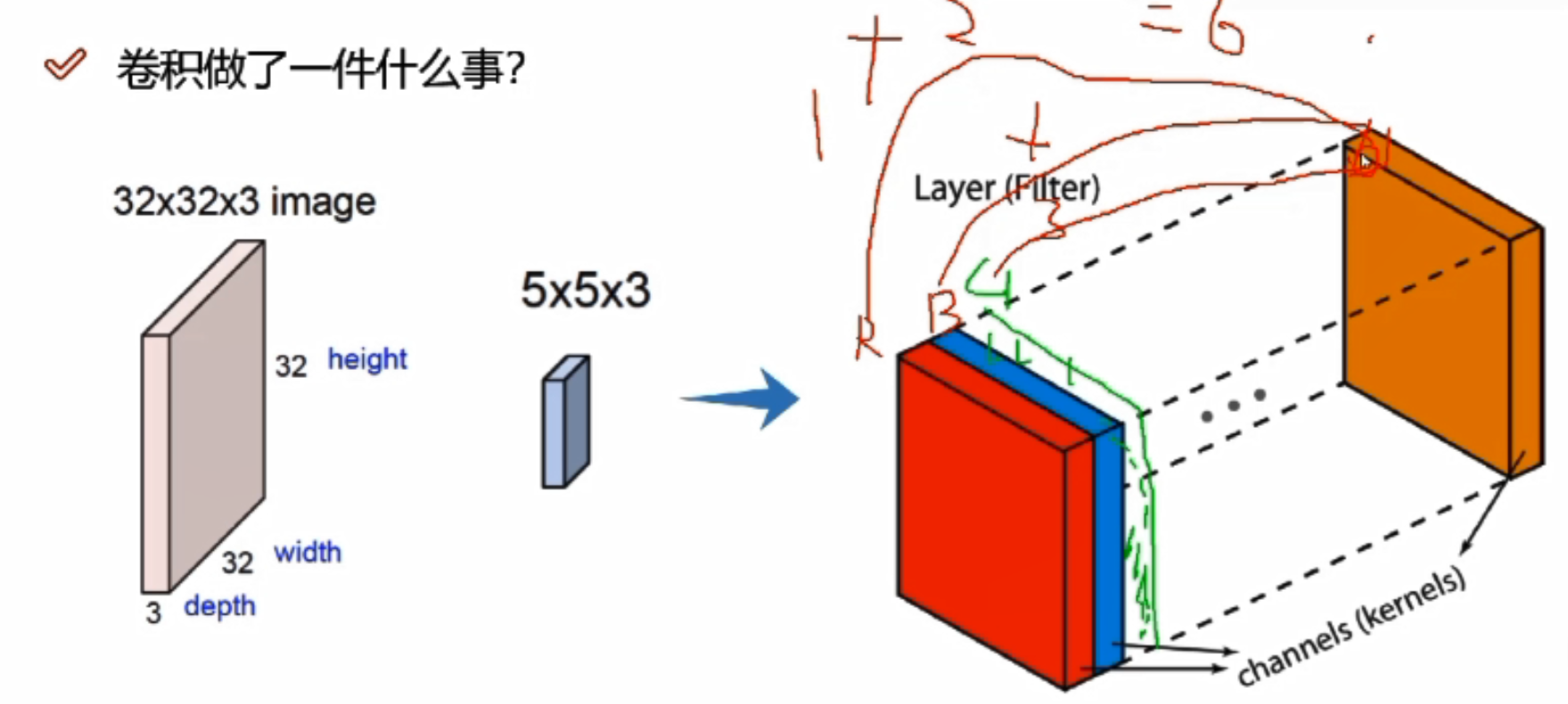
比如三个颜色通道,在对应分割区域上,R/G/B各计算一次,假设R通道对应结果为1,B通道对应结果为2,G通道对应结果为3,则最终结果为1+2+3=6
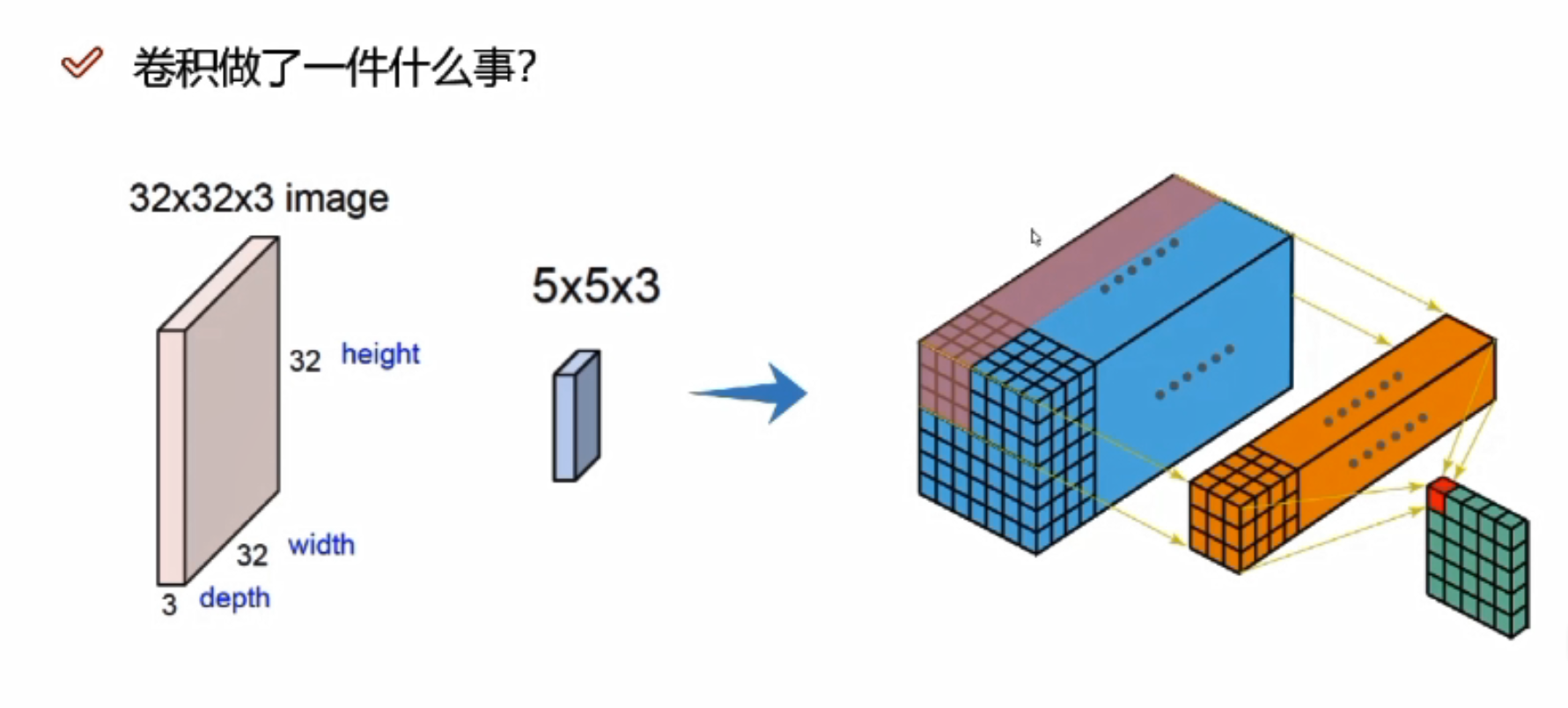
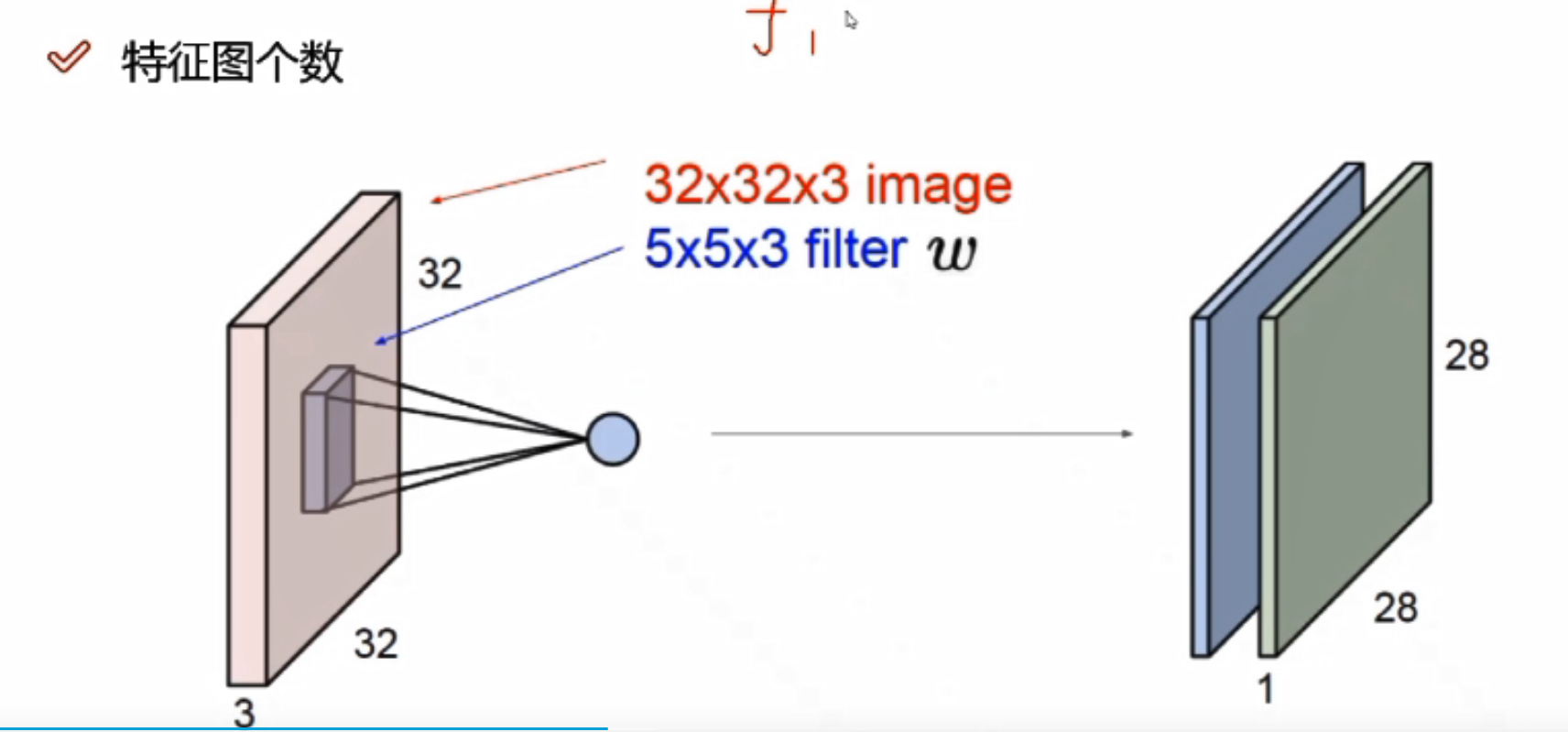
不同的权重参数会得到不同的特征图,可以有很多个
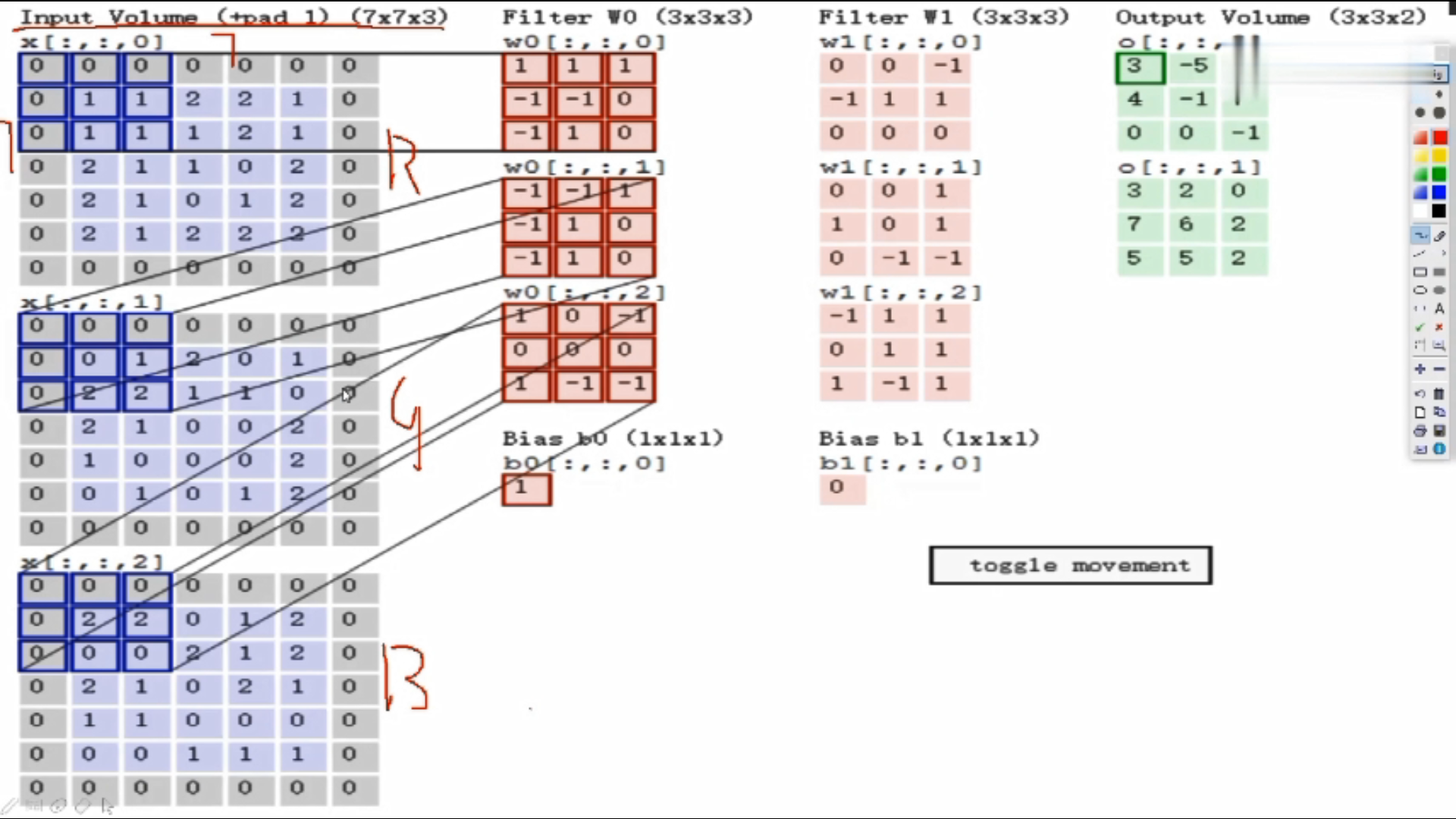
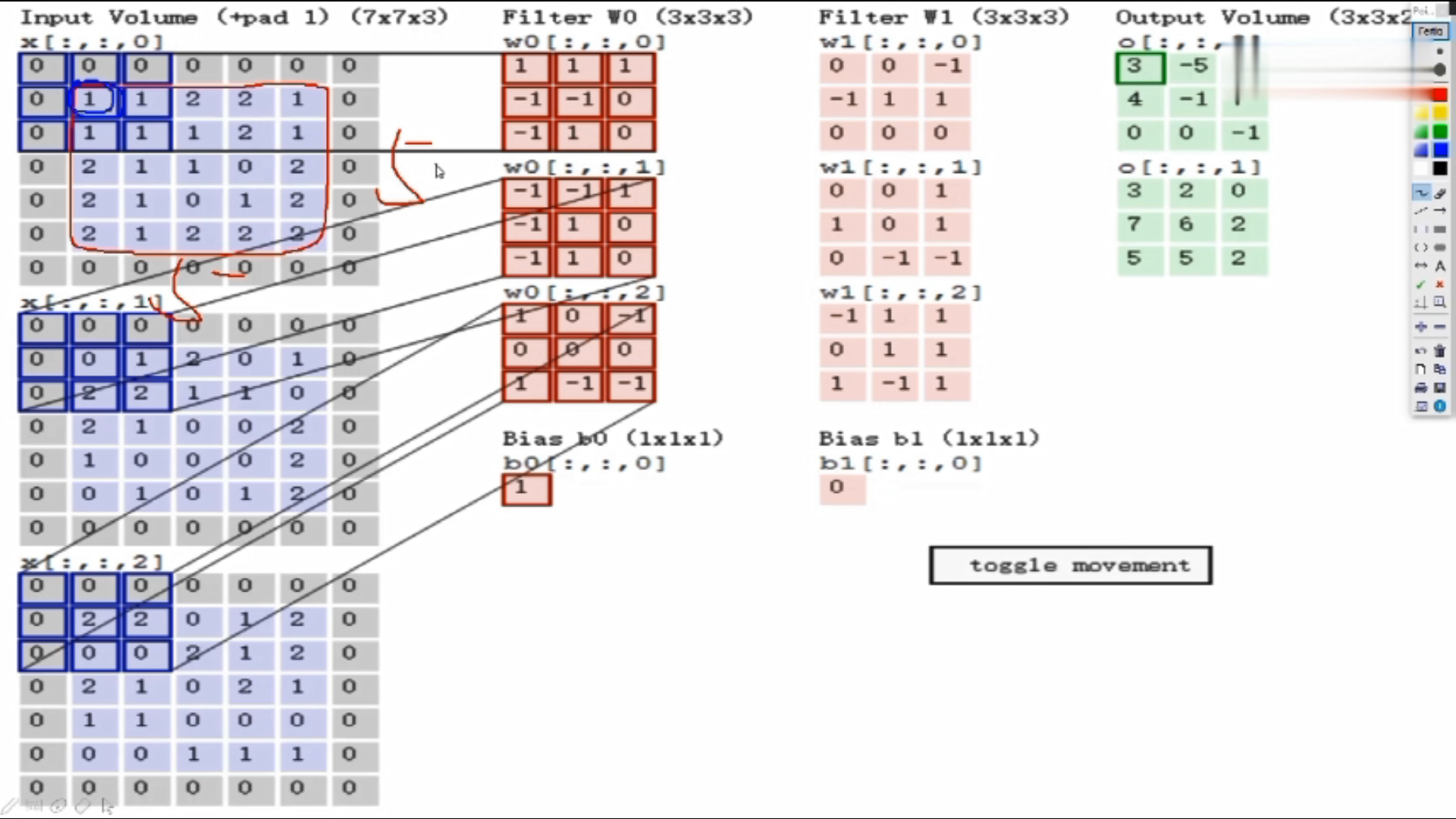
假设输入数据7*7*3
Filter W0:表示随机化一组权重参数,前两个3*3是卷积核,表示选择的区域是3*3的大小,即每3*3的区域选出来一个特征;三个通道的值是不一样的,因为通道不同像素值不同。
计算: 使用内积做计算,即对应位置相乘,所有结果加在一起。 如:上图三个颜色通道的计算内积结果分别为0、2、0,最终结果为三个颜色通道加在一起为0+2+0+b,b为偏置项,此图b=1,所以最终结果为3,即第一个3*3的区域对应的结果为3
Fliter W1:W1与W0规格相同,不同值
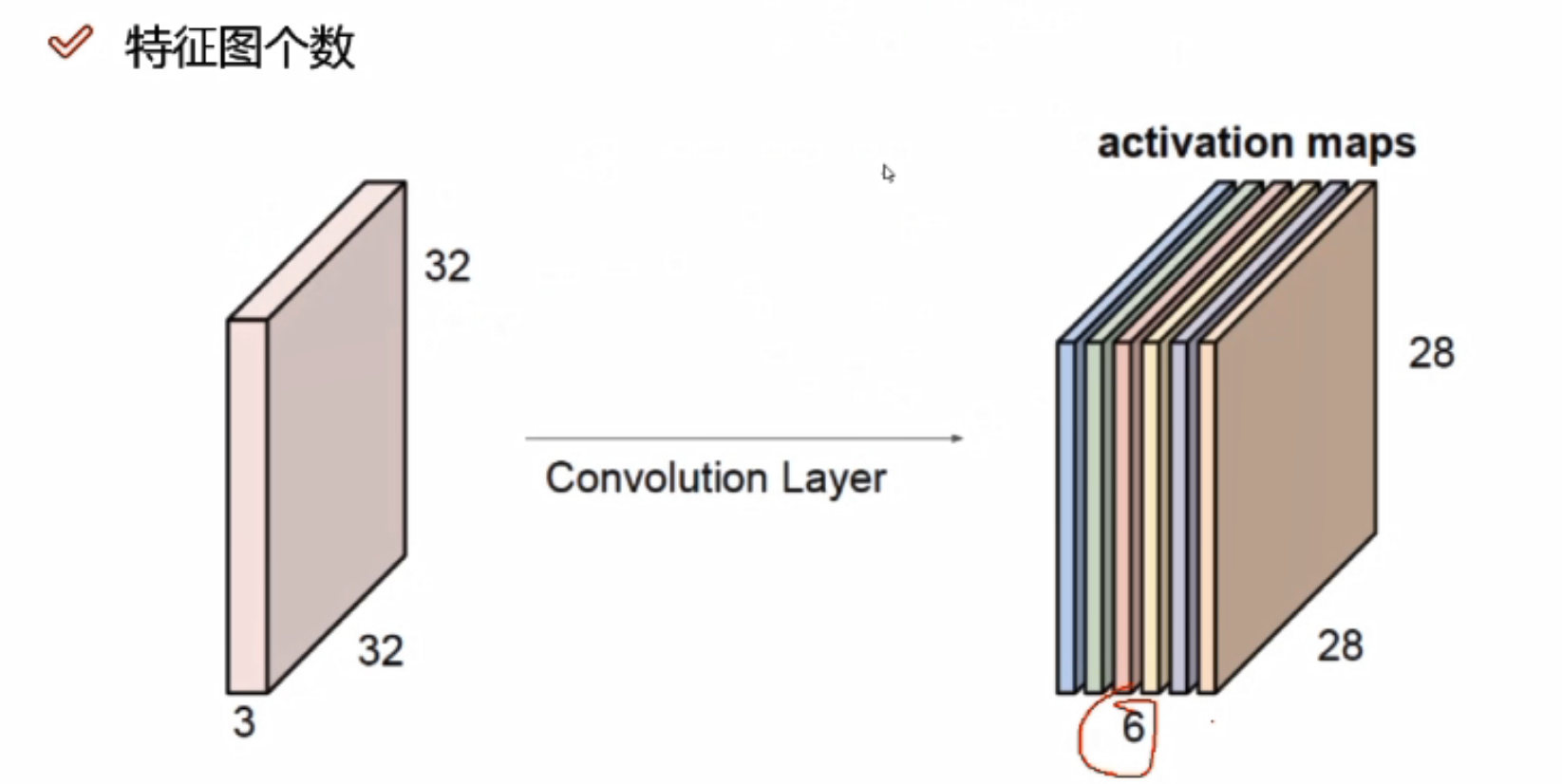
绿色图是3*3*2的,2代表深度,即特征图的个数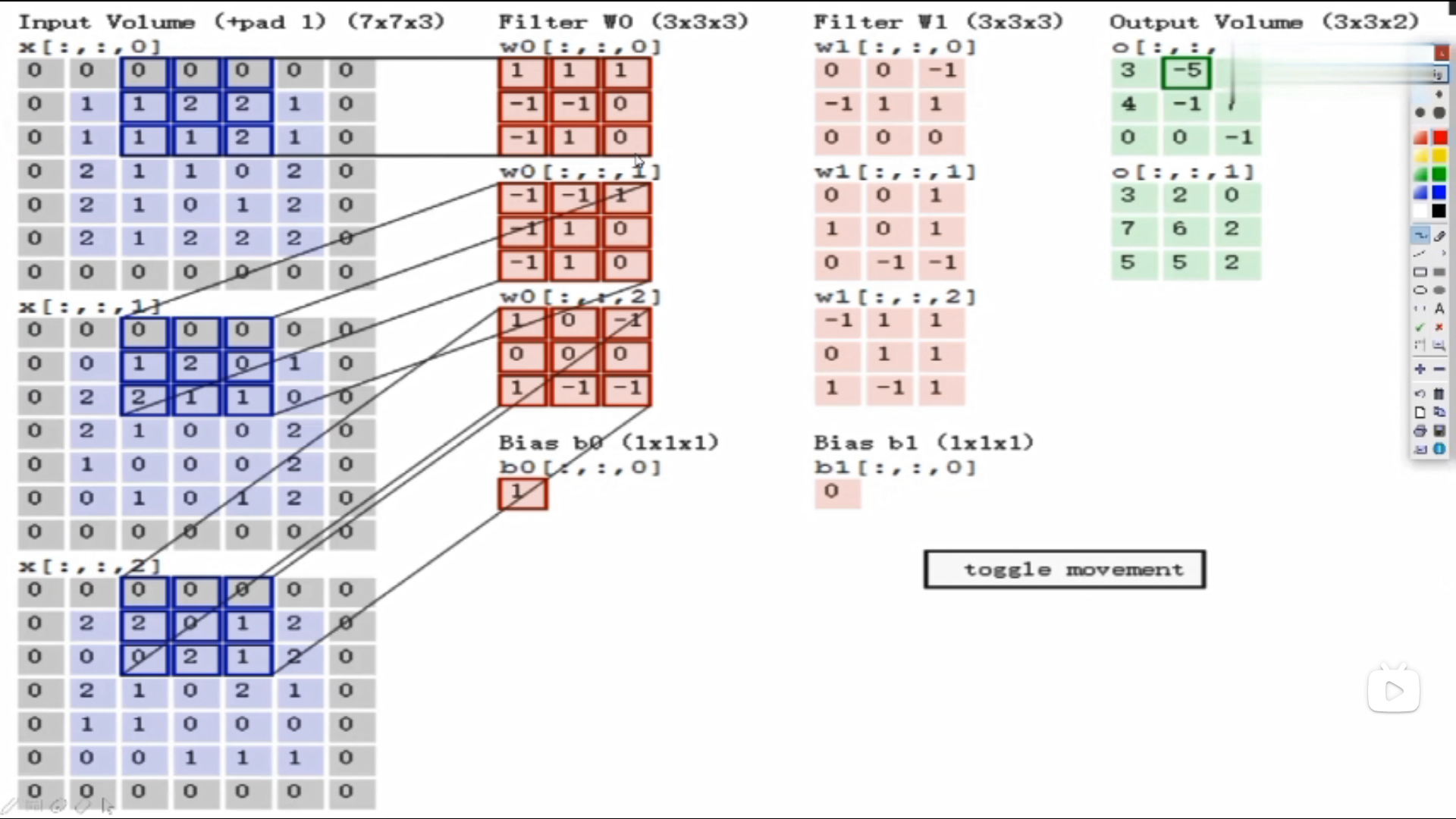
在第一个区域做完之后,该下一个区域了,往后平移了两格(可以自己设置大小),以此类推
只做一次卷积就可以了吗?
 做一次是不够了,需要好多次
做一次是不够了,需要好多次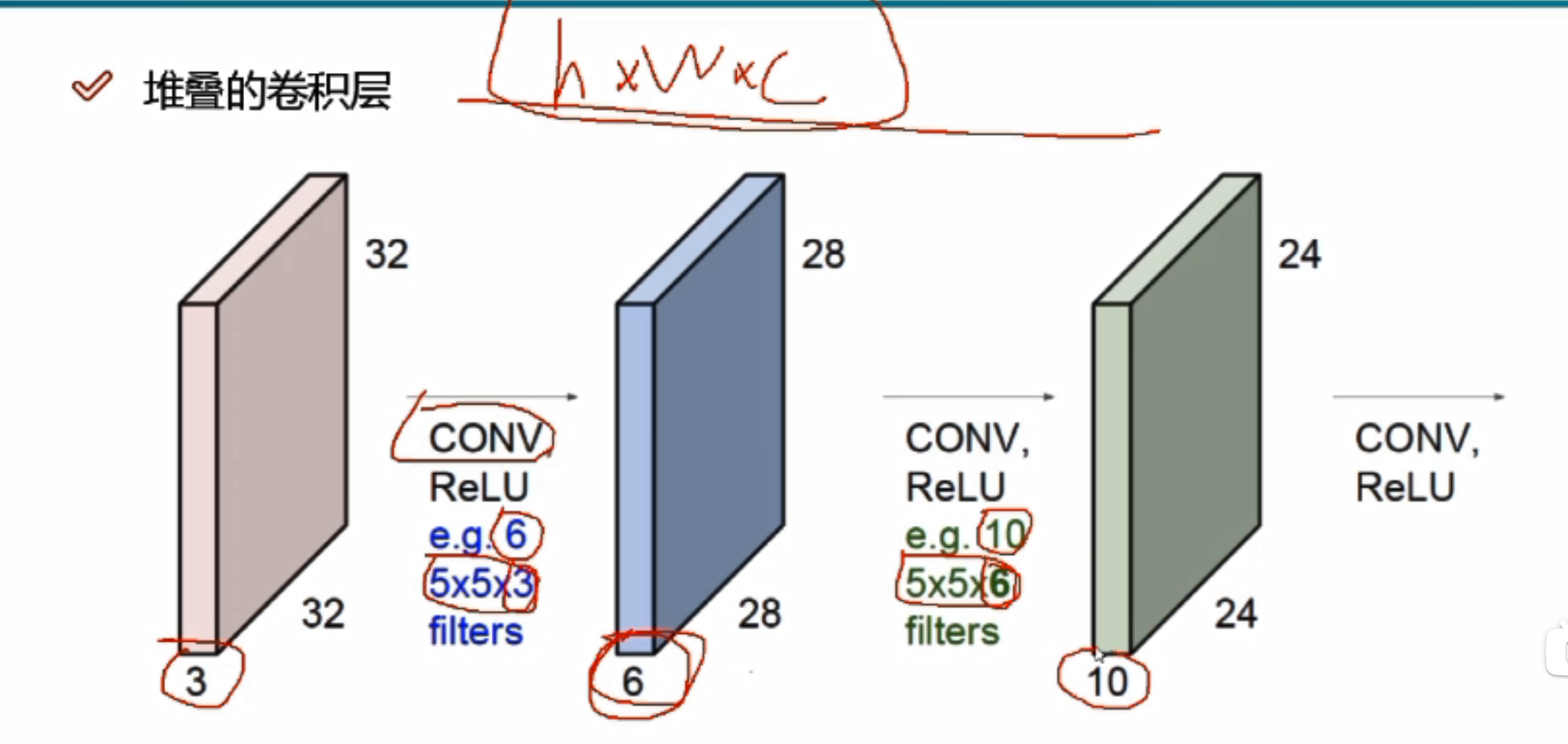
输入:32*32*3
e.g.6代表6个不同的filters,生成的特征图有6层
卷积核深度必须与前一个的输入数据的深度一致
卷积层涉及参数
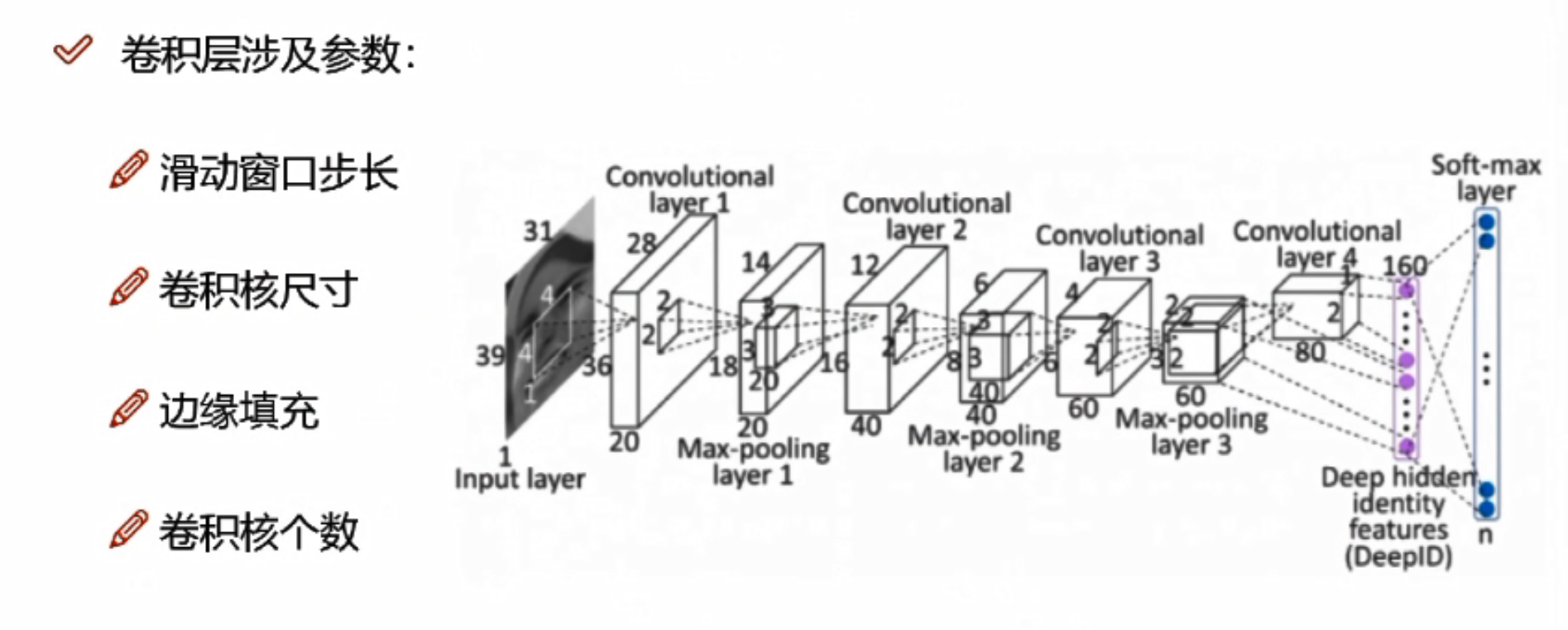
卷积核步长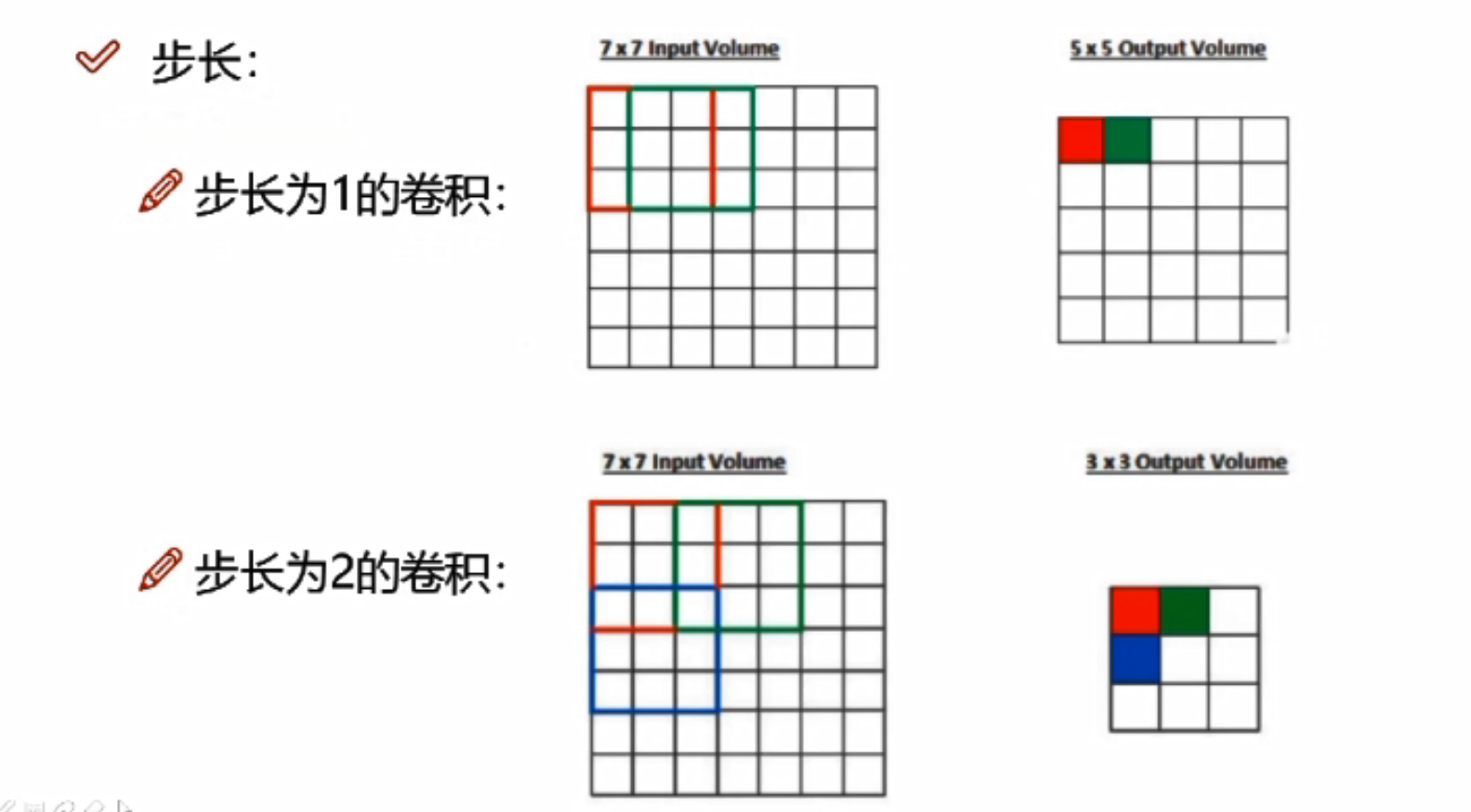
步长越小,提取图像特征越细腻,效率也就越慢。一般为1
步长每+1,特征图h与w多减2
卷积核尺寸
3*3的与4*4的区域大小不同,卷积核尺寸越小,提取图像特征越细腻。一般3*3
边缘填充
图像数据越靠近边缘,对特征提取的影响越小,越靠近中间,计算的次数越多,对于特征提取的结果影响越大。边界填充,可以将原来图像的边界置内,可以增大特征提取的程度,一定程度上避免了信息缺失。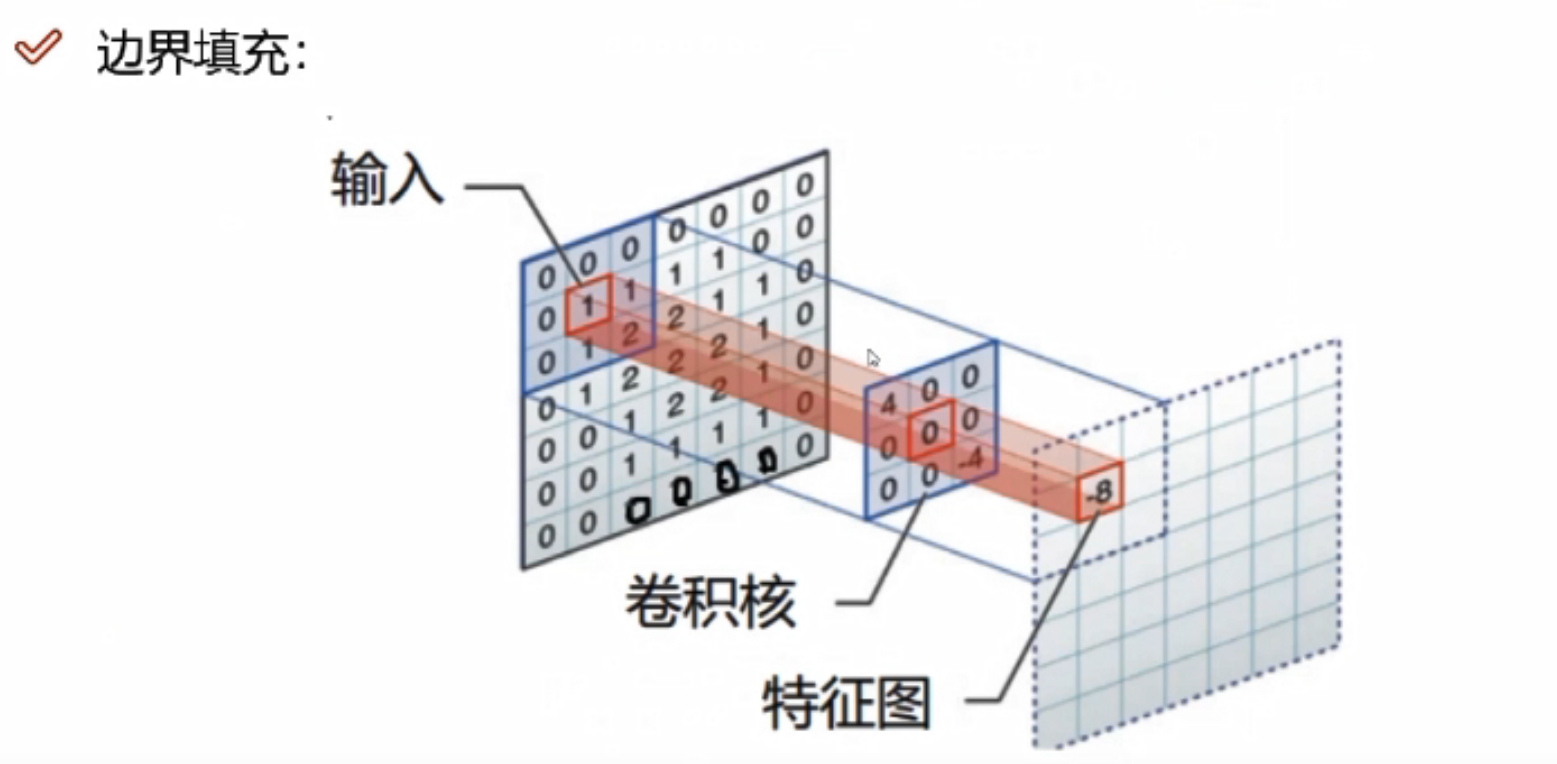
为什么选择加0,而不加其他值?
当添加其他值时,与filter进行计算的时候,会产生一些值,对结果会造成影响
卷积核个数
最终需要得到多少个特征图,卷积核个数就是多少
卷积核结果计算公式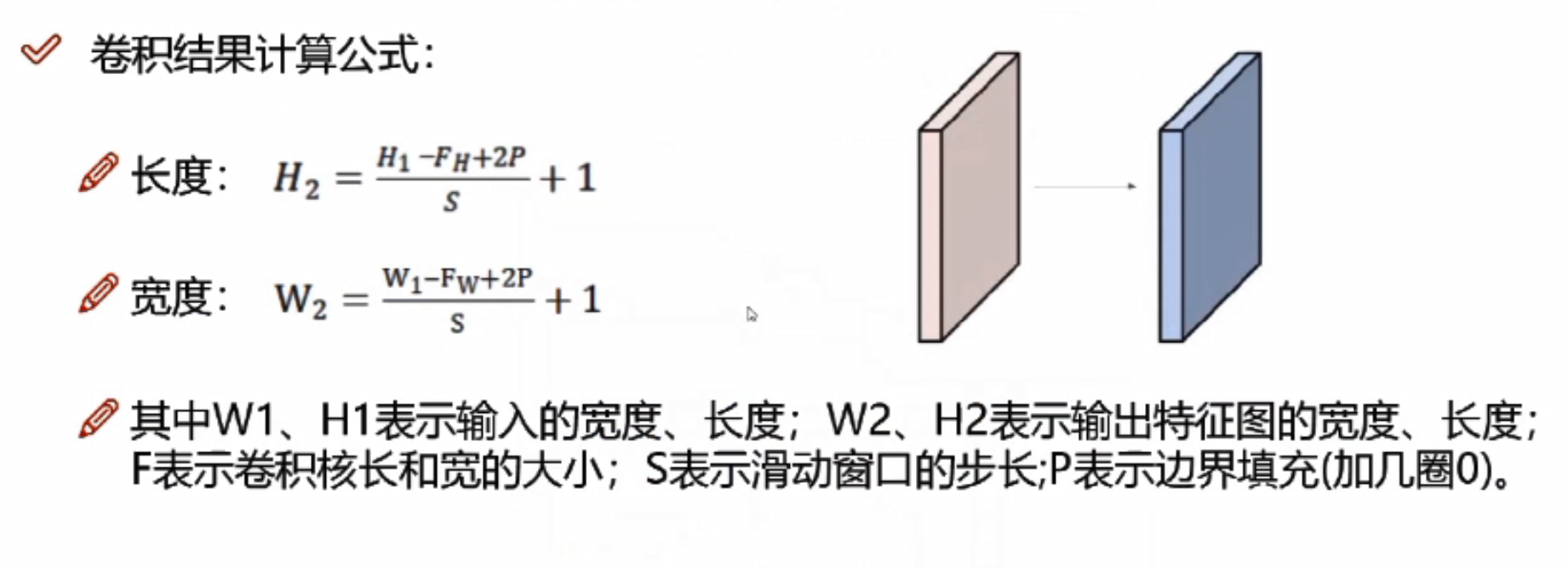
如果输入数据是32*32*3的图像,用10个5*5*3的filter来进行卷积操作,指定步长为1,边界填充为2,最终输出规模为?
(32-5+2*2)/1+1=32,最终输出规模为32*32*10
经过卷积操作后也可以保持特征图长度、宽度不变。
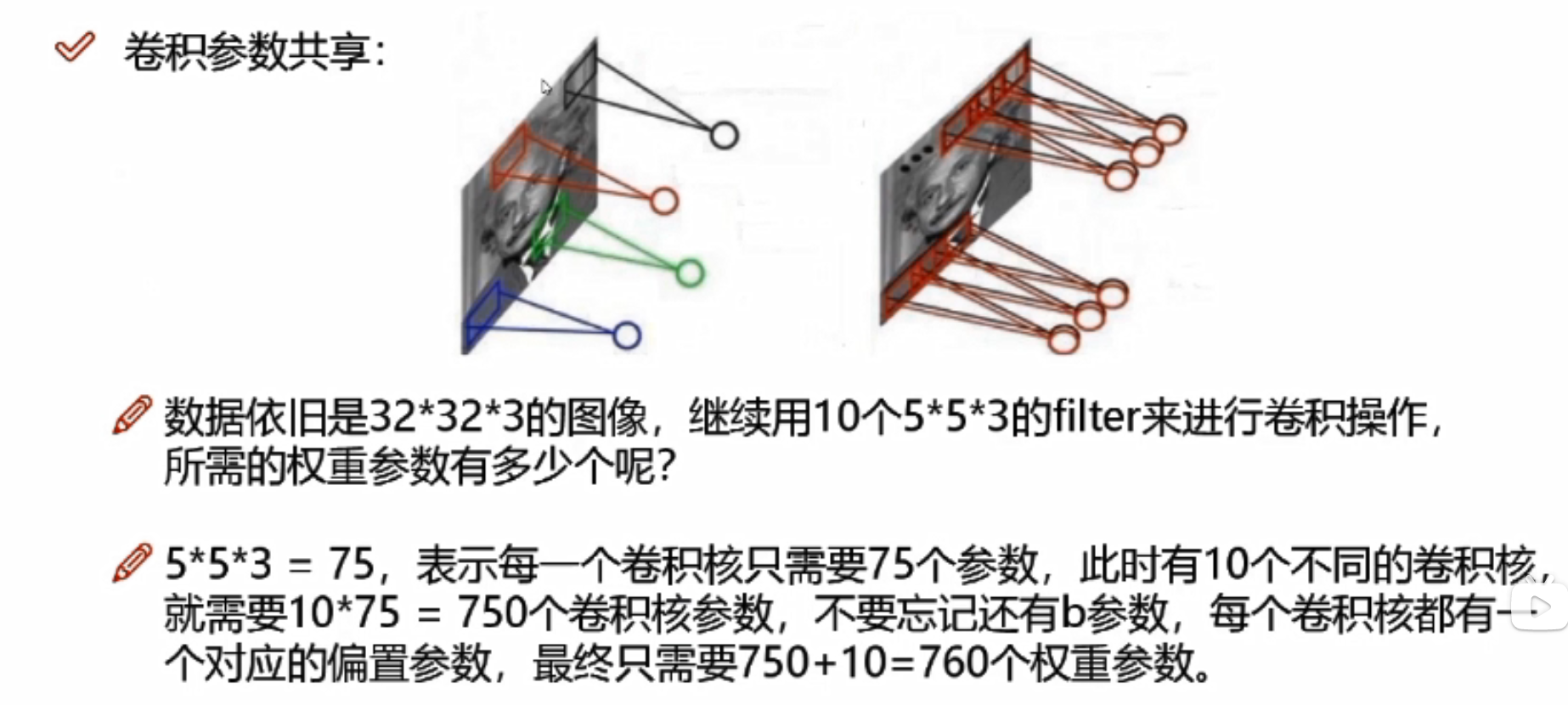
卷积参数共享
池化层
池化层是做压缩的,不涉及任何矩阵计算,只是一个筛选过滤的操作
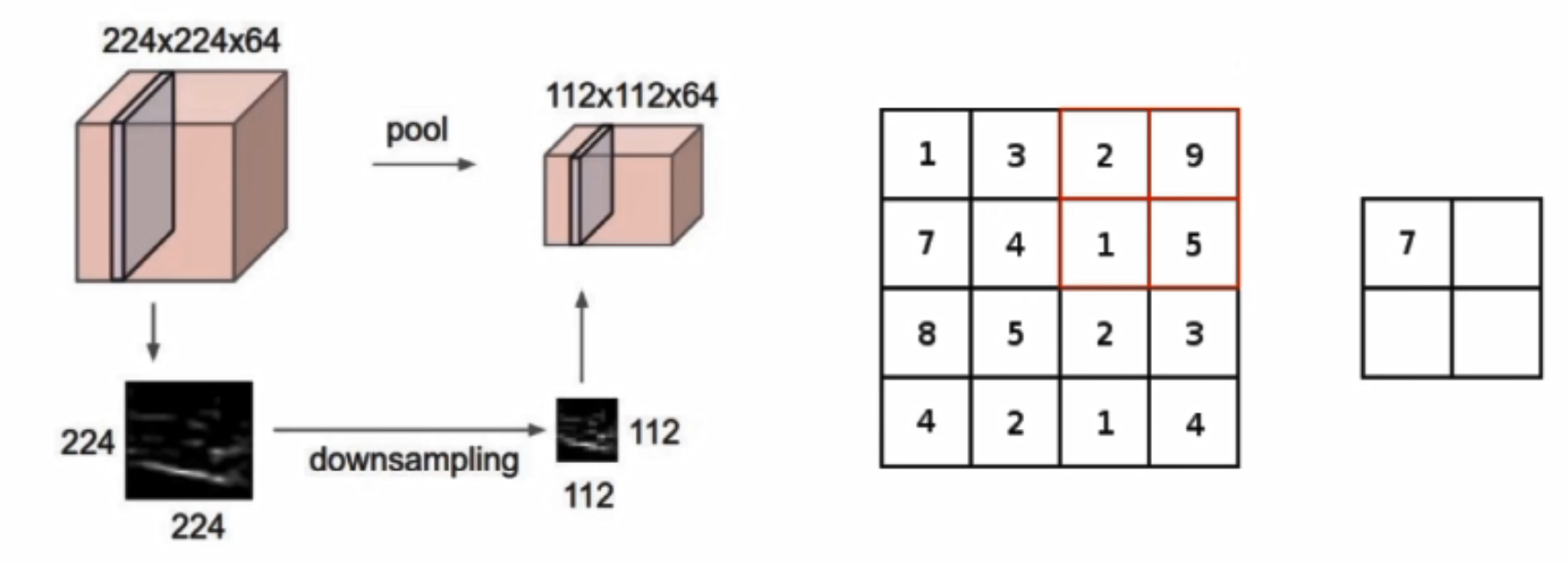 h,w变了,但是c不变
h,w变了,但是c不变
最大池化
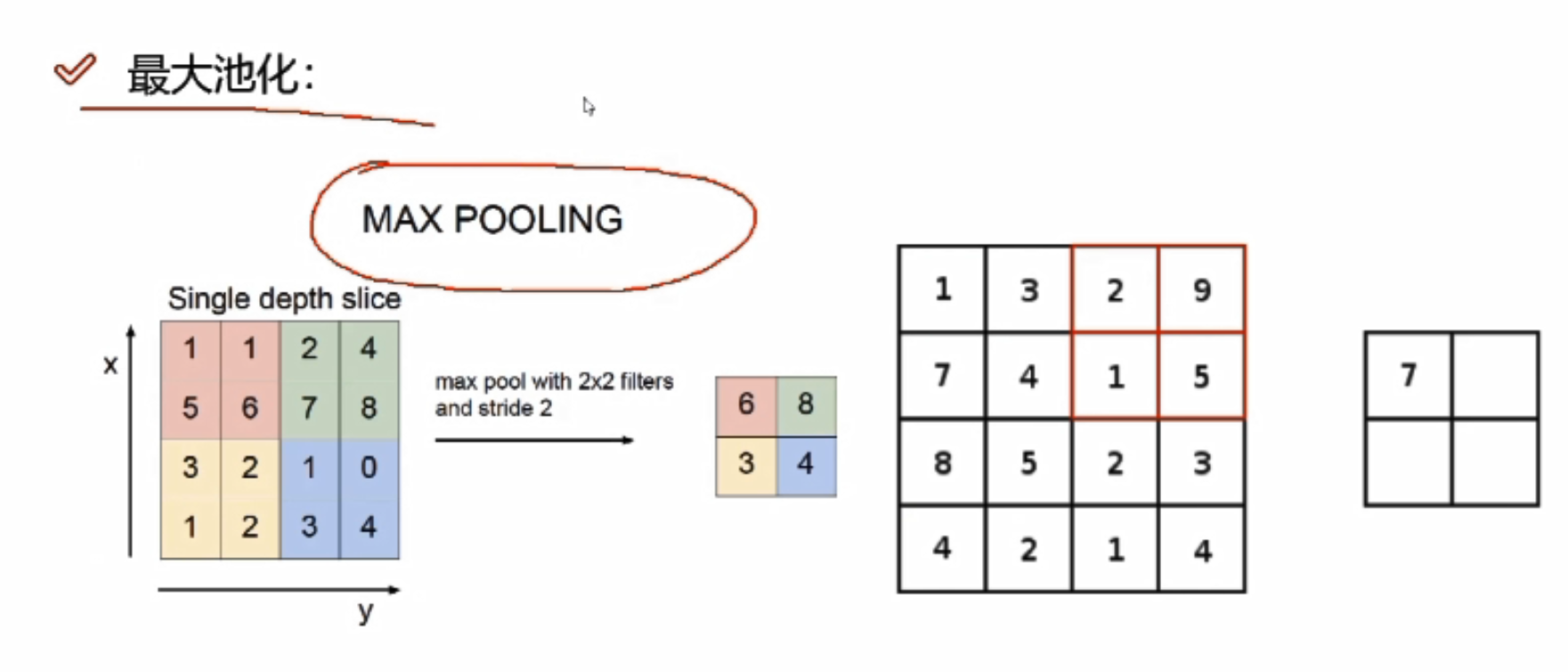
对某一个特征图(4*4)做MAX POOLING,它会先选择不同的区域,每一个区域中选择最大的值
为什么会选择最大的值?
卷积神经网络中,得到的比较大的值往往比较重要
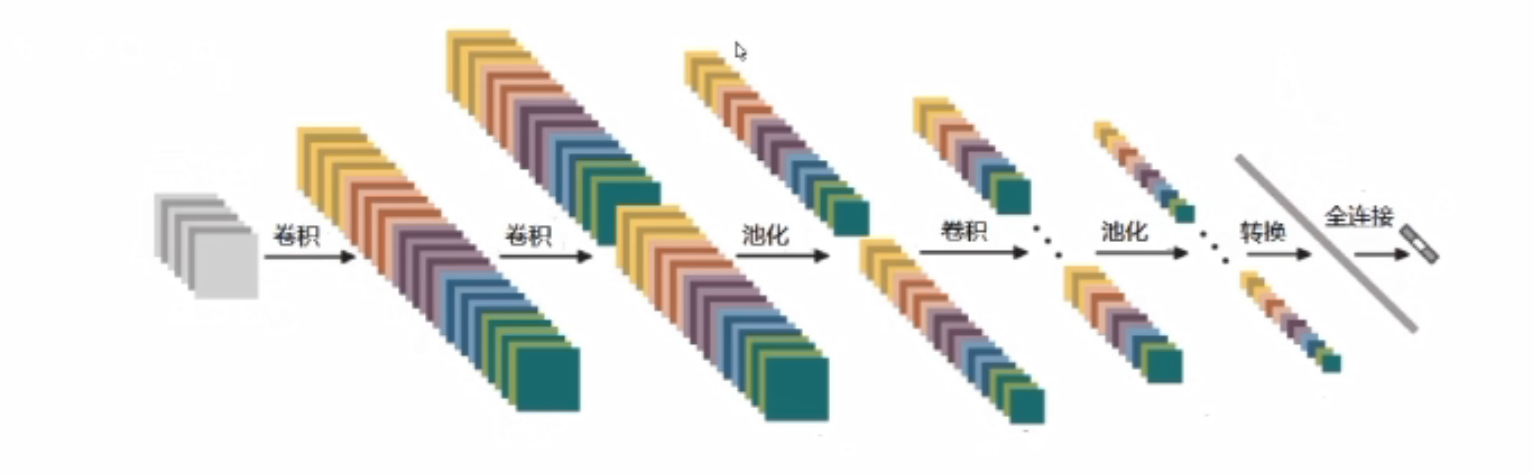
整体架构具体做法

首先卷积进行特征提取,卷积后的RELU,即经过一次卷积之后都需要加上一个非线性变换,两次卷积后做一次池化。
假设最后得到的是32*32*10的特征图,如何进行分类,转换成分类的概率值?
需要全连接层FC,FC将前面经过多次卷积后高度抽象化的特征进行整合,然后可以进行归一化,对各种分类情况都输出一个概率,之后的分类器可以根据全连接得到的概率进行分类。
FC的矩阵大小:[10240,5];五分类所以第二个值是5,FC不能连接三维,所以需要将前面的三维特征图拉成一个特征向量,向量大小为32*32*10=10240。
什么才能称之为一层?该图有几层神经网络?
带参数计算的才能叫做一层,卷积层带,RELU层不带,池化层不带,全连接层也带;所以该图有七层神经网络。
特征图的变化
转换:将三维的特征图拉成一个一维的向量
经典网络—Alexnet
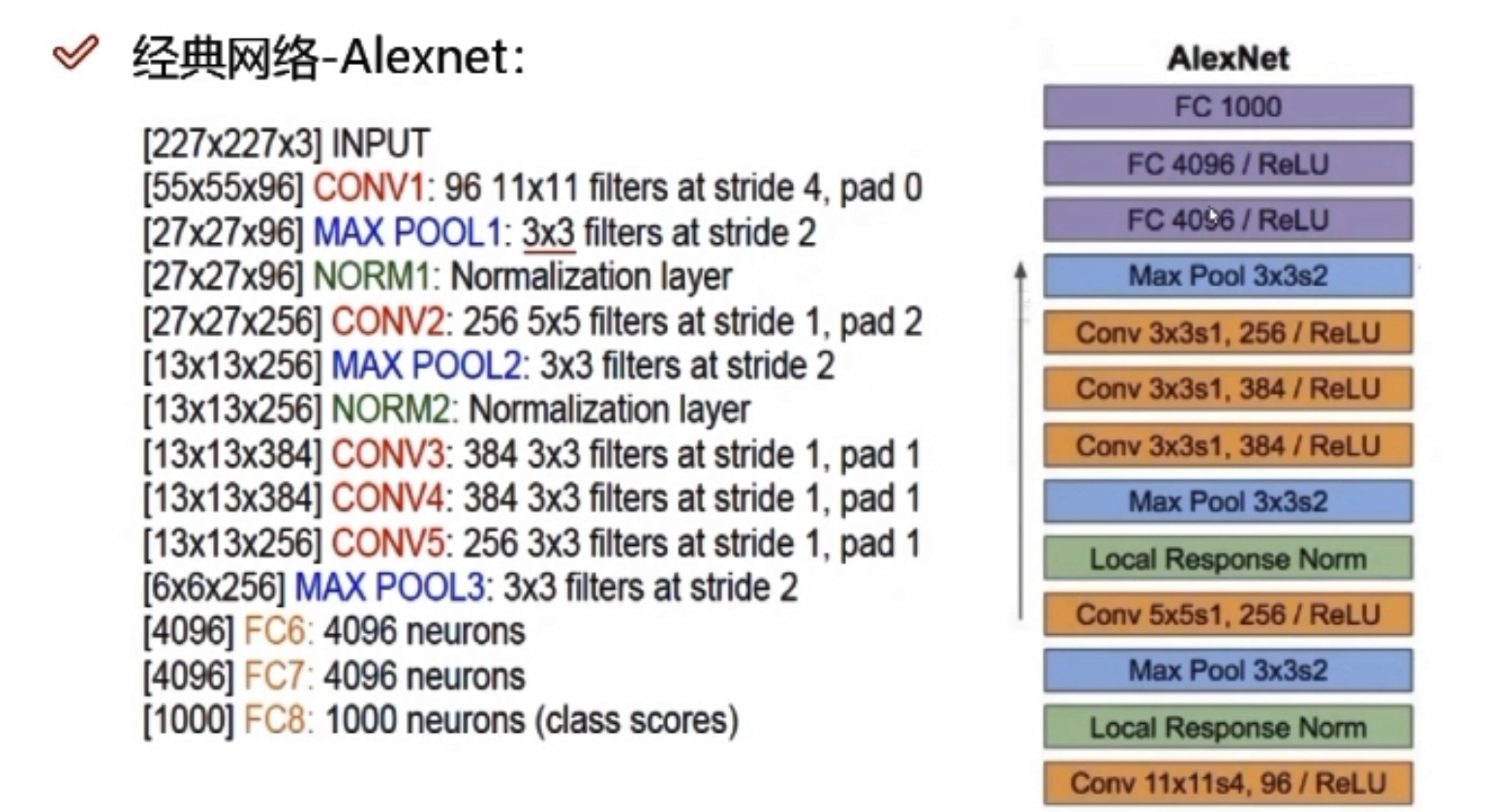
- 11*11的filters大刀阔斧,不好,现阶段卷积核越小越好
- stride为4,步长太长;pad为0,不加填充
- 8层网络,5层卷积,3层全连接
经典网络—Vgg
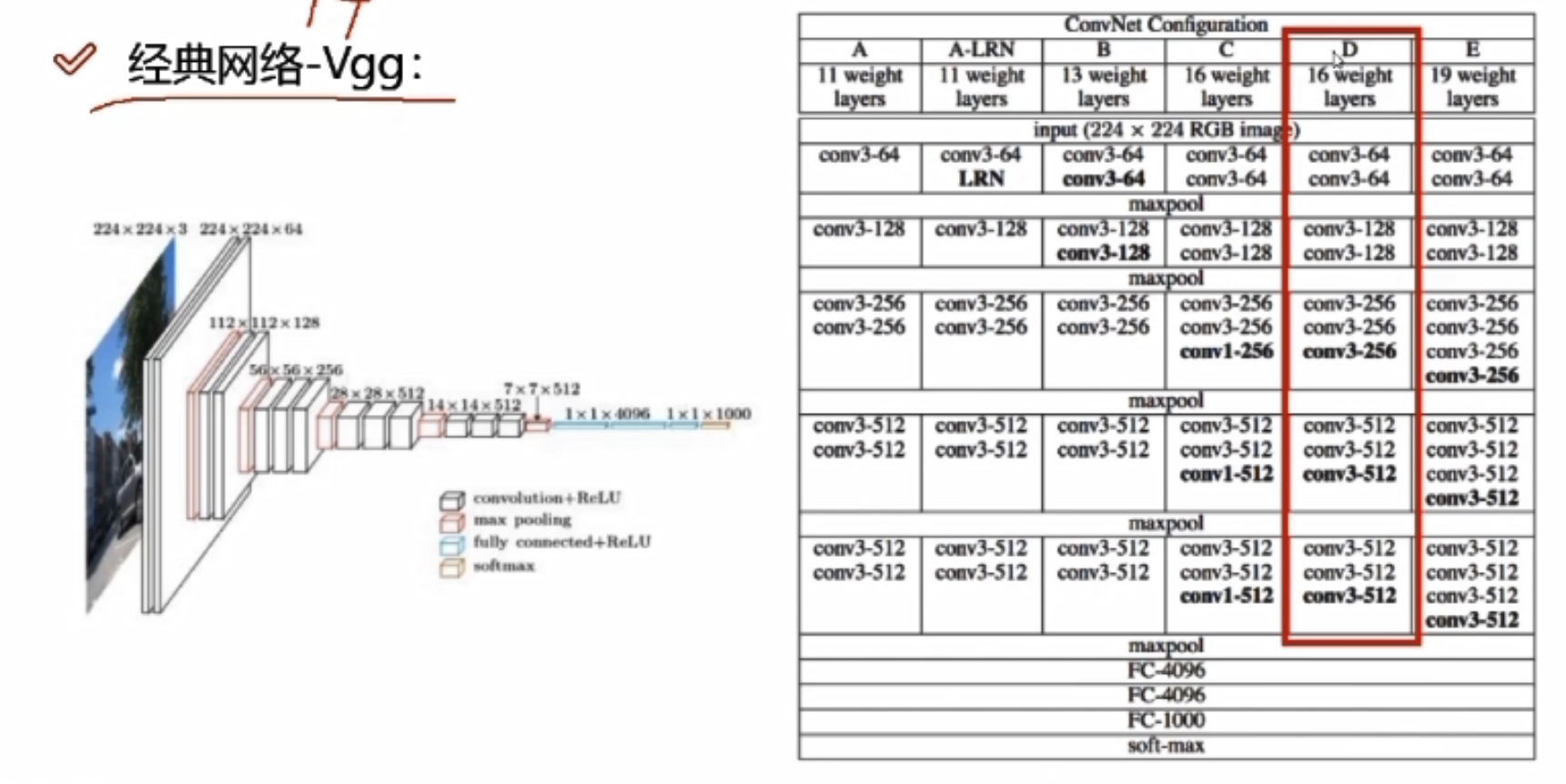
- 所有的卷积大小都是3*3的,细腻
- 有16/19层网络
- 在maxpool后,会损失信息,Vgg在maxpool后会使得特征图翻倍来弥补损失的信息
- Vgg的分类准确度相比Alexnet提升了15%左右,但是训练网络的时间需要比Alexnet长不少
Vgg为什么用到16层? 层越高越好吗?
经过验证,发现16层的效果要比其它层好,因为随着卷积层增加的时候,不一定所有的卷积层做的效果都好,因为是在之前提取的特征基础上再提取特征,不一定比之前提取的特征更好
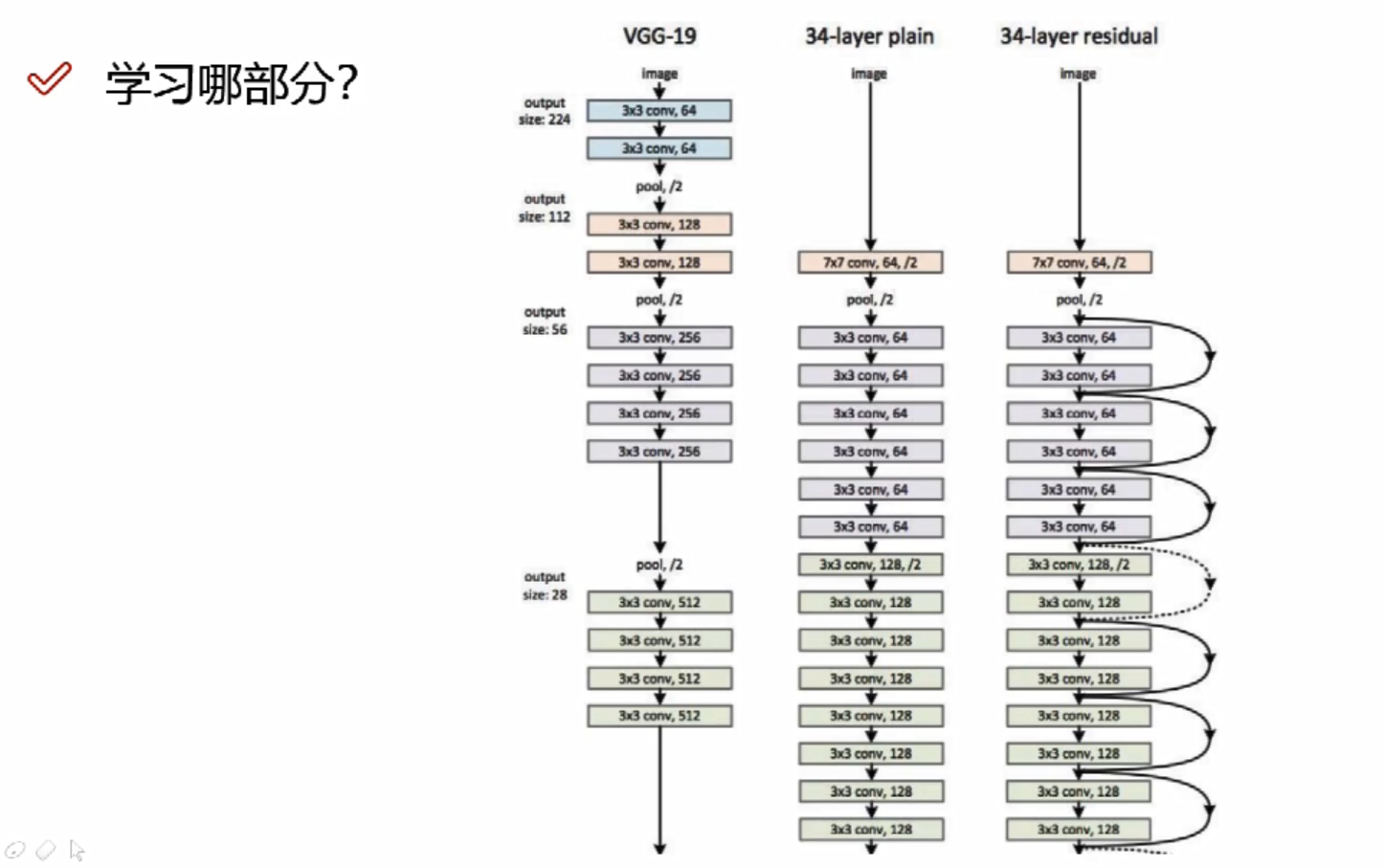
经典网络—Resnet
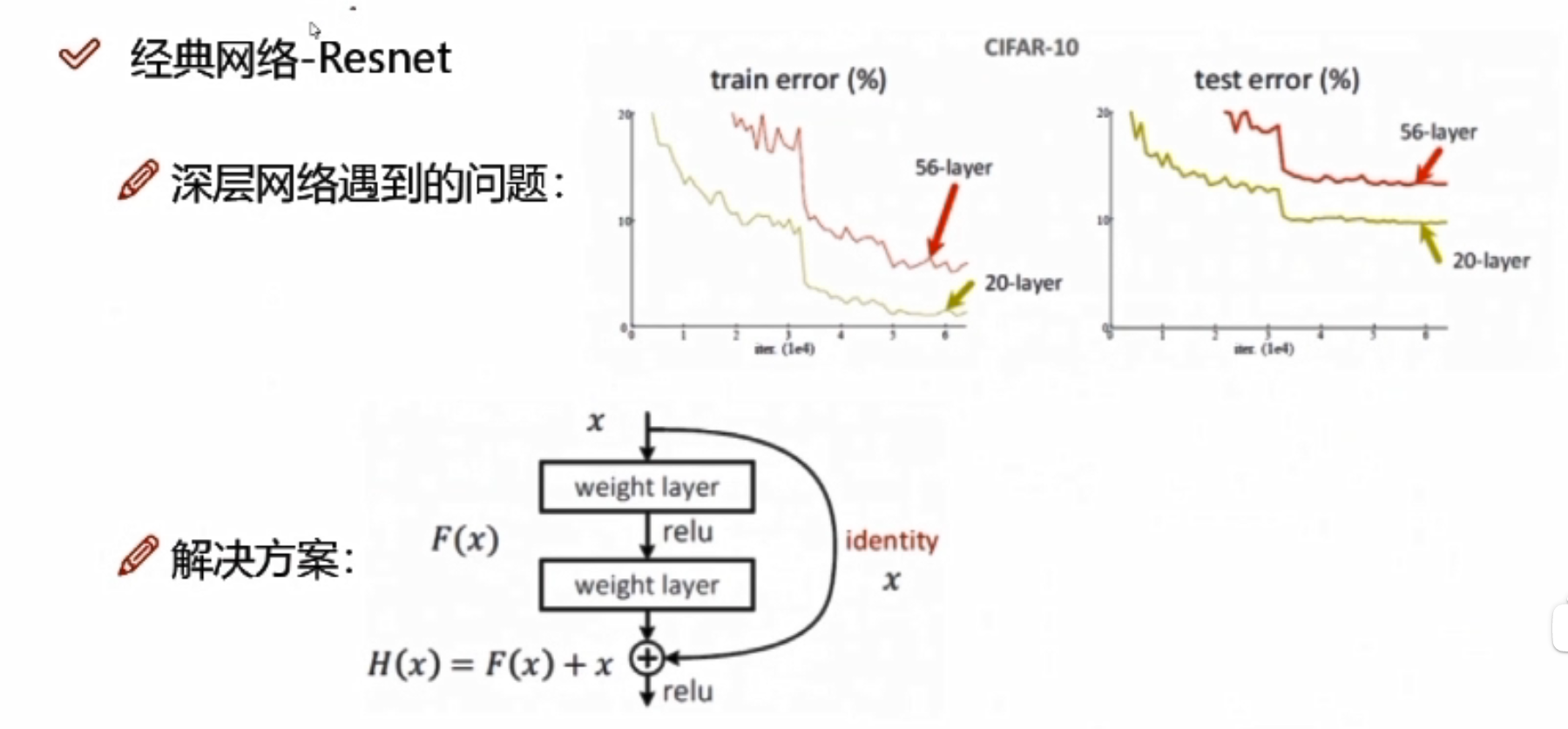
问题:56层的错误率是要高于20层的
分析:20层到56层的中间肯定有某些层数做的不好
解决方案: x:卷积当中的某一层,做两次卷积发现效果可能不好,此时额外用一条线把x拿过来,与卷积的结果进行堆叠相加,注意F(x)和x形状要相同,所谓相加是特征矩阵相同位置上的数字进行相加;如果卷积层始终使lose值发生上升,那么网络会使这一层所有的参数学为0,此时还剩下x层。相当于这一层白弄,但至少不会比原来的结果差。
解决效果:
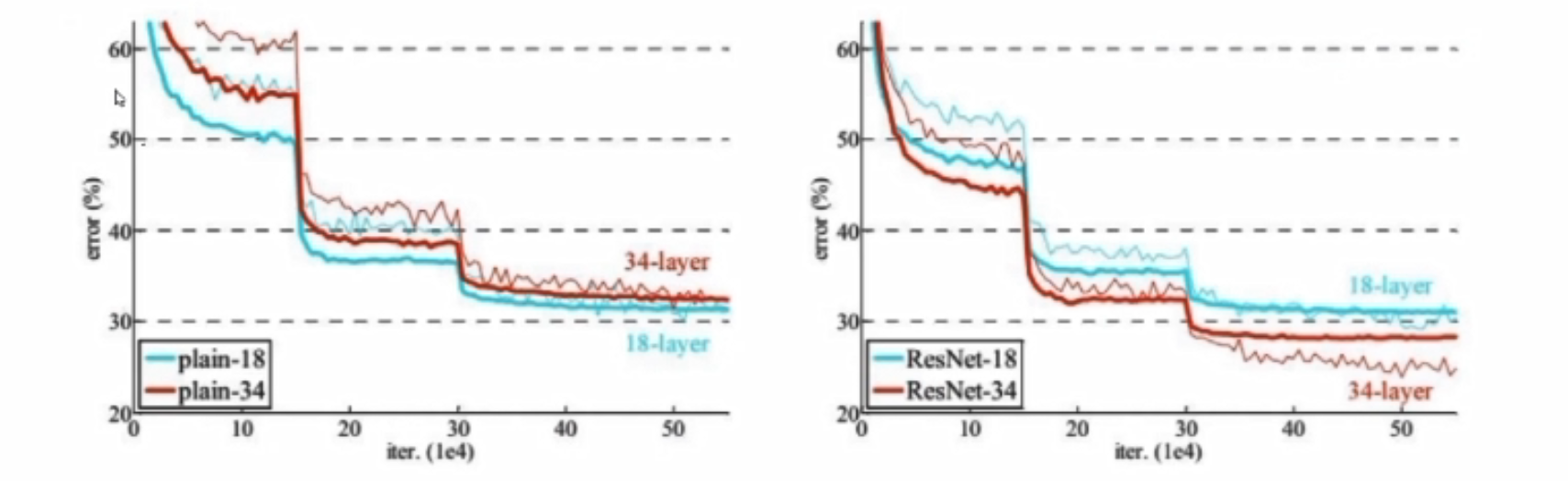
左边是传统网络,右边是Resnet网络;左边层数越高,error值越大,右边层数越高error值越小
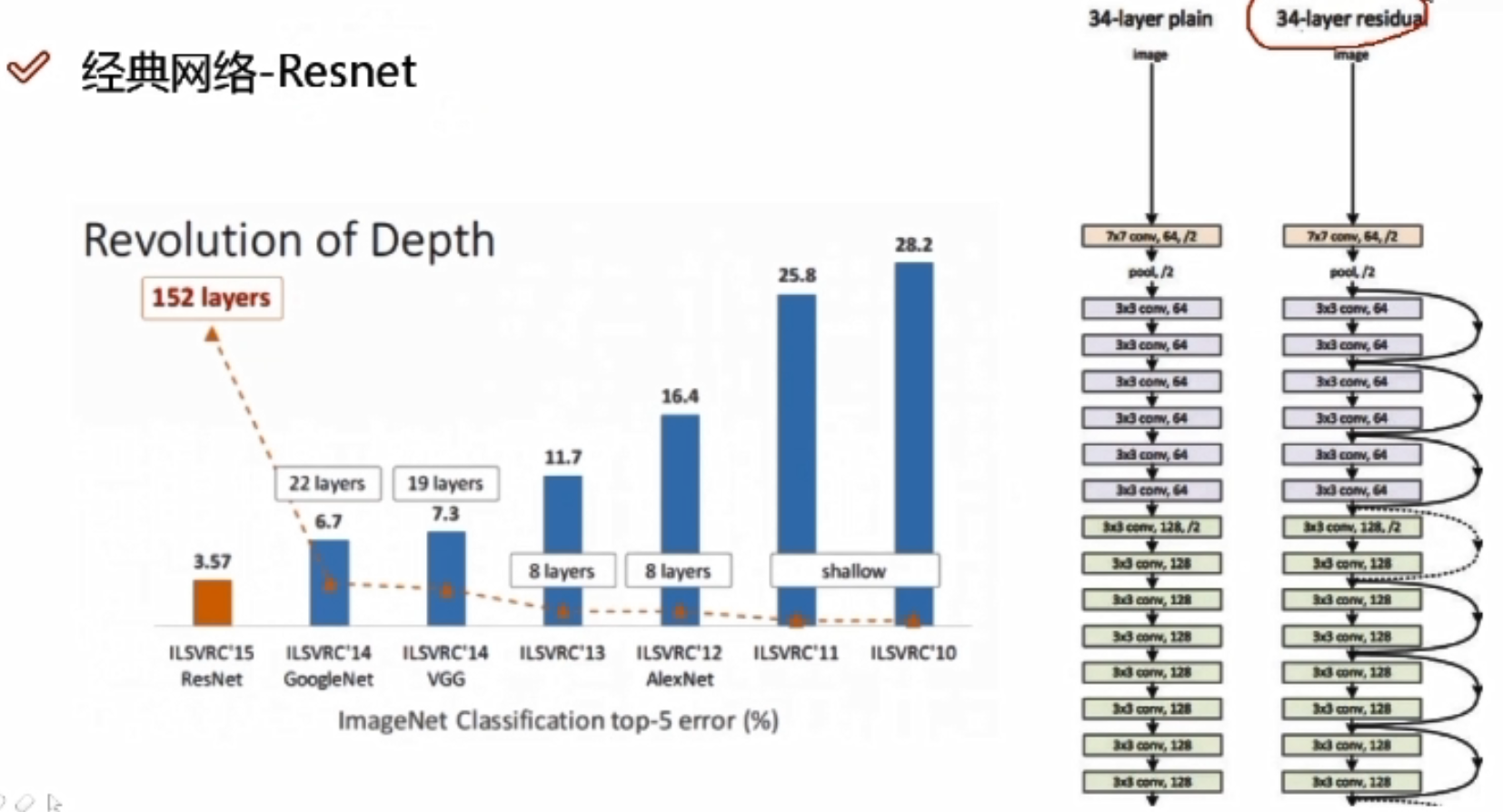 Resnet是一个特征提取,因为一个网络是分类还是回归,取决于损失函数还有最后的层是怎么连的
Resnet是一个特征提取,因为一个网络是分类还是回归,取决于损失函数还有最后的层是怎么连的
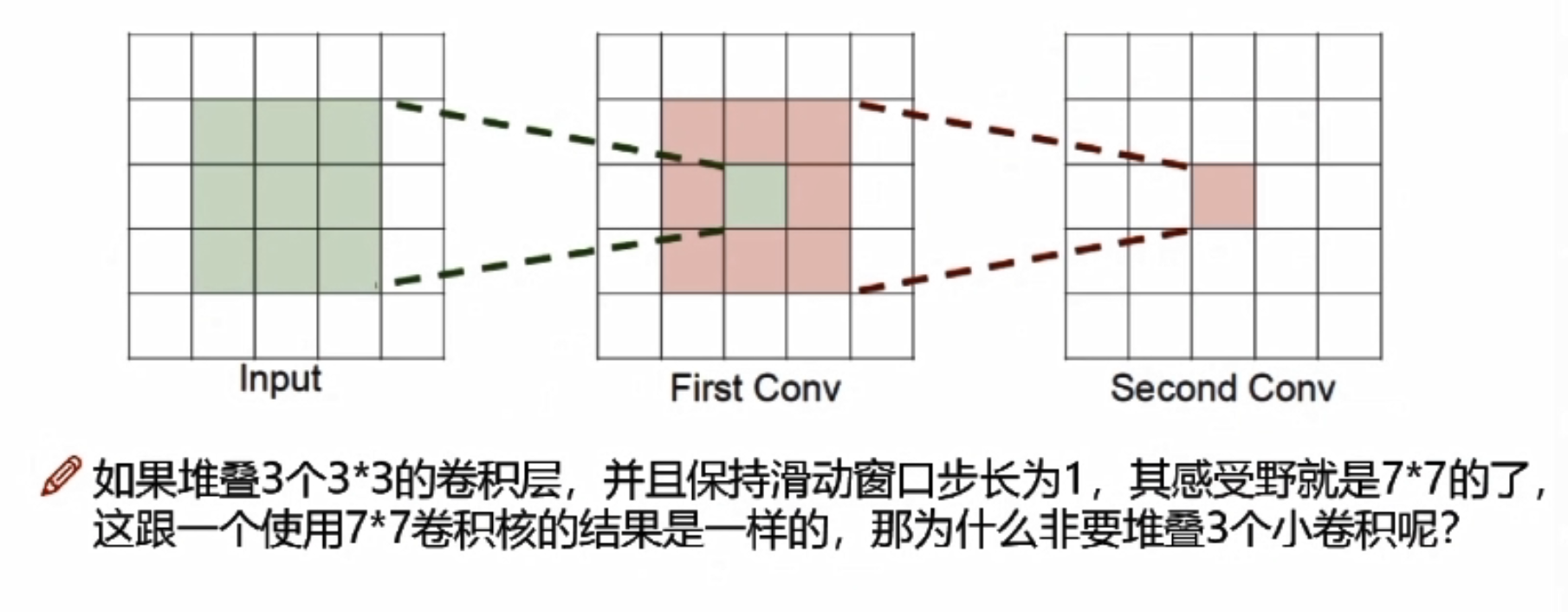
感受野
卷积神经网络每一层输出的特征图上的像素点在输入图片上映射的区域大小。

项目实战—基于CNN构建识别模型一
构建卷积神经网络
卷积网络中的输入和层与传统神经网络有些区别,需重新设计,训练模块基本一致
import torchimport torch.nn as nnimport torch.optim as optimimport torch.nn.functional as Ffrom torchvision import datasets,transforms import matplotlib.pyplot as pltimport numpy as np%matplotlib inline
首先读取数据
- 分别构建训练集和测试集(验证集)
- DataLoader来迭代取数据
# 定义超参数 input_size = 28 #图像的总尺寸28*28*1,三维的num_classes = 10 #标签的种类数num_epochs = 3 #训练的总循环周期batch_size = 64 #一个撮(批次)的大小,64张图片 # 训练集train_dataset = datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) # 测试集test_dataset = datasets.MNIST(root='./data',train=False,transform=transforms.ToTensor()) # 构建batch数据train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True)
卷积网络模块构建
- 一般卷积层,relu层,池化层可以写成一个套餐
- 注意卷积最后结果还是一个特征图,需要把图转换成向量才能做分类或者回归任务
class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() self.conv1 = nn.Sequential( # 输入大小 (1, 28, 28) conv1不是第一个卷积层,而是第一个卷积模块,包括卷积relu池化 nn.Conv2d( in_channels=1, # 灰度图,当前输入的特征图个数 out_channels=16, # 要得到几多少个特征图 kernel_size=5, # 卷积核大小 stride=1, # 步长 padding=2, # 如果希望卷积后大小跟原来一样,需要设置padding=(kernel_size-1)/2 if stride=1 ), # 输出的特征图为 (16, 28, 28) nn.ReLU(), # relu层 nn.MaxPool2d(kernel_size=2), # 进行池化操作(2x2 区域), 输出结果为: (16, 14, 14) ) self.conv2 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14) nn.Conv2d(16, 32, 5, 1, 2), #参数的简单写法,与conv1对应。# 输出 (32, 14, 14) nn.ReLU(), # relu层 nn.MaxPool2d(2), # 输出 (32, 7, 7) ) self.out = nn.Linear(32 * 7 * 7, 10) # 全连接层得到的结果 def forward(self, x): #前向传播 x = self.conv1(x) x = self.conv2(x) x = x.view(x.size(0), -1) # flatten操作,结果为:(batch_size, 32 * 7 * 7) output = self.out(x) return output准确率作为评估标准
def accuracy(predictions, labels): pred = torch.max(predictions.data, 1)[1] rights = pred.eq(labels.data.view_as(pred)).sum() return rights, len(labels) 训练网络模型
# 实例化net = CNN() #损失函数criterion = nn.CrossEntropyLoss() #优化器optimizer = optim.Adam(net.parameters(), lr=0.001) #定义优化器,普通的随机梯度下降算法 #开始训练循环for epoch in range(num_epochs): #当前epoch的结果保存下来 train_rights = [] for batch_idx, (data, target) in enumerate(train_loader): #针对容器中的每一个批进行循环 net.train() output = net(data) loss = criterion(output, target) optimizer.zero_grad() loss.backward() optimizer.step() right = accuracy(output, target) train_rights.append(right) if batch_idx % 100 == 0: net.eval() val_rights = [] for (data, target) in test_loader: output = net(data) right = accuracy(output, target) val_rights.append(right)#准确率计算 train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights])) val_r = (sum([tup[0] for tup in val_rights]), sum([tup[1] for tup in val_rights])) print('当前epoch: {} [{}/{} ({:.0f}%)]\t损失: {:.6f}\t训练集准确率: {:.2f}%\t测试集正确率: {:.2f}%'.format( epoch, batch_idx * batch_size, len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.data, 100. * train_r[0].numpy() / train_r[1], 100. * val_r[0].numpy() / val_r[1]))项目实战—基于CNN构建识别模型二
图像识别实战常用模块解读
数据预处理部分
- 数据增强:torchvision中transforms模块自带功能,比较实用
- 数据预处理:torchvision中transforms也帮我们实现好了,直接调用即可
- DataLoader模块直接读取batch数据
网络模块设置
- 加载预训练模型,torchvision中有很多经典网络架构,调用起来十分方便,并且可以用人家训练好的权重参数来继续训练,也就是所谓的迁移学习
- 需要注意的是别人训练好的任务跟咱们的可不是完全一样,需要把最后的head层改一改,一般也就是最后的全连接层,改成咱们自己的任务
- 训练时可以全部重头训练,也可以只训练最后咱们任务的层,因为前几层都是做特征提取的,本质任务目标是一致的
网络模型保存与测试
- 模型保存的时候可以带有选择性,例如在验证集中如果当前效果好则保存
- 读取模型进行实际测试

import osimport matplotlib.pyplot as plt%matplotlib inlineimport numpy as npimport torchfrom torch import nnimport torch.optim as optimimport torchvision#需要先安装pip install torchvision,安装后就可以用里面的三大模块了from torchvision import transforms, models, datasets#https://pytorch.org/docs/stable/torchvision/index.htmlimport imageioimport timeimport warningsimport randomimport sysimport copyimport jsonfrom PIL import Image数据读取与预处理操作
data_dir = './flower_data/'train_dir = data_dir + '/train'valid_dir = data_dir + '/valid'制作好数据源
- data_transforms中指定了所有图像预处理操作
- ImageFolder假设所有的文件按文件夹保存好,每个文件夹下面存贮同一类别的图片,文件夹的名字为分类的名字
>> 数据增强
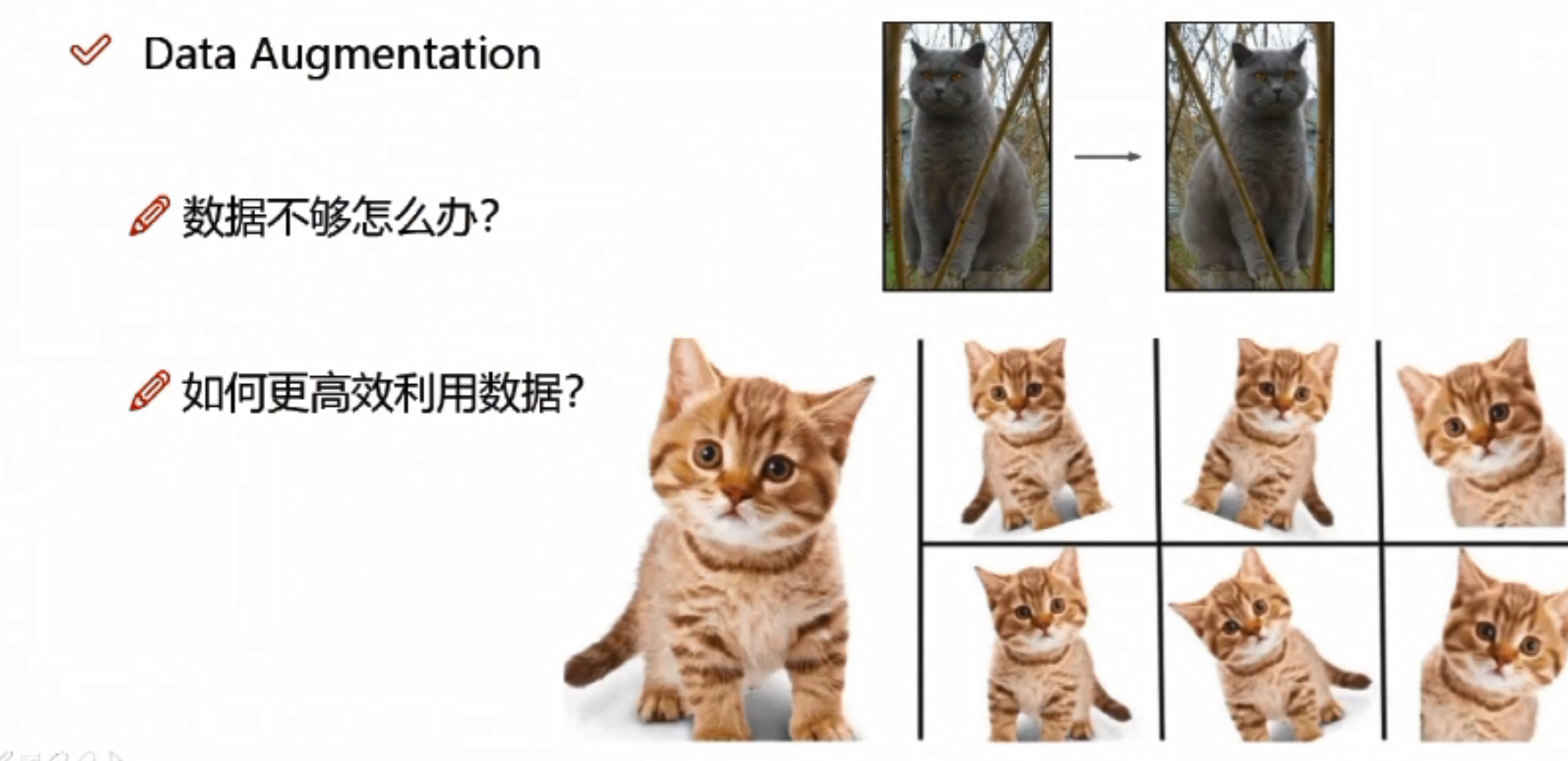
数据不够,可以将原图像进行翻转、旋转、放大、缩小,得到更多的数据
data_transforms = {#训练集做数据增强 'train': transforms.Compose([transforms.RandomRotation(45),#随机旋转,45是-45到45度之间随机选 transforms.CenterCrop(224),#从中心开始裁剪(非随机),留下224*244的大小区域 transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 p=0.5,有50%的概率进行翻转,50%概率不动,一般情况下都是0.5 transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转 transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相 transforms.RandomGrayscale(p=0.025),#概率转换成灰度率,3通道就是R=G=B transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#标准化: 均值,标准差 (减均值/标准差) ]), #验证集不需要数据增强了 'valid': transforms.Compose([transforms.Resize(256), #做验证的时候需要resize transforms.CenterCrop(224),#中心裁剪 transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#标准化 ]), #训练集是怎么做预处理的验证集也需要怎么做预处理}batch_size = 8#显存不够可调小 image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'valid']} #datasets.ImageFolder(实际路径,刚才的预处理方法)dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True) for x in ['train', 'valid']}dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'valid']}class_names = image_datasets['train'].classes读取标签对应的实际名字
with open('cat_to_name.json', 'r') as f: cat_to_name = json.load(f)展示下数据
- 注意tensor的数据需要转换成numpy的格式,而且还需要还原回标准化的结果
def im_convert(tensor): """ 展示数据""" image = tensor.to("cpu").clone().detach() image = image.numpy().squeeze() image = image.transpose(1,2,0) #将H W C还原回去 image = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406))#还原标准化,先乘再加 image = image.clip(0, 1) return imagefig=plt.figure(figsize=(20, 12))columns = 4rows = 2 dataiter = iter(dataloaders['valid']) #一组batch数据inputs, classes = dataiter.next() for idx in range (columns*rows): ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[]) ax.set_title(cat_to_name[str(int(class_names[classes[idx]]))]) plt.imshow(im_convert(inputs[idx]))plt.show()

>>迁移学习
训练网络的过程中,可能会遇到各种各样的问题
- 可能手里数据不多,会导致模型过拟合,结果可能不好——做数据增强
- 训练网络模型,需要调节各种各样的参数,花费时间多
- 训练一个模型,需要花费的时间太多了
这里就需要用到迁移学习
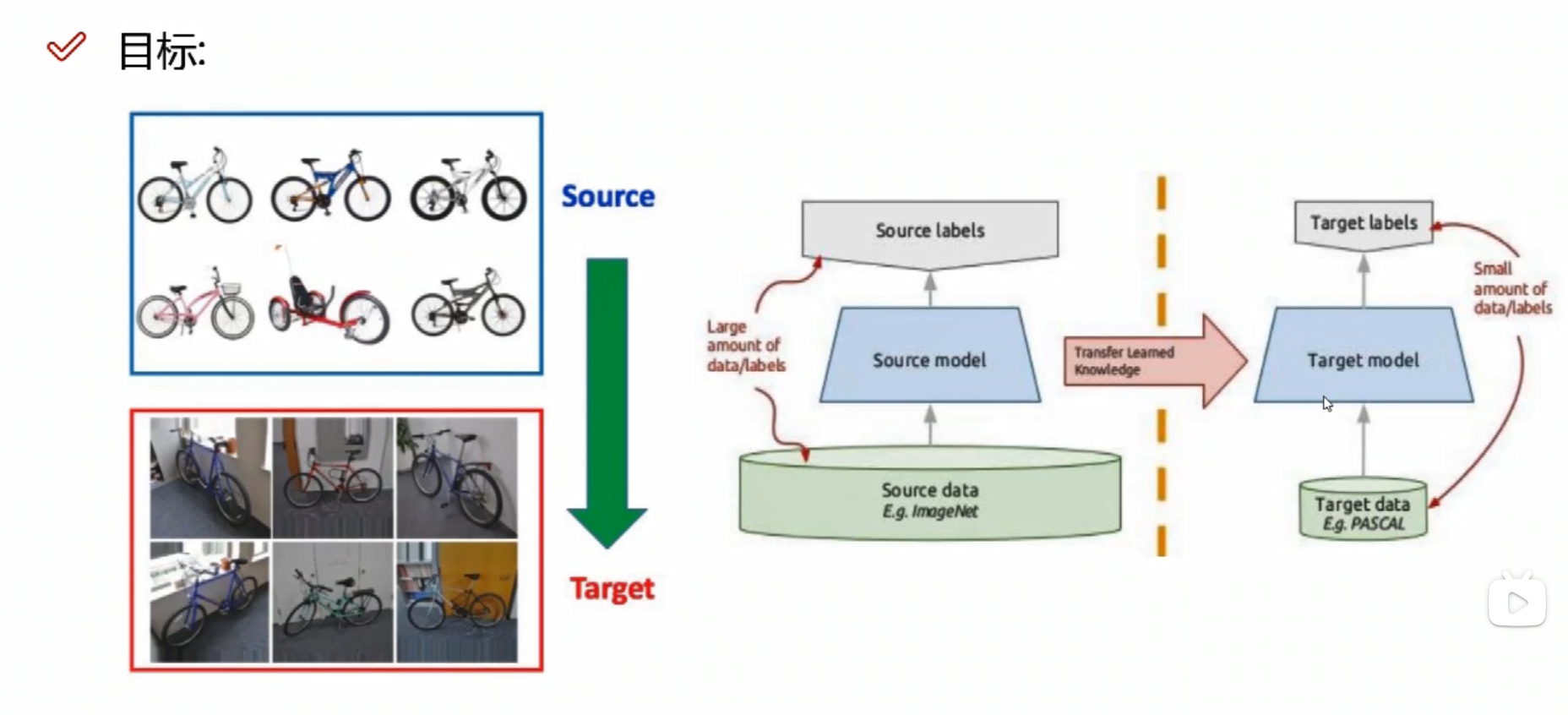 自己的数据不够多,可以借助别人的模型,用别人训练好的权重参数和偏置参数
自己的数据不够多,可以借助别人的模型,用别人训练好的权重参数和偏置参数
但是 需要保证自己的所有结构、输入和输出的格式与别人的一致
对于前面的层 通常有两种方案:
- A:将别人的卷积层拿过来当做自己的权重参数初始化,然后继续进行训练
- B:将别人的卷积层拿过来冻住,保持不变,把权重参数当做自己的结果
数据量小,需要冻住的层数多;数据量中等,可以冻前面的层数;数据量大,可以选择不冻 ;
全连接层通常用自己的方式进行新的定义,重新训练
加载models中提供的模型,并且直接用训练的好权重当做初始化参数
model_name = 'resnet' #可选的比较多 ['resnet', 'alexnet', 'vgg', 'squeezenet', 'densenet', 'inception']#是否用人家训练好的特征来做feature_extract = True # 是否用GPU训练train_on_gpu = torch.cuda.is_available() if not train_on_gpu: print('CUDA is not available. Training on CPU ...')else: print('CUDA is available! Training on GPU ...') device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")#迁移学习def set_parameter_requires_grad(model, feature_extracting): #要不要把某些层冻住,参数不用训练了 if feature_extracting: for param in model.parameters(): param.requires_grad = Falsemodel_ft = models.resnet152()model_ft参考pytorch官网例子
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True): # 选择合适的模型,不同模型的初始化方法稍微有点区别 model_ft = None input_size = 0 if model_name == "resnet": """ Resnet152 """ model_ft = models.resnet152(pretrained=use_pretrained) #pretrained 是否下载用人家的模型 set_parameter_requires_grad(model_ft, feature_extract) num_ftrs = model_ft.fc.in_features #返回原来模型的全连接层2048 model_ft.fc = nn.Sequential(nn.Linear(num_ftrs, 102), nn.LogSoftmax(dim=1)) #加一个全连接层2048*102 input_size = 224 elif model_name == "alexnet": """ Alexnet """ model_ft = models.alexnet(pretrained=use_pretrained) set_parameter_requires_grad(model_ft, feature_extract) num_ftrs = model_ft.classifier[6].in_features model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes) input_size = 224 elif model_name == "vgg": """ VGG11_bn """ model_ft = models.vgg16(pretrained=use_pretrained) set_parameter_requires_grad(model_ft, feature_extract) num_ftrs = model_ft.classifier[6].in_features model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes) input_size = 224 elif model_name == "squeezenet": """ Squeezenet """ model_ft = models.squeezenet1_0(pretrained=use_pretrained) set_parameter_requires_grad(model_ft, feature_extract) model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1)) model_ft.num_classes = num_classes input_size = 224 elif model_name == "densenet": """ Densenet """ model_ft = models.densenet121(pretrained=use_pretrained) set_parameter_requires_grad(model_ft, feature_extract) num_ftrs = model_ft.classifier.in_features model_ft.classifier = nn.Linear(num_ftrs, num_classes) input_size = 224 elif model_name == "inception": """ Inception v3 Be careful, expects (299,299) sized images and has auxiliary output """ model_ft = models.inception_v3(pretrained=use_pretrained) set_parameter_requires_grad(model_ft, feature_extract) # Handle the auxilary net num_ftrs = model_ft.AuxLogits.fc.in_features model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes) # Handle the primary net num_ftrs = model_ft.fc.in_features model_ft.fc = nn.Linear(num_ftrs,num_classes) input_size = 299 else: print("Invalid model name, exiting...") exit() return model_ft, input_size设置哪些层需要训练
model_ft, input_size = initialize_model(model_name, 102, feature_extract, use_pretrained=True) #要不要冻住一些层,要不要用人家的model #GPU计算model_ft = model_ft.to(device) # 模型保存filename='checkpoint.pth' # 是否训练所有层params_to_update = model_ft.parameters()print("Params to learn:")if feature_extract: params_to_update = [] for name,param in model_ft.named_parameters(): if param.requires_grad == True: params_to_update.append(param) print("\t",name)else: for name,param in model_ft.named_parameters(): if param.requires_grad == True: print("\t",name)model_ft#改完后,打印网络架构,看最后优化器设置
# 优化器设置optimizer_ft = optim.Adam(params_to_update, lr=1e-2)scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)#学习率每7个epoch衰减成原来的1/10#最后一层已经LogSoftmax()了,所以不能nn.CrossEntropyLoss()来计算了,nn.CrossEntropyLoss()相当于logSoftmax()和nn.NLLLoss()整合criterion = nn.NLLLoss()训练模块
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25, is_inception=False,filename=filename): #模型、一个一个batch取数据、损失函数、优化器、训练多少epoch、要不要用其他的网络、 since = time.time() best_acc = 0 #保存一个最好的准确率 """ checkpoint = torch.load(filename) best_acc = checkpoint['best_acc'] model.load_state_dict(checkpoint['state_dict']) optimizer.load_state_dict(checkpoint['optimizer']) model.class_to_idx = checkpoint['mapping'] """ model.to(device) val_acc_history = [] train_acc_history = [] train_losses = [] valid_losses = [] LRs = [optimizer.param_groups[0]['lr']] #学习率 best_model_wts = copy.deepcopy(model.state_dict()) #最好的一次存下来 for epoch in range(num_epochs): print('Epoch {}/{}'.format(epoch, num_epochs - 1)) print('-' * 10) # 训练和验证 for phase in ['train', 'valid']: if phase == 'train': model.train() # 训练 else: model.eval() # 验证 running_loss = 0.0 running_corrects = 0 # 把数据都取个遍 for inputs, labels in dataloaders[phase]: inputs = inputs.to(device) #传到GPU当中 labels = labels.to(device) # 清零 optimizer.zero_grad() # 只有训练的时候计算和更新梯度 with torch.set_grad_enabled(phase == 'train'): if is_inception and phase == 'train': outputs, aux_outputs = model(inputs) loss1 = criterion(outputs, labels) loss2 = criterion(aux_outputs, labels) loss = loss1 + 0.4*loss2 else:#resnet执行的是这里 outputs = model(inputs) loss = criterion(outputs, labels) _, preds = torch.max(outputs, 1) # 训练阶段更新权重 if phase == 'train': loss.backward() optimizer.step() # 计算损失 running_loss += loss.item() * inputs.size(0) running_corrects += torch.sum(preds == labels.data) epoch_loss = running_loss / len(dataloaders[phase].dataset) epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset) time_elapsed = time.time() - since print('Time elapsed {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60)) print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc)) # 得到最好那次的模型 if phase == 'valid' and epoch_acc > best_acc: best_acc = epoch_acc best_model_wts = copy.deepcopy(model.state_dict()) state = { 'state_dict': model.state_dict(), 'best_acc': best_acc, 'optimizer' : optimizer.state_dict(), } torch.save(state, filename) if phase == 'valid': val_acc_history.append(epoch_acc) valid_losses.append(epoch_loss) scheduler.step(epoch_loss) if phase == 'train': train_acc_history.append(epoch_acc) train_losses.append(epoch_loss) print('Optimizer learning rate : {:.7f}'.format(optimizer.param_groups[0]['lr'])) LRs.append(optimizer.param_groups[0]['lr']) print() time_elapsed = time.time() - since print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60)) print('Best val Acc: {:4f}'.format(best_acc)) # 训练完后用最好的一次当做模型最终的结果 model.load_state_dict(best_model_wts) return model, val_acc_history, train_acc_history, valid_losses, train_losses, LRs 代码参考:PyTorch 图像识别实战_我是小白呀的博客-CSDN博客_pytorch 识别
来源地址:https://blog.csdn.net/weixin_58176527/article/details/125530000







