
本篇文章给大家分享的是有关利用hadoop怎么实现一个文件上传功能,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
hdfs上的文件是手动执行命令从本地linux上传至hdfs的。在真实的运行环境中,我们不可能每次手动执行命令上传的,这样太过繁琐。那么,我们可以使用hdfs提供的Java api实现文件上传至hdfs,或者直接从ftp上传至hdfs。
然而,需要说明一点,之前笔者是要运行MR,都需要每次手动执行yarn jar,在实际的环境中也不可能每次手动执行。像我们公司是使用了索答的调度平台/任务监控平台,可以定时的以工作流执行我们的程序,包括普通java程序和MR。其实,这个调度平台就是使用了quartz。当然,这个调度平台也提供其它的一些功能,比如web展示、日志查看等,所以也不是免费的。
首先,给大家简单介绍一下hdfs。hdfs是以流式数据访问模式来存储超大文件,hdfs的构建思路是一次写入,多次读取,这样才是最高效的访问模式。hdfs是为高数据吞吐量应用优化的,所以会以提高时间延迟为代价。对于低延时的访问需求,我们可以使用hbase。
然后,还要知道hdfs中块(block)的概念,默认为64MB。块是hdfs的数据读写的最小单位,通常每个map任务一次只处理一个block,像我们对集群性能评估就会使用到这个概念,比如目前有多少节点,每个节点的磁盘空间、cpu以及所要处理的数据量、网络带宽,通过这些信息来进行性能评估。我们可以使用Hadoop fsck / -files -blocks列出文件系统中各个文件由哪些块构成。
然后,再就是要知道namenode和datanode,这个在之前的博文已经介绍过,下面看看cm环境中hdfs的管理者(namenode)和工作者(datanode),如下
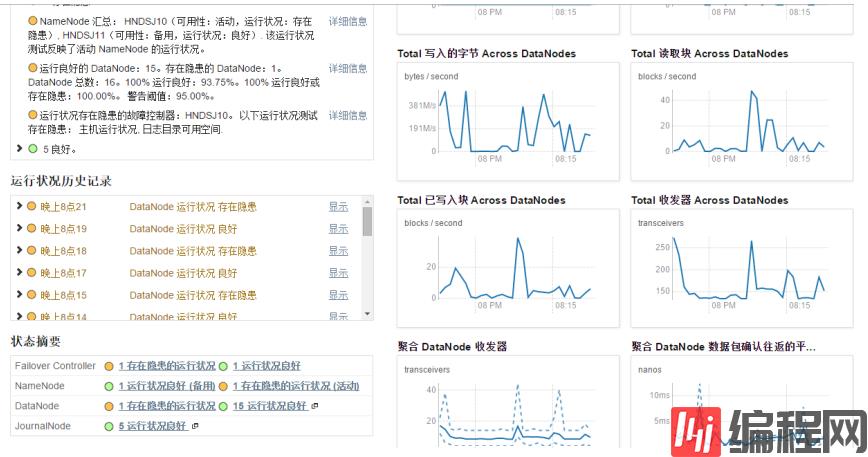
在yarn环境中是可以有多个nameNode的。此环境中没有SecondaryNameNode,当然也可以有。
好了,关于hdfs的基本概念就讲到这儿了,下面来看看具体的代码。
一、java实现上传本地文件至hdfs
这里,可以直接使用hdfs提供的java api即可实现,代码如下:
package com.bjpowernode.hdfs.local;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;public class UploadLocalFileToHdfs { public static void main(String[] args) { Configuration conf = new Configuration(); String localDir = "/home/qiyongkang"; String hdfsDir = "/qiyongkang"; try{ Path localPath = new Path(localDir); Path hdfsPath = new Path(hdfsDir); FileSystem hdfs = FileSystem.get(conf); hdfs.copyFromLocalFile(localPath, hdfsPath); }catch(Exception e){ e.printStackTrace(); } }}免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
软考中级精品资料免费领
 历年真题答案解析
历年真题答案解析 备考技巧名师总结
备考技巧名师总结 高频考点精准押题
高频考点精准押题
- 资料下载
- 历年真题
193.9 KB下载数265
191.63 KB下载数245
143.91 KB下载数1148
183.71 KB下载数642
644.84 KB下载数2756




