
今天就跟大家聊聊有关怎么在python项目中对xml进行解析,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
一、XML的读取
import xml.dom.minidom#负责解析xml文件的包from xml.dom.minidom import parse#使用minidom打开xml文件DOMTree = xml.dom.minidom.parse("D30_1_XmlNameSpace.xml")print(DOMTree)#将该XML文件定义为一个对象#得到文档对象doc = DOMTree.documentElement#打印出了带有根目录的名字的对象print(doc)#显示子元素for ele in doc.childNodes: if ele.nodeName == "student:Name": print("=======Node:{0}=======".format(ele.nodeName)) print(doc.childNodes) if ele.nodeName == "Age": print(ele.getAttribute("jio"))#获取某一节点的属性值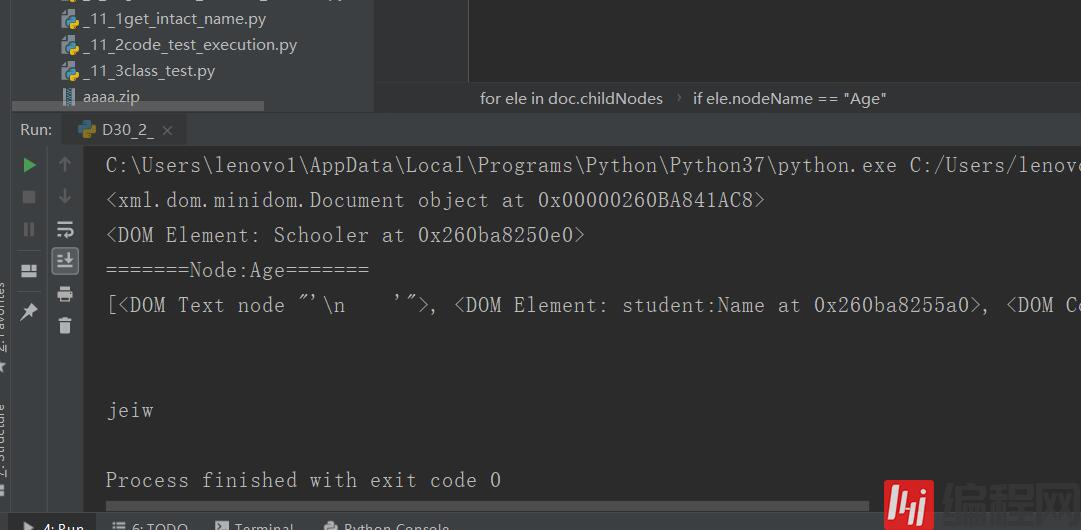
二、同时我们还可以使用xml.DOM.etree这种方式来进行解析
我们提供方法:
(1)以树形结构来表示xml;
(2)root.getiterator:得到相应的可迭代的node集合
(3)root.iter
(4)find(node_name):查找指定node_name的节点,返回一个node
(5)root.findall(node_name):返回多个node_name的节点
(6)node.tag:node对应的tagename
(7)node.text:node的文本值
(8)node.attrib:是node的属性的字典类型的内容
mport xml.etree.ElementTreeroot = xml.etree.ElementTree.parse("D30_1_XmlNameSpace.xml")nodes = root.getiterator()for node in nodes: print("{0}---{1}".format(node.tag,node.text))print("===========================================")ele_room_name = root.find("Location")print(type(ele_room_name))print("{0}----{1}".format(ele_room_name.tag,ele_room_name.text))print("===========================================")ele_room_name2 = root.findall("{http://my_room}Name")#这里如果使用“room:Name”是解析不出来的print(ele_room_name2)for ele in ele_room_name2: print("{0}----{1}".format(ele.tag,ele.text))ele_room_name2 = root.findall("room:Name")print(ele_room_name2)for ele in ele_room_name2: print("{0}----{1}".format(ele.tag,ele.text))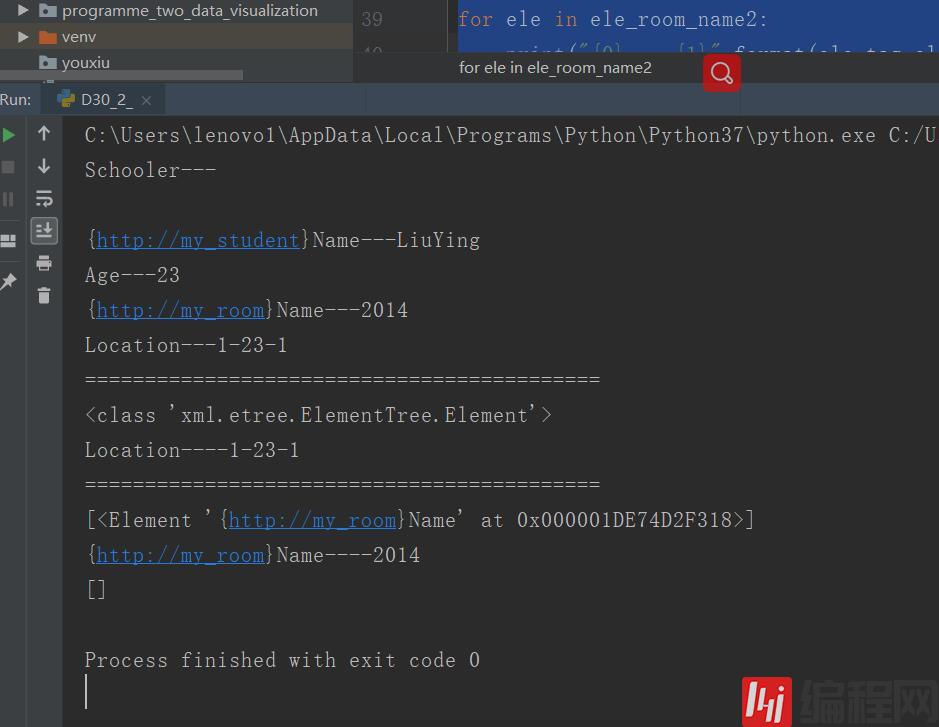
看完上述内容,你们对怎么在python项目中对xml进行解析有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注编程网行业资讯频道,感谢大家的支持。








