
说起当今最具代表性的数据通信技术,区块链无疑在列。作为当下最受关注的次世代分布式系统,区块链可谓众说纷纭,莫衷一是。有人视之为引爆下一次互联网技术革命的突破口,也有人称其为投机工具,惊世骗局。本文旨在于尽可能悬置那些游离于技术层面之外的价值判断,将视角重新移回到区块链技术本身,完整回溯区块链1.0到3.0的技术原理和设计理念之沿革,为读者揭开笼罩在区块链之上那层神秘的面纱。
第二章 Hyperledger Fabric与分布式联盟数据库
在上篇中已经详细介绍了基于区块链1.0设计的比特币电子记账系统。不设准入机制和POW算法使得比特币兼具了网络开放性和数据安全性。但是POW算法过高的算力开销也极大限制了区块链网络的数据处理效率。区块链技术不仅能够应用于电子记账,还可以广泛应用于如金融,安保等对数据安全性敏感度较高的领域。在强大的技术需求驱动下,一项专为企业机构间信息共享而量身定做的区块链项目应运而生,这就是Linux基金会旗下著名的Hyperledger Fabric项目。
一、Hyperledger Fabric的技术背景
Hyperledger Fabric是Linux基金会所主导的Hyperledger(超级账本)项目之一。除Fabric外,Hyperledger生态下还包含了诸如Burrow,Sawtooth(以太坊拓展项目),Indy(数字身份平台)等专门化项目。不同于比特币网络的公链设计,Hyperledger采用了内外网隔离和业务准入的联盟链架构,在区块链1.0网络架构的基础上进一步形成了节点角色的分化。这一设计规避了企业内部数据外泄的风险,同时也尽可能排除了潜在的安全隐患。
Hyperledger Fabric基于谷歌的gRPC框架开发,实现了网络内任意节点的对等通信。同时使用Docker容器技术来托管构成基本交互逻辑的智能合约。简而言之,Hyperledger Fabric是专门为企业和机构设计的通用型业务系统。
二、Hyperledger Fabric的数据结构
1. Hyperledger Fabric的区块链结构
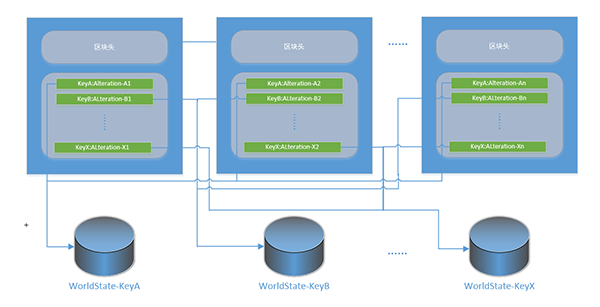
图十四:Hyperledger Fabric的区块链结构
Hyperledger Fabric的区块链结构与比特币大体相同,每个区块都由区块头和区块体组成,并通过父区块哈希编码构成唯一链接。不过Hyperledger Fabric在区块链1.0的基础上进一步加入了一层状态缓存设计,用以提高读写性能。
Hyperledger Fabric和比特币网络一样,本质上是一个分布式账本(Hyperledger Fabric的账本交互逻辑可以由使用者根据自身业务定制,在数据存储的灵活性上要优于区块链1.0系统)。在底层结构中都是通过键值对的方式来存储数据。而区块链为了实现数据的时间可回溯性和数据防篡改机制,在链中并不保存数据的状态,而只保存对数据的变更。这就使得对某条数据的状态查询需要进行全链遍历,其查询性能很难满足一些企业级业务的性能需求,因此Hyperledger Fabric引入了“世界状态(World State)”这一概念。当区块中保存某一条记录时,会同步更新对应Key的世界状态。当需要查询某个键值时,只需要查询对应的世界状态即可,而无需进行全链遍历。
需要强调的是,世界状态是脱链保存在LevelDB/CouchDB结构中的,是一种链外附加缓存机制,世界状态的丢失并不会对区块链中的数据产生影响。
2. Hyperledger Fabric的账本结构
当网络中的排序节点打包好最新区块分发到每个记账节点后,记账节点会对本地的区块链数据进行更新,其账本存储结构如下图所示:
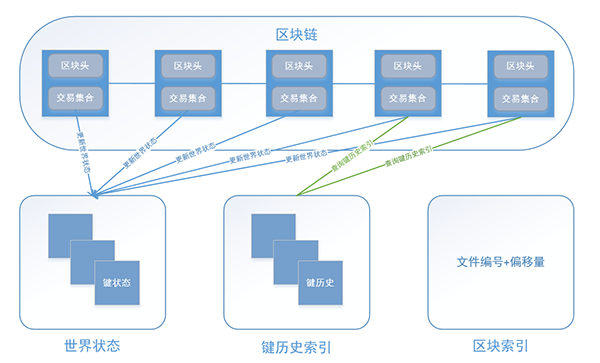
图十五:Hyperledger Fabric的账本结构
首先每个记账节点都保存了所有的历史区块信息,区块以文件系统的形式存储,多个区块以集合形式存储在一个文件块当中。区块链通过文件编号,区块编号,偏移量来实现对某个历史区块的快速索引。
区块链数据也是记账节点中唯一的持久化数据,永久保存且不可更改。某个区块硬编码为64M大小,以六位编码区分,理论单链最多可以容纳64*1000000M的数据量。当一个新的区块请求写入时,记账节点首先会将新的区块添加到本地区块链中,然后将数据同步给状态数据库(世界状态即目前数据的终态,也就是原始状态+区块链中所有交易操作的叠加后的最终状态)。
当每次节点启动时,首先会校验区块链,世界状态,键历史索引中的数据是否一致,若不一致,则可以通过区块链信息重构状态数据库。当然如果从创世区块开始重构世界状态性能开销往往很大,因此Hyperledger Fabric加入了额外的历史状态模块,这一模块记录了对世界状态中每一个键值对的操作(交易请求)的编码,当重构某一键值对时只需要从区块链中筛选出相应的交易请求执行即可,无需遍历整个区块链)。
3. Hyperledger Fabric的读写集机制
读写集是Hyperledger Fabric进行数据更新时所依赖的核心技术,当背书节点进行交易模拟时会对交易请求进行验证。读写集分为读集(读已提交的状态值)和写集(将要更新的状态键值对,状态键值对删除标记,若对同一键值对进行多次更新则以最后一次为准)。执行交易验证时,对于某个更新操作,只有当读集版本号=世界状态版本号时,才会执行写集。写集每更新一个键值对,都会同时更新这一键值对的版本号。这一设计的目的在于保障同一区块中的多笔交易不会对世界状态产生重复操作(类似于Redis的乐观锁机制)。
例如世界状态中存在某一键值对(A,100,V1),此时两笔时间相近的交易请求被打包进了同一个区块中执行:
请求一:读出A值为100后执行扣减50操作;
请求二:读出A值为100后执行扣减20操作;
当请求一执行后世界状态更新为(A,50,V2),此时如果请求二执行,则仍然按照之前读到的(A,100,V1)世界状态进行操作,操作后世界状态更新为(A,80,V2),继而抹除了请求一的操作,因此进行版本验证的目的在于避免在高并发情况下出现数据丢失的情形。
三、实用拜占庭容错算法(Practical Byzantine Fault Tolerance)
1.PBFT的基础模型
在前文中我们已经介绍了分布式系统必然面临的数据一致性问题——拜占庭将军问题。区块链1.0的网络架构主要通过POW算法实现全网共识,以强制记账节点用物理开销来换取记账权的方式规避作弊行为。但是POW算法的解谜设计也造成了很大的资源浪费,大量的算力被浪费在了没有实质意义的数字谜题上。而Hyperledger Fabric作为联盟链,其更偏重于满足企业的分布式数据存储和企业间的数据共享需求,因此性能成为了网络架构设计层面不得不考虑的问题。Hyperledger Fabric在区块链1.0的基础上引入了网络准入机制,只有赋权节点才能访问区块链中的数据,节点数目要远远小于公链系统,POW已经不再适合联盟链系统的设计开发。因此,Hyperledger Fabric采用了成本开销更低,性能更高的一种共识算法——“实用拜占庭容错算法(PBFT)”。
由莱斯利·兰伯特所提出的BFT算法仅仅只是在理论上证明了拜占庭容错的可行性,但是在实际的分布式系统设计中,由于网络阻滞等原因,BFT算法几乎无法被应用。因此在BFT的基础上,卡斯特罗,米格尔,芭芭拉•利斯科夫等三位计算机科学家进一步提出了能够实际应用的PBFT算法。
PBFT算法首先区分了分布式系统的三种基本模型:
强同步性(Synchrony)模型,任意一个节点发出的消息都能在确定的时间周期内送达目标节点。
强异步性(Asynchrony)模型,任意一个节点发出的消息都未必能到达目标节点。
弱同步性(Partial Synchrony)模型,任意一个节点发出的消息在可能的延迟范围内最终会送达目标节点。
强同步性与强异步性模型所设定的情况都过于极端,在实际的分布式系统中情况更加接近弱同步性模型。PBFT算法基于弱同步性模型设计,即消息可能延迟,但不会无限延迟。
假设一个分布式网络中故障/恶意节点为F个,总节点数为N个,在弱同步性模型中,PBFT需要确保两点:
当某个节点收到一条消息时,考虑到最多可能有F个节点保持静默,因此当收到N-F条消息时就要开始验证,而且N-F条消息中至少要有多于F条消息一致才能完成容错判定。因此N和F需要满足:
N - F > F
此外N-F条消息中还有可能包含F个来自恶意节点的假消息,因此真消息的数目至少要多于F条才可以完成容错判定,故而N和F需要满足:
N - F - F > F
综上有:
故当恶意/故障节点不超过总结点数1/3的情况下,PBFT算法能够实现全局一致性。
2.PBFT的网络拓扑模型
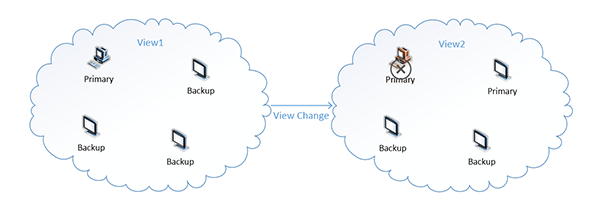
图十六:PBFT的网络拓扑模型
PBFT实现的分布式网络需要满足两个条件:
- 每个节点具有相同的起始状态;
- 在相同的状态下,同一操作产生的结果相同。
在一个PBFT算法实现的分布式网络中,一组节点中选取一个节点作为主节点(Primary),其它节点作为备份节点(Backup)。选取某个节点担任主节点的事态称为系统的一个视图(View)。当主节点故障时将重新选取主节点,主节点发生变化时视为系统的视图发生了一次更新。假设在View1视图下网络对某条消息m的排序n达成一致,为Order⟨view1,m,n⟩,那么当视图更新后对m的排序仍然为Order⟨view2,m,n⟩,即视图转换前后消息排序不会发生改变。
3.PBFT的消息处理流程
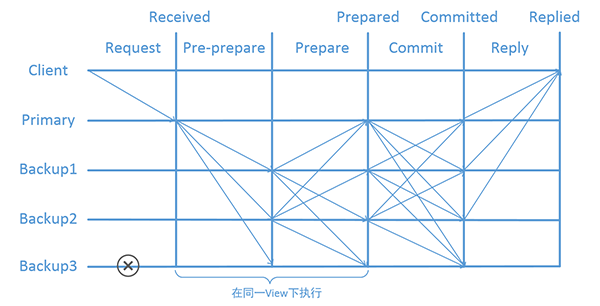
图十七:PBFT的消息处理流程
PBFT的消息处理流程大体上分为请求(Request),预处理(Pre-prepare),准备(Prepare),提交(Commit),响应(Reply)五个阶段。我们通过一个四节点,一个客户端的简单网络模型来对PBFT的信息传输校验流程加以说明:
在该网络模型中,Primary节点和Backup1,Backup2节点为正常节点,Backup3节点发生故障无法做出响应,符合N>3F要求。
首先在Request阶段,Client向Primary发出一条请求,消息格式为:
其中o 表示操作请求内容,t表示当前时间戳,c表示Client节点。
当Primary收到该消息并验证后,进入Pre-prepare阶段,Primary给予消息m一个序号n,向Backup1,Backup2,Backup3广播预处理消息,消息格式为: 其中v表示当前的系统视图,n为消息排序,m为消息内容,d为消息m的哈希值。
当Backup1,Backup2节点接收到Primary节点的消息后,首先会验证系统视图是否发生了更新,消息签名是否合法,排序n是否处于当前视图高低水位之间(为了保证n不出现极大极小值,同一视图下系统会对n的取值域进行限制,使n∈(h,H)),以及是否收到过其它排序为n的消息(确保不同的消息不会获得相同的排序)。验证通过后,进入PREPARE阶段,该节点会向其它节点(包括Primary节点)发送一条准备消息并将该消息存入本地日志中,消息格式为: 其中i表示当前节点。
当其他节点收到该消息后,会进行如下校验并将该消息存入本地日志:
第一步,校验本地日志中是否存在消息m。
第二步,校验本地日志中是否存在m的PRE-PREPARE消息。
第三步,校验本地日志中是否存在至少2F个关于m的PREPARE消息。
若校验通过,则称本节点对消息m达成了PREPARED状态。此时该节点会向其它节点广播,消息格式为:
当其它节点收到该条COMMIT消息时,会进行如下校验并将该消息存入本地日志:
第一步,检验本节点是否对消息m达成PREPARED状态。
第二步,校验本地日志中是否至少有2F条来自其它节点的关于m的COMMIT消息。
若校验通过,则说明对m的排序已经达成了全局一致,此时称该节点对消息m达成了COMMITTED-LOCAL(m,v,n,i)状态,可以直接返回给Client,消息格式为: 其中r和t相同,用于时间校验,当Client收到F+1个一致的REPLY消息时,共识流程结束。
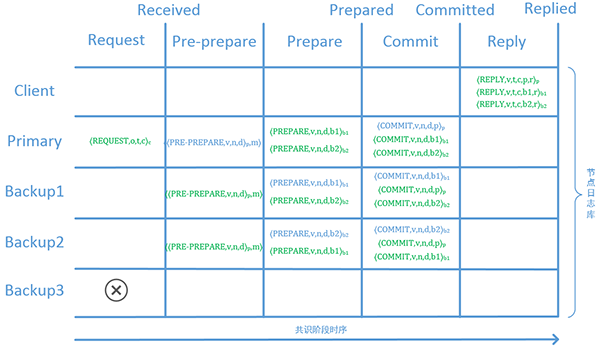
图十八:节点本地日志库状态转移图
为了更直观地理解这一流程,我们作出每个节点本地日志库的状态转移图。其中蓝色标识的消息为节点自己产生,绿色标识的消息来自其它节点。
首先Client发出REQUEST消息,该消息被保存在Primary的日志库中。然后Primary发送PRE-PREPARE消息给Backup1,Backup2,Backup3。Backup1,Backup2分别在日志库中保存该条PRE-PREPARE消息。然后向其它节点发送PREPARE消息。
Primary收到来自Backup1,Backup2的两条PREPARE消息并保存在日志库中。而Backup1,Backup2除了一条自己产生的PREPARE消息外,还收到一条其它节点的PREPARE消息。此时三个正常节点日志库均满足:
- 存在消息m的日志;
- 存在消息m的PRE-PREPARE日志;
- 存在消息m的2F个PREPARE日志。
此时三个节点均达成了关于m的PREPARED状态,继而向其它节点发送COMMIT消息。
由图可见,三个正常节点除了自身产生的一条COMMIT消息外,均收到了2条来自其它节点的COMMIT消息,均达成COMMITTED状态,返回REPLY消息给客户端,完成共识流程。
4.PBFT的垃圾回收机制
PBFT算法对信息的阶段性校验需要用到节点的日志库,随着信息的增加,日志库中的冗余数据也会越来越多,因此PBFT会通过定期的垃圾回收来释放内存空间。PBFT的垃圾回收通过Checkpoint机制来完成。Checkpoint点的设置为某个常数K的整数倍。假设当前消息排序值n取值的高低水位为h到H之间,当被排序的消息数超过H时,节点便会发送CHECKPOINT消息,消息格式为:
当某个节点收到2F+1条CHECKPOINT消息后,便会将高低水位重新置为n∈(H,H+K),并删除排序值小于H的消息日志,释放内存空间。
5.PBFT的视图更新机制
因为PBFT通过主节点完成对消息的排序,因此就存在主节点故障的风险。对此PBFT设计了一套对应的视图更新机制来保证主节点故障的情况下整个系统的可用性。
当某个节点i监测到主节点响应超时,便进入视图更新流程,并发送一条VIEWCHANGE消息,消息格式为:
其中n为最近一个Checkpoint的序号,C为对应的2F+1个CHECKPOINT消息集合。P为一个达成PREPARED状态的消息集合:
Pm表示序号大于n且达成PREPARED状态的消息m的至少1个PRE-PREPARE消息和至少2F个PREPARE消息的集合(也就是使消息m达成PREPARED状态的所有预处理消息和准备消息的总集)。
当新的主节点Primaryv+1收到2F个有效的VIEWCHANGE消息后,会广播一条新视图消息,消息格式为:
其中V是Primaryv+1收到的所有VIEWCHANGE消息的集合,O为以新视图构造的PRE-PREPARE消息的集合,至此视图更新流程结束。这一机制有效确保了系统在视图更新前后达成PREPARED状态的消息排序不变。
四、Hyperledger Fabric的网络拓扑结构与共识机制
Hyperledger Fabric使用PBFT作为其共识算法的底层实现。对于分布式系统而言,数据一致性策略可分为强一致性策略和最终一致性策略。所谓强一致性策略是指系统能够实现在极端条件下的数据一致性,其涉及到复杂的数据交互,且对系统压力较大,并不适合商业级数据存储。因此Hyperledger Fabric采用了最终一致性策略,所谓最终一致性是指系统可以容忍在短时间内不同节点数据不一致的情形,整个区块链网络只需要保证在一定时间周期内达成一致即可。
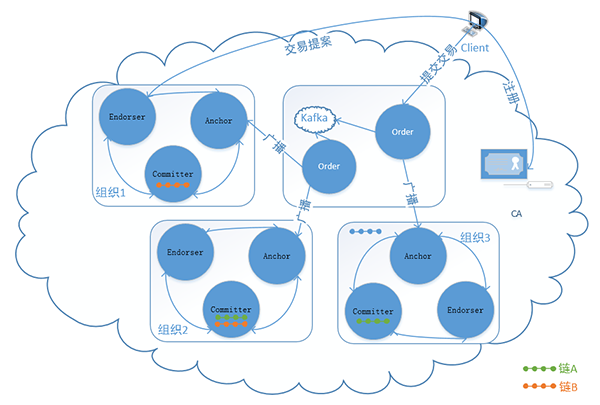
图十九:Hyperledger Fabric的网络拓扑结构
如图所示,Hyperledger Fabric采用多中心的网络架构模式,由独立的排序节点对来自不同终端的交易请求进行规整处理,封装成区块后再下发到整个区块链网络。
Hyperledger Fabric网络下主要有四种类型的节点:
- Client节点(客户端节点),这一节点主要用于提供应用访问区块链网络的入口,负责系统与区块链之间的数据交互。
- Peer节点,包含了Anchor节点(锚节点),Endorser节点(背书节点)和Committer节点(记账节点)。其中锚节点每个组织中至多只有一个,负责和其他组织以及order节点交互,组织网络中的非锚节点不直接参与和外部网络的信息交换。背书节点负责模拟执行来自用户的交易请求,并对请求进行验证和签名。记账节点负责保存区块链信息,更新世界状态等。需要强调的是这三种角色之间并非互斥关系,一个Peer节点可能同时兼有背书节点,记账节点等多种角色,而且所有的Peer节点都是记账节点。
- Order节点,共识机制的核心节点,负责对来自用户的交易请求进行排序,打包成区块后分发给其它组织的锚节点。
- CA节点(鉴权节点),非必要节点,主要负责证书的颁发,身份验证及用户鉴权等。也可通过第三方证书鉴权机构实现。
就Hyperledger Fabric的网络拓扑结构而言,其并不同于如比特币,以太坊等常见公链的网状拓扑结构,而是更接近于具备一定层级关系的树状拓扑结构(就此而言,Hyperledger Fabric并非是一个去中心网络,而是一个多中心网络)。
不同的组织分属于不同的网域,每个组织结构下只暴露一个锚节点作为与其它组织交互的接口。这一设计主要是出于部分企业的数据安全性考虑。很多企业核心数据往往不便于直接暴露在公网中,内外网隔离的设计可以充分确保敏感数据的安全性。
除了不同的组织外,区块链网络中还存在由Order节点组成的排序网络,Order节点有Solo和Kafka两种运行模式。Solo模式由单个Order节点提供排序服务,往往只是用于网络测试和节点数较少的场景。商业应用中一般采用Kafka模式,Order节点将接收到的交易请求发送给Kafka集群,由Kafka集群排序后再返回给Order节点,这一设计大大提升了Order集群的排序分发效率。
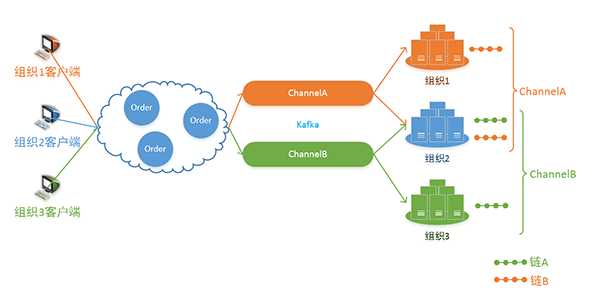
图二十:Hyperledger Fabric的多通道排序机制
在企业应用场景中可能存在一个区块链网络需要承接多种业务的情形,因此Hyperledger Fabric采用了多通道设计。所谓通道指的是一个封闭的业务群,一个Hyperledger Fabric网络中可能存在多个业务群处理不同的业务,彼此之间在逻辑和物理上均相互隔离。有几个业务群就会存在几条不同的区块链,每个节点都只会保存自己加入的通道的区块链数据,进而杜绝了多业务交叉场景下数据外泄的风险。而排序节点也会根据通道的不同将交易请求分发给不同的Kafka队列,实现业务间的链级隔离。
Hyperledger Fabric网络中一个完整的交易流程为:
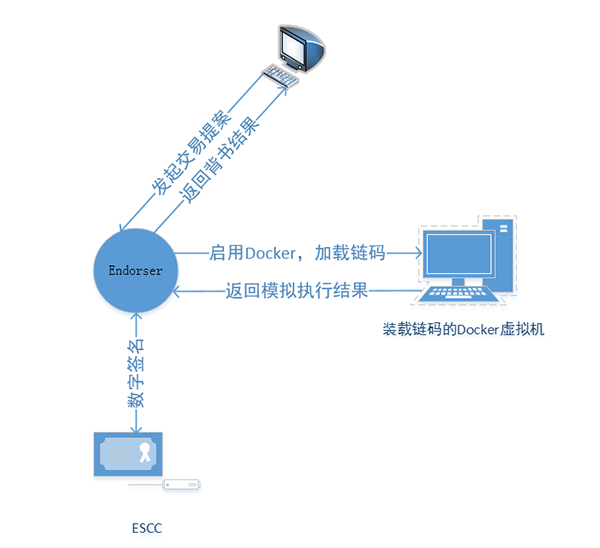
客户端首先提交交易提案发送给背书节点(至少两个,具体可在背书策略中设置,用户可指定要使用的背书节点),背书节点收到交易提案后启动链码(运行在一个隔离的安全容器中,无法被人为干预)模拟交易(仅仅是模拟,并不会更新到区块链网络中)。鉴权验证通过后背书节点会添加数字签名并返回给客户端(理论上多个背书节点返回的执行结果应当一致)。客户端将签名后的交易请求发送给Order节点,Order节点进行排序后打包成区块分发给各组织锚节点。锚节点分发给组织内记账节点,记账节点验证完成后将最新的区块添加到本地区块链中,并更新世界状态。
五、智能合约
图二十一:发起交易和智能合约调用流程
智能合约(链码)是Hyperledger Fabric用于应用和区块链网络之间交互的媒介。链码部署在独立且隔离的Docker容器中,无法被外界干预和篡改,通过gRPC与背书节点通信。背书节点将交易请求发送给链码容器后,链码容器返回给背书节点该笔交易的执行结果。
智能合约类似于应用系统中的对外接口,而交易就是对接口的一次调用。链码中对外接口只提供两个方法,Init方法和Invoke方法。Init方法只会在区块链网络启动时在任意一个节点执行一次,Invoke方法则用于应用和区块链网络之间具体的交互。
链码存在五个生命周期,打包(链码的编译),安装(上传到背书节点),实例化(执行Init方法),升级(链码中的功能拓展和Bug修复),交互(应用调用)。
企业用户可以根据自身业务场景编写不同功能的智能合约来实现应用和区块链网络之间的数据交互。
六、Hyperledger Fabric的业务应用
Hyperledger Fabric是一套专门为机构和企业设计的通用型业务方案。其相比于区块链1.0和2.0,可以灵活的根据用户业务进行定制。而模块化和插件式的服务模式也大大降低了用户的组网成本。非常适用于金融,支付等高敏感性业务场景。而Hyperledger Fabric底层的键值对存储结构也具有很强的扩展性。传统数据库能够存储的数据,理论上Hyperledger Fabric都可以存储。其多通道设计可以实现物理级别的业务解耦,多种业务都可以无干扰地挂载在同一区块链网络下。实现资源复用的同时又避免了机构之间业务交叉产生的数据外泄风险。
Hyperledger Fabric的另一大优势在于用户可以根据自身业务编写智能合约,定制应用系统和区块链网络的数据交互模式。这就为复杂业务场景和区块链技术的缝合提供了便利,使得“区块链+”得以真正进入企业级应用之中。
结语
区块链技术问世以来,十数年间历经三次迭代,其间或誉或诼,不绝于耳。唯有拨开笼罩在区块链上的那层神秘面纱,深究其技术原理,方能得见其真容。单纯作为一种技术而言,区块链本身是价值无涉的。工具能释放出怎样的社会价值,终究取决于其使用者。我们也许惊叹于设计者的旷世奇思,但绝无必要为其赋予太多超脱于技术之外的神秘色彩。区块链也许是通往未来的一个入口,但任何技术奇点的引爆都并非来自于某个单点技术突破,而是酝酿于厚积薄发的逐步嬗变。勤恳与踏实才是推动社会进步的最终驱力,在技术瞬息万变,发展一日千里的当下,我们更当持守此心。
参考文献
[1] Satoshi Nakamoto: Bitcoin:A Peer-to-Peer Electronic Cash System[EB/OL]
[2] Castro,Miguel,Barbara Liskov: Practical Byzantine fault tolerance.OSDI.Vol.99.1999
[3] Kwon,Jae: Tendermint:Consensus without mining.Draft v.0.6,fall(2014)
作者简介:
王翔,毕业于安徽大学2018届电子信息工程专业,现就职于某知名世界五百强互联网企业。致力于服务端系统的架构设计,多活部署,性能优化,业务开发等工作。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】








{kind=link}
{kind=link}
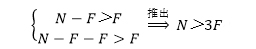{kind=link}
{kind=link}
{kind=link}
{kind=link}
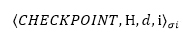{kind=link}
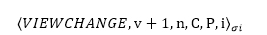{kind=link}
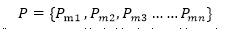{kind=link}
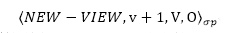{kind=link}
{kind=link}
{kind=link}
{kind=link}