
前言:实验本身并不是很难,照着实验指导书抄就行,不过注意有些sql语句和mysql语句是不相同的,需要进行一定的修改
实验1 数据库定义与操作语言实验
实验1.1 数据库定义实验
1.实验目的
理解和掌握数据库DDL语言,能够熟练使用SQL DDL 语句创建、修改和删除数据库、模式和基本表。
2.实验内容和要求
理解和掌握SQL DDL语句的语法,特别是各种参数的具体含义和使用方法;使用SQL语句创建、修改和删除数据库、模式和基本表。掌握SQL语句常见语法错误的调试方法。
3.实验过程
1)创建数据库
采用中文字符集创建名为 TPCH 的数据库。
CREATE DATABASE TPCH ENCODING = 'GBK ';mysql会报错,删除ENCODING = 'GBK ',创建完数据库后再更改其编码格式即可

2)创建模式
在数据库TPCH中创建名为Sales 的模式。
CREATE DATABASE Sales;可以看到,创建模式成功

3)创建数据库表
在TPCH数据库的 Sales模式中创建8个基本表。
表 1 地区表(region)
| 字段名 | 中文含义 | 类型 | 约束 |
|---|---|---|---|
| regionkey | 地区编号 | int | 主键 |
| name | 地区名称 | char(25) | null |
| comment | 备注 | varchar(150) | null |
表 2 国家表(nation)
| 字段名 | 中文含义 | 类型 | 约束 |
|---|---|---|---|
| nationkey | 国家编号 | int | 主键 |
| name | 国家名称 | char(25) | null |
| regionkey | 地区编号 | int | 外键,参照 region表的 regionkey |
| comment | 备注 | varchar(150) | null |
表 3 供应商基本表(supplier)
| 字段名 | 中文含义 | 类型 | 约束 |
|---|---|---|---|
| suppkey | 供应商编号 | int | 主键 |
| name | 供应商名称 | char(100) | null |
| address | 供应商地址 | varchar(100) | null |
| nationkey | 国家编号 | int | 外键,参照 nation表的 nationkey |
| phone | 供应商电话 | char(30) | null |
| acctbal | 供应商帐户余额 | numeric(12,2) | null |
| comment | 备注 | varchar(100) | null |
表 4 零件基本表(part)
| 字段名 | 中文含义 | 类型 | 约束 |
|---|---|---|---|
| partkey | 零件编号 | int | 主键 |
| name | 零件名称 | varchar(100) | null |
| mfgr | 制造厂 | char(50) | null |
| brand | 品牌 | char(50) | null |
| type | 零件类型 | varchar(25) | null |
| size | 尺寸 | int | null |
| container | 包装 | char(10) | null |
| retailprice | 零售价格 | numeric(8,2) | null |
| comment | 备注 | varchar(20) | null |
表 5 零件供应联系表(partsupp)
| 字段名 | 中文含义 | 类型 | 约束 | 备注 |
|---|---|---|---|---|
| partkey | 零件编号 | int | 外键,参照 part表的 partkey | partkey 和 suppkey 联合作为主键 |
| suppkey | 供应商编号 | int | 外 键 , 参 照supplier 表 的 suppkey | |
| availqty | 可用数量 | int | null | |
| supplycost | 供应价格 | numeric(10,2) | null | |
| comment | 备注 | varchar(200) | null |
表 6 顾客表(customer)
| 字段名 | 中文含义 | 类型 | 约束 |
|---|---|---|---|
| custkey | 顾客编号 | int | 主键 |
| name | 姓名 | varchar(25) | null |
| address | 地址 | varchar(40) | null |
| nationkey | 国家编号 | int | 外键,来自 nation表的 nationkey |
| phone | 电话 | char(30) | null |
| acctbal | 帐户余额 | numeric(12,2) | null |
| mktsegment | 市场分区 | char(10) | null |
| comment | 备注 | varchar(100) | null |
表 7 订单表(orders)
| 字段名 | 中文含义 | 类型 | 约束 |
|---|---|---|---|
| orderkey | 订单编号 | int | 主键 |
| custkey | 顾客编号 | int | 外 键 , 参 照 customer 表 的Custkey |
| orderstatus | 订单状态 | char(1) | null |
| totalprice | 订单金额 | numeric(10,2) | null |
| orderdate | 订单日期 | date | null |
| orderpriority | 订单优先级别 | char(15) | null |
| clerk | 记帐员 | char(16) | null |
| shippriority | 运输优先级别 | char(1) | null |
| comment | 备注 | varchar(60) | null |
表 8 订单明细表(lineitem)
| 字段名 | 中文含义 | 类型 | 约束 | 备注 |
|---|---|---|---|---|
| orderkey | 订单编号 | int | 外键, 参照 orders表的 orderkey | orderkey 和 linenumber 联合作为主键 |
| partkey | 零件编号 | int | 外键,参照 part 表的 partkey | partkey 和 suppkey 联 合参照 partsupp表 的 partkey和 suppkey |
| suppkey | 供应商编号 | int | 外键,参照 supplier表的 suppkey | |
| linenumber | 订单明细编号 | int | null | |
| quantity | 零件数量 | int | null | |
| extendedprice | 订单明细价格 | numeric(8,2) | null | |
| discount | 折扣 | numeric(3,2) | null | |
| tax | 税率 | numeric(3,2) | null | |
| returnflag | 退货标记 | char(1) | null | |
| linestatus | 订单明细状态 | char(1) | null | |
| shipdate | 装运日期 | date | null | |
| commitdate | 委托日期 | date | null | |
| receiptdate | 签收日期 | date | null | |
| shipinstruct | 装运说明 | char(25) | null | |
| shipmode | 装运方式 | char(10) | null | |
| comment | 备注 | varchar(40) | null |
CREATE TABLE region(regionkey INT PRIMARY KEY,name CHAR(25),comment VARCHAR(150));CREATE TABLE nation(nationkey INT PRIMARY KEY,name CHAR(25),regionkey INT,comment VARCHAR(150),FOREIGN KEY(regionkey) REFERENCES region(regionkey));CREATE TABLE supplier(suppkey INT PRIMARY KEY,name CHAR(100),address VARCHAR(100),nationkey INT,phone CHAR(30),acctbal NUMERIC(12,2),comment VARCHAR(100),FOREIGN KEY(nationkey) REFERENCES nation(nationkey));CREATE TABLE part(partkey INT PRIMARY KEY,name VARCHAR(100),mfgr CHAR(50),brand CHAR(50),type VARCHAR(25),size INT,container CHAR(10),retailprice NUMERIC(8,2),comment VARCHAR(20));CREATE TABLE partsupp(partkey INT,suppkey INT,availqty INT,supplycost NUMERIC(10,2),comment VARCHAR(200),PRIMARY KEY(partkey,suppkey),FOREIGN KEY(partkey) REFERENCES part(partkey),FOREIGN KEY(suppkey) REFERENCES supplier(suppkey));CREATE TABLE customer(custkey INT PRIMARY KEY,name VARCHAR(25),address VARCHAR(40),nationkey INT,phone CHAR(30),acctbal NUMERIC(12,2),mktsegment CHAR(10),comment VARCHAR(100),FOREIGN KEY(nationkey) REFERENCES nation(nationkey));CREATE TABLE orders(orderkey INT PRIMARY KEY,custkey INT,orderstatus CHAR(1),totalprice NUMERIC(10,2),orderdate DATE,orderpriority CHAR(15),clerk CHAR(16),shippriority CHAR(1),comment VARCHAR(60),FOREIGN KEY(custkey) REFERENCES customer(custkey));CREATE TABLE lineitem(orderkey INT,partkey INT,suppkey INT,linenumber INT,quantity INT,extendedprice NUMERIC(8,2),discount NUMERIC(3,2),tax NUMERIC(3,2),returnflag CHAR(1),linestatus CHAR(1),shipdate DATE,commitdate DATE,receiptdate DATE,shipinstruct CHAR(25),shipmode CHAR(10),comment VARCHAR(40),PRIMARY KEY(orderkey,linenumber),FOREIGN KEY(partkey,suppkey) REFERENCES partsupp(partkey,suppkey));4.实验总结
- 可以先定义零件供应商子模式,包括Part、Suppler和 PartSupp三个基本表,类似学生、课程和选课数据库模式。
- 可以先不定义实体完整性和参照完整性,待讲完有关概念后再在实验3中练习。
5.思考题
(1)SQL语法规定,双引号括定的符号串为对象名称,单引号括定的符号串为常量字符串,那么什么情况下需要用双引号来界定对象名呢?
(2)数据库对象的完整引用是“服务器名.数据库名.模式名.对象名”,但通常可以省略服务器名和数据库名,甚至模式名,直接用对象名访问对象即可。
1)
答:所插入的一个元素时变量时用双引号。如:
插入字符串型
假如要插入一个名为小小的人,因为是字符串,所以Insert语句中名字两边要加单引号,数值型可以不加单引号如:
Insert into usertable(username) values('小小')如果现在姓名是一个变量thename,则写成:
Insert into usertable(username) values('" & thename & "')
我们在写SQL查询的时候建议还是不厌其烦的加上单引号,除了麻烦些并没有坏处。因为对于主键为字符串类型的查询语句,加不加单引号的性能是相差比较大的。
2)
在一个数据库中创建了一个数据库对象后,据库对象的完整名称应该由服务器名、数据库名、拥有者名和对象名四部分组成,其格式如下:
[ [ [server.][database]. ][ owner_name ]. ]object_name
服务器、数据库和所有者的名称即所谓的对象名称限定符。当引用一个对象时,不需要指定服务器、数据库和所有者,可以利用句号标出它们的位置,从而省略限定符。
实验 1.2 数据基本查询实验
1.实验目的
掌握 SQL 程序设计基本规范,熟练运用 SQL 语言实现数据基本查询,包括单表查询、分组统计查询和连接查询。
2.实验内容和要求
针对TPC-H数据库设计各种单表查询SQL语句、分组统计查询语句;设计单个表针对自身的连接查询,设计多个表的连接查询。理解和掌握SQL查询语句各个子句的特点和作用,按照SQL程序设计规范写出具体的SQL查询语句,并测试通过。
说明:简单地说,SQL程序设计规范包含SQL关键字大写、表名、属性名、存储过程名等标识符大小写混合、SQL程序书写缩进排列等编程规范。
3.实验过程
SELECT语句的一般格式
SELECT [ALL|DISTINCT] <目标列表达式> [别名] [ ,<目标列表达式> [别名]] …FROM <表名或视图名> [别名] [ ,<表名或视图名> [别名]] …[WHERE <条件表达式>][GROUP BY <列名1>[HAVING <条件表达式>]][ORDER BY <列名2> [ASC|DESC] (1)单表查询(实现投影操作)
查询供应商的名称、地址和联系电话。
SELECT name, address, phoneFROM Supplier;结果如下:

(2)单表查询(实现选择操作)
查询最近一周内提交的总价大于1000元的订单的编号、顾客编号等订单的所有信息。
SELECT *FROM OrdersWHERE current_date-orderdate < 7 AND totalprice > 1000;运行结果如下:

(3)不带分组过滤条件的分组统计查询
统计每个顾客的订购金额
SELECT C.custkey, SUM(O.totalprice)FROM Customer C, Orders OWHERE C.custkey = O.custkeyGROUP BY C.custkey;运行结果如下:

(4)带分组过滤条件的分组统计查询
查询订单平均金额超过1000元的顾客编号及其姓名
SELECT C.custkey, MAX(C.name)FROM Customer C, Orders OWHERE C.custkey = O.custkeyGROUP BY C.custkeyHAVING avg(O.totalprice) > 1000;运行结果如下:

(5)单表自身连接查询
查询与“中国英雄集团”在同一个国家的供应商编号,名称和地址信息
SELECT F.suppkey, F.name, F.addressFROM Supplier F, Supplier SWHERE F.nationkey = S.nationkey AND S.name = '中国英雄集团';运行结果如下:

(6)两表连接查询(普通连接)
查询供应价格大于零售价的零件名,制造商名,零售价格和供应价格
SELECT P.name, P.mfgr, P.retailprice, Ps.supplycostFROM Part P, PartSupp PSWHERE P.retailprice > PS.supplycost;运行结果如下:

(7)两表连接查询(自然连接)
查询供应价大于零售价格的零件名,制造商名,零售价和供应价
SELECT P.name, P.mfgr, P.retailprice, Ps.supplycostFROM Part P, PartSupp PSWHERE P.retailprice = PS.supplycost AND P.retailprice > PS.supplycost;(8)三表连接查询
查询顾客“苏举库”订购的订单编号,总价极其订购的零件编号,数量和明细价格
SELECT O.orderskey, O.totalprice, L.partkey, L.quantity, L.extendedpriceFROM Customer C, Orders O, Lineitem LWHERE C.custkey = O.custkeyAND O.orderskey = L.orderskeyAND C.name = '苏举库';4.实验总结
- 正确理解数据库模式结构,才能正确设计数据库查询;
- 连接查询是数据库SQL查询中最重要的查询,连接查询的设计要特别注意,不同的查询表达,其查询执行的性能会有很大差别。
5.思考题
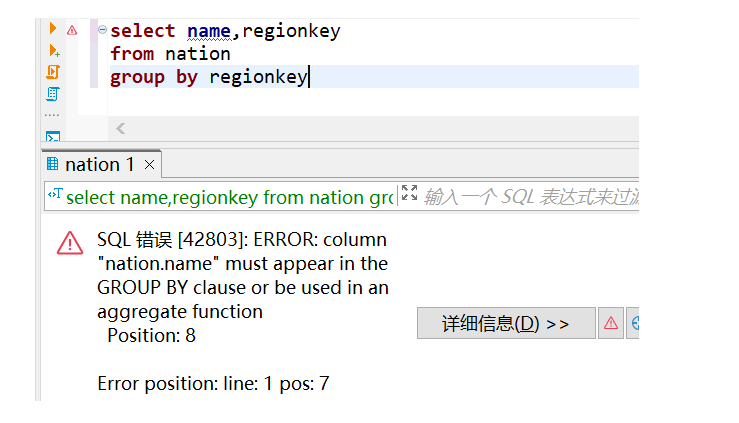
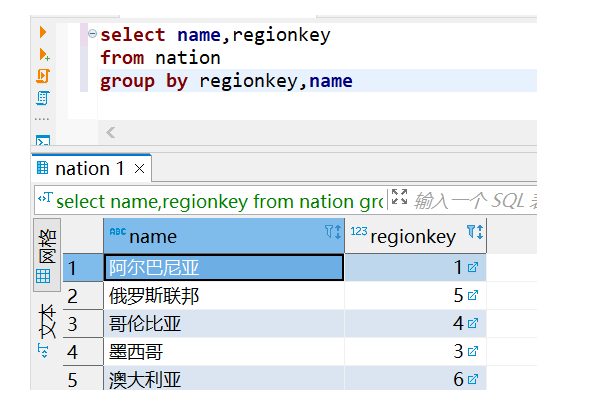
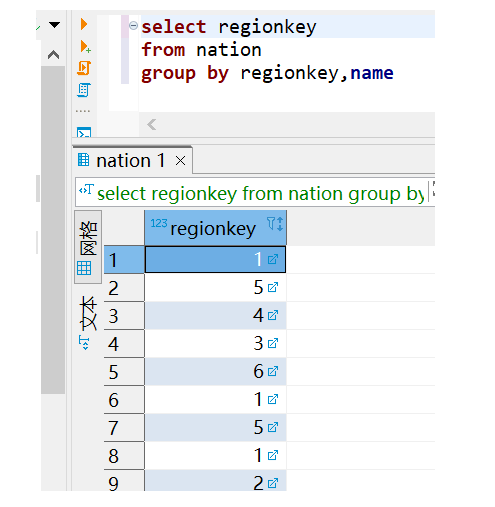
(1)不在GROUP BY子句出现的属性,是否可以出现在SELECT子句中?请举例并上机验证。
不在group by子句出现的属性,不可以出现在select子句中(SELECT子句中的统计列必须出现在GROUP BY子句);而出现在group by子句出现的属性,可以不出现在select子句中。
SELECT子句中的统计列必须出现在GROUP BY子句中,Group By语句从英文的字面意义上理解就是“根据(by)一定的规则进行分组(Group)”.它的作用是通过一定的规则将一个数据集划分成若干个小的区域,然后针对若干个小区域进行数据处理。比如你要根据姓名分组,group by的意思就是根据,你肯定要group by统计的列。
(2)请举例说明分组统计查询中的 WHERE和 HAVING有何区别?
| 优点 | 缺点 | |
|---|---|---|
| where | 先筛选数据在关联,执行效率高 | 不能使用分组中的数据进行筛选 |
| having | 可以使用分组中的计算函数 | 在最后的结果集中进行筛选,执行效率低 |
where可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;having必须要和group by 配合使用,可以把分组计算的函数和分组字段作为筛选条件,在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务。这是因为,在查询语法结构中,WHERE 在 GROUP BY 之前,所以无法对分组结果进行筛选。HAVING 在 GROUP BY 之后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选,这个功能是 WHERE 无法完成的。
WHERE 是直接对表中的字段进行限定,来筛选结果;HAVING 则需要跟分组关键字GROUP BY 一起使用,通过对分组字段或分组计算函数进行限定,来筛选结果。虽然它们都是对查询进行限定,却有着各自的特点和适用场景。很多时候,我们会遇到 2 个都可以用的情况。一旦用错,就很容易出现执行效率低下、查询结果错误,甚至是查询无法运行的情况。
WHERE不能用聚集函数作为条件表达式。
(3)连接查询速度是影响关系数据库性能的关键因素。请讨论如何提高连接查询速度
答:
优化语句,精确条件。实现同一个查询的请求可以有多种方法,不同的方法其执行效率可能会有差别,甚至会差别很大,这就需要我们对于聚进行优化,找出查询速度最快的语句。
用程序中,
保证在实现功能的基础上,尽量减少对数据库的访问次数;通过搜索参数,尽量减少对表的访问行数,最小化结果集,从而减轻网络负担;能够分开的操作尽量分开处理,提高每次的响应速度;在数据窗口使用SQL时,尽量把使用的索引放在选择的首列;算法的结构尽量简单;在查询时,不要过多地使用通配符如SELECT * FROM T1语句,要用到几列就选择几列如:
SELECT COL1,COL2 FROM T1;
在可能的情况下尽量限制尽量结果集行数如:
SELECT TOP 300 COL1,COL2,COL3 FROM T1,因为某些情况下用户是不需要那么多的数据的。
不要在应用中使用数据库游标,游标是非常有用的工具,但比使用常规的、面向集的SQL语句需要更大的开销;
按照特定顺序提取数据的查找。
避免使用不兼容的数据类型。例如float和int、char和varchar、binary和varbinary是不兼容的。
数据类型的不兼容可能使优化器无法执行一些本来可以进行的优化操作。例如:
SELECT name FROM employee WHERE salary > 60000
在这条语句中,如salary字段是money型的,则优化器很难对其进行优化,因为60000是个整型数。
我们应当在编程时将整型转化成为钱币型,而不要等到运行时转化。
尽量避免在WHERE子句中对字段进行函数或表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
SELECT * FROM T1 WHERE F1/2=100
应改为:
SELECT * FROM T1 WHERE F1=100*2
SELECT * FROM RECORD WHERE SUBSTRING(CARD_NO,1,4)=’5378’
应改为:
SELECT * FROM RECORD WHERE CARD_NO LIKE ‘5378%’
SELECT member_number, first_name, last_name FROM members
WHERE DATEDIFF(yy,datofbirth,GETDATE()) > 21
应改为:
SELECT member_number, first_name, last_name FROM members
WHERE dateofbirth < DATEADD(yy,-21,GETDATE())
即:任何对列的操作都将导致表扫描,它包括数据库函数、计算表达式等等,查询时要尽可能将操作移至等号右边。
避免使用!=或<>、IS NULL或IS NOT NULL、IN ,NOT IN等这样的操作符,因为这会使系统无法使用索引,而只能直接搜索表中的数据。例如:
SELECT id FROM employee WHERE id != ‘B%’
优化器将无法通过索引来确定将要命中的行数,因此需要搜索该表的所有行。
尽量使用数字型字段,一部分开发人员和数据库管理人员喜欢把包含数值信息的字段设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接回逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
合理使用EXISTS,NOT EXISTS子句。如下所示:
SELECT SUM(T1.C1)FROM T1 WHERE(
(SELECT COUNT()FROM T2 WHERE T2.C2=T1.C2>0)
2.SELECT SUM(T1.C1) FROM T1WHERE EXISTS(
SELECT * FROM T2 WHERE T2.C2=T1.C2)
两者产生相同的结果,但是后者的效率显然要高于前者。因为后者不会产生大量锁定的表扫描或是索引扫描。
如果你想校验表里是否存在某条纪录,不要用count()那样效率很低,而且浪费服务器资源。可以用EXISTS代替。如:
IF (SELECT COUNT(*) FROM table_name WHERE column_name = ‘xxx’)
可以写成:
IF EXISTS (SELECT * FROM table_name WHERE column_name = ‘xxx’)
经常需要写一个T_SQL语句比较一个父结果集和子结果集,从而找到是否存在在父结果集中有而在子结果集中没有的记录,如:
SELECT a.hdr_key FROM hdr_tbl a---- tbl a 表示tbl用别名a代替
WHERE NOT EXISTS (SELECT * FROM dtl_tbl b WHERE a.hdr_key = b.hdr_key)SELECT a.hdr_key FROM hdr_tbl a
LEFT JOIN dtl_tbl b ON a.hdr_key = b.hdr_key WHERE b.hdr_key IS NULLSELECT hdr_key FROM hdr_tbl
WHERE hdr_key NOT IN (SELECT hdr_key FROM dtl_tbl)
三种写法都可以得到同样正确的结果,但是效率依次降低。
尽量避免在索引过的字符数据中,使用非打头字母搜索。这也使得引擎无法利用索引。 见如下例子:
SELECT * FROM T1 WHERE NAME LIKE ‘%L%’
SELECT * FROM T1 WHERE SUBSTING(NAME,2,1)=’L’
SELECT * FROM T1 WHERE NAME LIKE ‘L%’
即使NAME字段建有索引,前两个查询依然无法利用索引完成加快操作,引擎不得不对全表所有数据逐条操作来完成任务。
而第三个查询能够使用索引来加快操作。
充分利用连接条件,在某种情况下,两个表之间可能不只一个的连接条件,这时在 WHERE 子句中将连接条件完整的写上,有可能大大提高查询速度。例:
SELECT SUM(A.AMOUNT) FROM ACCOUNT A,CARD B WHERE A.CARD_NO = B.CARD_NO
SELECT SUM(A.AMOUNT) FROM ACCOUNT A,CARD B WHERE A.CARD_NO = B.CARD_NO AND A.ACCOUNT_NO=B.ACCOUNT_NO
第二句将比第一句执行快得多。
消除对大型表行数据的顺序存取,尽管在所有的检查列上都有索引,但某些形式的WHERE子句强迫优化器使用顺序存取。如:
SELECT * FROM orders WHERE (customer_num=104 AND order_num>1001) OR order_num=1008
解决办法可以使用并集来避免顺序存取:
SELECT * FROM orders WHERE customer_num=104 AND order_num>1001
UNION
SELECT * FROM orders WHERE order_num=1008
这样就能利用索引路径处理查询。
避免困难的正规表达式。
- 建立索引可以提高查询速度,但是删除插入操作多了,索引会影响速度;
- 必须定期重建索引;
- 定期清理数据库文件中的碎片,即压缩数据文件,具体可以参考帮助文档;
- 如果碎片太多,只能重建数据文件;
- 优化sql语句,这是非常重要的,减少连接查询和排序等。
实验1.3 数据高级查询实验
1.实验目的
掌握SQL嵌套查询和集合查询等各种高级查询的设计方法等。
2.实验内容和要求
针对TPC-H数据库,正确分析用户查询要求,设计各种嵌套查询和集合查询
3.实验过程
(1)IN 嵌套查询
查询订购了“海大”制造的“船舶模拟驾驶舱”的顾客。
SELECT *FROM Customer CWHERE C.Custkey IN (SELECT O.CustkeyFROM Orders O, PartSupp PS, Supplier S, Part P, Lineitem LWHERE S.Name = '海大'AND P.Name = '船舶模拟驾驶舱'AND P.Partkey = L.PartkeyAND L.Suppkey = S.Suppkey)运行结果:

说明没有这个顾客
另一种方法
SELECT custkey, `name`FROM customerWHERE custkey IN (SELECT o.custkeyFROM orders o, lineitem l, part pWHERE o.orderkey = l.orderkeyAND l.partkey = p.partkeyAND p.mfgr = '海大'AND p.name = '船舶模拟驾驶舱');
(2) 单层EXISTS 嵌套查询
查询没有购买过“海大”制造的“船舶模拟驾驶舱”的顾客。
涉及Customer, Orders, Lineitem, PartSupp, Part
SELECT custkey, NAMEFROM customer cWHERE NOT EXISTS (SELECT o.custkeyFROM orders o, lineitem l, partsupp ps, part pWHERE c.custkey = o.custkeyAND o.orderkey = l.orderkeyAND l.partkey = ps.partkeyAND l.suppkey = ps.suppkeyAND p.mfgr = '海大'AND p.name = '船舶模拟驾驶舱');结果如下:

(3)双层EXISTS 嵌套查询
查询至少购买过顾客“张三”购买过的全部零件的顾客姓名。
SELECT CA.nameFROM Customer CAWHERE NOT EXISTS (SELECT *FROM customer CB, orders OB, Lineitem LBWHERE CB.custkey = OB.custkeyAND OB.orderkey = LB.orderkeyAND CB.name = '张三'AND NOT EXISTS (SELECT *FROM Orders OC, Lineitem LCWHERE CA.custkey = OC.custkeyAND OC.orderkey = LC.orderkeyAND LB.suppkey = LC.suppkeyAND LB.partkey = LC.partkey));(4) FROM 子句中的嵌套查询
查询订单平均金额超过1 万元的顾客中的中国籍顾客信息。
涉及Customer, Orders
SELECT C.*FROM Customer C, (SELECT CustkeyFROM OrdersGROUP BY CustkeyHAVING AVG(Totalprice) > 10000) B, Nation NWHERE C.Custkey = B.CustkeyAND C.Nationkey = N.NationkeyAND N.Name = '中国';运行结果:
(5) 集合查询(交)
查询顾客“张三”和“李四”都订购过的全部零件信息。
涉及Customer, Orders, Lineitem, PartSupp, Part
SELECT p.*FROM Part P, Customer C, Orders O, Lineitem L, PartSupp PSWHERE C.Name = '张三'AND C.Custkey = O.CustkeyAND O.Orderkey = L.OrderkeyAND L.Suppkey = PS.SuppkeyAND L.Partkey = PS.PartkeyAND PS.Partkey = P.PartkeyINTERSECTSELECT p.*FROM Part P, Customer C, Orders O, Lineitem L, PartSupp PSWHERE C.Name = '李四'AND C.Custkey = O.CustkeyAND O.Orderkey = L.OrderkeyAND L.Suppkey = PS.SuppkeyAND L.Partkey = PS.PartkeyAND PS.Partkey = P.Partkey;(6) 集合查询(并)
查询顾客“张三”和“李四”订购的全部零件的信息。
涉及Customer, Orders, Lineitem, PartSupp, Part
SELECT p.*FROM Part P, Customer C, Orders O, Lineitem L, PartSupp PSWHERE C.Name = '张三'AND C.Custkey = O.CustkeyAND O.Orderkey = L.OrderkeyAND L.Suppkey = PS.SuppkeyAND L.Partkey = PS.PartkeyAND PS.Partkey = P.PartkeyUNIONSELECT p.*FROM Part P, Customer C, Orders O, Lineitem L, PartSupp PSWHERE C.Name = '李四'AND C.Custkey = O.CustkeyAND O.Orderkey = L.OrderkeyAND L.Suppkey = PS.SuppkeyAND L.Partkey = PS.PartkeyAND PS.Partkey = P.Partkey;(7) 集合查询(差)
查询顾客“张三”订购过而“李四”没有订购过的零件的信息。
涉及Customer, Orders, Lineitem, PartSupp, Part
SELECT p.*FROM Part P, Customer C, Orders O, Lineitem L, PartSupp PSWHERE C.Name = '张三'AND C.Custkey = O.CustkeyAND O.Orderkey = L.OrderkeyAND L.Suppkey = PS.SuppkeyAND L.Partkey = PS.PartkeyAND PS.Partkey = P.PartkeyEXCEPTSELECT p.*FROM Part P, Customer C, Orders O, Lineitem L, PartSupp PSWHERE C.Name = '李四'AND C.Custkey = O.CustkeyAND O.Orderkey = L.OrderkeyAND L.Suppkey = PS.SuppkeyAND L.Partkey = PS.PartkeyAND PS.Partkey = P.Partkey;4.实验总结
这次实验主要内容是数据查询,涉及到了嵌套查询和集合操作的使用,较之基本查询技巧性更强,实现的功能更复杂。
嵌套查询使用关键字IN,判断某数据是否属于查询结果集合;也使用EXISTS/NOT EXISTS,判断数据元组是否满足某查询结果;使用FROM子句嵌套,直接将查询结果作为一个表处理。同时,嵌套查询往往和聚集函数、连接查询配合使用。
集合操作的方法,将两个查询结果作为结果,可以找到它们的并、交、差集合,从而找到满足条件的数据集合。
5.思考题
(1)试分析什么类型的查询可以用连接查询实现,什么类型的查询用只能用嵌套查询实现?
(2)试分析不相关子查询和相关子查询的区别。
1)
连接查询在算法实现上,一定可以通过嵌套循环实现,因此连接查询一定能被嵌套查询等价替换。由于嵌套查询在嵌套条件上提供了一些语义,因此嵌套查询不一定能被转换为连接查询。
从语义上看,连接查询首先是对两个表进行笛卡尔积运算(不带条件的),然后对得到的元组集合进行条件筛选,因此连接查询适用于需要将多个表的属性关联起来的查询需求。嵌套查询则是外层表和内层表进行嵌套罗列,嵌套时可以使用 IN、ANY、ALL、EXISTS 谓词。这些谓词的使用使得嵌套查询语义不一定能被连接查询实现。
连接查询在算法实现上不一定需要通过嵌套循环实现,因此效率往往高于嵌套查询。
2)
- 处理次数不同
- 相关子查询:相关子查询被多次处理,需要重复求值以供外部查询使用。
- 不相关子查询:不相关子查询的处理一次完成,执行后传递给外部查询。
- 依赖不同
- 相关子查询:相关子查询中的查询条件取决于外部查询中的值。
- 不相关子查询:无关子查询是独立于外部查询的子查询,不依赖于外部查询中的值。
- 效率不同
- 相关子查询:相关子查询可以嵌套在多个层中,但嵌套层越多,效率越低。
- 不相关子查询:不相关子查询不能嵌套,效率高于相关子查询。
实验1.4 数据更新实验
1.实验目的
熟悉数据库的数据更新操作,能够使用SQL语句对数据库进行数据的插入,修改、删除操作。
2.实验内容和要求
针对TPC-H数据库设计单元组插入,批量数据插入,修改数据和删除数据等SQL语句。理解和掌握INSERT、UPDATE和 DELETE语法结构的各个组成成分,结合嵌套SQL子查询,分别设计几种不同形式的插入、修改和删除数据的语句,并调试成功。
3.实验过程
插入元组语句格式
INSERTINTO <表名> [(<属性列1>[,<属性列2 >…)]VALUES (<常量1> [,<常量2>] … )(1)INSERT 基本语句(插入全部列的数据)
插入一条顾客记录,要求每列都给一个合理的值
INSERT INTO CustomerVALUES (30, '张三', '北京市', 40, '010-51001199', 0.000, 'Northeast', 'VIP Customer');可以看到,插入成功
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ElbGbs99-1671623563428)(C:\Users\86159\AppData\Roaming\Typora\typora-user-images\1670124044974.png)]](https://file.lsjlt.com/upload/f/202310/20/5xpbnnhcwuk.png)
(2)INSERT 基本语句(插入部分列的数据)
插入一条顾客记录,只给出顾客编号和姓名
INSERT INTO Customer (custkey, name)VALUES (1, '李明');可以看到,插入成功
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8SqiVmMM-1671623563429)(C:\Users\86159\AppData\Roaming\Typora\typora-user-images\1670124070916.png)]](https://file.lsjlt.com/upload/f/202310/20/2anko5j20y1.png)
修改数据语句格式
UPDATE <表名>SET <列名>=<表达式>[,<列名>=<表达式>]…[WHERE <条件>];(3)UPDATE 语句(修改部分记录的部分列值)
修改张三的国家编号为50
UPDATE customerSET regionkey = 50WHERE name='张三';可以看到,更新成功
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JEjPtKsj-1671623563430)(C:\Users\86159\AppData\Roaming\Typora\typora-user-images\1670124172623.png)]](https://file.lsjlt.com/upload/f/202310/20/ej1qipkpunx.png)
删除数据语句格式
DELETEFROM <表名>[WHERE <条件>];(4)DELETE 语句(删除给定条件点的所有记录)
删除顾客张三的所有订单记录。
涉及Lineitem,Orders,Customer 表
先删除张三的订单明细记录
DELETE FROM Lineitem LWHERE Orderkey IN (SELECT OrderkeyFROM Orders O, Customer CWHERE O.Custkey = C.CustkeyAND C.Name = '张三');再删除张三的订单记录
DELETE FROM OrdersWHERE Custkey = (SELECT OrderkeyFROM Orders O, Customer CWHERE O.Custkey = C.CustkeyAND C.Name = '张三');可以看到,关于张三的记录全部删除

4.实验总结
这次实验主要内容是数据更新,包括了数据插入,数据更新及数据删除。数据插入需要注意是否全部给值,如果只给必要的几个字段添加值需要指出添加值的字段,和值一一对应。数据更新要先找到需要更新的数据(配合查询)再进行更新操作。删除数据记录使用关键字DELETE(删除数据库或表用关键字DROP),WHERE后面写删除数据需要满足的条件。注意,如果存在主外键关系,应该先删除子表中的数据再删除主表中的数据。
5.思考题
(1)请分析数据库模式更新和数据更新SQL语句的异同。
(2)请分析数据库系统除了INSERT、UPDATE 和 DELETE等基本的数据更新语句之外,还有哪些可以用来更新数据库基本表数据的SQL语句?
1)
Alter用来修改基本表,是对表的结构进行操作,比如对字段增加,删除,修改类型。
Update用来修改表中的数据,修改某一行某一列的值。
2)
LOAD,DATA,INFILE,SELECT INTO
实验1.5 视图实验
1.实验目的
熟悉SQL语言有关视图的操作,能够熟练使用SQL语句来创建需要的视图,定义数据库外模式,并能使用所创建的视图实现数据管理。
2.实验内容和要求
针对给定的数据库模式,以及相应的应用需求,创建视图和带WITH CHECK OPTION的视图,并验证视图WITH CHECK OPTION选项的有效性。理解和掌握视图消解执行原理,掌握可更新视图和不可更新视图的区别。
3.实验过程
视图的特点
- 虚表,是从一个或几个基本表(或视图)导出的表
- 只存放视图的定义,不存放视图对应的数据
- 基表中的数据发生变化,从视图中查询出的数据也随之改变
(1)创建视图(省略视图列名)
创建一个“河北大力集团”供应商供应的零件视图V_DLMU_PartSupp1,要求列出供应零件的编号、零件名称、可用数量、零售价格、供应价格和备注等信息。
涉及Part.partkey, Part.name, PartSupp.availqty, Part.retailprice, PartSupp.supplycost, Part.comment,Supplier
CREATE VIEW V_DLMU_PartSupp1ASSELECT P.Partkey, P.Name, PS.Availqty, P.Retailprice, PS.Supplycost, P.CommentFROM Part P, PartSupp PSWHERE P.Partkey = PS.partkeyAND PS.Suppkey IN (SELECT SuppkeyFROM Supplier SWHERE S.Name = '河北大力集团');
(2)创建视图(不能忽略列名的情况)
创建一个视图V_CustAvgOrder,按顾客统计平均每个订单的购买金额和零件数量,要求输出顾客编号,姓名,平均购买金额和平均购买零件数量。
涉及Customer, Orders, Lineitem
CREATE VIEW V_CustAvgOrder (Custkey, Name, Avgprice, Avgquan)ASSELECT O.Custkey, C.Name, AVG(O.Totalprice), AVG(L.Quantity)FROM Customer C, Orders O, Lineitem LWHERE C.Custkey = O.CustkeyAND L.Orderkey = O.OrderkeyGROUP BY O.Custkey, C.Name;
(3)创建视图(WITH CHECK OPTION)
使用WITH CHECK OPTION,创建一个“河北大力集团”供应商供应的零件视图V_DLMU_PartSupp2,要求列出供应零件的编号、供应商编号、可用数量和供应价格信息。然后通过该视图分别增加、删除和修改一条“海大汽配”零件供应记录,验证WITH CHECK OPTION是否起作用。
CREATE VIEW V_DLMU_PartSupp2ASSELECT Partkey, Suppkey, Availqty, SupplycostFROM PartSuppWHERE Suppkey = (SELECT SuppkeyFROM SupplierWHERE Name = '河北大力集团')WITH CHECK OPTION;检测一下WITH CHECK OPTION是否起到作用
INSERT INTO V_DLMU_PartSupp2 VALUES(10086,001,600,66666);
报错说明WITH CHECK OPTION起到作用
(4)删除视图
删除V_DLMU_PartSupp2视图
DROP VIEW V_DLMU_PartSupp2;在视图列表中找不到V_DLMU_PartSupp2视图,说明删除成功

总结:视图的作用
-
视图能够简化用户的操作
-
视图使用户能以多种角度看待同一数据
-
视图对重构数据库提供了一定程度的逻辑独立性
-
视图能够对机密数据提供安全保护
-
适当的利用视图可以更清晰的表达查询
4.实验总结
实验主要练习了创建视图相关的SQL语句操作。创建视图的时候如果可以省略列名,则视图列名使用选择的属性列列名;也可以指定列名(创建视图时指定,与属性列一一对应)。WITH CHECK OPTION表示视图里面所有的元组都要满足WHERE子句中的条件,无论时修改前还是修改后都必须遵从此规则。透过视图进行的插入、更新或删除操作,都需要符合视图定义中的谓词条件。使用WITH CHECK OPTION需要视图中有WHERE子句,否则该语句是多余的。
5.思考题
(1)请分析视图和基本表在使用方面有哪些异同
(2)请具体分析修改基本表的结构对相应的视图会产生何种影响?
1)
- 视图是已经编译好的sql语句,而基本表不是。
- 视图没有实际的物理记录,而基本表有。
- 基本表是内容,视图是窗口。
- 基本表只用物理空间而视图不占用物理空间,视图只是逻辑概念的存在,表可以及时四对它进行修改,但视图只能有创建的语句来修改。
- 基本表是内模式,视图是外模式。
- 视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合。从安全的角度说,视图可以不给用户接触数据表,从而不知道表结构。
- 基本表属于全局模式中的表,是实表;视图属于局部模式的表,是虚表。
- 视图的建立和删除只影响视图本身,不影响对应的基本表。
2)
修改视图会影响所有调用视图的函数和存储过程,如果这些函数和存储过程里的语句因为视图的修改失效,就会产生无效包。 修改基表的结构将导致基表与视图的映像关系被破坏,导致视图不能正常工作答案
实验1.6 索引实验
1.实验目的
掌握索引设计原则和技巧,能够创建合适的索引以提高数据库查询、统计分析效率。
2.实验内容和要求
针对给定的数据库模式和具体应用需求,创建唯一索引、函数索引、复合索引等;修改索引;删除索引。设计相应的SQL查询验证索引有效性。学习利用EXPLAIN命令分析SQL查询是否使用了所创建的索引,并能够分析其原因,执行SQL查询并估算索引提高查询效率的百分比。要求实验数据集达到10万条记录以上的数据量,以便验证索引效果。
3.实验过程
建立索引语句格式
CREATE [UNIQUE] [CLUSTER] INDEX <索引名> ON <表名>(<列名>[<次序>][,<列名>[<次序>] ]…);- UNIQUE表明此索引每一个索引值只对应唯一的数据
- CLUSTER表示要建立的索引是聚簇索引。聚簇索引是指索引顺序与表中记录的物理顺序一致的索引组织。
(1)创建唯一索引
在顾客表的名字字段上创建唯一索引。
CREATE UNIQUE INDEX part_name ON part (name);验证查询速度
SELECT NAME FROMcustomer WHERENAME = '张三';可以看到,查询速度极大提升

(2)创建函数索引(对某个属性的函数创建索引,称为函数索引)
在零件表的零件名称字段上创建一个零件名称长度的函数索引。
CREATE INDEX Idx_part_name_fun ON Part (LENGTH(name));(3)创建复合索引(对两个及两个以上的属性创建索引,称为复合索引)
在零件表的制造商和品牌两个字段上创建一个复合索引。
CREATE UNIQUE INDEX Idx_part_mfgr_brand ON Part (mfgr, brand);(4)创建Hash 索引
在零件表的名称字段上创建一个Hash索引。
CREATE INDEX Idx_part_name_hash ON Part USING HASH(name);(5)修改索引名称
修改零件表的名称字段上的索引名。
ALTER INDEX Idx_part_name_hash RENAME TO Idx_part_name_hash_new ;建立索引的目的:加快查询速度(相当于书的目录)
4.实验总结
这次实验主要练习索引和用户权限相关的SQL语句操作。创建唯一索引**CREATE UNIQUE INDEX 索引名 ON 表名(列名1,列名2……)**直接创建,也可添加其他索引。定义不同用户对于数据的操作权限,创建用户后将对应的权限赋予用户即可。
5.思考题
在一个表的多个字段上创建的复合索引,与在相应的每个字段上创建的多个简单索引有何异同?请设计相应的例子加以验证。
答:
复合索引
根据查询需求在多个字段设置一个索引
例如你有一个学生表。
字段包含学号, 班级, 姓名,性别, 出生年月日。
你创建一个组合索引 ( 班级, 姓名)
那么
SELECT * FROM 学生表 WHERE 班级='2010级3班' AND 姓名='张三' 将使用索引.
SELECT * FROM 学生表 WHERE 班级='2010级3班' 将使用索引 .
SELECT * FROM 学生表 WHERE 姓名='张三' 将不使用索引。
多个单列索引
在每个需要索引的字段上设置一个索引
删除掉上面的索引
再创建两个 独立索引
索引1 ( 班级)
索引2 ( 姓名)
那么
SELECT * FROM 学生表 WHERE 班级='2010级3班' AND 姓名='张三' 将根据数据库的分析信息, 自动选择使用索引1或者索引2中的一个 (理论上会使用 索引2, 因为 姓名=张三的人少, 优先找到所有 姓名为 张三的人以后, 然后再从这些数据中, 找班级 = ‘2010级3班’ 的
SELECT * FROM 学生表 WHERE 班级='2010级3班' 将使用索引1 .
SELECT * FROM 学生表 WHERE 姓名='张三' 将使用索引2。
区别:
多个单列索引实现简单,那个字段需要就在哪里加,而复合索引的话,需要根据需求,考虑好索引顺序设置索引。
2、再查询中,如果查询条件使用where连接的,则多个单列索引中只有一个索引会生效,而复合索引在设计的时候已经考虑了索引顺序,所以这时候,复合索引的效率是要比多个单列索引效率高。
组合索引是组合条件查询时有条件查询的顺序很重要。
##### **(5)修改索引名称**修改零件表的名称字段上的索引名。```sqlALTER INDEX Idx_part_name_hash RENAME TO Idx_part_name_hash_new ;建立索引的目的:加快查询速度(相当于书的目录)
4.实验总结
这次实验主要练习索引和用户权限相关的SQL语句操作。创建唯一索引**CREATE UNIQUE INDEX 索引名 ON 表名(列名1,列名2……)**直接创建,也可添加其他索引。定义不同用户对于数据的操作权限,创建用户后将对应的权限赋予用户即可。
5.思考题
在一个表的多个字段上创建的复合索引,与在相应的每个字段上创建的多个简单索引有何异同?请设计相应的例子加以验证。
答:
复合索引
根据查询需求在多个字段设置一个索引
例如你有一个学生表。
字段包含学号, 班级, 姓名,性别, 出生年月日。
你创建一个组合索引 ( 班级, 姓名)
那么
SELECT * FROM 学生表 WHERE 班级='2010级3班' AND 姓名='张三' 将使用索引.
SELECT * FROM 学生表 WHERE 班级='2010级3班' 将使用索引 .
SELECT * FROM 学生表 WHERE 姓名='张三' 将不使用索引。
多个单列索引
在每个需要索引的字段上设置一个索引
删除掉上面的索引
再创建两个 独立索引
索引1 ( 班级)
索引2 ( 姓名)
那么
SELECT * FROM 学生表 WHERE 班级='2010级3班' AND 姓名='张三' 将根据数据库的分析信息, 自动选择使用索引1或者索引2中的一个 (理论上会使用 索引2, 因为 姓名=张三的人少, 优先找到所有 姓名为 张三的人以后, 然后再从这些数据中, 找班级 = ‘2010级3班’ 的
SELECT * FROM 学生表 WHERE 班级='2010级3班' 将使用索引1 .
SELECT * FROM 学生表 WHERE 姓名='张三' 将使用索引2。
区别:
多个单列索引实现简单,那个字段需要就在哪里加,而复合索引的话,需要根据需求,考虑好索引顺序设置索引。
2、再查询中,如果查询条件使用where连接的,则多个单列索引中只有一个索引会生效,而复合索引在设计的时候已经考虑了索引顺序,所以这时候,复合索引的效率是要比多个单列索引效率高。
组合索引是组合条件查询时有条件查询的顺序很重要。
来源地址:https://blog.csdn.net/qq_51684393/article/details/128401328













