
图片来自 Pexels
这个 No 并不是 Not 的意思,而是 Not Only 的缩写。不得不说这个缩写实在是很坑爹,单从字面上应该没人能猜出来它是这个意思。
而且即使解读成 Not Only SQL,还是有点云里雾里,不是很能精准地 get 到它的点。
因为 SQL 的英文全写是 Structured Query Language,也就是结构化查询语言的意思。它可以认为是一门特殊的编程语言,但“不仅仅是 SQL”是啥意思?
的确令人费解,所以我们从字面意思上去理解是不行的,我们需要从实际应用场景去理解。
SQL 的应用场景是关系型数据库,比如我们常用的 Oracle、MySQL,这些就是关系型数据库。
我们理解数据库的时候,往往会从表的结构入手去理解。数据库当中存储的是一张张的表,表呢是一行行数据组成的,而每一行数据都有固定的字段。
我想这点大家应该非常熟悉,即使没有学过数据库或者是像我这样已经还给老师的,应该或多或少都有印象。
但是为什么它会被叫做关系型数据库,而不是表结构数据库呢?
因为在数据库当中,关系要比表结构更重要。表结构只是一种形式,而数据库当中核心的设计理念其实是关系。
这也是为什么我们学习数据库的时候都需要从 ER 图开始,而不是上来就讲数据库使用的方法,或者是 SQL 语言的细节。
如果你想不明白这句话的含义,也没有关系,我们先放一放,最后再回到这个话题来。
问题来了,我们知道了常用的 SQL 数据库是关系型数据库,那么 NoSQL 代表的数据库又是什么呢?
关于 NoSQL 概念我至少看到了两种说法:
- 非关系型数据库
- 文档型数据库
我个人在理解的时候觉得这两种说法都不是非常完美,但相比之下显然是第二种更好,因为第一种说法完全没有给我们提供任何信息。
文档型数据库这里的文档,并不是我们常规理解的一篇文档的含义,而是指的数据存储的结构和核心逻辑。
一个生动的例子
和大多数技术上的概念一样,NoSQL 也比较晦涩,很难单纯用语言将它描述清楚。
所以我决定举一个生动活泼,大家都耳熟能详的例子——就是万能的 X 宝。
下面是一张 X 宝当中的商品详情页的图(随便选取,并非广告,如有巧合,请付推广费):
这张图大家应该都很熟悉了,在我们平时的网上购物的活动当中,一定见过了许多次。
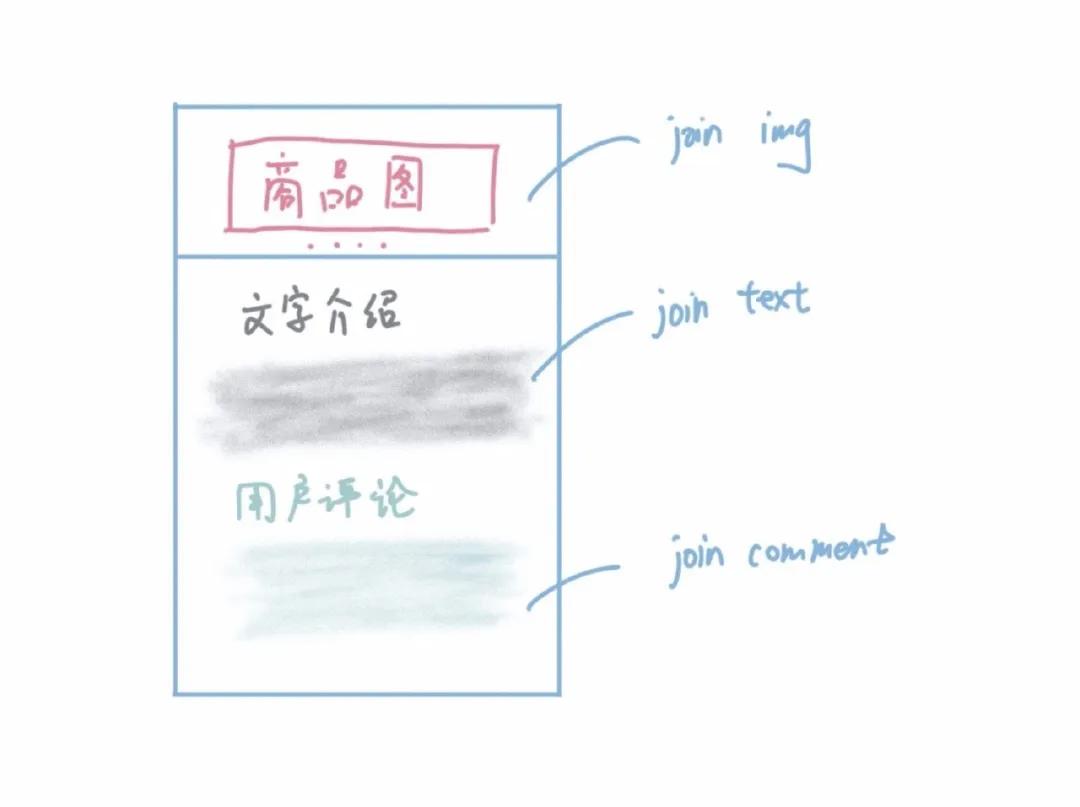
它看起来有些眼花缭乱,我们把上面的内容做个抽象和精简,画成一张草图,它大概是这样的(的确有些草率):
也就是说我们把一个商品详情页展示的内容大概分成了三个部分:
- 商品图
- 商品的一些介绍说明
- 用户的评论
各大电商公司商品详情页的设计大同小异,也许有些细节不太一样,但是整体上的模块都相差不大。
为了简化问题,我们就假设商品详情页需要关联图片信息、文字说明和用户评论这三张表。
其实这样划分不太科学,比如文字介绍和商品图可以都存在商品详情页的表中。
比如除了这些信息之外,还有商品的售卖信息,比如库存、价格、当前的优惠、活动等等,但是这些和我们最后的结论关系不大,可以简单这么理解。
根据上面的划分方式,我们应该根据 itemID 去查询商品的图片、文字以及评论信息,这从表面上看当然没有问题。
但实际上这是有问题的,问题在于这些数据都不是一对一的关系,而是一对多的关系。
比如头部展示的图片往往不止一张,文字说明可能也不止一段,同样用户的评论可能也不止一条。这个问题怎么解决呢?
你可能会想出办法来,这不难啊,我们在 img 和 text 以及 comment 的表里都加入 itemID 这个字段,在我们查询的时候通过 itemID 进行关联,不就 OK 了么?
这样做当然可以,假设你是负责这个项目的程序员,你做出了这个更新,成功上线了之后,产品又给你提了一个新的需求。
她说我想要在文字介绍和用户评论里面都展示图片,虽然系统一开始不是这么设计的,但是我不管,我就是需要,立刻马上。
你翻了好一会白眼,冷静了许久,想了想,终于想到了两种方案:
- 第一个方案是在目前的图片表上加上字段,用来判断图片的用途是详情页展示还是评论页展示,把之后要加的文本介绍和评论页中的图片依然存在这张表上。
- 第二个方案是重新建新的表,专表专用,专门负责存放评论页和说明页的图片。
第一个方案的好处是我们不用建新的表,避免了表的冗余,如果每一个需求都需要建新的表,显然对于后续的维护是一个巨大的负担。
但是它的缺点是我们需要批量修正之前所有的数据,因为之前的数据里没有来源这个字段。
当然你也可以不加这个字段,直接用 ID 区分,但是这是不符合规范的,而且必然会留下安全隐患。
第二个方案的优点是操作简单,不需要变更之前的数据,安全风险较小,但问题是需要占用新的资源,利用率低。
因为有些详情页的图片和顶部的图片是可以共用的,这样分开存储的话就需要存储多份。
这两个方案各有优缺点,似乎都还不错,但坑爹的是它们都有一个共同的缺点,就是都会增加目前系统和查询的复杂度。
一个是要增加查询时候传入的字段,一个是要发起额外的查询,不论选择哪一个,都会让系统越来越复杂。
到了后来,一个用户请求传来,会带动数十个联动请求,才能拼装出完整的数据。
现在最新版本的 X 宝的详情页商品介绍的部分一律用图片展示,没有了文字,也许背后就是受到这个问题的驱动。
我们回顾一下这个例子,为什么我们的查询会很复杂,其实就和数据库的核心理念有关。
关系型数据库存储的数据是关系,在这个问题当中,我们一个详情页的查询,需要查询商品和图片的关系,商品和说明的关系,商品和评论的关系,评论和图片的关系等等。
也就是说我们最终看到的页面,其实是这一系列关系拧在一起的结果,每一次查询的背后都是一个关系分解再合并的过程,因此会非常复杂。
文档型数据库
我们刚才看了关系型数据库在电商场景下的问题,我们再来看下文档型数据库在同样场景下的表现。
和关系型数据库不同,文档型数据库存储的核心是文档。当然这里的文档指的不是我们通常意义上的文档,而是 Json 或者是 XML 格式的数据。在目前的 NoSQL 数据库当中,Json 类型的数据更加常用一些。
我们还用刚才详情页的例子来看下在 NoSQL 数据库当中,这份数据是如何存储的:
- {
- "itemID": 123,
- "itemName": "iPad Pro",
- "topImgs": ["imgs1.path", "imgs2.path"],
- "desc": [{"text": "iPad Pro", "img": ""}, {"text": "2020 new version", "img": "imgs1.path"}],
- "comments": [{"userName": "chengzhi", "comment": "good product", "imgs": ["imgs3.path", "img4.path"]}]
- }
你看,在文档型数据库当中刚才复杂的、需要经过多次查询经过一系列处理才可以拧到一起的数据,我们通过 itemID 一次查询就可以获取到了。
单纯从使用上来说,它比关系型数据库要方便了许多,但是它也并不是没有缺点的。
这其中一个很大的问题是,我们把所有数据都直接存储在了文档当中,这一方面造成了数据的冗余,另一方面也限制了拓展性。
比如说,同一个商家下类似的商品不能共享图片,而必须存储多份,这造成了空间的浪费。
再比如,假设我们希望支持用户修改之前过去的评论会非常麻烦,因为我们必须要找到所有存储了用户评论的文档进行修改(假设在其他场景下也用到了用户评论),这往往是跨系统并且非常不方便的。
这个问题也并不是不可解的,比如我们可以把文档当中存储的具体数据换成一个 ID。
比如 Comment 当中不再存储具体的图片和评论信息,而存储一个评论的 ID,在使用的时候再去关联。
由于文档型数据库由于架构的原因,对于关联的支持并不好,往往需要我们手动根据 ID 再去查询来模拟连接,这也会带来额外的开销。
另外一个小瑕疵是在文档型数据库当中我们访问数据的路径变长了,举个例子,加入我们要获取商品评论当中的第二条中的第一张图片。
我们需要写成 item['comments'][1]['imgs'][0],而在关系型数据库当中,由于图片是通过关系直接查询得到的,因此要方便一些。
除了这些之外,NoSQL 数据库发展的年限和 MySQL 这些较成熟的关系型数据库相比要短得多,因此支持的特性相对比较少。
总结
通过一个例子,我们很生动地对比了关系型数据库和 NoSQL 数据库之间的差别。
为什么我们在学习数据库的时候需要先从 ER 图开始,而不是直接学习数据库的原理和它的使用方法呢?我想理解了上面的例子之后,再来看这个问题应该会简单许多。
因为关系型数据库的核心逻辑就是存储关系,使用规范、各种技巧和特性,本质上都是围绕这个核心展开的。
如果我们没有 Get 到这一层就来使用数据库很容易走偏,很多匪夷所思的操作就是这么来的。
比如有人在数据库当中存储前端页面的代码,比如把 ID 拼接成一个字符串来实现存储多个值等等。
这也说明了经典教材上的内容没有废话,每一个章节都有它预期的作用,因此当我们觉得某些内容没有用的时候,可能并不是教材错了,只是我们没有理解到位。
作者:梁唐
编辑:陶家龙
出处:转载自微信公众号 TechFlow(ID:techflow2019)










![[[324265]]](https://s1.51cto.com/oss/202004/28/c78257f8b72210e731072ba8d1170a49.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}