
这篇文章主要介绍Spark-Sql的示例分析,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
SparkSQL运行架构
Spark SQL对SQL语句的处理,首先会将SQL语句进行解析(Parse),然后形成一个Tree,在后续的如绑定、优化等处理过程都是对Tree的操作,而操作的方法是采用Rule,通过模式匹配,对不同类型的节点采用不同的操作。
spark-sql是用来处理结构化数据的模块,是入门spark的首要模块。
技术的学习无非就是去了解它的API,但是Spark有点难,因为它的例子和网上能搜到的基本都是Scala写的。我们这里使用Java。
入门例子
数据处理的第一个例子通常都是word count,就是统计一个文件里每个单词出现了几次。我们也来试一下。
> 这个例子网上有很多,即使是通过spark实现的也不少;这里面大部分都是使用Scala写的,我没有试过;少部分是通过Java写的;
Java里面的例子有一些是使用RDD实现的,只有极个别是通过DataSet来做的。但即使这一小撮例子,我也跑不通。
所以我自己来尝试完成这个例子,看到别人用Scala写三五行就完成了,而我尝试了一整天几无进展。在网上东拼西凑熟悉Spark的Java
还是以我们前面的例子来改:
String logFile = "words";
SparkSession spark = SparkSession.builder().appName("Simple Application").master("local").getOrCreate();
Dataset<String> logData = spark.read().textFile(logFile).cache();
System.out.println("行数:" + logData.count());这里我不再使用之前的README文件,自己创建了一个words文件,内容随意写了一堆单词。
执行程序,可以正常打印出来:

接下来我们需要把句子分割成一个个单词合在一起,然后统计每个单词出现的次数。
> 可能有人会说,这个简单,我用Java8的流一下就处理好了:
把行集合通过flatMap处理,每一行通过split(" ")分割成一个独立的单词集合,再把结果通过自身groupBy一下就拿到终止数据结构Map了。
最后把map的key和value的大小拿到就好了。
的确,使用Java就是这样实现。但是Spark提供了一套和Java的流API名字和效果类似的工具,区别是Spark的是分布式API
我们通过Spark的flatMap先来处理一下:
Dataset<String> words = logData.flatMap((FlatMapFunction<String, String>) k -> Arrays.asList(k.split("\\s")).iterator(), Encoders.STRING());System.out.println("单词数:" + words.count());words.foreach(k -> {System.out.println("W:" + k);});不同于Java的流,spark这个flatMap的返回值是可以直接访问结果的:
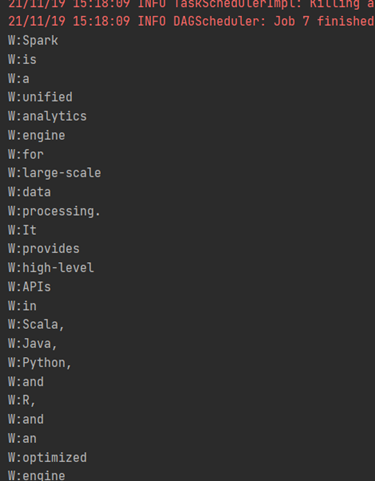
> 可能有人留意到spark中函数式方法的参数定义和Java差距较大。他们的参数不太一样,还多了个编码器。目前来讲我还不清楚为啥这样定义,不过印象中编码器也是spark3的重要优化内容。
再Java中使用Scala的方法总是有些怪异,Lambda表达式前面总是需要强制类型转换,只是为了指明参数类型,否则需要new一个匿名类。
这个也花了我不少时间,后来找到一个网页org.apache.spark.sql.Dataset.flatMap java code examples | Tabnine

再往后我迷茫了:
KeyValueGroupedDataset<String, String> group = words.groupByKey((Function1<String, String>) k -> k, Encoders.STRING());
这样我已经group好了,但是返回的不是DataSet,我也不知道这个返回有啥用,怎么拿到里面的内容呢?我费了好大劲没搞定。
比如我发现count方法会返回一个DataSet:
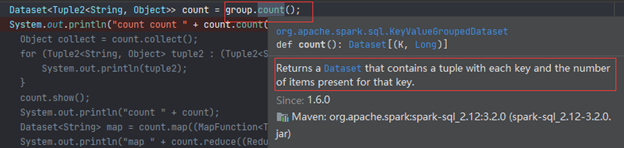
看起来正是我想要的,但是当我想把它输出竟然执行报错:
ount.foreach(t -> { System.out.println(t);});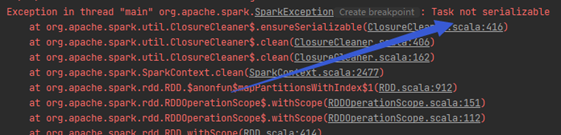
别说foreach了,就算想看看里面的数量(就像一开始我们查看了文件有几行那样)都会报错,错误内容一样
count.count();
查了很多资料,大意是说spark的计算方法都是分布式的,各个任务之间需要通信,通信时需要序列化来传递信息。所以上面我们能看文件行数因为类型是String,有序列化标志;现在生成的是元组,不能序列化。我尝试了各种方法,甚至自己创建新类模拟了计算过程还是不行
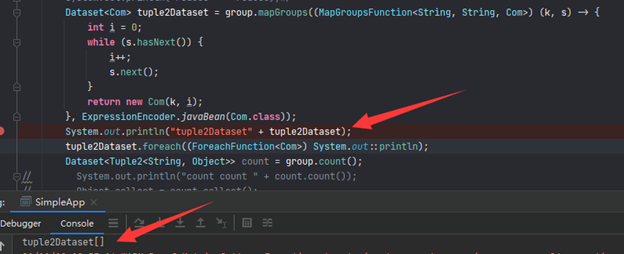
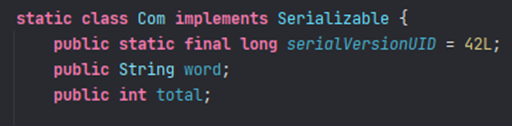
查了好久资料,比如Job aborted due to stage failure: Task not serializable: | Databricks Spark Knowledge Base (gitbooks.io)依然没有解决。偶然的机会找到一个令人激动的网站Spark Groupby Example with DataFrame — SparkByExamples终于解决了我的问题。
使用DataFrame
DataFrame虽然是spark提供的重要工具,但是再Java上并没有对应的类,只是把DataSet的泛型对象改成Row而已。注意这个Row没有泛型定义,所以里面有哪些列不知道
可以从一开始就把DataSet转成DataFrame:

但是可以看到要从Row里面拿数据比较麻烦。所以目前我只在需要序列化的地方转:

以上是“Spark-Sql的示例分析”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注编程网行业资讯频道!







