
前言
- 训练文本相似度数据集并进行评估:sentence-transformers(SBert)
- 预训练模型:chinese-roberta-wwm-ext
- 数据集:蚂蚁金融文本相似度数据集
- 前端:Vue2+elementui+axios
- 后端:flask
训练模型
- 创建网络:使用Sbert官方给出的预训练模型sentence_hfl_chinese-roberta-wwm-ext,先载入embedding层进行分词,再载入池化层并传入嵌入后的维度,对模型进行降维压缩,最后载入密集层,选择Than激活函数,输出维度大小为256维。
- 获取训练数据:构建出新模型后使用InputExample类存储训练数据,它接受文本对字符串列表和用于指示语义相似性的标签,用标准的Pytorch Dataloader包装train_examples,作用是打乱数据并生成特定大小的批次。
- 计算损失函数:对于每个句子对,通过网络传递句子A和句子B,从而产生嵌入u和v,使用余弦相似度计算相似性,并将结果与标准相似度得分进行比较。这样网络就能够进行微调,更好地识别句子的相似性。
- 模型调优:通过调用model.fit()来调优模型。向model.fit()中传递train_objective列表(由元组(dataloader, loss_function))组成。也可以传递多个元组,以便在具有不同损失函数的多个数据集上执行多任务学习。在训练过程需要使用sentence_transformers.evaluation评估表现是否有所改善,它包含各种可以传递给fit方法的evaluators。Evaluators会在训练期间定期运行,并且会返回分数,只有得分最高的模型才会存储在磁盘上。
首先运行preprocess.py获取数据,并划分训练集和测试集,之后运行train_sentence_bert.py,使用预训练模型, sbert将数据集用sbert训练相似度任务,得到训练好的模型,最后运行evaluate.py评估训练好的模型,将结果保存在predict.txt中,并输出预测结果。
这部分在详细代码里注释得很全。
后端部分
使用flask编写post接口,接收的数据格式为application/json,将前端传来的两个句子使用训练好的模型对其进行相似度预测,将得到的相似度类型从无法序列化存入json的tensor转成list,并将状态码,信息,数据返回给前端。
from sentence_transformers import SentenceTransformer, util# 后端接口from flask import Flask, jsonify, requestimport re# 用当前脚本名称实例化Flask对象,方便flask从该脚本文件中获取需要的内容app = Flask(__name__)# 使通过jsonify返回的中文显示正常,否则显示为ASCII码app.config["JSON_AS_ASCII"] = Falsemodel_path = 'D:/xxx模型路径/'model = SentenceTransformer(model_path)@app.route("/evaluate",methods=['POST'])def evalute_sentence(): s1 = request.json.get("s1") s2 = request.json.get("s2") if s1 and s2: embedding1 = model.encode(s1, convert_to_tensor=True) embedding2 = model.encode(s2, convert_to_tensor=True) similarity = util.cos_sim(embedding1, embedding2).tolist() return jsonify({"code": 200, "msg": "预测成功", "data": similarity}) else: return jsonify({"code": 400, "msg": "缺少字段"})if __name__ == '__main__': app.run(debug=True)前端部分
框架使用Vue2,UI框架使用elementui。组件校验用户输入的表单(内容为中文,字数限制32个字,两个句子不为空),只有符合规则的字段才能提交表单。将数据通过Axios调用接口传递给后端,再根据后端接口响应状态进行相应的处理,如果返回状态码200,说明接口调用成功,展示返回的预测值,否则调用失败,页面弹出失败消息提示。
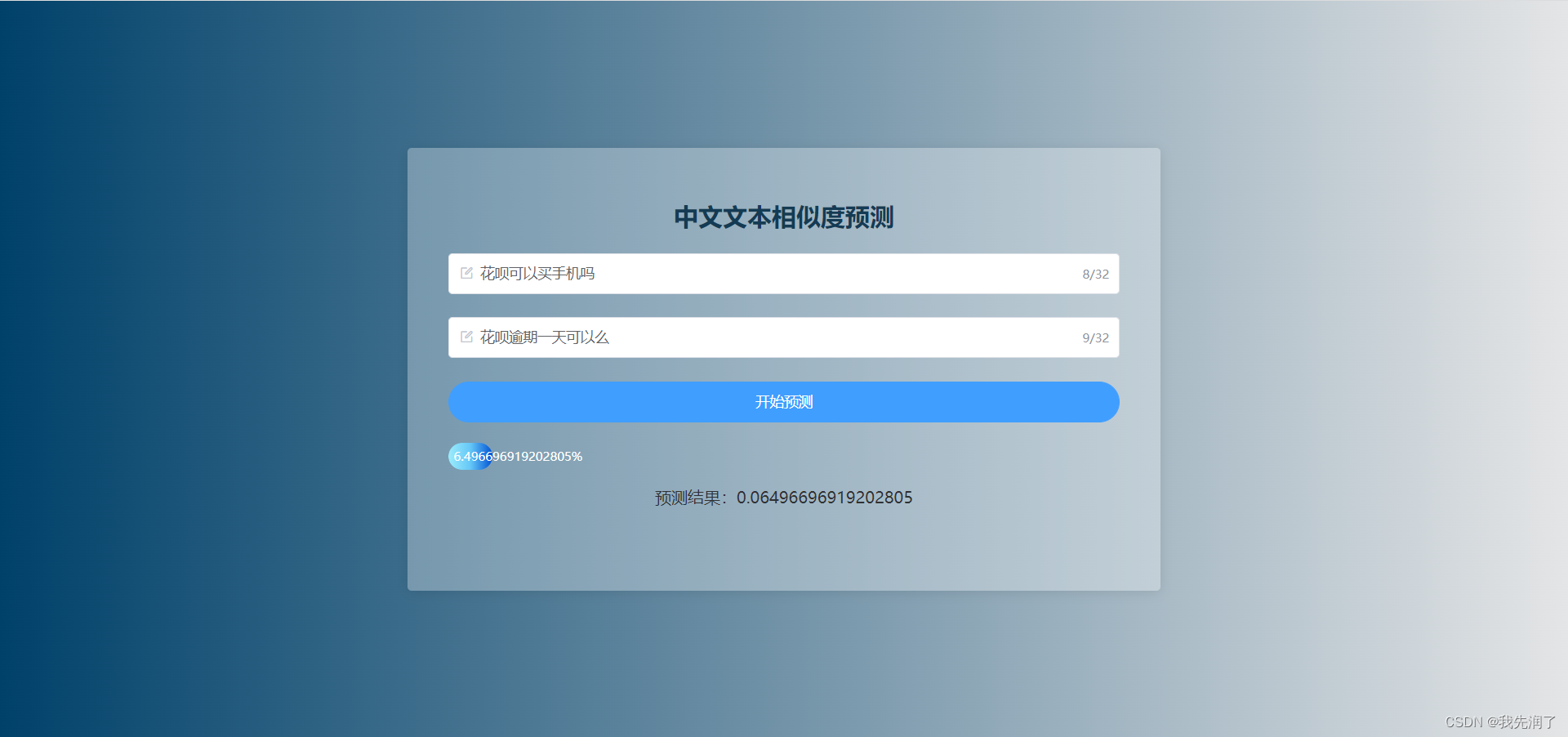
<template> <div class="recommend"> <el-card class="box"> <h2 class="title">中文文本相似度预测</h2> <el-form :model="evaluateForm" :rules="evaluateRules" ref="evaluateForm" class="form"> <el-form-item prop="s1"> <el-input placeholder="请输入句子一" maxlength="32" show-word-limit v-model="evaluateForm.s1" autocomplete="false" prefix-icon="el-icon-edit-outline" ></el-input> </el-form-item> <el-form-item prop="s2"> <el-input maxlength="32" placeholder="请输入句子二" v-model="evaluateForm.s2" show-word-limit autocomplete="false" prefix-icon="el-icon-edit-outline" ></el-input> </el-form-item> <el-form-item class="btn-container"> <el-button type="primary" @click="submitForm('evaluateForm')" class="btn" id="queryButton" >开始预测</el-button> </el-form-item> </el-form> <div v-show="result" style="margin-top: 20px"> <el-progress :text-inside="true" :stroke-width="26" :percentage="result*100 ? result*100 : 0" class="el-bg-inner-running" ></el-progress> <p>预测结果:{{result}}</p> </div> </el-card> </div></template><script>import api from "@/api/index"export default { data () { return { evaluateForm: { s1: "", s2: "" }, evaluateRules: { // 评估表单校验规则 s1: [ { required: true, message: '请输入中文句子', trigger: 'blur', pattern: /^[\u4E00-\u9FA5]+$/ }, ], s2: [ { required: true, message: '请输入中文句子', trigger: 'blur', pattern: /^[\u4E00-\u9FA5]+$/ }, ], }, result: undefined, } }, methods: { postEvaluate () { // 调用接口 api.postEvaluate(this.evaluateForm) .then((res) => { if (!res) { return } console.log("res", res) if (res.data.code !== 200) { this.$message({ message: "请求失败", type: "error" }) return } let data = res.data.data[0] this.result = data[0] console.log("this.result", this.result) this.$message({ message: "预测成功!", type: "success" }) }) .catch((error) => { this.$message.error('资源获取错误!') }) }, submitForm (formName) { // 提交表单 this.$refs[formName].validate((valid) => { if (valid) { this.postEvaluate() } else { this.$message({ message: "请按要求填写", type: "warning" }) console.log('error in submit form') return false } }) document.getElementById("queryButton").blur() }, }}</script><style lang="scss" scoped>.recommend { width: 100%; height: 100%; text-align: center; display: flex; text-align: center; flex-direction: column; align-items: center; justify-content: center; overflow: hidden; background: #00416a 0 / cover fixed; background: -webkit-linear-gradient( to right, #00416a, #e4e5e6 ); background: linear-gradient( to right, #00416a, #e4e5e6 ); .box { width: 48%; height: 60%; position: relative; background: hsla(0, 0%, 100%, 0.3); z-index: 5; padding: 10px 20px; // display: flex; // flex-direction: column; // justify-content: center; box-sizing: border-box; &::before { content: ''; position: absolute; top: 0; right: 0; bottom: 0; left: 0; filter: blur(20px); } .title { color: #143b54; } .btn-container { margin: 10px auto; .btn { width: 100%; border-radius: 20px; } } }}::v-deep .el-card { border: 0; box-shadow: 0 5px 16px 0 rgb(0 0 0 / 30%);}::v-deep .el-progress-bar__outer { border: 0; background-color: transparent; // background-color: #abcbe0;}::v-deep .el-bg-inner-running .el-progress-bar__inner { background: #9cecfb; background: -webkit-linear-gradient( to left, #0052d4, #65c7f7, #9cecfb ); background: linear-gradient( to left, #0052d4, #65c7f7, #9cecfb ); }</style>预训练模型比较
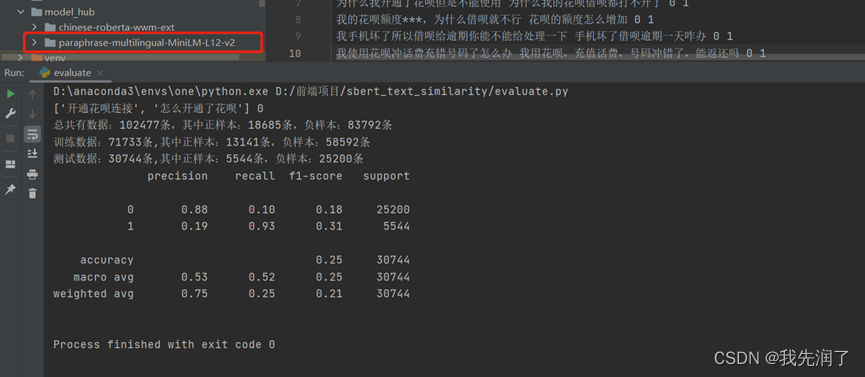
paraphrase-multilingual-MiniLM-L12-v2
参数设置:epochs=1,batch_size=16
特点:作为sbert官方多语言预训练模型,已带有BERT层和池化层,可直接用数据评估,但未经纯中文文本训练,准确率较低
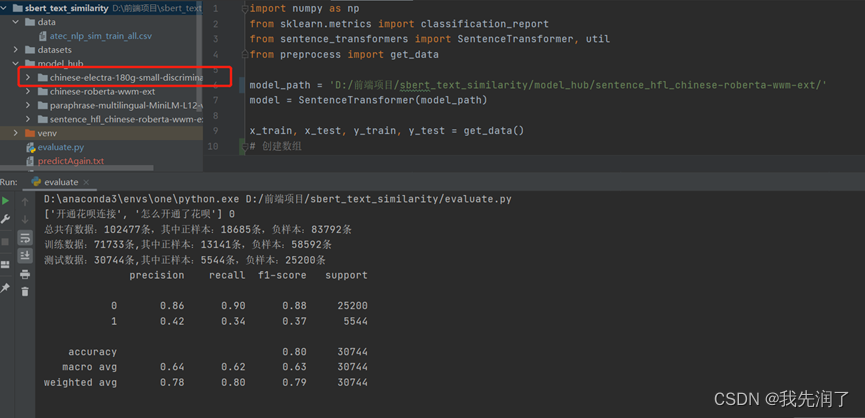
chinese-electra-180g-small-discriminator
参数设置:epochs=1, batch_size=16
特点:运行时间快,准确率尚可
chinese-electra-180g-small-discriminator
参数设置:epochs=20, batch_size=16
特点:20次迭代比1次迭代有效果,但差别不大
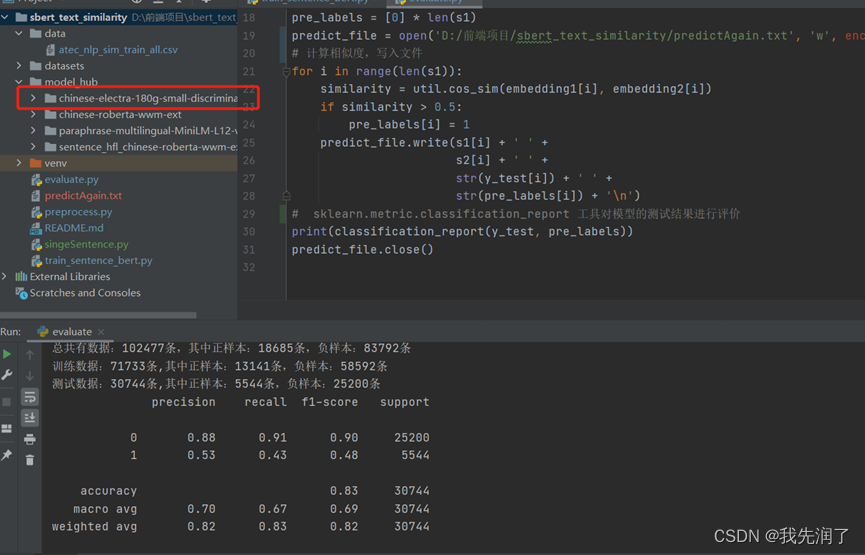
chinese-electra-180g-small-discriminator
参数设置:epochs=1,batch_size=8
特点:比batch_size=16时效果更好
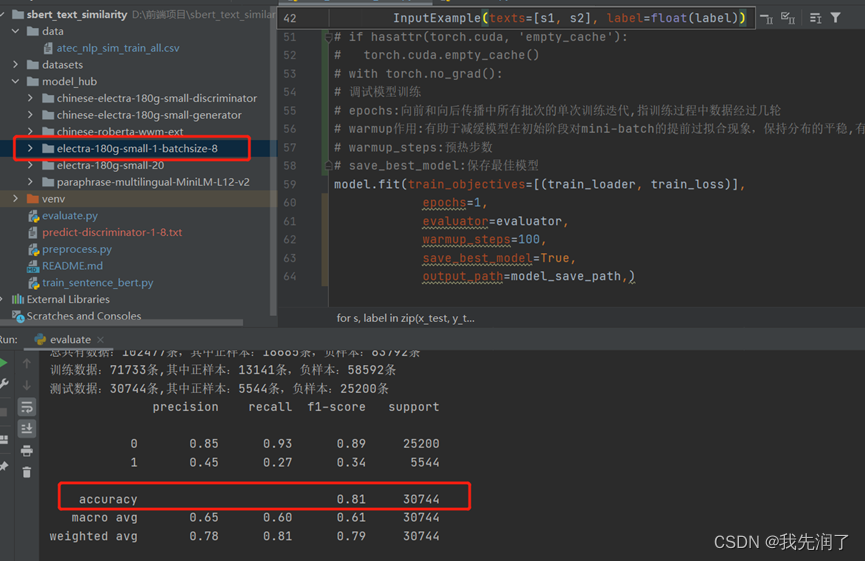
chinese-roberta-wwm-ext
参数设置:epochs=1,batch_size=8
特点:迭代1次和20次准确率无差别,稳定且效果在所有模型中最好,缺点是体积大运行速度慢
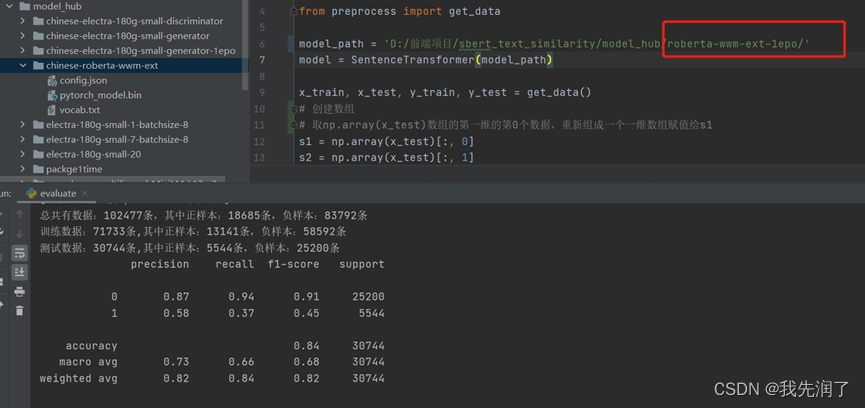
最后
代码已上传至sbert中文文本相似度预测,欢迎star!
来源地址:https://blog.csdn.net/weixin_54218079/article/details/128687878







