
这里博主给大家封装好了一个工具类,里面有两个方法。
- 方法一:可以根据指定字段去除重复数据。
- 方法二:可以获取到重复的数据。
大家在使用过程中直接拷贝下方代码在要去重的类中调用即可。
package com.jzmy.specialist.entity.util;import java.util.Map;import java.util.concurrent.ConcurrentHashMap;import java.util.function.Function;import java.util.function.Predicate;public class DeduplicationUtil { public static <T> Predicate<T> distinctByKey(Function<? super T, ?> keyExtractor) { Map<Object,Boolean> seen = new ConcurrentHashMap<>(); return t -> seen.putIfAbsent(keyExtractor.apply(t), Boolean.TRUE) == null; } public static <T> Predicate<T> distinctNotByKey(Function<? super T, ?> keyExtractor) { Map<Object,Boolean> seen = new ConcurrentHashMap<>(); return t -> seen.putIfAbsent(keyExtractor.apply(t), Boolean.TRUE) != null; }}导入这个工具类后怎么使用呢?我们接着往下看。
方法一根据指定字段去重
package com.jzmy.specialist.entity.util;import java.util.ArrayList;import java.util.List;import java.util.stream.Collectors;public class Test { public static class Student{ private String id; private String name; public String getId() { return id; } public void setId(String id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } } public static void main(String[] args) { List<Student> list =new ArrayList<>(); Student student =new Student(); student.setId("1"); student.setName("张三"); list.add(student); Student student2 =new Student(); student2.setId("1"); student2.setName("张三"); list.add(student2); Student student3 =new Student(); student3.setId("1"); student3.setName("李四"); list.add(student3); Student student4 =new Student(); student4.setId("2"); student4.setName("王五"); list.add(student4); System.out.println("未去重前list有几条数据:"+list.size()); List<Student> rstList = list.stream().filter(DeduplicationUtil.distinctByKey(Student::getId)).collect(Collectors.toList()); System.out.println("未去重前list有几条数据:"+rstList.size()); }}List rstList = list.stream().filter(DeduplicationUtil.distinctByKey(Student::getId)).collect(Collectors.toList());
- 这段代码的意思是通过stream的filter方法进行过滤,过滤Id不相同的数据并通过collect方法收集为一个新的集合。
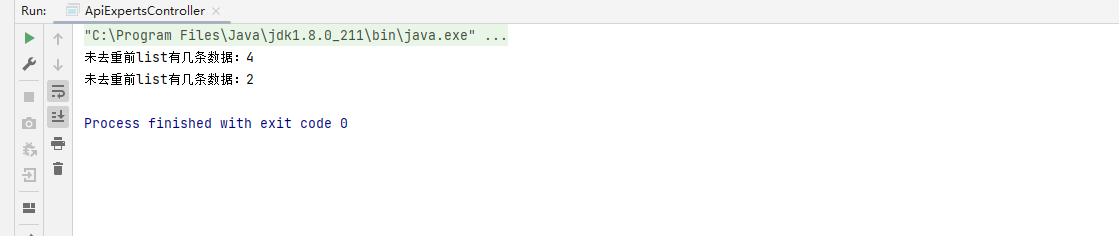
代码运行结果
方法二获取重复数据
package com.jzmy.specialist.entity.util;import java.util.ArrayList;import java.util.List;import java.util.stream.Collectors;public class Test { public static class Student{ private String id; private String name; public String getId() { return id; } public void setId(String id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } } public static void main(String[] args) { List<Student> list =new ArrayList<>(); Student student =new Student(); student.setId("1"); student.setName("张三"); list.add(student); Student student2 =new Student(); student2.setId("1"); student2.setName("张三"); list.add(student2); Student student3 =new Student(); student3.setId("1"); student3.setName("李四"); list.add(student3); Student student4 =new Student(); student4.setId("2"); student4.setName("王五"); list.add(student4); System.out.println("集合中的全部数据"); for (int i=0;i<list.size();i++){ System.out.println(list.get(i).getId()); System.out.println(list.get(i).getName()); } List<Student> rstList = list.stream().filter(DeduplicationUtil.distinctNotByKey(Student::getId)).collect(Collectors.toList()); System.out.println("集合中的重复数据"); for (int i=0;i<rstList.size();i++){ System.out.println(rstList.get(i).getId()); System.out.println(rstList.get(i).getName()); } }}List rstList = list.stream().filter(DeduplicationUtil.distinctNotByKey(Student::getId)).collect(Collectors.toList());
- 这个和上面那个方法原理一样的只是换了一个调用方法而已。
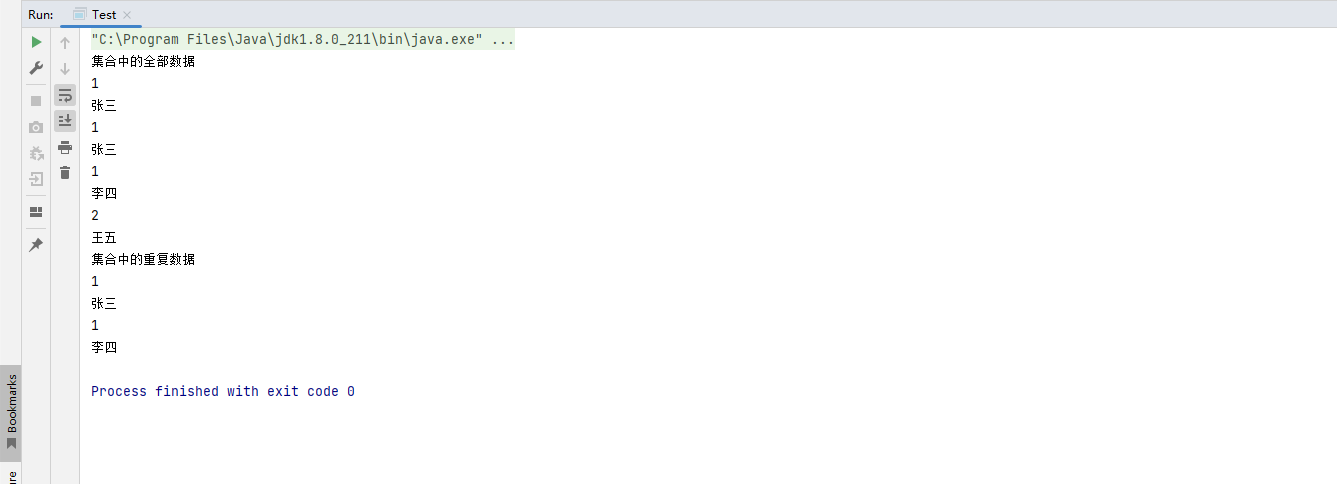
代码运行结果
来源地址:https://blog.csdn.net/weixin_45692705/article/details/128144013







