
1.canal的应用场景
目前普遍基于日志增量订阅和消费的业务,主要包括
- 基于数据库增量日志解析,提供增量数据订阅和消费
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
2.canal的工作原理
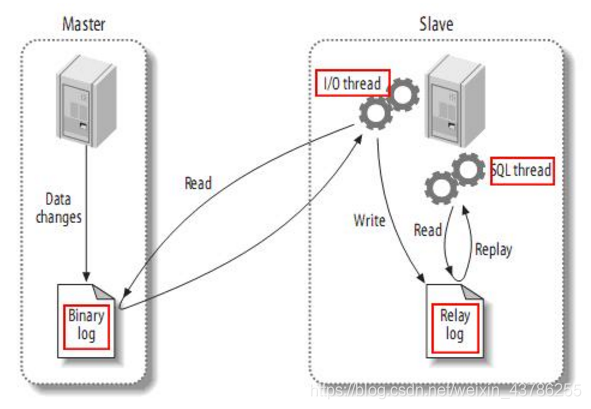
首先了解一下mysql主备复制原理:
(1)master主库将改变记录,发送到二进制文件(binary log)中
(2)slave从库向mysql Master发送dump协议,将master主库的binary log events拷贝到它的中继日志(relay log)
(3)slave从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库
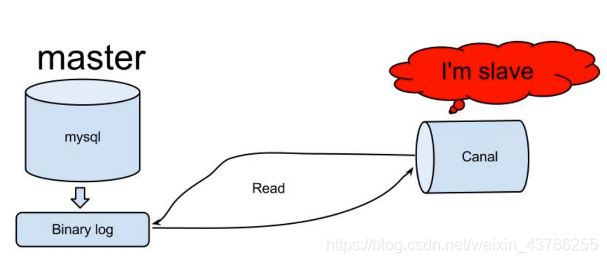
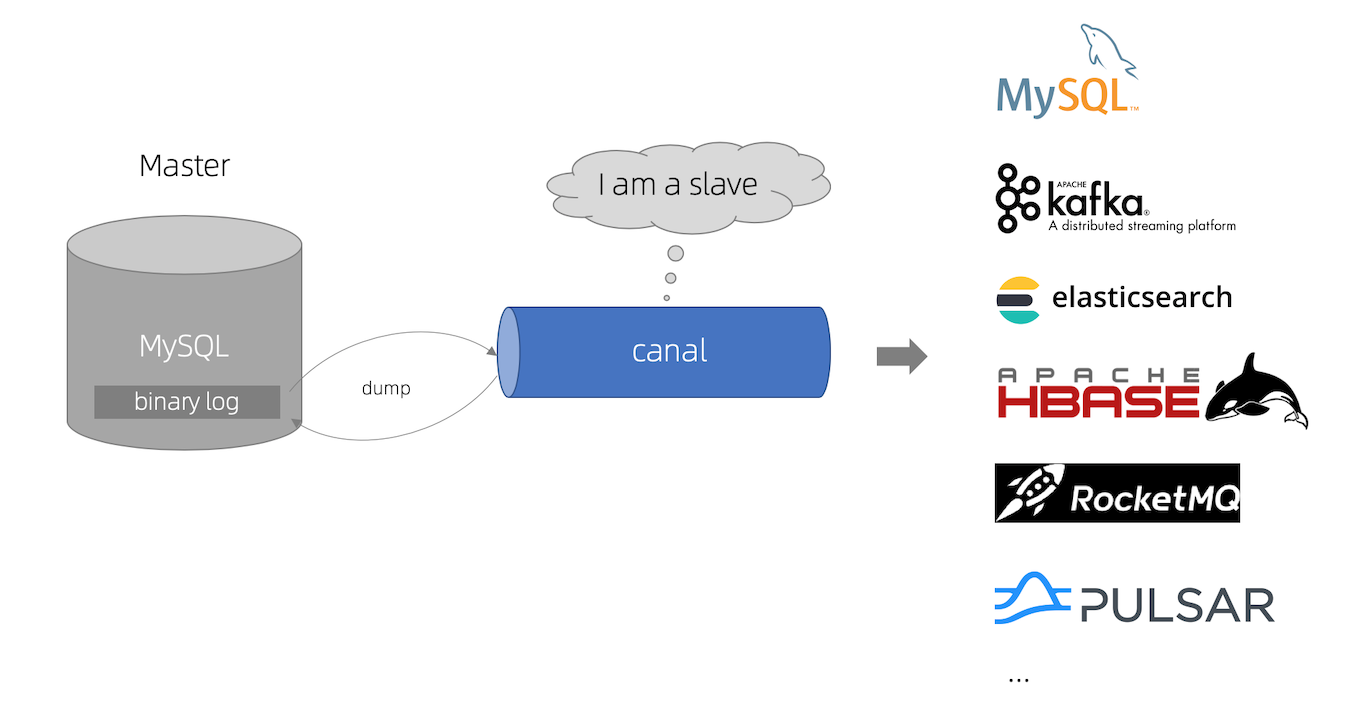
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送
binary log给 slave (也就是 canal ) - canal 解析
binary log对象(数据为byte流)
基于这样的原理与方式,便可以完成数据库增量日志的获取解析,提供增量数据订阅和消费,实现mysql实时增量数据传输的功能。
3.Canal服务端的搭建
canal官网下载地址:https://github.com/alibaba/canal
canal 官方开源github地址: canal ;下载地址:
canal 官方文档github地址:canal document
3.1启动MySQL的Binlog功能
查看是否开启Binlog功能
show variables like 'log_bin%'; #log_bin ON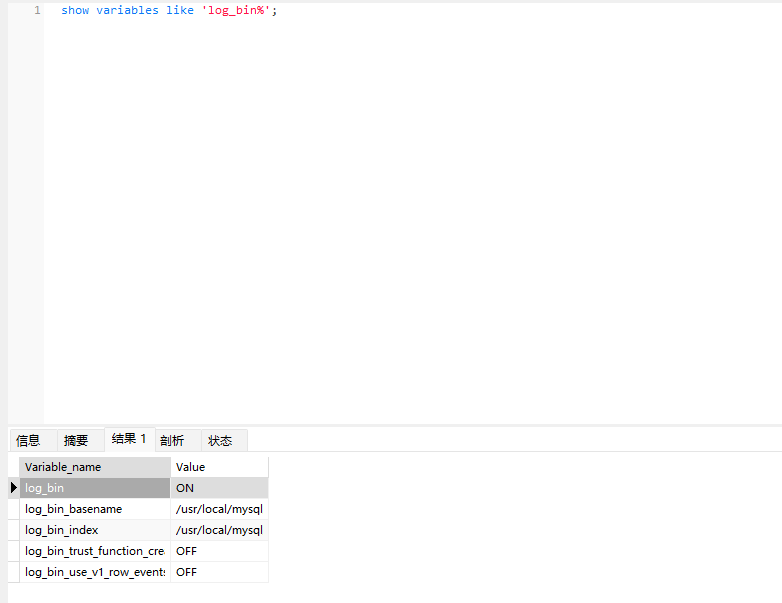
如果未开启则先开启mysql的Binlog写入功能,配置 binlog-format 为ROW模式,故须使用如下命令修改mysql的my.cnf中配置
vi /etc/my.cnf在my.cnf配置中加入以下配置
[mysqld]log-bin=mysql-bin # 开启 binlogbinlog-format=ROW # 选择 ROW 模式server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复log-bin用于指定binlog日志文件名前缀,默认存储在/var/lib/mysql 目录下。
server-id用于标识唯一的数据库,不能和别的服务器重复,建议使用ip的最后一段,默认值也不可以。
binlog-ignore-db:表示同步的时候忽略的数据库。
binlog-do-db:指定需要同步的数据库(如果没有此项,表示同步所有的库)
添加配置并保存后,使用如下命令重启mysql服务
service mysql restart3.2canal下载以及安装
下载 canal, 访问 release 页面 , 选择需要的包下载, 如以 1.1.6 版本为例
wget https://github.com/alibaba/canal/releases/download/canal-1.1.6/canal.deployer-1.1.6.tar.gz或者直接选择文件下载
创建canal文件夹
cd /usr/locallsmkdir canal使用如下命令给文件夹授权
//给local赋予读写权限chmod 777 canal//给local及其以下子目录赋予读写权限chmod -R 777 canal将canal压缩包放在canal目录下,解压下载好的canal压缩包
tar -zxvf canal.deployer-1.1.6-SNAPSHOT.tar.gz修改配置文件 cd conf/
vi canal.properties
canal 搭配 rabbitmq 配置文件的修改
########################################################## common argument############################################################### tcp, kafka, rocketMQ, rabbitMQ, pulsarMQcanal.serverMode = rabbitMQ // 选择方式为rabbitmq########################################################### RabbitMQ ###############################################################rabbitmq.host =127.0.0.1rabbitmq.virtual.host =/rabbitmq.exchange =canal.topic // 定义交换机rabbitmq.username =user //用户名rabbitmq.password =user //密码rabbitmq.deliveryMode =canal 搭配 kafka配置文件的修改
########################################################## common argument############################################################### tcp, kafka, rocketMQ, rabbitMQ, pulsarMQcanal.serverMode = kafka // 选择方式为rabbitmq########################################################### Kafka ###############################################################kafka.bootstrap.servers = 127.0.0.1:9092kafka.acks = allkafka.compression.type = nonekafka.batch.size = 16384kafka.linger.ms = 1kafka.max.request.size = 1048576kafka.buffer.memory = 33554432kafka.max.in.flight.requests.per.connection = 1kafka.retries = 0kafka.kerberos.enable = falsekafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf"kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf"cd /usr/local/canal/deployer/conf/example 下配置instance.properties
修改instance.properties 的文件配置
canal 搭配 rabbitmq 配置文件的修改
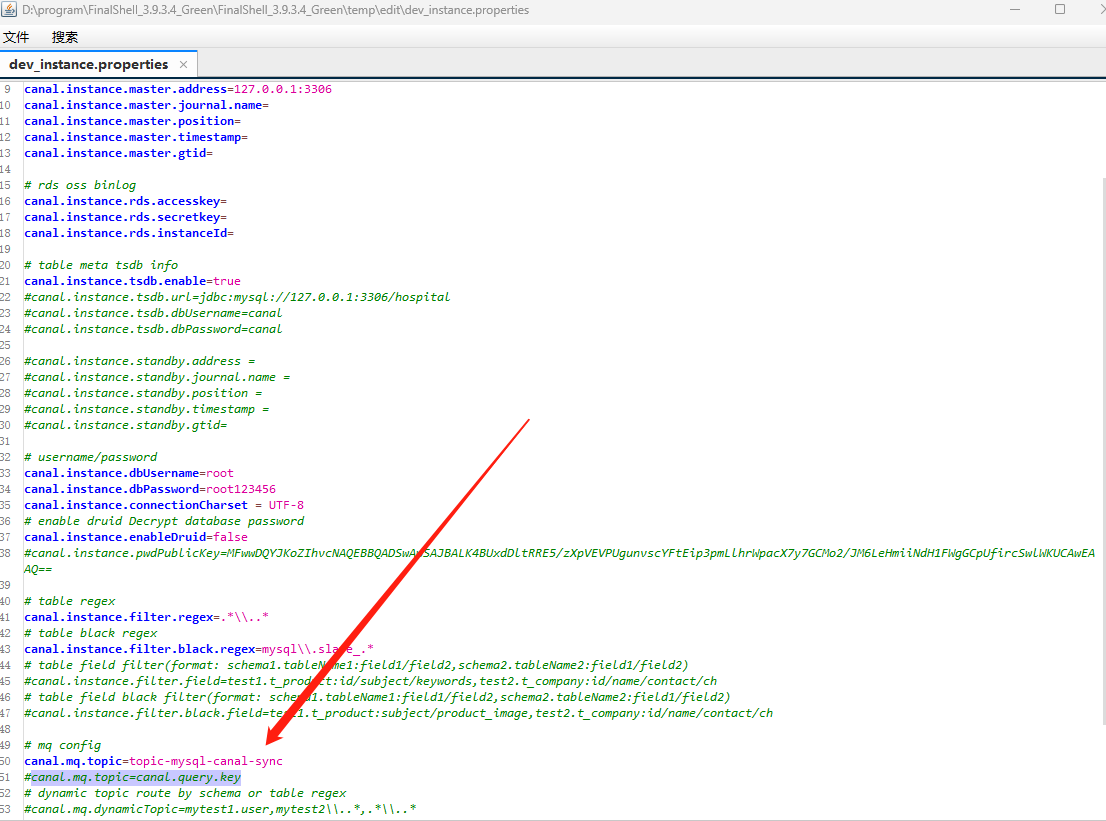
#主要修改连接数据库的用户名与密码 与相应的mq key# username/passwordcanal.instance.dbUsername=rootcanal.instance.dbPassword=root123456# mq config#canal.mq.topic=topic-mysql-canal-synccanal.mq.topic=canal.query.key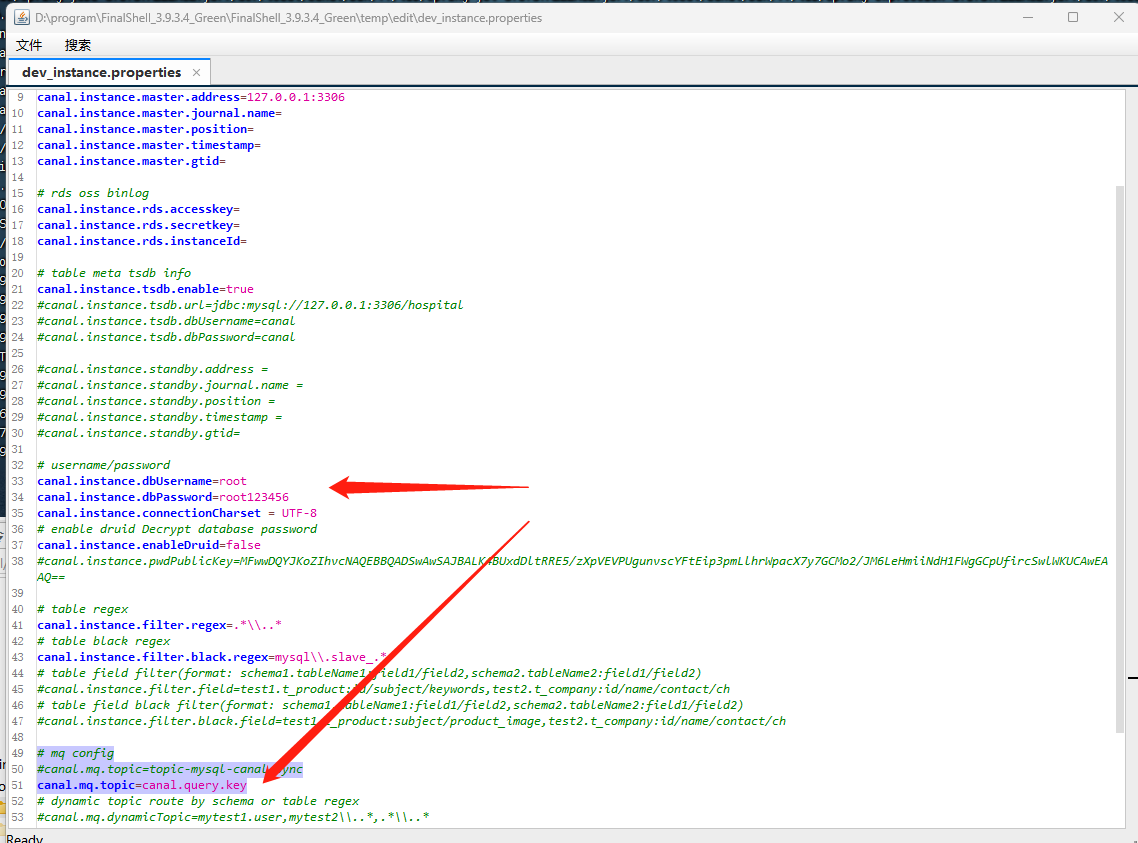
canal 搭配 kafka 配置文件的修改
更换定义好的topic
cd到bin目录下使用如下命令启动canal
./startup.sh 或者sh startup.sh // 停止sh stop.sh启动后,使用命令查看是否启动
ps -ef | grep canal或
观察canal日志:tail -n 50 /usr/local/canal/logs/canal/canal.log没有错误则表示启动正常至此,canal启动成功
3.3canal搭配rabbitmq监听Binlog日志
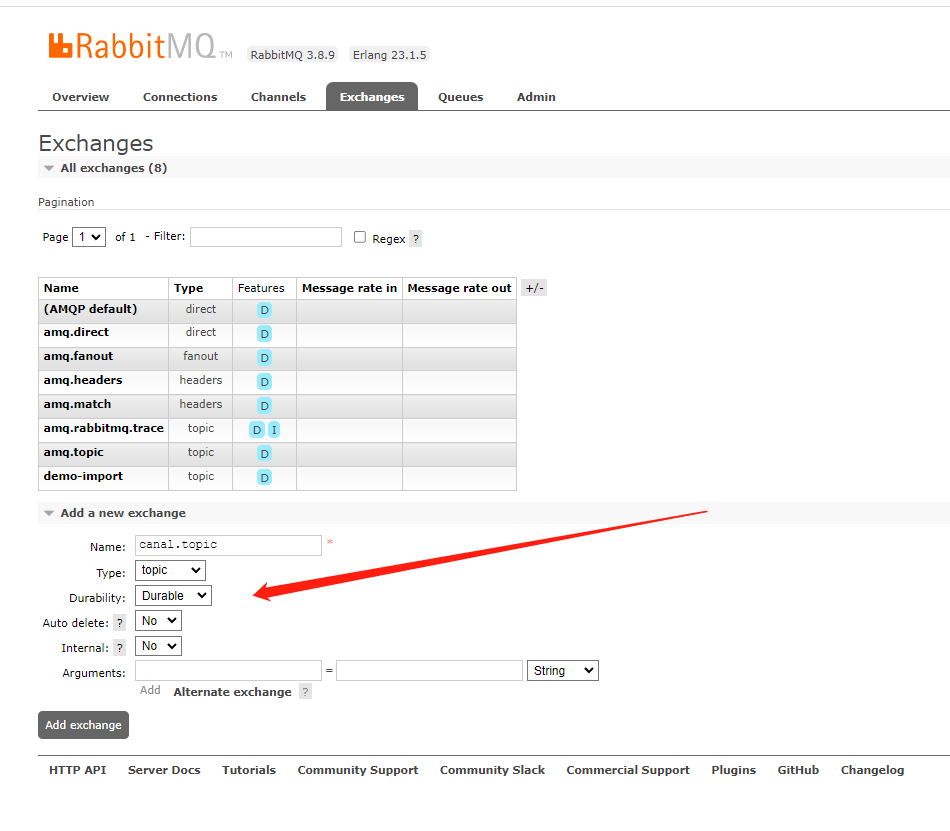
新建主题类型canal.topic交换机
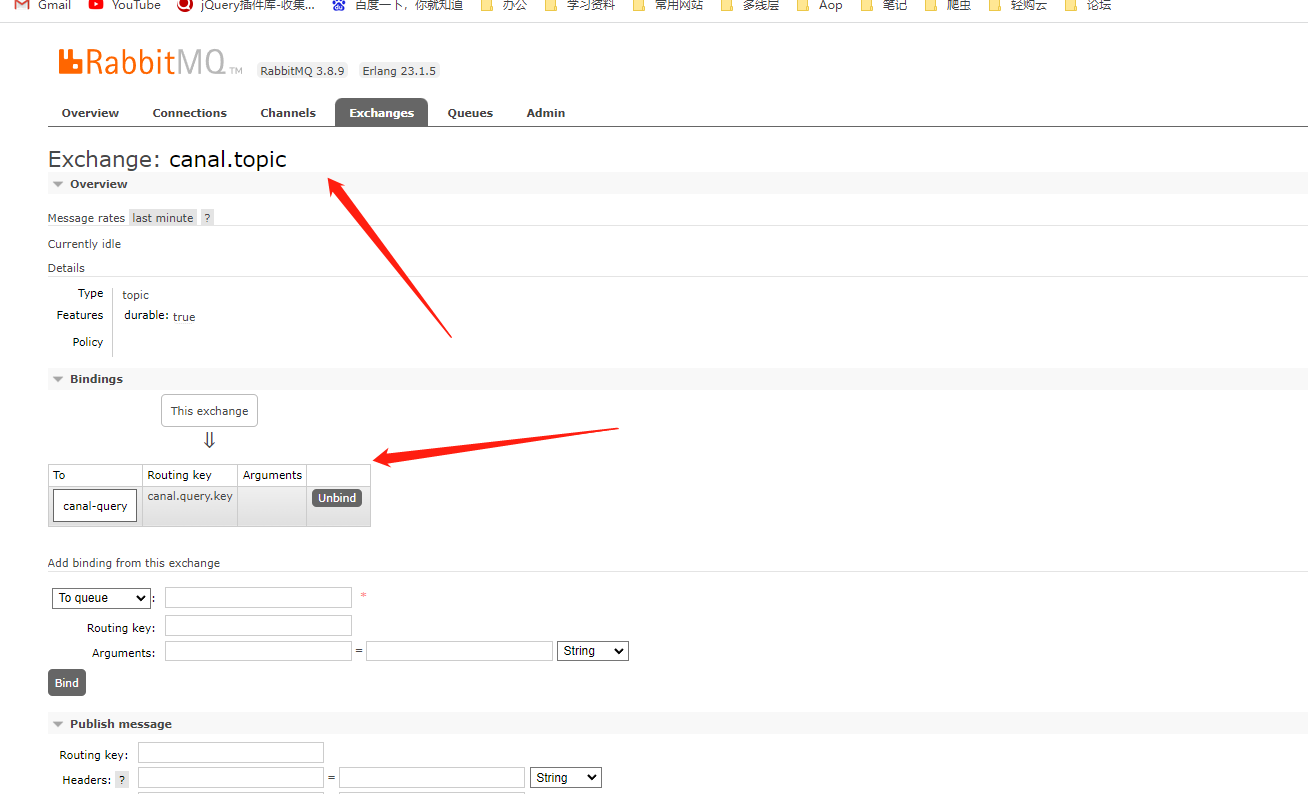
新建canal-query队列,并且通过canal.query.key 绑定 canal.topic交换机上
数据测试:
// 批量修改表中数据UPDATE department SET department_name = "哈哈哈哈" where department_id in (21, 22)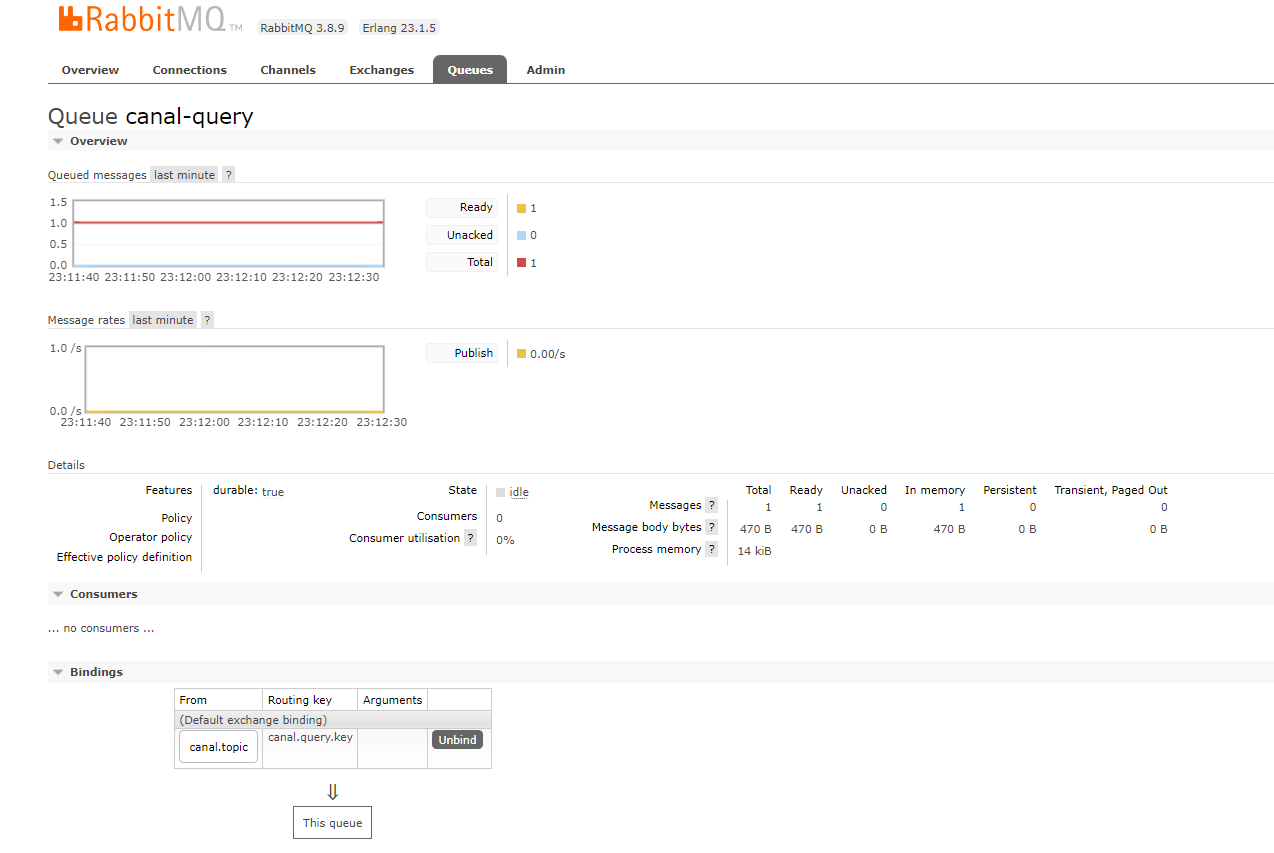
查看队列即已有数据,数据格式如下
{ "data": [ { "department_id": "21", "department_name": "哈哈哈哈" }, { "department_id": "22", "department_name": "哈哈哈哈" } ], "database": "hospital", "es": 1677165050000, "id": 2, "isDdl": false, "mysqlType": { "department_id": "bigint", "department_name": "varchar(255)" }, "old": [ { "department_name": "测试部门" }, { "department_name": "SSh" } ], "pkNames": [ "department_id" ], "sql": "", "sqlType": { "department_id": -5, "department_name": 12 }, "table": "department", "ts": 1677165050763, "type": "UPDATE"}3.4.canal搭配kafka监听Binlog日志
创建topic-mysql-canal-sync topic 主题
// 批量修改表中数据UPDATE department SET department_name = "他他他" where department_id in (21, 22)定义消费者可以查看测试消息
@Componentpublic class CanalTableRecive { @KafkaListener(topics = "topic-mysql-canal-sync") public void execute1(ConsumerRecord record) { receive(record); } private void receive(ConsumerRecord record) { StringBuilder sb = new StringBuilder("\n"); sb.append("topic: ").append(record.topic()).append("\n"); sb.append("key : ").append(record.key()).append("\n"); sb.append("value: ").append(record.value().toString()).append("\n"); System.out.println("分区:" + record.partition() + "\t接收到数据的code:" + sb);// System.out.println(sb); }}
4.项目搭建canal同步服务处理
服务处理架构设计如下
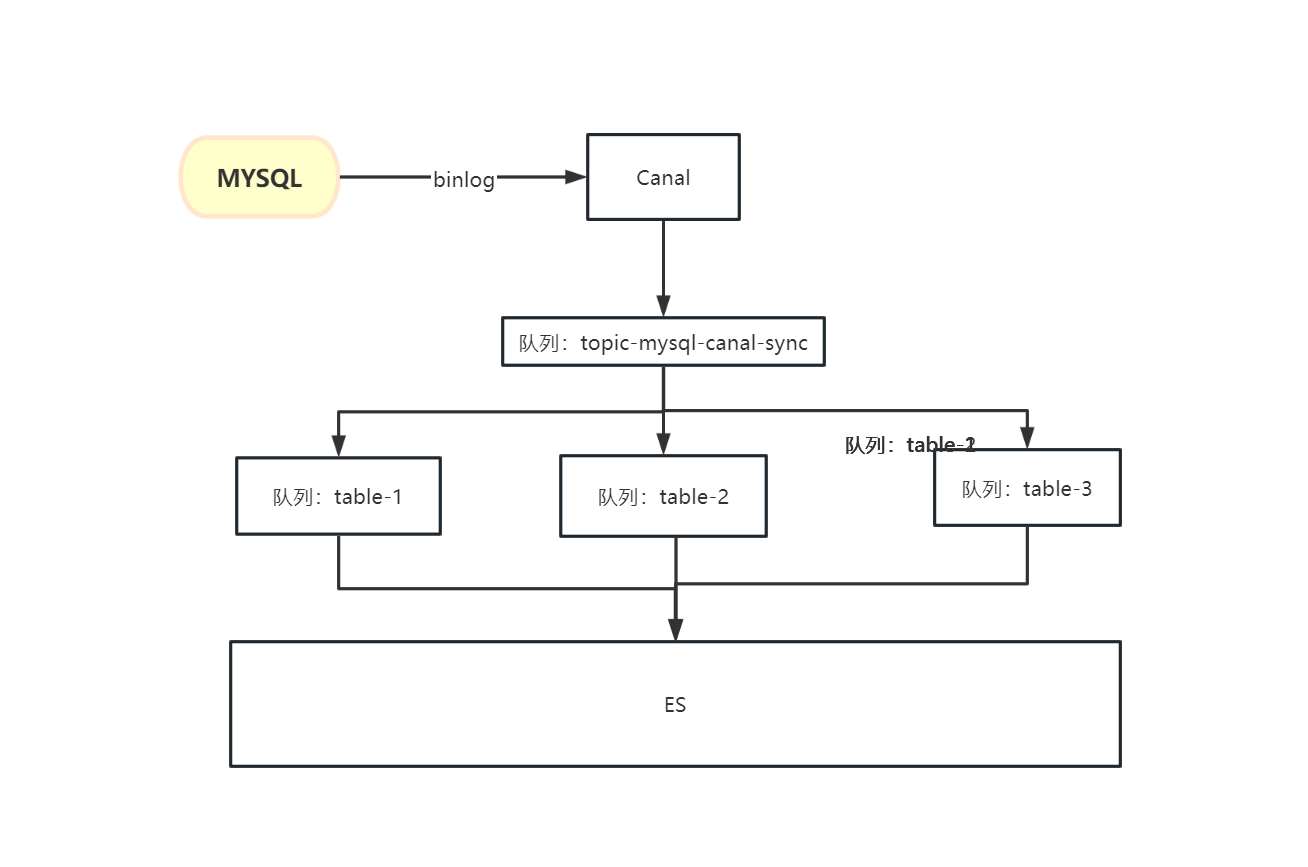
在表的binlog日志往topic-mysql-canal-sync队列投递时,考虑到此队列可能会存在堆积问题,以及每张表存在不同数据同步策略、以及后期会存在历史数据同步、或全量同步等,根据不同的表名获取不同的策略类,往不同队列投递,进行分流数据同步写入。
项目目录结构如下:
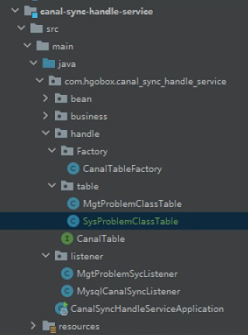
采用工厂模式+策略模式实现对于不同表不同策略处理
topic-mysql-canal-sync 消费者处理
@Slf4j@Componentpublic class MysqlCanalSyncListener { public static final String TABLE_NAME = "table"; public static final String DATA = "data"; @KafkaListener(topics = "topic-mysql-canal-sync") public void execute(ConsumerRecord record, Acknowledgment ack) { StringBuilder sb = new StringBuilder("\n"); sb.append("topic: ").append(record.topic()).append("\n"); sb.append("key : ").append(record.key()).append("\n"); sb.append("value: ").append(record.value().toString()).append("\n"); log.info(sb.toString()); try { JSONObject jsonObject = JSON.parseObject(record.value().toString()); String table = jsonObject.getString(TABLE_NAME); JSONArray data = jsonObject.getJSONArray(DATA); for (Object obj : data) { CanalTable canalTable = CanalTableFactory.get(table); canalTable.handle((JSONObject) obj); } } catch (Exception e) { log.error(e.getMessage()); } finally { ack.acknowledge(); } }}定义table处理接口
public interface CanalTable { void handle(JSONObject object) throws Exception;}canal table 工厂
public class CanalTableFactory { public static CanalTable get(String tableName) { CanalTable bean = SpringUtils.getBean(tableName); if (bean == null) { throw new BusinessException(tableName + "未获取到对应的CanalTable"); } return bean; }}已表名注册bean,利用springioc 容器 getBean 拿到相应的策略实现类
不同表策略类
@Service(CanalTableConstant.MGT_PROBLEM)public class MgtProblemClassTable implements CanalTable { @Resource private KafkaTemplate kafkaTemplate; // 表名id public static final String ID = "id"; @Override public void handle(JSONObject object) { String id = object.getString(ID); CanalTableRequest canalTableRequest = CanalTableRequest.builder().id(Long.valueOf(id)).build(); kafkaTemplate.send("mgt_problem_class_sync", id, JSON.toJSONString(canalTableRequest)); }} @Service(CanalTableConstant.SYS_PROBLEM)public class SysProblemClassTable implements CanalTable { @Resource private KafkaTemplate kafkaTemplate; // 表名id public static final String ID = "id"; @Override public void handle(JSONObject object) { String id = object.getString(ID); CanalTableRequest canalTableRequest = CanalTableRequest.builder().id(Long.valueOf(id)).build(); kafkaTemplate.send("sys_problem_class_sync", id, JSON.toJSONString(canalTableRequest)); }} 5.canal搭配kafka解决canal写入kafka并发消费问题
5.1问题描述
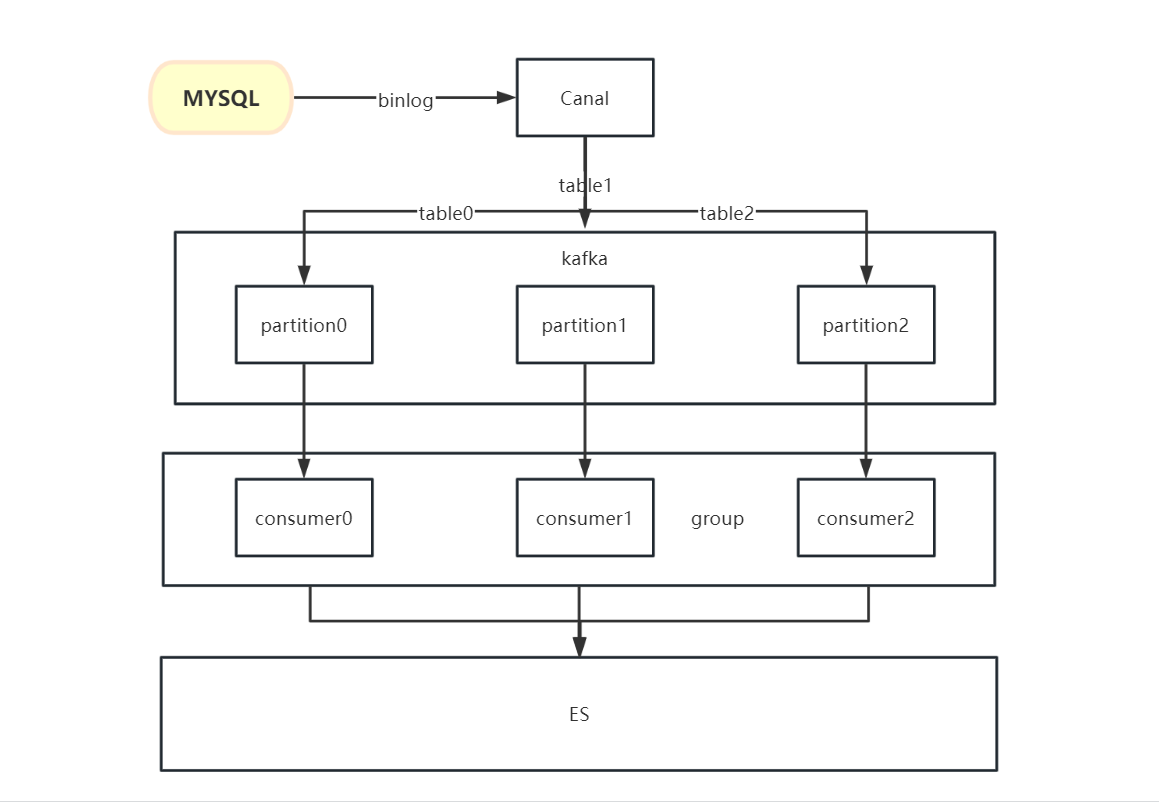
消息写入kafka,但方式上依然是在一条一条的消费消息,性能并未得到提升。如何解决这样的问题?首先肯定想到的是多线程并发消费,如果我们单纯地用多线程并发消费的话并不能保证消息的有序性,这种binlog日志同步是需要严格有序性的,否则会导致数据错乱。那有没有办法能够保证顺序的情况下并发消费呢?参考网上的资料,了解到了指定分区消费,即将指定数据发送到指定分区当中,然后起多个消费者消费不同分区的数据即可,并且Canal提供写入指定分区的配置。
5.2方案处理
5.2.1修改canal配置文件
# mq configcanal.mq.topic=topic-mysql-canal-synccanal.mq.partitionsNum=3canal.mq.partitionHash=.\..*这里面主要配置了canal.mq.partitionsNum和canal.mq.partitionHash两个参数,他们的意思如下:
canal.mq.partitionsNum:指定当前topic的分区数
canal.mq.partitionHash:指定到分区的分区规则,可以细化到字段
目前的构想是想根据不同的表名去hash,散列到不同的分区
5.2.2修改项目代码
原先项目中只有一个消费,现在再添加两个消费的方法,让三个消费者能够消费不同分区的数据,通过@TopicPartition注解指定topic和对应的分区,并且可以同时消费多个分区的数据,三个消费者的groupId一定要保持一致,因为Kafka指定在一个group里面一条partition的消息只能被一个消费者消费
@Componentpublic class CanalTableRecive { @KafkaListener(topicPartitions = {@TopicPartition(topic = "topic-mysql-canal-sync", partitions = {"0"})}) public void execute1(ConsumerRecord record) { receive(record); } @KafkaListener(topicPartitions = {@TopicPartition(topic = "topic-mysql-canal-sync", partitions = {"1"})}) public void execute2(ConsumerRecord record) { receive(record); } @KafkaListener(topicPartitions = {@TopicPartition(topic = "topic-mysql-canal-sync", partitions = {"2"})}) public void execute3(ConsumerRecord record) { receive(record); } private void receive(ConsumerRecord record) { StringBuilder sb = new StringBuilder("\n"); sb.append("topic: ").append(record.topic()).append("\n"); sb.append("key : ").append(record.key()).append("\n"); sb.append("value: ").append(record.value().toString()).append("\n"); System.out.println("分区:" + record.partition() + "\t接收到数据的code:" + sb);// System.out.println(sb); }}5.2.3数据测试
//修改department表UPDATE department SET department_name = "他他" where department_id in (21, 22)打印数据可以得知 department 表的数据落在 分区2 上

//修改test表UPDATE test SET age = 17 where id = 4打印数据可以得知 test 表的数据落在 分区1 上

//修改user表update user set gender = "男" where user_id = 1打印数据可以得知 user 表的数据落在 分区0 上

通过这样的方式我们可以确保相同表的数据到同一个分区被同一个消费者有序消费且只消费一次,这样即可达到目的
5.3整体架构图
5.4参考
Canal官方文档提供的相关配置
canal.mq.partitionHash 表达式说明:
canal 1.1.3版本之后, 支持配置格式:schema.table:pk1^pk2,多个配置之间使用逗号分隔例子1:test\.test:pk1^pk2 指定匹配的单表,对应的hash字段为pk1 + pk2例子2:.\…:id 正则匹配,指定所有正则匹配的表对应的hash字段为id例子3:.\…:p k pkpk 正则匹配,指定所有正则匹配的表对应的hash字段为表主键(自动查找)例子4: 匹配规则啥都不写,则默认发到0这个partition上例子5:.\… ,不指定pk信息的正则匹配,将所有正则匹配的表,对应的hash字段为表名按表hash: 一张表的所有数据可以发到同一个分区,不同表之间会做散列 (会有热点表分区过大问题)例子6: test\.test:id,.\…* , 针对test的表按照id散列,其余的表按照table散列注意:大家可以结合自己的业务需求,设置匹配规则,多条匹配规则之间是按照顺序进行匹配(命中一条规则就返回)mq顺序性问题
1.binlog本身是有序的,写入到mq之后如何保障顺序是很多人会比较关注,在issue里也有非常多人咨询了类似的问题,这里做一个统一的解答2.canal目前选择支持的kafka/rocketmq,本质上都是基于本地文件的方式来支持了分区级的顺序消息的能力,也就是binlog写入mq是可以有一些顺序性保障,这个取决于用户的一些参数选择 canal支持MQ数据的几种路由方式:单topic单分区,单topic多分区、多topic单分区、多topic多分区 canal.mq.dynamicTopic,主要控制是否是单topic还是多topic,针对命中条件的表可以发到表名对应的topic、库名对应的topic、默认topic name3.canal.mq.partitionsNum、canal.mq.partitionHash,主要控制是否多分区以及分区的partition的路由计算,针对命中条件的可以做到按表级做分区、pk级做分区等canal的消费顺序性,主要取决于描述2中的路由选择,举例说明:单topic单分区,可以严格保证和binlog一样的顺序性,缺点就是性能比较慢,单分区的性能写入大概在2~3k的TPS多topic单分区,可以保证表级别的顺序性,一张表或者一个库的所有数据都写入到一个topic的单分区中,可以保证有序性,针对热点表也存在写入分区的性能问题单topic、多topic的多分区,如果用户选择的是指定table的方式,那和第二部分一样,保障的是表级别的顺序性(存在热点表写入分区的性能问题),如果用户选择的是指定pk hash的方式,那只能保障的是一个pk的多次binlog顺序性 ** pk hash的方式需要业务权衡,这里性能会最好,但如果业务上有pk变更或者对多pk数据有顺序性依赖,就会产生业务处理错乱的情况. 如果有pk变更,pk变更前和变更后的值会落在不同的分区里,业务消费就会有先后顺序的问题,需要注意6.canal配置文件说明
conf\example\instance.properties ################################################### mysql serverId , v1.0.26+ will autoGen # canal.instance.mysql.slaveId=0 //每个instance都会伪装成一个mysql slave , 此id对于canal前端的Mysql实例而言,必须是唯一的,但是同一个Canal中相同的instance,此slaveld应该一样 # enable gtid use true/falsecanal.instance.gtidon=false # position infocanal.instance.master.address=127.0.0.1:3306 //需要连接的数据库地址及端口canal.instance.master.journal.name= //需要读取的起始的binlog文件canal.instance.master.position= //需要读取的起始的binlog文件的偏移量canal.instance.master.timestamp= //需要读取的起始的binlog的时间戳 canal.instance.master.gtid= # rds oss binlogcanal.instance.rds.accesskey=canal.instance.rds.secretkey=canal.instance.rds.instanceId= # table meta tsdb infocanal.instance.tsdb.enable=true //v1.0.25版本新增,是否开启table meta的时间序列版本记录功能#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb //v1.0.25版本新增,table meta的时间序列版本的本地存储路径,默认为instance目录#canal.instance.tsdb.dbUsername=canal#canal.instance.tsdb.dbPassword=canal #canal.instance.standby.address =#canal.instance.standby.journal.name =#canal.instance.standby.position =#canal.instance.standby.timestamp =#canal.instance.standby.gtid= # username/passwordcanal.instance.dbUsername=canal //数据库账号canal.instance.dbPassword=canal //数据库密码canal.instance.connectionCharset = UTF-8 //数据库解析编码格式canal.instance.defaultDatabaseName =test //数据库连接时默认schema# enable druid Decrypt database passwordcanal.instance.enableDruid=false#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ== # table regexcanal.instance.filter.regex=.*\\..* //mysql 数据解析关注的表,Perl正则表达式.# table black regexcanal.instance.filter.black.regex= //canal将会过滤那些不符合要求的table,这些table的数据将不会被解析和传送 #################################################conf\canal.properties ########################################################## common argument############# #################################################canal.id= 1 #每个canal server实例的唯一标识canal.ip= #canal server绑定的本地IP信息,如果不配置,默认选择一个本机IP进行,canal.port=11111 #canal server提供socket tcp服务的端口canal.metrics.pull.port=11112canal.zkServers= #canal server链接zookeeper集群的链接信息 # flush data to zkcanal.zookeeper.flush.period = 1000 #canal持久化数据到zookeeper上的更新频率,单位毫秒canal.withoutNetty = false # tcp, kafka, RocketMQcanal.serverMode = tcp # flush meta cursor/parse position to file canal.file.data.dir = ${canal.conf.dir} #canal持久化数据到file上的目录 canal.file.flush.period = 1000 #canal持久化数据到file上的更新频率,单位毫秒 ## memory store RingBuffer size, should be Math.pow(2,n) canal.instance.memory.buffer.size = 16384 #canal内存store中可缓存buffer记录数,需要为2的指数## memory store RingBuffer used memory unit size , default 1kbcanal.instance.memory.buffer.memunit = 1024 #内存记录的单位大小,默认1KB,和buffer.size组合决定最终的内存使用大小## meory store gets mode used MEMSIZE or ITEMSIZEcanal.instance.memory.batch.mode = MEMSIZE #canal内存store中数据缓存模式 1. ITEMSIZE : 根据buffer.size进行限制,只限制记录的数量 2. MEMSIZE : 根据buffer.size * buffer.memunit的大小,限制缓存记录的大小 canal.instance.memory.rawEntry = true ## detecing configcanal.instance.detecting.enable = false #是否开启心跳检查 #canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()canal.instance.detecting.sql = select 1 #心跳检查sqlcanal.instance.detecting.interval.time = 3 #心跳检查频率,单位秒 canal.instance.detecting.retry.threshold = 3 #心跳检查失败重试次数##非常注意:interval.time * retry.threshold值,应该参考既往DBA同学对数据库的故障恢复时间, ##“太短”会导致集群运行态角色“多跳”;“太长”失去了活性检测的意义,导致集群的敏感度降低,Consumer断路可能性增加。 canal.instance.detecting.heartbeatHaEnable = false #心跳检查失败后,是否开启自动mysql自动切换 #说明:比如心跳检查失败超过阀值后,如果该配置为true,canal就会自动链到mysql备库获取binlog数据false # support maximum transaction size, more than the size of the transaction will be cut into multiple transactions deliverycanal.instance.transaction.size = 1024 #最大事务完整解析的长度支持超过该长度后,一个事务可能会被拆分成多次提交到canal store中,无法保证事务的完整可见性 # mysql fallback connected to new master should fallback timescanal.instance.fallbackIntervalInSeconds = 60 #canal发生mysql切换时,在新的mysql库上查找 binlog时需要往前查找的时间,单位秒说明:mysql主备库可能存在解析延迟或者时钟不统一,需要回退一段时间,保证数据不丢 # network configcanal.instance.network.receiveBufferSize = 16384 #网络链接参数,SocketOptions.SO_RCVBUFcanal.instance.network.sendBufferSize = 16384 #网络链接参数,SocketOptions.SO_SNDBUFcanal.instance.network.soTimeout = 30 #网络链接参数,SocketOptions.SO_TIMEOUT # binlog filter configcanal.instance.filter.druid.ddl = true canal.instance.filter.query.dcl = false #ddl语句是否隔离发送,开启隔离可保证每次只返回发送一条ddl数据,不和其他dml语句混合返回.(otter ddl同步使用) canal.instance.filter.query.dml = false #是否忽略DML的query语句,比如insert/update/delete table.(mysql5.6的ROW模式可以包含statement模式的query记录) canal.instance.filter.query.ddl = false #是否忽略DDL的query语句,比如create table/alater table/drop table/rename table/create index/drop index. (目前支持的ddl类型主要为table级别的操作,create databases/trigger/procedure暂时划分为dcl类型) canal.instance.filter.table.error = falsecanal.instance.filter.rows = falsecanal.instance.filter.transaction.entry = false # binlog format/image checkcanal.instance.binlog.format = ROW,STATEMENT,MIXED canal.instance.binlog.image = FULL,MINIMAL,NOBLOB # binlog ddl isolationcanal.instance.get.ddl.isolation = false # parallel parser configcanal.instance.parser.parallel = true## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()#canal.instance.parser.parallelThreadSize = 16## disruptor ringbuffer size, must be power of 2canal.instance.parser.parallelBufferSize = 256 # table meta tsdb info //关于时间序列版本canal.instance.tsdb.enable=truecanal.instance.tsdb.dir=${canal.file.data.dir:../conf}/${canal.instance.destination:}canal.instance.tsdb.url=jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;canal.instance.tsdb.dbUsername=canalcanal.instance.tsdb.dbPassword=canal# dump snapshot interval, default 24 hourcanal.instance.tsdb.snapshot.interval=24# purge snapshot expire , default 360 hour(15 days)canal.instance.tsdb.snapshot.expire=360 # rds oss binlog accountcanal.instance.rds.accesskey =canal.instance.rds.secretkey = ########################################################## destinations############# #################################################canal.destinations= example# conf root dircanal.conf.dir = ../conf# auto scan instance dir add/remove and start/stop instancecanal.auto.scan = true #开启instance自动扫描如果配置为true,canal.conf.dir目录下的instance配置变化会自动触发:a. instance目录新增: 触发instance配置载入,lazy为true时则自动启动b. instance目录删除:卸载对应instance配置,如已启动则进行关闭c. instance.properties文件变化:reload instance配置,如已启动自动进行重启操作 canal.auto.scan.interval = 5 #instance自动扫描的间隔时间,单位秒 canal.instance.tsdb.spring.xml=classpath:spring/tsdb/h2-tsdb.xml#canal.instance.tsdb.spring.xml=classpath:spring/tsdb/mysql-tsdb.xml canal.instance.global.mode = spring #instance管理模式,Production级别我们要求使用spring canal.instance.global.lazy = false #全局lazy模式#canal.instance.global.manager.address = 127.0.0.1:1099 #全局的manager配置方式的链接信息 #canal.instance.global.spring.xml = classpath:spring/memory-instance.xmlcanal.instance.global.spring.xml = classpath:spring/file-instance.xml #全局的spring配置方式的组件文件 #canal.instance.global.spring.xml = classpath:spring/default-instance.xml来源地址:https://blog.csdn.net/qq_45072555/article/details/129193008







