
YOLOv5如何进行区域目标检测(手把手教学)
提示:本项目的源码是基于yolov5 6.0版本修改
文章目录
效果展示
在使用YOLOv5的有些时候,我们会遇到一些具体的目标检测要求,比如要求不检测全图,只在规定的区域内才检测。所以为了满足这个需求,可以用一个mask覆盖掉不想检测的区域,使得YOLOv5在检测的时候,该覆盖区域就不纳入检测范围。
话不多说,直接上检测效果,可以很直观的看到目标在进入规定的检测区域才得到检测。

一、确定检测范围
快捷查询方法:
- 用windows自带画图打开图片
- 鼠标移到想要框选检测区域的四个顶点,查询点的像素坐标
- 分别计算点的像素坐标与图片总像素坐标的比例(后面要用)
查询方法如下图所示:
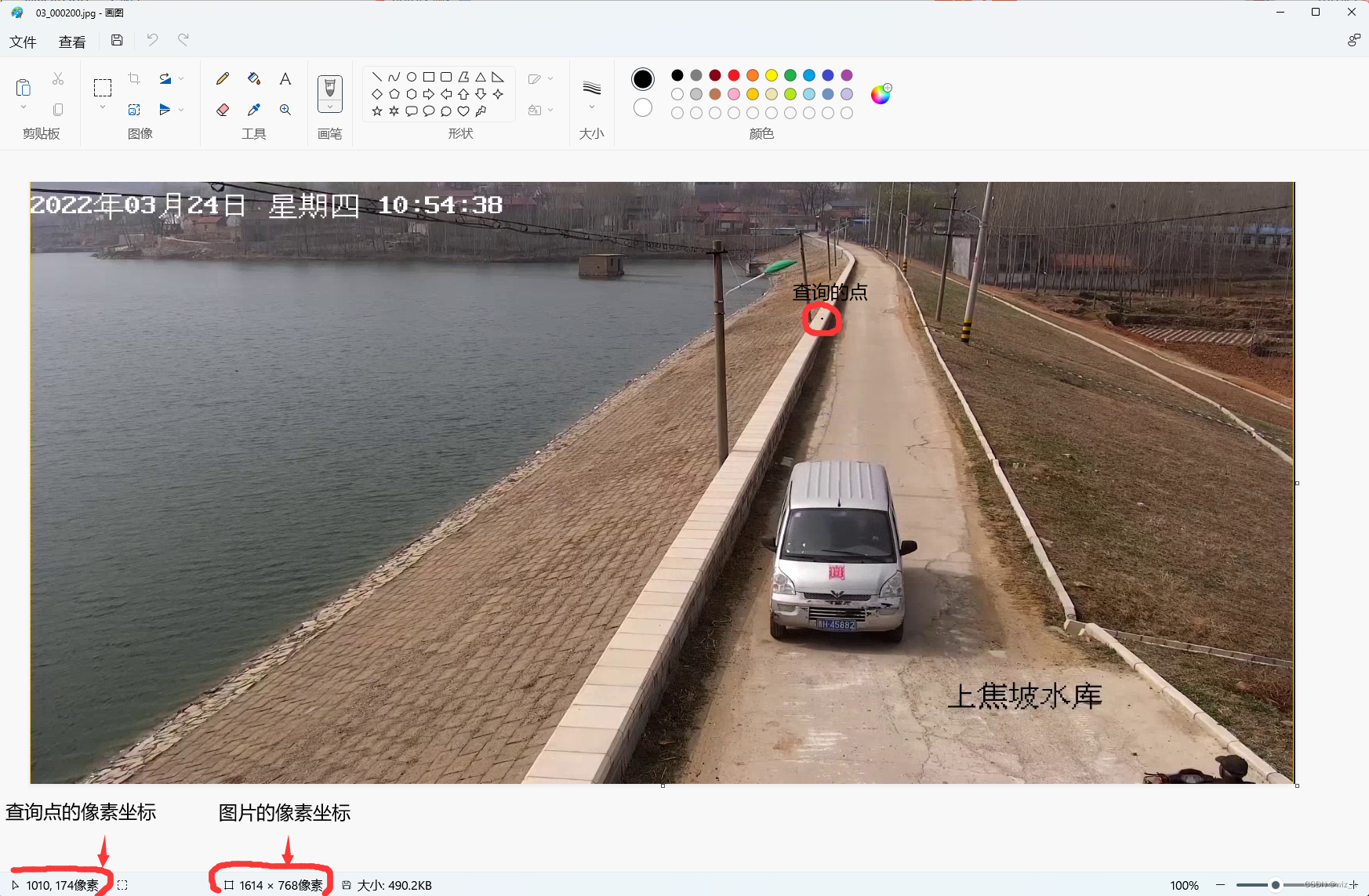
提示:以下是计算的举例说明,仅供参考
例如:图中所标注的点(1010,174)代表(x,y)坐标
hl1 = 174 / 768 (可约分)监测区域纵坐标距离图片***顶部*** 比例
wl1 = 1010 / 1614 (可约分)监测区域横坐标距离图片***左部*** 比例
这里只举例了一个点,如检测范围是四边形,需要计算左上,右上,右下,左下四个顶点。
二、detect.py代码修改
1.确定区域检测范围
在下面代码位置填上计算好的比例:
# mask for certain region #1,2,3,4 分别对应左上,右上,右下,左下四个点 hl1 = 1.4 / 10 #监测区域高度距离图片顶部比例 wl1 = 6.4 / 10 #监测区域高度距离图片左部比例 hl2 = 1.4 / 10 # 监测区域高度距离图片顶部比例 wl2 = 6.8 / 10 # 监测区域高度距离图片左部比例 hl3 = 4.5 / 10 # 监测区域高度距离图片顶部比例 wl3 = 7.6 / 10 # 监测区域高度距离图片左部比例 hl4 = 4.5 / 10 # 监测区域高度距离图片顶部比例 wl4 = 5.5 / 10 # 监测区域高度距离图片左部比例在135行:for path, img, im0s, vid_cap in dataset: 下插入代码:
# mask for certain region #1,2,3,4 分别对应左上,右上,右下,左下四个点 hl1 = 1.6 / 10 #监测区域高度距离图片顶部比例 wl1 = 6.4 / 10 #监测区域高度距离图片左部比例 hl2 = 1.6 / 10 # 监测区域高度距离图片顶部比例 wl2 = 6.8 / 10 # 监测区域高度距离图片左部比例 hl3 = 4.5 / 10 # 监测区域高度距离图片顶部比例 wl3 = 7.6 / 10 # 监测区域高度距离图片左部比例 hl4 = 4.5 / 10 # 监测区域高度距离图片顶部比例 wl4 = 5.5 / 10 # 监测区域高度距离图片左部比例 if webcam: for b in range(0,img.shape[0]): mask = np.zeros([img[b].shape[1], img[b].shape[2]], dtype=np.uint8) #mask[round(img[b].shape[1] * hl1):img[b].shape[1], round(img[b].shape[2] * wl1):img[b].shape[2]] = 255 pts = np.array([[int(img[b].shape[2] * wl1), int(img[b].shape[1] * hl1)], # pts1 [int(img[b].shape[2] * wl2), int(img[b].shape[1] * hl2)], # pts2 [int(img[b].shape[2] * wl3), int(img[b].shape[1] * hl3)], # pts3 [int(img[b].shape[2] * wl4), int(img[b].shape[1] * hl4)]], np.int32) mask = cv2.fillPoly(mask,[pts],(255,255,255)) imgc = img[b].transpose((1, 2, 0)) imgc = cv2.add(imgc, np.zeros(np.shape(imgc), dtype=np.uint8), mask=mask) #cv2.imshow('1',imgc) img[b] = imgc.transpose((2, 0, 1)) else: mask = np.zeros([img.shape[1], img.shape[2]], dtype=np.uint8) #mask[round(img.shape[1] * hl1):img.shape[1], round(img.shape[2] * wl1):img.shape[2]] = 255 pts = np.array([[int(img.shape[2] * wl1), int(img.shape[1] * hl1)], # pts1[int(img.shape[2] * wl2), int(img.shape[1] * hl2)], # pts2[int(img.shape[2] * wl3), int(img.shape[1] * hl3)], # pts3[int(img.shape[2] * wl4), int(img.shape[1] * hl4)]], np.int32) mask = cv2.fillPoly(mask, [pts], (255,255,255)) img = img.transpose((1, 2, 0)) img = cv2.add(img, np.zeros(np.shape(img), dtype=np.uint8), mask=mask) img = img.transpose((2, 0, 1))2.画检测区域线(若不想像效果图一样显示出检测区域可不添加)
在196行: p, s, im0, frame = path, ‘’, im0s.copy(), getattr(dataset, ‘frame’, 0) 后添加
if webcam: # batch_size >= 1 p, s, im0, frame = path[i], f'{i}: ', im0s[i].copy(), dataset.count cv2.putText(im0, "Detection_Region", (int(im0.shape[1] * wl1 - 5), int(im0.shape[0] * hl1 - 5)),cv2.FONT_HERSHEY_SIMPLEX,1.0, (255, 255, 0), 2, cv2.LINE_AA) pts = np.array([[int(im0.shape[1] * wl1), int(im0.shape[0] * hl1)], # pts1 [int(im0.shape[1] * wl2), int(im0.shape[0] * hl2)], # pts2 [int(im0.shape[1] * wl3), int(im0.shape[0] * hl3)], # pts3 [int(im0.shape[1] * wl4), int(im0.shape[0] * hl4)]], np.int32) # pts4 # pts = pts.reshape((-1, 1, 2)) zeros = np.zeros((im0.shape), dtype=np.uint8) mask = cv2.fillPoly(zeros, [pts], color=(0, 165, 255)) im0 = cv2.addWeighted(im0, 1, mask, 0.2, 0) cv2.polylines(im0, [pts], True, (255, 255, 0), 3) # plot_one_box(dr, im0, label='Detection_Region', color=(0, 255, 0), line_thickness=2) else: p, s, im0, frame = path, '', im0s.copy(), getattr(dataset, 'frame', 0) cv2.putText(im0, "Detection_Region", (int(im0.shape[1] * wl1 - 5), int(im0.shape[0] * hl1 - 5)),cv2.FONT_HERSHEY_SIMPLEX,1.0, (255, 255, 0), 2, cv2.LINE_AA) pts = np.array([[int(im0.shape[1] * wl1), int(im0.shape[0] * hl1)], # pts1 [int(im0.shape[1] * wl2), int(im0.shape[0] * hl2)], # pts2 [int(im0.shape[1] * wl3), int(im0.shape[0] * hl3)], # pts3 [int(im0.shape[1] * wl4), int(im0.shape[0] * hl4)]], np.int32) # pts4 # pts = pts.reshape((-1, 1, 2)) zeros = np.zeros((im0.shape), dtype=np.uint8) mask = cv2.fillPoly(zeros, [pts], color=(0, 165, 255)) im0 = cv2.addWeighted(im0, 1, mask, 0.2, 0) cv2.polylines(im0, [pts], True, (255, 255, 0), 3)总结
基于yolov5的区域目标检测实质上就是在图片选定检测区域做一个遮掩mask,检测区域不一定为四边形,也可是其他形状。该方法可检测图片/视频/摄像头。
提示:使用该方法要先确定数据集图像是否像监控图像一样,画面主体保持不变
原理展现如图所示:(图片参考http://t.csdn.cn/lgyO1)



整体detect.py修改代码
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license"""Run inference on images, videos, directories, streams, etc.Usage: $ python path/to/detect.py --source path/to/img.jpg --weights yolov5s.pt --img 640"""import argparseimport osimport sysfrom pathlib import Pathimport cv2import numpy as npimport torchimport torch.backends.cudnn as cudnnFILE = Path(__file__).resolve()ROOT = FILE.parents[0] # YOLOv5 root directoryif str(ROOT) not in sys.path: sys.path.append(str(ROOT)) # add ROOT to PATHROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relativefrom models.experimental import attempt_loadfrom utils.datasets import LoadImages, LoadStreamsfrom utils.general import apply_classifier, check_img_size, check_imshow, check_requirements, check_suffix, colorstr, \ increment_path, non_max_suppression, print_args, save_one_box, scale_coords, set_logging, \ strip_optimizer, xyxy2xywhfrom utils.plots import Annotator, colorsfrom utils.torch_utils import load_classifier, select_device, time_sync@torch.no_grad()def run(weights=ROOT / 'yolov5s.pt', # model.pt path(s) source=ROOT / 'data/images', # file/dir/URL/glob, 0 for webcam imgsz=640, # inference size (pixels) conf_thres=0.25, # confidence threshold iou_thres=0.45, # NMS IOU threshold max_det=1000, # maximum detections per image device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu view_img=False, # show results save_txt=False, # save results to *.txt save_conf=False, # save confidences in --save-txt labels save_crop=False, # save cropped prediction boxes nosave=False, # do not save images/videos classes=None, # filter by class: --class 0, or --class 0 2 3 agnostic_nms=False, # class-agnostic NMS augment=False, # augmented inference visualize=False, # visualize features update=False, # update all models project=ROOT / 'runs/detect', # save results to project/name name='exp', # save results to project/name exist_ok=False, # existing project/name ok, do not increment line_thickness=3, # bounding box thickness (pixels) hide_labels=False, # hide labels hide_conf=False, # hide confidences half=False, # use FP16 half-precision inference dnn=False, # use OpenCV DNN for ONNX inference ): source = str(source) save_img = not nosave and not source.endswith('.txt') # save inference images webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith( ('rtsp://', 'rtmp://', 'http://', 'https://')) # Directories save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir # Initialize set_logging() device = select_device(device) half &= device.type != 'cpu' # half precision only supported on CUDA # Load model w = str(weights[0] if isinstance(weights, list) else weights) classify, suffix, suffixes = False, Path(w).suffix.lower(), ['.pt', '.onnx', '.tflite', '.pb', ''] check_suffix(w, suffixes) # check weights have acceptable suffix pt, onnx, tflite, pb, saved_model = (suffix == x for x in suffixes) # backend booleans stride, names = 64, [f'class{i}' for i in range(1000)] # assign defaults if pt: model = torch.jit.load(w) if 'torchscript' in w else attempt_load(weights, map_location=device) stride = int(model.stride.max()) # model stride names = model.module.names if hasattr(model, 'module') else model.names # get class names if half: model.half() # to FP16 if classify: # second-stage classifier modelc = load_classifier(name='resnet50', n=2) # initialize modelc.load_state_dict(torch.load('resnet50.pt', map_location=device)['model']).to(device).eval() elif onnx: if dnn: # check_requirements(('opencv-python>=4.5.4',)) net = cv2.dnn.readNetFromONNX(w) else: check_requirements(('onnx', 'onnxruntime')) import onnxruntime session = onnxruntime.InferenceSession(w, None) else: # TensorFlow models check_requirements(('tensorflow>=2.4.1',)) import tensorflow as tf if pb: # https://www.tensorflow.org/guide/migrate#a_graphpb_or_graphpbtxt def wrap_frozen_graph(gd, inputs, outputs): x = tf.compat.v1.wrap_function(lambda: tf.compat.v1.import_graph_def(gd, name=""), []) # wrapped import return x.prune(tf.nest.map_structure(x.graph.as_graph_element, inputs), tf.nest.map_structure(x.graph.as_graph_element, outputs)) graph_def = tf.Graph().as_graph_def() graph_def.ParseFromString(open(w, 'rb').read()) frozen_func = wrap_frozen_graph(gd=graph_def, inputs="x:0", outputs="Identity:0") elif saved_model: model = tf.keras.models.load_model(w) elif tflite: interpreter = tf.lite.Interpreter(model_path=w) # load TFLite model interpreter.allocate_tensors() # allocate input_details = interpreter.get_input_details() # inputs output_details = interpreter.get_output_details() # outputs int8 = input_details[0]['dtype'] == np.uint8 # is TFLite quantized uint8 model imgsz = check_img_size(imgsz, s=stride) # check image size # Dataloader if webcam: view_img = check_imshow() cudnn.benchmark = True # set True to speed up constant image size inference dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt) bs = len(dataset) # batch_size else: dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt) bs = 1 # batch_size vid_path, vid_writer = [None] * bs, [None] * bs # Run inference if pt and device.type != 'cpu': model(torch.zeros(1, 3, *imgsz).to(device).type_as(next(model.parameters()))) # run once dt, seen = [0.0, 0.0, 0.0], 0 for path, img, im0s, vid_cap in dataset: # mask for certain region #1,2,3,4 分别对应左上,右上,右下,左下四个点 hl1 = 1.6 / 10 #监测区域高度距离图片顶部比例 wl1 = 6.4 / 10 #监测区域高度距离图片左部比例 hl2 = 1.6 / 10 # 监测区域高度距离图片顶部比例 wl2 = 6.8 / 10 # 监测区域高度距离图片左部比例 hl3 = 4.5 / 10 # 监测区域高度距离图片顶部比例 wl3 = 7.6 / 10 # 监测区域高度距离图片左部比例 hl4 = 4.5 / 10 # 监测区域高度距离图片顶部比例 wl4 = 5.5 / 10 # 监测区域高度距离图片左部比例 if webcam: for b in range(0,img.shape[0]): mask = np.zeros([img[b].shape[1], img[b].shape[2]], dtype=np.uint8) #mask[round(img[b].shape[1] * hl1):img[b].shape[1], round(img[b].shape[2] * wl1):img[b].shape[2]] = 255 pts = np.array([[int(img[b].shape[2] * wl1), int(img[b].shape[1] * hl1)], # pts1 [int(img[b].shape[2] * wl2), int(img[b].shape[1] * hl2)], # pts2 [int(img[b].shape[2] * wl3), int(img[b].shape[1] * hl3)], # pts3 [int(img[b].shape[2] * wl4), int(img[b].shape[1] * hl4)]], np.int32) mask = cv2.fillPoly(mask,[pts],(255,255,255)) imgc = img[b].transpose((1, 2, 0)) imgc = cv2.add(imgc, np.zeros(np.shape(imgc), dtype=np.uint8), mask=mask) #cv2.imshow('1',imgc) img[b] = imgc.transpose((2, 0, 1)) else: mask = np.zeros([img.shape[1], img.shape[2]], dtype=np.uint8) #mask[round(img.shape[1] * hl1):img.shape[1], round(img.shape[2] * wl1):img.shape[2]] = 255 pts = np.array([[int(img.shape[2] * wl1), int(img.shape[1] * hl1)], # pts1[int(img.shape[2] * wl2), int(img.shape[1] * hl2)], # pts2[int(img.shape[2] * wl3), int(img.shape[1] * hl3)], # pts3[int(img.shape[2] * wl4), int(img.shape[1] * hl4)]], np.int32) mask = cv2.fillPoly(mask, [pts], (255,255,255)) img = img.transpose((1, 2, 0)) img = cv2.add(img, np.zeros(np.shape(img), dtype=np.uint8), mask=mask) img = img.transpose((2, 0, 1)) t1 = time_sync() if onnx: img = img.astype('float32') else: img = torch.from_numpy(img).to(device) img = img.half() if half else img.float() # uint8 to fp16/32 img = img / 255.0 # 0 - 255 to 0.0 - 1.0 if len(img.shape) == 3: img = img[None] # expand for batch dim t2 = time_sync() dt[0] += t2 - t1 # Inference if pt: visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False pred = model(img, augment=augment, visualize=visualize)[0] elif onnx: if dnn: net.setInput(img) pred = torch.tensor(net.forward()) else: pred = torch.tensor(session.run([session.get_outputs()[0].name], {session.get_inputs()[0].name: img})) else: # tensorflow model (tflite, pb, saved_model) imn = img.permute(0, 2, 3, 1).cpu().numpy() # image in numpy if pb: pred = frozen_func(x=tf.constant(imn)).numpy() elif saved_model: pred = model(imn, training=False).numpy() elif tflite: if int8: scale, zero_point = input_details[0]['quantization'] imn = (imn / scale + zero_point).astype(np.uint8) # de-scale interpreter.set_tensor(input_details[0]['index'], imn) interpreter.invoke() pred = interpreter.get_tensor(output_details[0]['index']) if int8: scale, zero_point = output_details[0]['quantization'] pred = (pred.astype(np.float32) - zero_point) * scale # re-scale pred[..., 0] *= imgsz[1] # x pred[..., 1] *= imgsz[0] # y pred[..., 2] *= imgsz[1] # w pred[..., 3] *= imgsz[0] # h pred = torch.tensor(pred) t3 = time_sync() dt[1] += t3 - t2 # NMS pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det) dt[2] += time_sync() - t3 # Second-stage classifier (optional) if classify: pred = apply_classifier(pred, modelc, img, im0s) # Process predictions for i, det in enumerate(pred): # per image seen += 1 # if webcam: # batch_size >= 1 # p, s, im0, frame = path[i], f'{i}: ', im0s[i].copy(), dataset.count # else: # p, s, im0, frame = path, '', im0s.copy(), getattr(dataset, 'frame', 0) if webcam: # batch_size >= 1 p, s, im0, frame = path[i], f'{i}: ', im0s[i].copy(), dataset.count cv2.putText(im0, "Detection_Region", (int(im0.shape[1] * wl1 - 5), int(im0.shape[0] * hl1 - 5)),cv2.FONT_HERSHEY_SIMPLEX,1.0, (255, 255, 0), 2, cv2.LINE_AA) pts = np.array([[int(im0.shape[1] * wl1), int(im0.shape[0] * hl1)], # pts1 [int(im0.shape[1] * wl2), int(im0.shape[0] * hl2)], # pts2 [int(im0.shape[1] * wl3), int(im0.shape[0] * hl3)], # pts3 [int(im0.shape[1] * wl4), int(im0.shape[0] * hl4)]], np.int32) # pts4 # pts = pts.reshape((-1, 1, 2)) zeros = np.zeros((im0.shape), dtype=np.uint8) mask = cv2.fillPoly(zeros, [pts], color=(0, 165, 255)) im0 = cv2.addWeighted(im0, 1, mask, 0.2, 0) cv2.polylines(im0, [pts], True, (255, 255, 0), 3) # plot_one_box(dr, im0, label='Detection_Region', color=(0, 255, 0), line_thickness=2) else: p, s, im0, frame = path, '', im0s.copy(), getattr(dataset, 'frame', 0) cv2.putText(im0, "Detection_Region", (int(im0.shape[1] * wl1 - 5), int(im0.shape[0] * hl1 - 5)),cv2.FONT_HERSHEY_SIMPLEX,1.0, (255, 255, 0), 2, cv2.LINE_AA) pts = np.array([[int(im0.shape[1] * wl1), int(im0.shape[0] * hl1)], # pts1 [int(im0.shape[1] * wl2), int(im0.shape[0] * hl2)], # pts2 [int(im0.shape[1] * wl3), int(im0.shape[0] * hl3)], # pts3 [int(im0.shape[1] * wl4), int(im0.shape[0] * hl4)]], np.int32) # pts4 # pts = pts.reshape((-1, 1, 2)) zeros = np.zeros((im0.shape), dtype=np.uint8) mask = cv2.fillPoly(zeros, [pts], color=(0, 165, 255)) im0 = cv2.addWeighted(im0, 1, mask, 0.2, 0) cv2.polylines(im0, [pts], True, (255, 255, 0), 3) p = Path(p) # to Path save_path = str(save_dir / p.name) # img.jpg txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt s += '%gx%g ' % img.shape[2:] # print string gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh imc = im0.copy() if save_crop else im0 # for save_crop annotator = Annotator(im0, line_width=line_thickness, example=str(names)) if len(det): # Rescale boxes from img_size to im0 size det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round() # Print results for c in det[:, -1].unique(): n = (det[:, -1] == c).sum() # detections per class s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string # Write results for *xyxy, conf, cls in reversed(det): if save_txt: # Write to file xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format with open(txt_path + '.txt', 'a') as f:f.write(('%g ' * len(line)).rstrip() % line + '\n') if save_img or save_crop or view_img: # Add bbox to image c = int(cls) # integer class label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}') annotator.box_label(xyxy, label, color=colors(c, True)) if save_crop:save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True) # Print time (inference-only) print(f'{s}Done. ({t3 - t2:.3f}s)') # Stream results im0 = annotator.result() if view_img: cv2.imshow(str(p), im0) cv2.waitKey(1) # 1 millisecond # Save results (image with detections) if save_img: if dataset.mode == 'image': cv2.imwrite(save_path, im0) else: # 'video' or 'stream' if vid_path[i] != save_path: # new video vid_path[i] = save_path if isinstance(vid_writer[i], cv2.VideoWriter):vid_writer[i].release() # release previous video writer if vid_cap: # videofps = vid_cap.get(cv2.CAP_PROP_FPS)w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) else: # streamfps, w, h = 30, im0.shape[1], im0.shape[0]save_path += '.mp4' vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h)) vid_writer[i].write(im0) # Print results t = tuple(x / seen * 1E3 for x in dt) # speeds per image print(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t) if save_txt or save_img: s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else '' print(f"Results saved to {colorstr('bold', save_dir)}{s}") if update: strip_optimizer(weights) # update model (to fix SourceChangeWarning)def parse_opt(): parser = argparse.ArgumentParser() parser.add_argument('--weights', nargs='+', type=str, default=ROOT / '权重文件', help='model path(s)') parser.add_argument('--source', type=str, default=ROOT / '检测图片', help='file/dir/URL/glob, 0 for webcam') parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w') parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold') parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold') parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image') parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') parser.add_argument('--view-img', action='store_true', help='show results') parser.add_argument('--save-txt', action='store_true', help='save results to *.txt') parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels') parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes') parser.add_argument('--nosave', action='store_true', help='do not save images/videos') parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3') parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS') parser.add_argument('--augment', action='store_true', help='augmented inference') parser.add_argument('--visualize', action='store_true', help='visualize features') parser.add_argument('--update', action='store_true', help='update all models') parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name') parser.add_argument('--name', default='exp', help='save results to project/name') parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment') parser.add_argument('--line-thickness', default=1, type=int, help='bounding box thickness (pixels)') parser.add_argument('--hide-labels', default=True, action='store_true', help='hide labels') parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences') parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference') parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference') opt = parser.parse_args() opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand print_args(FILE.stem, opt) return optdef main(opt): check_requirements(exclude=('tensorboard', 'thop')) run(**vars(opt))if __name__ == "__main__": opt = parse_opt() main(opt)来源地址:https://blog.csdn.net/qq_39740357/article/details/125149010







