
如何使用Django基础模板优化自己的知识库 ,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
我有时候会把文章同步到头条上,发现了一个蛮有意思的现象。公众号里的文章基本上阅读量比较稳定,如果高也高不到哪里,我发一些非技术类的文章,阅读量明显要高一些,技术文章相对来说非技术文章要低一些。而头条却相反,有些技术类的文章会有井喷的现象,突然一篇文章就几百的收藏量,非技术类的文章反而关注的人少。我想着也就是公众号和头条一个很大的差别吧,公众号群体相对垂直,读者粘性强,头条群体相对更大,但是读者的粘性不强。
有句话说,一屋不扫而已扫天下,我觉得我就深陷其中,自己每天阅读的文章很多,但是值得收藏的少,保守估计,一天收藏一篇,那一年就是300多篇,如果稍多几篇,那这个量级就会翻几番。绝对是我们控制不了的。
等我意识到这个问题的严重性,从开始改进,到今天,也就差不多两天左右的时间,一个新的知识库就建立起来了。
这是原来的知识库初稿截图:
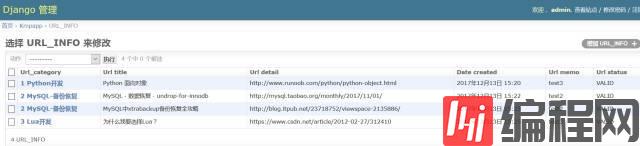
截止现在,已经发生了重大的变化。
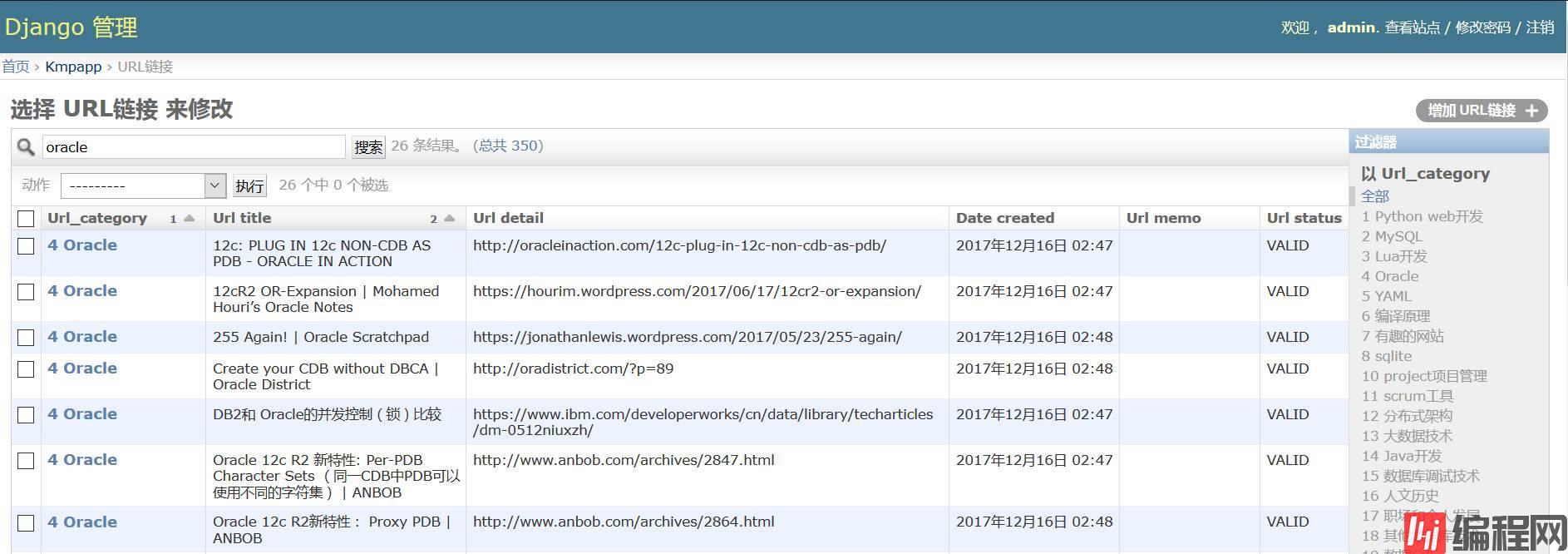
除去界面的风格,这两天除了工作,做了下面的几件事情:
配置了右侧的导航,也叫过滤器。
从浏览器的收藏夹导出了json格式的标签,通过Python来解析,导入了MySQL里面
最近修改的代码同步到了linux端
把windows端的部分数据从sqlite迁移到了MySQL中
配置了搜索框,可以根据多字段数据进行全局搜索
添加URL配置的时候,除了URL链接和,其他数据都是动态生成
配置了一些额外的类别,准备支持更全面的信息
其中第二步是重点也是难点,解析json的过程并不顺利,里面有很多的细节和自己设想的有很大的差别,导致解析的过程可谓是困难重重。因为原来的有些标签比较混乱,结构层次差别很大,解析的时候压根没法实现自动解析。这个部分花的时间最多。
算是迈出了一大步,目前已收集整理了近350个标签,如果要搜索一些内容,可以完全通过这个知识库来得到一些结果了。
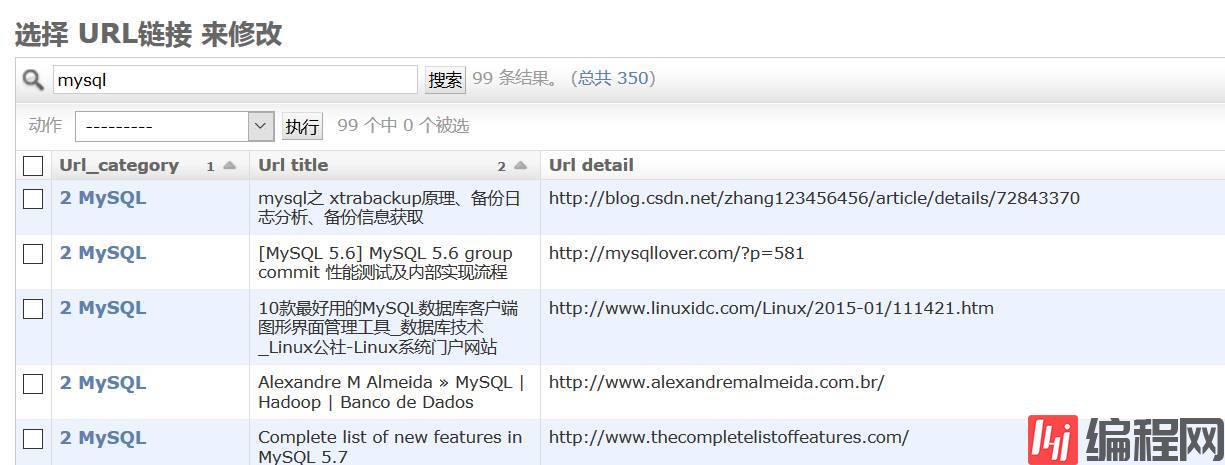
后续,计划做几件事情来持续改进:
把公众号的文章链接收集过来,那直接量级就是1300+,比现有的量级翻了3倍多
后期尝试引进全文索引,能够根据关键字搜索到一些文章的来源,这个工作目前还在考虑如何细化。
把公众号收藏的文章引入进来,这个量级估计至少是500+,收集的方式相比公众号收集要更大。
把一些重要的文档能够归纳整理起来,放到知识库里面集中管理
把个人工作或者知识点收集整理起来,目前是在一个应用里面,但是会有不同的目录和链接入口
支持文件上传,支持文件下载
做文件数据的定期备份工作
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注编程网行业资讯频道,感谢您对编程网的支持。







