
文章目录
- 1、数据集格式及存放
- 2、修改两处
- 3、用训练命令生成配置文件
- 4、正式训练开始
- 5、报错记录
- 6、模型评价测试(VOC指标mAP、COCO指标AP)
- 7、绘制每个类别bbox 的结果曲线图并保存
- 8、统计模型参数量和FLOPs
- 9 计算混淆矩阵
- 10 画PR曲线
- 11 查看完整config配置文件
- 12 核查数据增强的结果是否正确
- 8、参考链接
mmdet支持COCO格式和VOC格式,能用COCO格式,还是建议COCO的。网上有YOLO转COCO,VOC转COCO,可以自己转换。
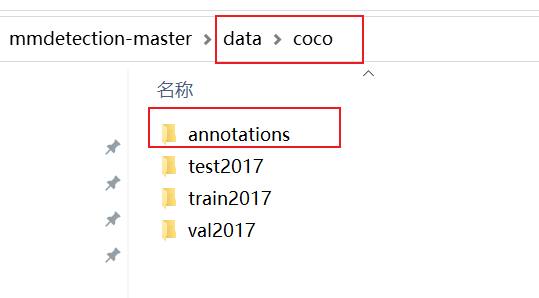
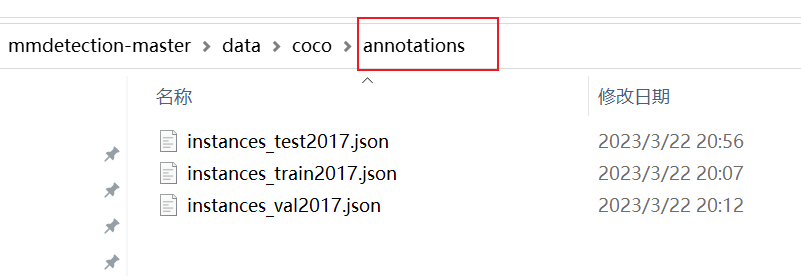
在mmdetection代码的根目录下,创建 data/coco 文件夹,按照coco的格式排放好数据集。annotations下面是标签文件,train2017、val2017、test2017是图片。
第一处: mmdet/core/evalution/class_names.py 代码下的 def coco_classes() 的 return 内容改为自己数据集的类别;
第二处:mmdet/datasets/coco.py 代码下的 class CocoDataset(CustomDataset) 的 CLASSES 改为自己数据集的类别;
注意:修改两处后,一定要在根目录下,输入命令:
python setup.py install build
重新编译代码,要不然类别会没有载入,还是原coco类别,训练异常。
python tools/train.py configs/cascade_rcnn/cascade_rcnn_r50_fpn_1x_coco.py --work-dir work_dirs其中,work_dirs是自己在根目录新建的工作目录,训练文件存储在这里。
注意,此时运行命令之后,并不是直接训练就可以不管了!我们还有参数设置没改!这里输入训练命令,只是需要它生成一个配置文件,便于我们改参数!
打开配置文件 cascade_rcnn_r50_fpn_1x_coco.py :
(1)修改 num_classes ,将其改为自己数据类别(直接全局搜索,有3处,都要改);
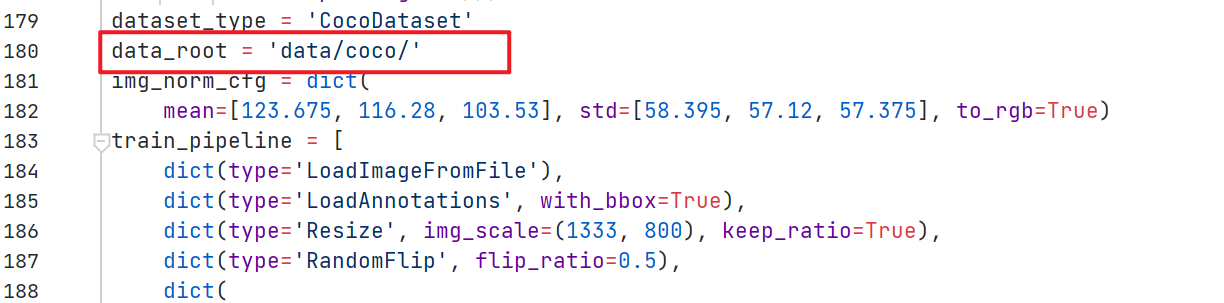
(2)修改 data_root 路径和训练集、验证集、测试集的图片和标签路径,如下图:
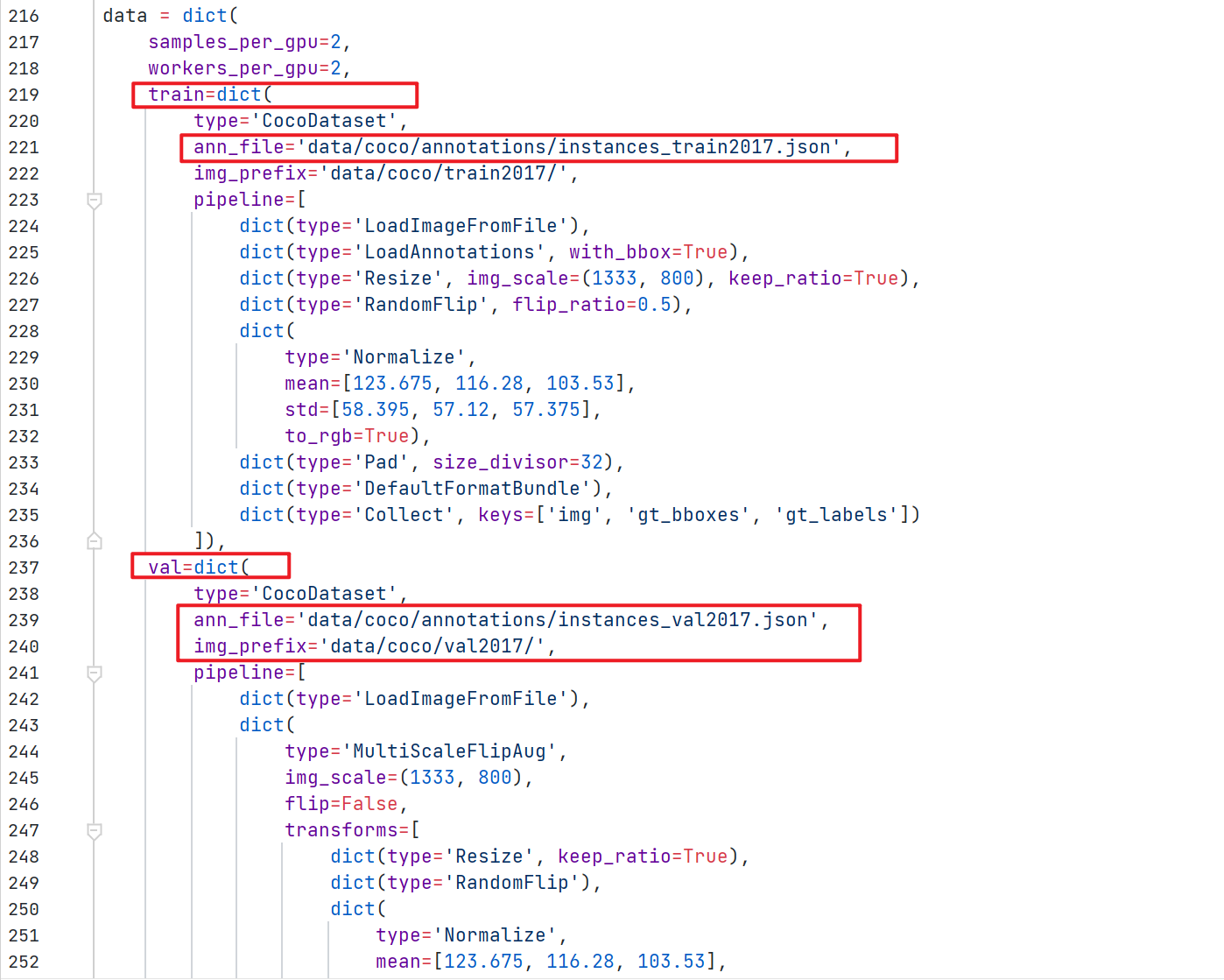
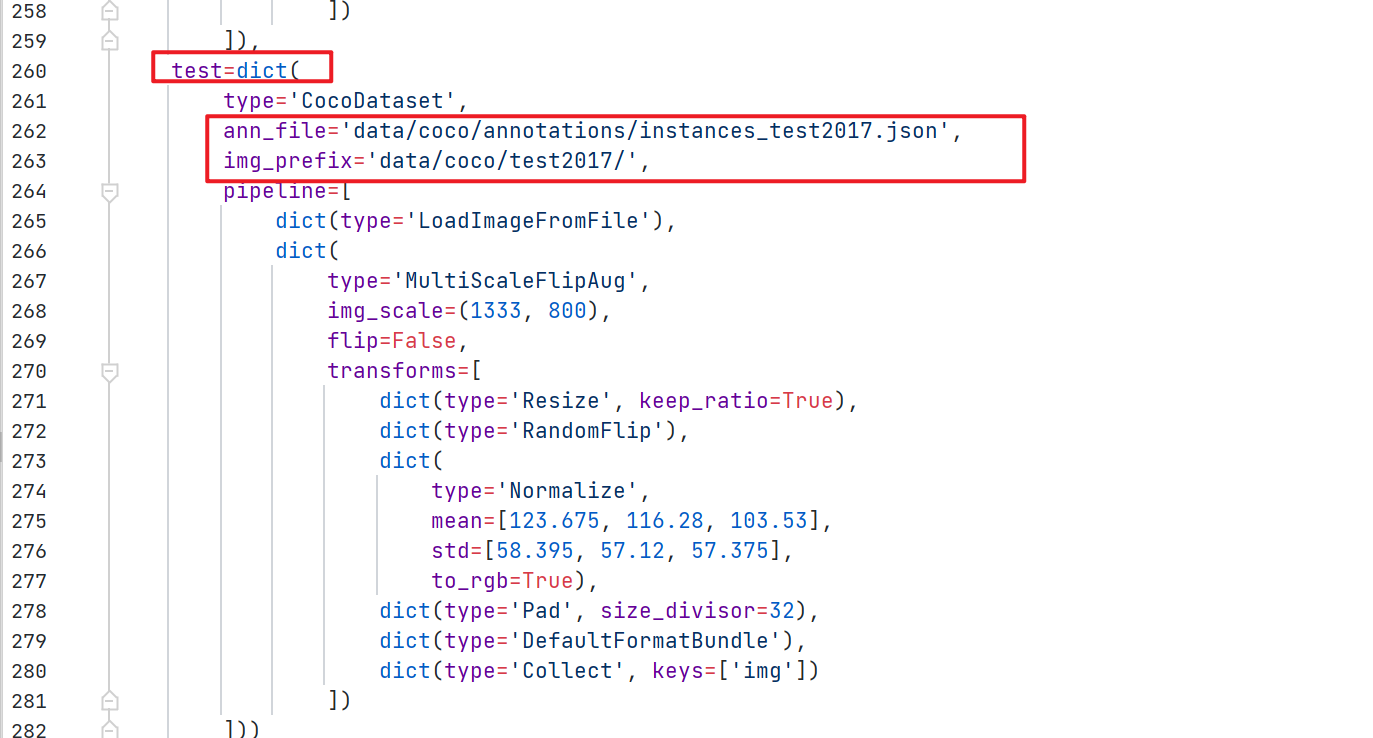
(3)修改训练图片大小和学习率
修改下处代码,可以更改图片大小
img_scale = (1333, 800), batch_size, mmdet默认的方式是由 GPU 数量与 samples_per_gpu 参数决定:
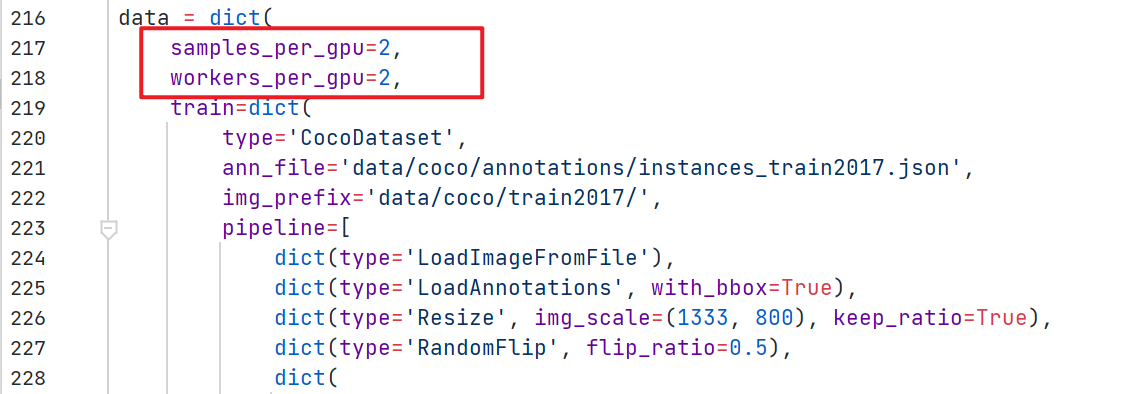
samples_per_gpu: 每个gpu读取的图像数量(意思不就是batch_size=2),该参数和训练时的gpu数量决定了训练时的batch_size。(为什么这么说呢?因为mmdet是8个GPU训练的,那么总的batch就是 8 *samples_per_gpu=16,即训练时是batch_size为16) 。
但我们通常是只有一个gpu, 该参数设置为 2, 意思就是我们训练的 batch_size为2;
workers_per_gpu: 读取数据时每个gpu分配的线程数 ,一般设置为 2即可;(我感觉既然用单个GPU,设置到8也无妨吧?我还没试)
学习率设置:
mmdet 默认的学习率是基于8个gpu,而且默认是1个GPU处理2个图像(就上面说的samples_per_gpu为2),可以这样理解:
8个GPU,每个GPU处理2张图片,那么真实训练总的一个batch就包括16张图片,学习率为0.02;
4个GPU,每个GPU处理2张图片,那么真实训练总的一个batch就包括8张图片,学习率为0.01;
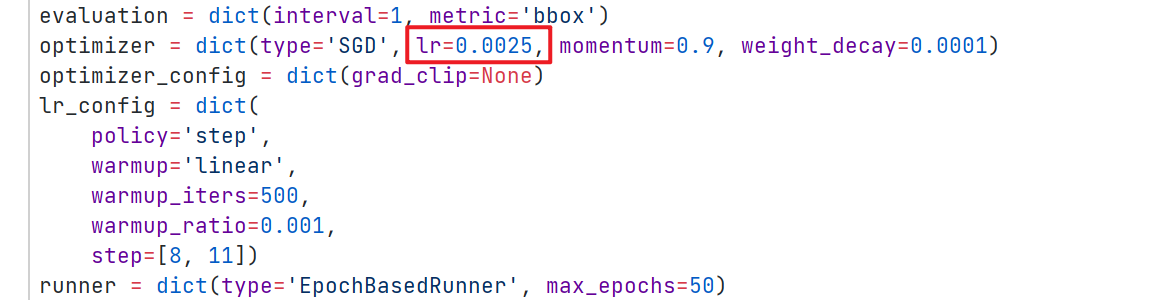
1个GPU,每个GPU处理2张图片,那么真实训练总的一个batch就包括2张图片,学习率为0.0025;
1个GPU,每个GPU处理1张图片,那么真实训练总的一个batch就包括1张图片,学习率为0.00125;
(4)使用预训练模型
提前从github上下载预训练模型,新建一个checkpoints文件夹下,放到里面。(模型下载链接:https://github.com/open-mmlab/mmdetection/blob/master/docs/en/model_zoo.md)
然后修改以下代码:
# 原本是 load_from = None ,修改为load_from = 'checkpoints/fcascade_rcnn_r50_fpn_1x_coco_20200316-3dc56deb.pth’(5)训练轮数,保存模型间隔,日志保存参数
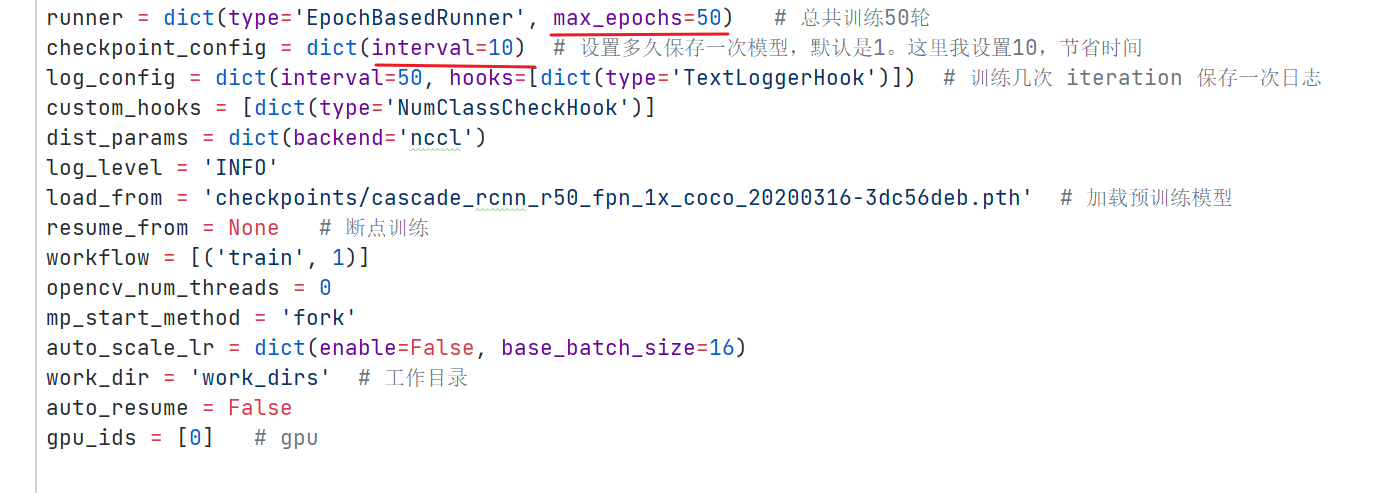
!!!看清楚路径!使用的是更改过的配置文件训练!!!
python tools/train.py work_dirs/cascade_rcnn_r50_fpn_1x_coco.py在第三步生成配置文件时,遇到以下报错:
AssertionError: The num_classes (10) in Shared2FCBBoxHead of
MMDataParallel does not matches the length of CLASSES 80) in
CocoDataset
即使在修改 coco.py 和 class_names.py 后运行 python setup.py install仍然无法解决;
解决方法:
根据报错信息,找到自己虚拟环境的/mmdet/datasets/coco.py和mmdet/core/evaluation/class_names.py,再次修改
CocoDataset()和 coco_classes()l两处(跟第二步一样,其实打开,就能看到虚拟环境下的并没有修改成功)
参考链接:AssertionError: The num_classes (3) in Shared2FCBBoxHead of
MMDataParallel does not
matches
(1)生成中间件
python tools/test.py work_dirs/cascade_rcnn_r50_fpn_1x_coco.py work_dirs/epoch_20.pth --out results.pkl- work_dirs/cascade_rcnn_r50_fpn_1x_coco.py 模型配置文件(跟训练时的一样)
- work_dirs/epoch_20.pth: 训练好的模型(我是训练了20epoch)
--out指定 results.pkl 输出目录,可以自己指定输出目录
(2)使用COCO标准评估指标
python tools/analysis_tools/eval_metric.py work_dirs/cascade_rcnn_r50_fpn_1x_coco.py results.pkl --eval=bbox--eval,COCO数据集可选参数有:bbox 、segm、proposal ;对VOC数据集可选参数有:mAP
(3)使用VOC标准评估指标
# results.pkl 的顺序别放错,在中间。python tools/voc_eval.py results.pkl work_dirs/cascade_rcnn_r50_fpn_1x_coco.py - voc_eval.py 文件 mmdetection 2.X 版本删除了,可以去老版本1.X 找找
(1)使用 test.py 生成 results.bbox.json 文件(在根目录下,路径可自己指定)
python tools/test.py work_dirs/cascade_rcnn_r50_fpn_1x_coco.py work_dirs/epoch_20.pth --format-only --options "jsonfile_prefix=./results"(2)获得COCO bbox错误结果每个类别,保存分析结果图像到目录results/
python tools/analysis_tools/coco_error_analysis.py results.bbox.json results --ann=data/coco/annotations/instances_val2017.json- results.bbox.json:上一步生成的文件
- results: 结果曲线图的生成目录, 此处将生成到results/ 目录下
- –ann=data/coco/annotations/instances_val2017.json: 数据集标注文件存放路径
python tools/analysis_tools/get_flops.py work_dirs/cascade_rcnn_r50_fpn_1x_coco.py --shape 640 640--shape参数指定输入图片尺寸
python tools/analysis_tools/confusion_matrix.py work_dirs/cascade_rcnn_r50_fpn_1x_coco.py results.pkl coco_confusion_matrix/- 需要三个参数,配置文件、pkl文件、输出目录
plot_pr_curve.py 代码来自:https://blog.csdn.net/weixin_44966641/article/details/124558532
import osimport sysimport mmcvimport numpy as npimport argparseimport matplotlib.pyplot as pltfrom pycocotools.coco import COCOfrom pycocotools.cocoeval import COCOevalfrom mmcv import Configfrom mmdet.datasets import build_datasetdef plot_pr_curve(config_file, result_file, out_pic, metric="bbox"): """plot precison-recall curve based on testing results of pkl file. Args: config_file (list[list | tuple]): config file path. result_file (str): pkl file of testing results path. metric (str): Metrics to be evaluated. Options are 'bbox', 'segm'. """ cfg = Config.fromfile(config_file) # turn on test mode of dataset if isinstance(cfg.data.test, dict): cfg.data.test.test_mode = True elif isinstance(cfg.data.test, list): for ds_cfg in cfg.data.test: ds_cfg.test_mode = True # build dataset dataset = build_dataset(cfg.data.test) # load result file in pkl format pkl_results = mmcv.load(result_file) # convert pkl file (list[list | tuple | ndarray]) to json json_results, _ = dataset.format_results(pkl_results) # initialize COCO instance coco = COCO(annotation_file=cfg.data.test.ann_file) coco_gt = coco coco_dt = coco_gt.loadRes(json_results[metric]) # initialize COCOeval instance coco_eval = COCOeval(coco_gt, coco_dt, metric) coco_eval.evaluate() coco_eval.accumulate() coco_eval.summarize() # extract eval data precisions = coco_eval.eval["precision"] ''' precisions[T, R, K, A, M] T: iou thresholds [0.5 : 0.05 : 0.95], idx from 0 to 9 R: recall thresholds [0 : 0.01 : 1], idx from 0 to 100 K: category, idx from 0 to ... A: area range, (all, small, medium, large), idx from 0 to 3 M: max dets, (1, 10, 100), idx from 0 to 2 ''' pr_array1 = precisions[0, :, 0, 0, 2] pr_array2 = precisions[1, :, 0, 0, 2] pr_array3 = precisions[2, :, 0, 0, 2] pr_array4 = precisions[3, :, 0, 0, 2] pr_array5 = precisions[4, :, 0, 0, 2] pr_array6 = precisions[5, :, 0, 0, 2] pr_array7 = precisions[6, :, 0, 0, 2] pr_array8 = precisions[7, :, 0, 0, 2] pr_array9 = precisions[8, :, 0, 0, 2] pr_array10 = precisions[9, :, 0, 0, 2] x = np.arange(0.0, 1.01, 0.01) # plot PR curve plt.plot(x, pr_array1, label="iou=0.5") plt.plot(x, pr_array2, label="iou=0.55") plt.plot(x, pr_array3, label="iou=0.6") plt.plot(x, pr_array4, label="iou=0.65") plt.plot(x, pr_array5, label="iou=0.7") plt.plot(x, pr_array6, label="iou=0.75") plt.plot(x, pr_array7, label="iou=0.8") plt.plot(x, pr_array8, label="iou=0.85") plt.plot(x, pr_array9, label="iou=0.9") plt.plot(x, pr_array10, label="iou=0.95") plt.xlabel("recall") plt.ylabel("precison") plt.xlim(0, 1.0) plt.ylim(0, 1.01) plt.grid(True) plt.legend(loc="lower left") plt.savefig(out_pic)if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument('config', help='config file path') parser.add_argument('pkl_result_file', help='pkl result file path') parser.add_argument('--out', default='pr_curve.png') parser.add_argument('--eval', default='bbox') cfg = parser.parse_args() plot_pr_curve(config_file=cfg.config, result_file=cfg.pkl_result_file, out_pic=cfg.out, metric=cfg.eval)输入命令:
python plot_pr_curve.py work_dirs/cascade_rcnn_r50_fpn_1x_coco.py results.pklpython tools/misc/print_config.py work_dirs/cascade_rcnn_r50_fpn_1x_coco.pypython tools/misc/browse_dataset.py work_dirs/cascade_rcnn_r50_fpn_1x_coco.py --output-dir work_dirs/https://blog.csdn.net/qq_35077107/article/details/124768460?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_44966641/article/details/124558532
来源地址:https://blog.csdn.net/retainenergy/article/details/129907347








