
距离矢量路由算法是这样工作的:每个路由器维护一张路由表(即一个矢量),它以网络中的每个路由器为索引,表中列出了当前已知的路由器到每个目标路由器的最佳距离,以及所使用的线路。通过在邻居之间相互交换信息,路由器不断地更新他们的内部路由表。举例来说,假定使用延迟作为“距离”的度量标准,并且该路由器发送一个列表,其中包含了他到每一个目标路由器的延时估计值;同时,他也从每个邻居路由器接收到一个类似的列表。假设一个路由器接收到来自邻居x的一个列表,其中x(i)表示x估计的到达路由器i所需要的时间。如果该路由器知道他到x的延时为m毫秒,那么他也知道在x(i)+m毫秒之间内经过x可以到达路由器i。一个路由器针对每个邻居都执行这样的计算,就可以发现最佳的估计值,然后在新的路由器表中使用这个最佳的估计值以及对应的输出路线。
现代计算机网络通常使用动态路由算法,因为这类算法能够适应网络的拓扑和流量变化,其中最流行的两种动态路由算法是“距离矢量路由算法”和“链路状态路由算法”。
距离矢量路由算法(Distance Vector Routing,DV)是ARPANET网络上最早使用的路由算法,也称Bellman-Ford路由算法和Ford-Fulkerson算法,主要在RIP(Route Information Protocol)协议中使用。Cisco的IGRP和EIGRP路由协议也是采用DV这种路由算法的。
“距离矢量路由算法”的基本思想如下:每个路由器维护一个距离矢量(通常是以延时是作变量的)表,然后通过相邻路由器之间的距离矢量通告进行距离矢量表的更新。每个距离矢量表项包括两部分:到达目的结点的最佳输出线路,和到达目的结点所需时间或距离,通信子网中的其它每个路由器在表中占据一个表项,并作为该表项的索引。每隔一段时间,路由器会向所有邻居结点发送它到每个目的结点的距离表,同时它也接收每个邻居结点发来的距离表。这样以此类推,经过一段时间后便可将网络中各路由器所获得的距离矢量信息在各路由器上统一起来,这样各路由器只需要查看这个距离矢量表就可以为不同来源分组找到一条最佳的路由。
现假定用延时作为距离的度量,举一个简单的例子,如图7-37所示。假设某个时候路由器Y收到其邻居路由器X的距离矢量,其中m是Y估计到达路由器X的延时。若Y路由器知道它到邻居Z的延时为n,那么它可以得知Z通过Y到达X需要花费时间m+n。如果Z路由器还有其他相邻路由器,则对于从其他每个邻居那儿收到的距离矢量,该路由器执行同样的计算,最后从中选择费时最小的路由作为Z去往X的最佳路由,然后更新其路由表,并通告给其邻居路由器。
如下图距离矢量路由算法简单实例

现以一个如下图所示的示例介绍距离矢量算法中的路由的确定流程,各段链路的延时均已在图中标注。A、B、C、D、E代表五个路由器,假设路由表的传递方向为:A → B → C → D → E(这与路由器启动的先后次序有关)。下面具体的流程。
(1)初始状态下,各路由器都只收集直接相连的链路的延时信息,各路由器结点得出各自的初始矢量表如图7-39所示。因为各结点间还没有交换路由信息,所以它们的初始状态的路由表也如它们的矢量表。
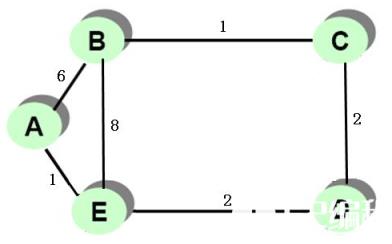
如上图距离矢量算法路由确定示例

如上图初始状态下各结点的矢量表
(2) 现在路由器A把它的路由表发给路由器B。此时它会综合从A路由器发来的路由表和它自己的初始路由表,更新为一个新的矢量表,如图7-40左图所示(最终的矢量表如图中深颜色部分)。从图中可以看出,从B结点到达E结点此时存在两条路径,一条是直达的,一条是通过A结点到达的。而且这两条线的开销不同,经过A结点到达E结点的开销(7)比直达线路的开销(8)更低,所以最终在形成的路由表中,把到达E结点的线路改为经由A结点这条线路,如下图右图所示。
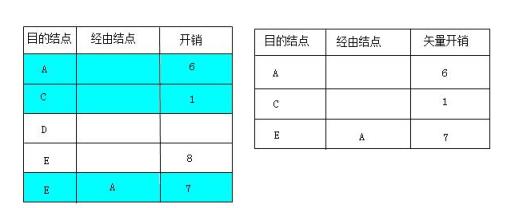
如上图B结点新的矢量表和路由表
(3)B再把最终形成的路由表发给路由器C。同样,路由器C也要把它原来的初始路由表与从B路由器发来的路由表进行综合,形成新的矢量表,如图左图所示(最终的矢量表如图中深颜色部分)。在新的矢量表中,除了最初的直接连接的B和D结点间的矢量外,还新收集了到达A和E结点的矢量信息。因为C结点没有与A和E结点的直接连接,在初始路由表中并没有到达这两个结点的路由信息,所以现在只有采用从B路由器发来的路由表中,经过B结点到达A、E结点的路径。
这里要注意一点,因为在B结点路由表中就已识别了直接通过B结点到达E结点的开销(8)还比依次通过B、A结点到达E结点的开销(7)大,所以在C结点路由表中是采用依次通过B、A结点到达E结点这条路径。最终形成的路由表如下图右图所示。
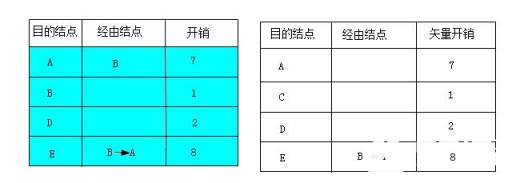
如上图C结点新的矢量表和路由表
(4)路由器 C再把它的最终路由表发给路由器D。同样,路由器D也要把它原来的初始路由表与从C路由器发来的路由表进行综合,形成新的矢量表,如图左图所示(最终的矢量表如图中深颜色部分)。在新的矢量表中,除了最初的直接连接的C和E结点间的矢量信息外,还新收集了到达A和B结点的矢量信息。因为D结点没有与A和B结点的直接连接,所以在其最初的路由表中并没有到达这两个结点的矢量信息,此时仍采用经过C结点到达A和B结点的路径。
在这里同样要注意一点,从D结点到达E结点也有两条路径:一是直接到达,二是依次通过C、B、A结点到达,经过比较发现直接连接到达的开销(2)要比通过C、B、A结点到达E结点路径的开销(10)要小,所以在D结点中,到达E结点是采用直接连接这条线路。最终形成的路由表如图右图所示。
(5)路由器 D再把它的最终路由表发给路由器E。同样,路由器E也要把它原来的初始路由表与从D路由器发来的路由表进行综合,形成新的矢量表,如图7-43左图所示(最终的矢量表如图中深颜色部分)。在新的矢量表中,除了最初的直接连接的A、B和D结点间的矢量外,还新收集了到达C结点的矢量信息,因为E结点没有与C结点的直接连接。此时仍采用经过D结点到达C结点的路径。
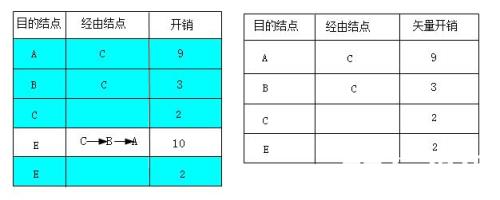
如上图D结点新的矢量表和路由表
在这里有两个要注意的地方:一是从E结点到达A结点的路径问题,因为此时E结点与A结点是直接连接的,而且其开销(1)要比原来从D路由口器发来的路由表中提供的通过D、C、B结点到达A结点路径开销(11)要小,所以在最终的E结点路由表中,到达A结点是采用直接连接这条线路。二是E结点虽然也是与B结点直接连接,但它的开销(8)还要比原来从D路由器发来的路由表中提供的依次经过D、C这两个结点到达B结点的开销(5)大,所以在最终的E结点路由表中,到达B结点是采用依次经过D、C两个结点这条路径。最终形成的路由表如图右图所示。
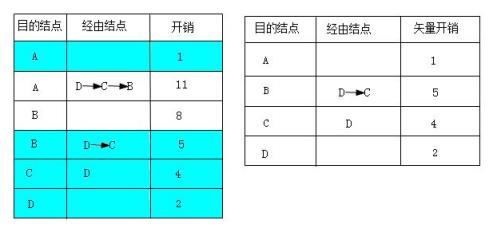
如上图E结点新的矢量表和路由表
通过以上步骤,网络中各路由器就完整了整个路由表的确定,当然在拓扑结构发生变化时,各路由器的路由表又会发生变化,重新进行更新。
当形成环路或者有一些路由器连接断裂时,就会产生无穷计算问题
为了避免无穷计算,RIP协议规定路由的最大METRIC为15跳,大于15跳表示网络不可达。这种规定限制的RIP的应用范围, 它只能适用于中小网络,网络规模太大路由信息就无法到达远端的路由器了。
同时, RIP协议在实现中还使用了带毒性逆转的水平分割技术。
所谓水平分割是指从某一个邻居获得的路由信息不再向这个邻居发送回去。
而毒性逆转则是将这样的路由信息METRIC置为无穷大,大于或等于16 在发送回去。
这两种措施都是为了让路由器不收到从自己发送出去的循环路由而产生错误路由,保持法,将不可达的路由信息在路由表中保持一段时间,以尽可能的扩展最坏情况
毒性逆转是指发出一条路由,路由的METRIC为无穷大(16跳),作用是通知别的路由器,这条路由已经不可达了。
距离矢量算法(我们简称它为DV,而链路路由算法我们简称为LS)是一种迭代的、异步的、分布式的算法。首先,说它是迭代的,是因为这个过程一直要持续到邻居之间没有更多信息需要交换为止。其次,说它是异步的,是因为不需要所有路由器同步一致地进行操作。最后,说它是分布式的,是因为每个结点都要从它的邻居接受信息,同时也要发送信息给它的邻居。并且每个结点需要知道的只是它的邻居的信息,而不需要了解整个网络的拓扑等信息。
在真正学习DV算法之前,我们需要了解一个很著名的方程,因为DV算法就是利用这个方程在不断更新每个路由表的信息的。这个方程叫做Bellman-Ford方程:
dx(y)= minv { c(x,v)+ dv(y)}
dx(y)表示结点x到结点y的最低费用路径所需要花费的费用,v是x的邻居结点,c(x,v)表示x到v的直接费用,dv(y)表示结点v到结点y的最低费用路径所需要花费的费用。
好处:收到一条坏消息好过没有收到任何消息,也就是有消息好过没有消息。可以取代保持机制来加快路由收敛。
坏处:过多地浪费了链路的带宽,增大了路由表的大小。
结论:通常情况下,不提倡使用,因为会增大路由表,浪费链路带宽。
水平分割也有二种:普通水平分割和带毒性逆转的水平分割。
普通水平分割:从一个接口收到的路由不会再从这个接口泛洪出去。
带毒性逆转的水平分割:从一个接口收到的路由,会从这个接口泛洪出去,但这条路由的METRIC是无穷大。
相信最后大家阅读完毕本篇文章后,学到了不少知识吧?大家私下还得多自学才能了解到更多的知识,当然如果大家还想要了解更多相关方面的详细内容的话呢,请登录编程学习网教育平台咨询哟~












