
今天小编给大家分享一下nonebot插件之chatgpt如何使用的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。
准备
1.获取开发者key
获取key的地址:Account API Keys - OpenAI API
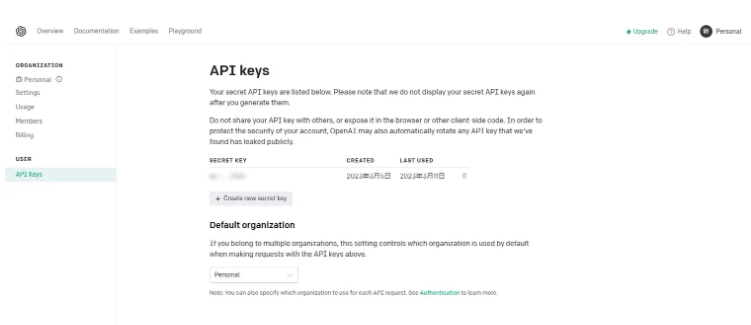
如图所示,我已经创建好一个key了,大家也可以点击Create new secret key按钮来创建一个新的key,注意,千万不要泄露自己的key哦
2.魔法
在获取key的过程我们还是需要用到魔法的,且代理必须为国外的,只要key搞到手,后续的步骤就不用用到魔法了
开始
1.找接口
之前我原本是想要教大家去对接OpenAI的官方接口的,但是想到大部分同学可能不会“魔法”,如果没有“魔法”体验感会大打折扣,所以我们就要借助其他大佬帮助我们完成代理这个过程
在网上冲浪的时候,我发现了这个宝藏网站 GPT3.5 (cutim.top)
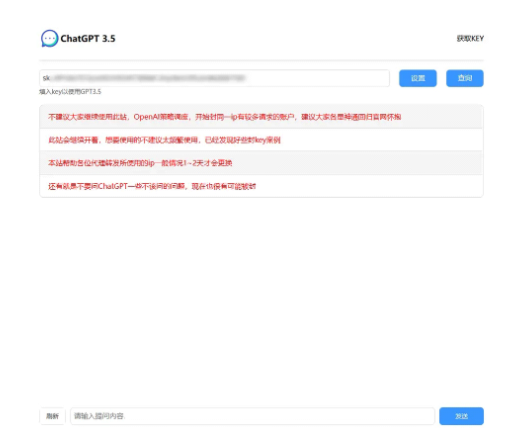
可以看到这个网站是需要我们提供key的,我这里浅浅解释一下本次程序的主要思路
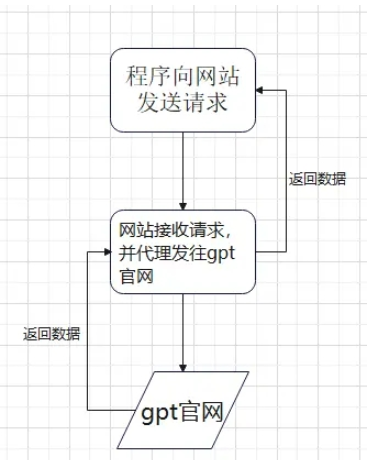
整体思路大概就是这样
到这里,大家应该都有key了吧,我们打开刚才的网站,按F12打开开发者调试工具
在这里我们可以看到请求的api地址: gpt.cutim.top/question
我们可以看到他是post请求
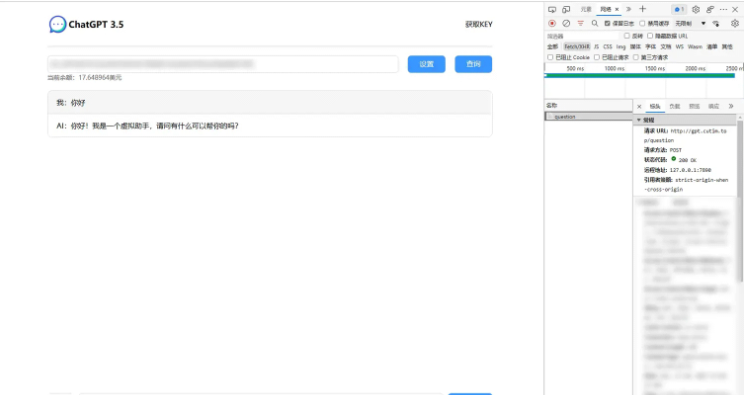
那么我们打开源分析,不难看出数据就是json格式,且有两个参数,一个key,一个question

既然我们已经找到接口了,那么下一步就是重头戏——写代码了
2.快乐的敲代码
先上猛料
from nonebot import on_keywordfrom nonebot.typing import T_Statefrom nonebot.adapters.onebot.v11 import GroupMessageEvent, Bot, Messageimport httpximport json'''实现qq群聊调用chatgptwrite by 萌新源 at 2023/3/5'''chatgpt = on_keyword({"#gpt"})@chatgpt.handle()async def yy(bot: Bot, event: GroupMessageEvent, state: T_State): get_msg = str(event.message).strip() # 获取用户发送的链接 user_question = get_msg.strip("#gpt") msg_id = event.message_id # 获取消息id user_id = event.user_id file_name = "chatgpt.json" try: with open(file_name, "r", encoding="UTF-8") as f: person_data = json.load(f) # 读取数据 try: user_data = person_data[str(user_id)] except KeyError: user_data = "" form_data = {'key': '填写你自己的key', 'question': user_data + f"----{user_question}"} async with httpx.AsyncClient() as client: headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE' } url = f"http://gpt.cutim.top/question" data = await client.post(url=url, headers=headers, json=form_data, timeout=None) # 请求数据 response = data.json() try: # 规避内容获取失败 res_ai = str(response['content']) try: user_data = person_data[str(user_id)] + f"----{user_question}" question = user_data + f'\n{res_ai}' person_data[str(user_id)] = question except KeyError: person_data[str(user_id)] = f'----{user_question}' with open(file_name, "w", encoding="UTF-8") as f: json.dump(person_data, f, ensure_ascii=False) ai_res = str(response['content']).strip("\n") except KeyError: # 重置会话 person_data[user_id] = "" with open(file_name, "w", encoding="UTF-8") as f: json.dump(person_data, f, ensure_ascii=False) ai_res = '很抱歉,内容获取失败,请确认您的问题没有非法成分,如没有可能是您的会话历史已达到上限,请更换您的提问方式或再试一次' except FileNotFoundError: with open(file_name, "w", encoding="UTF-8") as f: json.dump({user_id: f'----{user_question}'}, f, ensure_ascii=False) form_data = {'key': '填写你自己的key', 'question': user_question} async with httpx.AsyncClient() as client: headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE' } url = f"http://gpt.cutim.top/question" data = await client.post(url=url, headers=headers, json=form_data, timeout=None) # 请求数据 response = data.json() ai_res = str(response['content']).strip("\n") res = f"[CQ:reply,id={msg_id}]{ai_res}" await chatgpt.send(Message(res))这里我也是直接上全部代码
接下来我挑一些我认为比较有研究价值的代码出来讲讲
try: with open(file_name, "r", encoding="UTF-8") as f: #① person_data = json.load(f) # 读取数据 try: user_data = person_data[str(user_id)] except KeyError: user_data = "" form_data = {'key': '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', 'question': user_data + f"----{user_question}"}比如这一段,在①这个地方,我读取了一个用来储存用户会话的json文件,那么可能有人会问了,为什么要读取这样一个文件呢?或者说这个文件有什么作用?
其实在早期版本没有会话文件的时候,经过群友的测试,我发现了一个小问题,那就是对话不连续,比如说我要跟gpt玩成语接龙,但是会话是不连续的呀,于是我就找到了用一个文件储存用户会话的方法,文件结构大概是这样

就是把每个人的会话数据分别储存起来,这样对话就有了连续性
连续性问题是解决了,但是又产生了一个新的问题——会话太长,gpt不知道怎么回答或者说是无法正常获取内容,那又怎么办,于是我想到了下面的方法来解决这个问题
try: # 规避内容获取失败 res_ai = str(response['content']) try: user_data = person_data[str(user_id)] + f"----{user_question}" question = user_data + f'\n{res_ai}' person_data[str(user_id)] = question except KeyError: person_data[str(user_id)] = f'----{user_question}' with open(file_name, "w", encoding="UTF-8") as f: json.dump(person_data, f, ensure_ascii=False) ai_res = str(response['content']).strip("\n")except KeyError: # 重置会话 person_data[user_id] = "" with open(file_name, "w", encoding="UTF-8") as f: json.dump(person_data, f, ensure_ascii=False) ai_res = '很抱歉,内容获取失败,请确认您的问题没有非法成分,如没有可能是您的会话历史已达到上限,请更换您的提问方式或再试一次'可以看到,我这里写了个try语句,当获取内容失败的时候就把会话清空,并且返回一个提示信息给用户,好让用户重新提问。
以上就是“nonebot插件之chatgpt如何使用”这篇文章的所有内容,感谢各位的阅读!相信大家阅读完这篇文章都有很大的收获,小编每天都会为大家更新不同的知识,如果还想学习更多的知识,请关注编程网行业资讯频道。







