
玩爬虫的都避免不了各大网站的反爬措施限制,比较常见的是通过固定时间检测某ip地址访问量来判断该用户是否为 “网络机器人”,也就是所谓的爬虫,如果被识别到,就面临被封ip的风险,那样你就不能访问该网址了。
通用的解决办法是用代理ip进行爬取,但是收费的代理ip一般都是比较贵的,网上倒是有很多免费的代理ip网站,但是受时效性影响,大部分地址都不能用,有很多维护代理ip池的教程,即把爬取并检测后能用代理ip放到“代理池里”,等以后要用的时候再从里面提取,在我看来,这种效率比较低,因为这类IP地址很快就失效,我们要做的是边检测边使用,充分保证免费IP的时效性。
二.抓取IP地址
下面就开始实战操作。
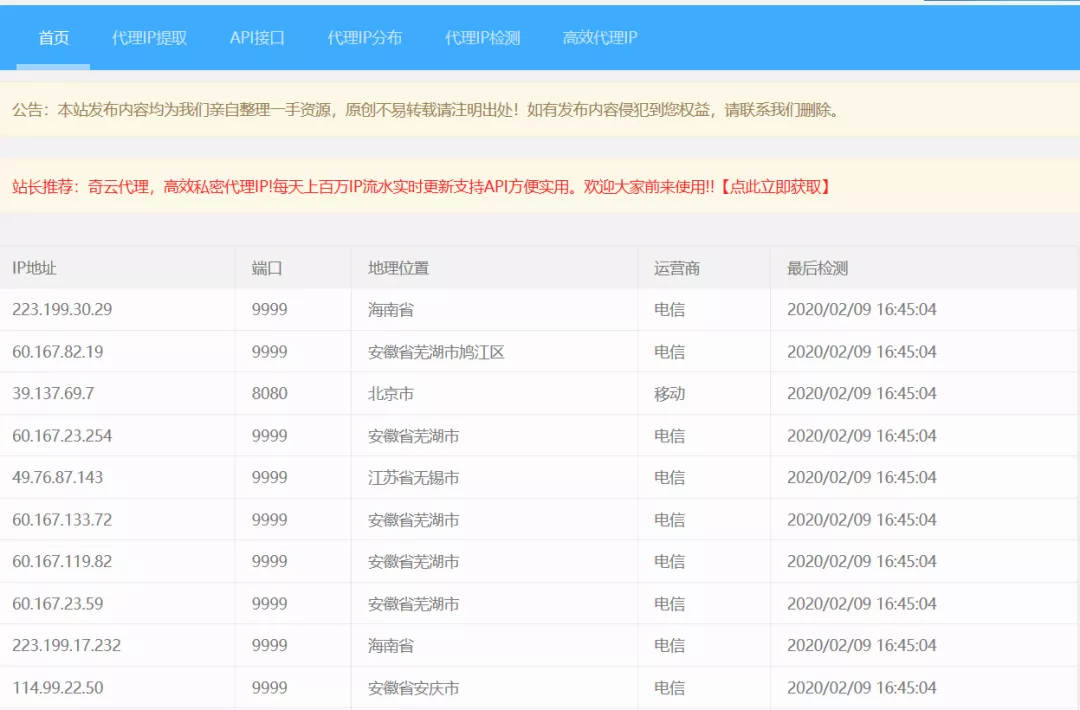
首先我们随便找一个免费代理ip网站,如下图所示。
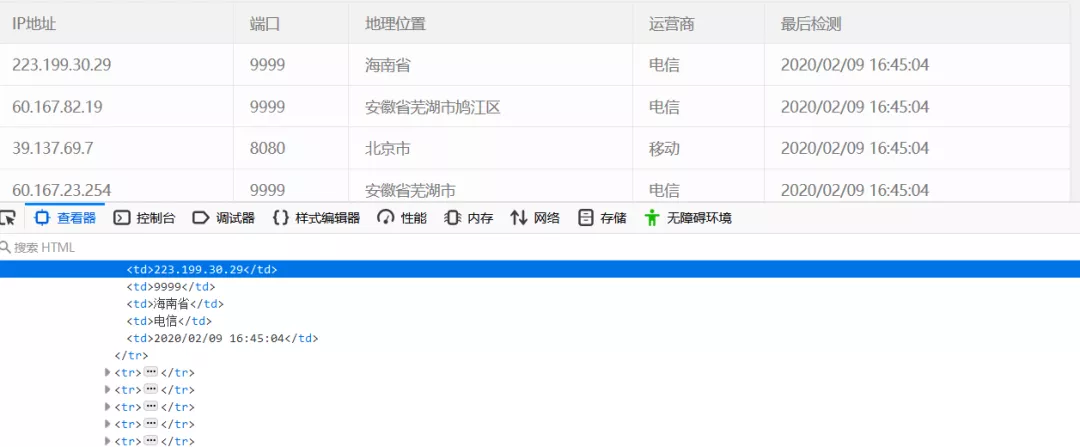
打开网页查看器,分析其网页元素结构,如下图所示。
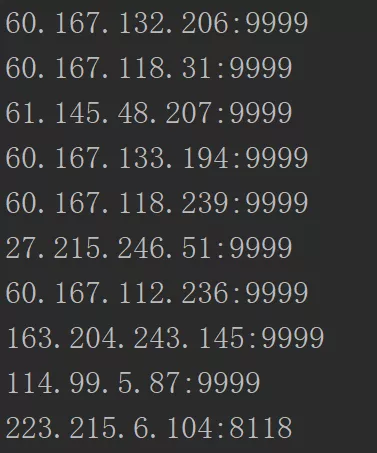
就是一个简单的静态网页,我们用requests和bs4将ip地址和对应端口爬下,如下图所示。
每一行ip地址都由5个标签组成,而我们需要的是第一个标签(对应IP地址)和第2个标签(对应端口),所以从第一个开始,每隔5个取出ip地址(item[::5]),从第二个开始,每隔5个取出对应端口(item[1::5]),参数n为页码,每次只在1页取1个有用的ip地址,最终效果如下图所示:
三.验证IP有效性
这里把百度百科作为目标网站,这个看似很普通的网站,反爬措施却极为严格,爬不了几条内容就开始请求失败了,下面我以在百度百科查询全国火车站归属地信息为例演示如何使用免费代理ip。
首先我在12306上把所有的火车站名都爬下来了,但是没有归属地信息。
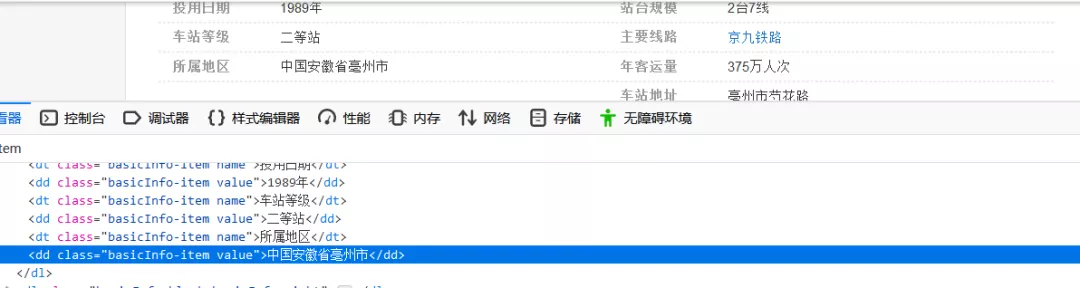
然后以站名构造百度百科url信息,分析网页元素,把爬取爬取火车站地址信息,网页元素如下图所示:
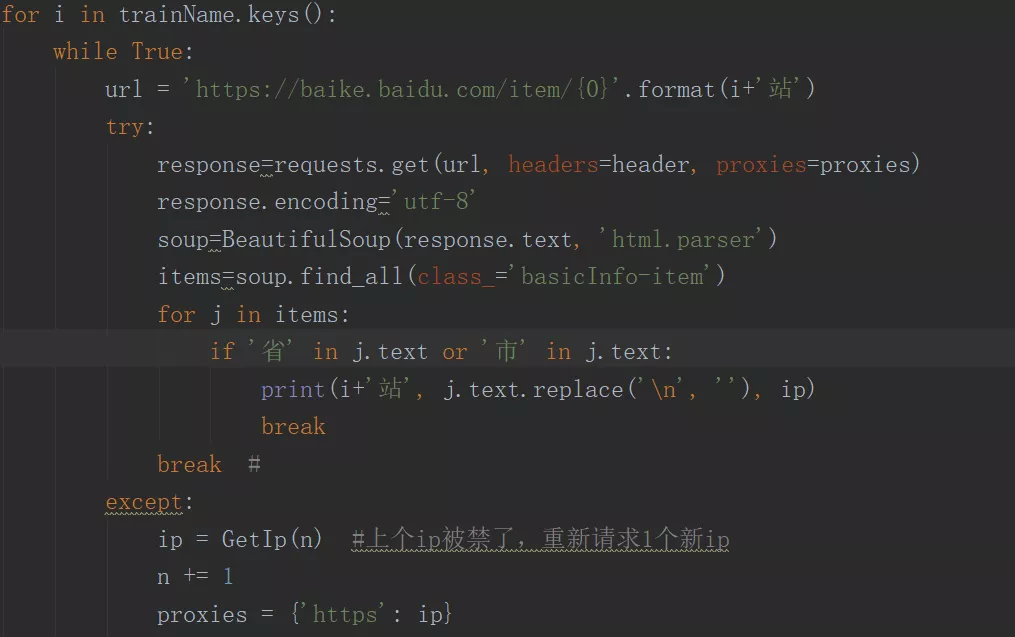
所以,我们只需在class_='basicInfo-item'的标签内容里查找有无“省”或者“市”的字符,然后输出就行了,最后加一个while True循环,当该ip能正常爬数据时,则break该循环;若该ip被禁,则马上重新请求一个新ip进行爬取。直接上代码如下图所示:
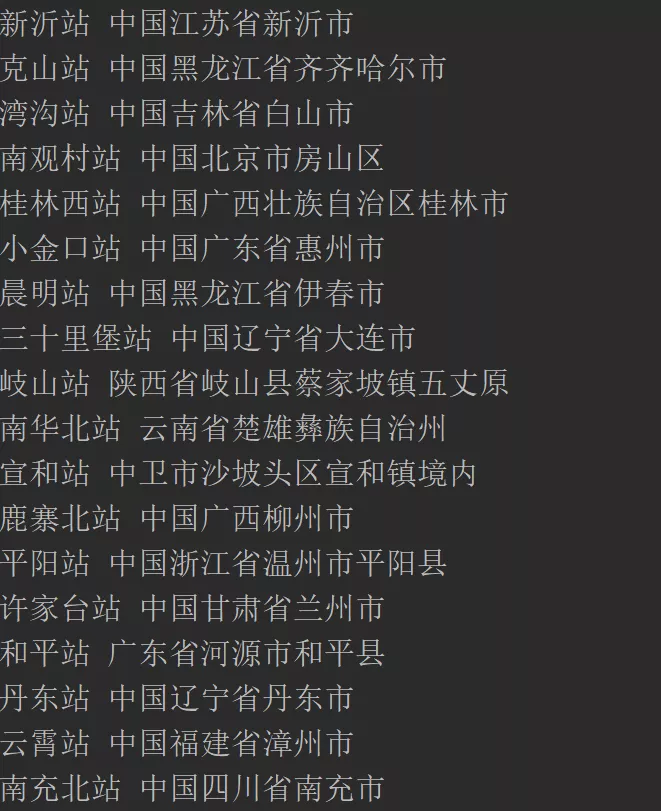
其中for循环是遍历所有火车站,try是用于检测该ip还能不能用,若不能,则在except里请求1个新ip,爬取效果如下图所示:
下次再遇到爬虫被禁的情况就可以用此办法解决了。
四.结语
本文基于Python网络爬虫技术,主要介绍了去IP代理网站上抓取可用IP,并且Python脚本实现验证IP地址的时效性,如遇到爬虫被禁的情况就可以用本文的办法进行解决。








![[[317798]]](https://s5.51cto.com/oss/202003/08/ffae1ead8716af1a678feb79037b8a58.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}