
【Python_Pandas】reset_index函数解析
文章目录
1. 介绍
pandas.DataFrame.reset_index
reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')1)函数作用:
- 重置索引或其level。
- 重置数据帧的索引,并使用默认索引。如果数据帧具有多重索引,则此方法可以删除一个或多个level。
2)参数:
- drop: 重新设置索引后是否将原索引作为新的一列并入DataFrame,默认为False
- inplace: 是否在原DataFrame上改动,默认为False
- level: 如果索引(index)有多个列,仅从索引中删除level指定的列,默认删除所有列
- col_level: 如果列名(columns)有多个级别,决定被删除的索引将插入哪个级别,默认插入第一级
- col_fill: 如果列名(columns)有多个级别,决定其他级别如何命名
3)返回
- DataFrame or None。具有新索引的数据帧,如果inplace=True,则无索引。
2. 示例
2.1 参数drop
- False:表示重新设置索引后,将原索引作为新的一列并入DataFrame,
- True:表示删除原索引
import pandas as pdimport numpy as npdf = pd.DataFrame([('bird', 389.0), ('bird', 24.0), ('mammal', 80.5), ('mammal', np.nan)], index=['falcon', 'parrot', 'lion', 'monkey'], columns=('class', 'max_speed'))print(df)print('\n')df1 = df.reset_index()print(df1)print('\n')df2 = df.reset_index(drop=True)print(df2)- 输出:
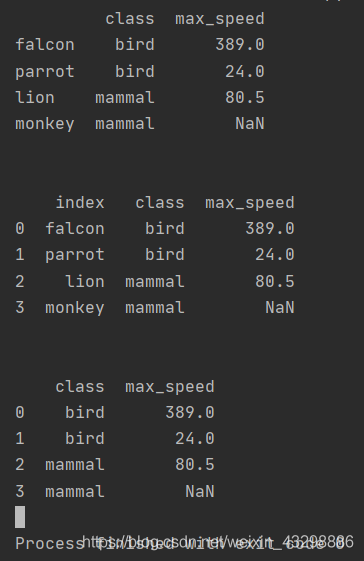
2.2 参数inplace
- True表示:在原DataFrame上修改,返回为None
- False:将修改后的DataFrame作为新的对象返回
import pandas as pdimport numpy as npdf = pd.DataFrame([('bird', 389.0), ('bird', 24.0), ('mammal', 80.5), ('mammal', np.nan)], index=['falcon', 'parrot', 'lion', 'monkey'], columns=('class', 'max_speed'))print(df)print('\n')df1 = df.reset_index()print(df1)print('\n')df2 = df.reset_index(inplace=True)print(df2)print('\n')print(df)- 输出:
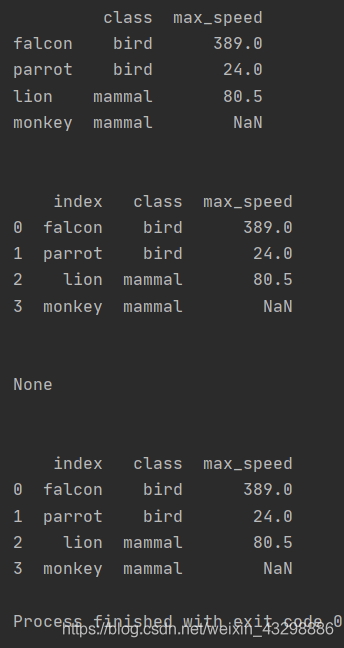
2.3 参数level
如果索引有多个列,仅从索引中删除由level指定的列,默认删除所有列。
- 输入整数时表示将index的names中下标为level的索引删除;
- 输入为字符串时表示将名字为level的索引删除
import pandas as pdimport numpy as npindex = pd.MultiIndex.from_tuples([('bird', 'falcon'), ('bird', 'parrot'), ('mammal', 'lion'), ('mammal', 'monkey')], names=['class', 'name'])columns = pd.MultiIndex.from_tuples([('speed', 'max'), ('species', 'type')])df = pd.DataFrame([(389.0, 'fly'), ( 24.0, 'fly'), ( 80.5, 'run'), (np.nan, 'jump')], index=index, columns=columns)print(df)print('\n')df0 = df.reset_index()print(df0)print('\n')df1 = df.reset_index(level=1)print(df1)print('\n')df2 = df.reset_index(level='name')print(df2)- 输出:

2.4 参数col_level
如果列名(columns)有多个级别,决定被删除的索引将插入哪个级别,默认插入第一级(col_level=0)
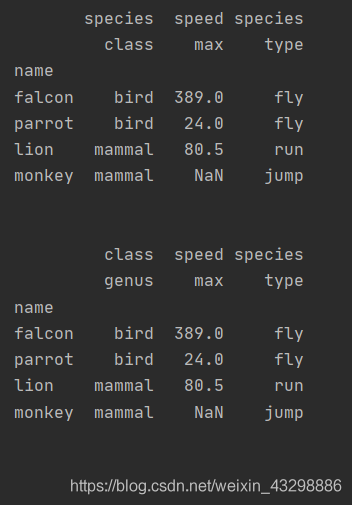
import pandas as pdimport numpy as npindex = pd.MultiIndex.from_tuples([('bird', 'falcon'), ('bird', 'parrot'), ('mammal', 'lion'), ('mammal', 'monkey')], names=['class', 'name'])columns = pd.MultiIndex.from_tuples([('speed', 'max'), ('species', 'type')])df = pd.DataFrame([(389.0, 'fly'), ( 24.0, 'fly'), ( 80.5, 'run'), (np.nan, 'jump')], index=index, columns=columns)print(df)print('\n')df1 = df.reset_index(level=0, col_level=0)print(df1)print('\n')df2 = df.reset_index(level=0, col_level=1)print(df2)print('\n')- 输出:
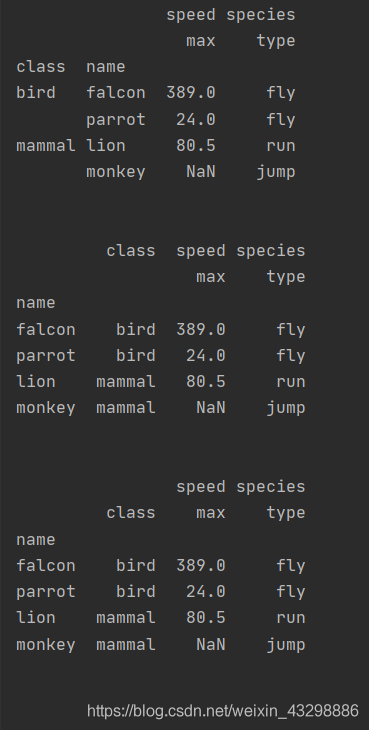
2.5 参数col_fill
重置索引时被删除的索引只能插入一个级别,
- 如果列名(columns)有多个级别,那么这个列的列名的其他级别如何命名就由col_fill决定,默认不做填充,
- 如果传入None则用被删除的索引的名字填充
import pandas as pdimport numpy as npindex = pd.MultiIndex.from_tuples([('bird', 'falcon'), ('bird', 'parrot'), ('mammal', 'lion'), ('mammal', 'monkey')], names=['class', 'name'])columns = pd.MultiIndex.from_tuples([('speed', 'max'), ('species', 'type')])df = pd.DataFrame([(389.0, 'fly'), ( 24.0, 'fly'), ( 80.5, 'run'), (np.nan, 'jump')], index=index, columns=columns)print(df)print('\n')df0 = df.reset_index(level=0, col_level=0)print(df0)print('\n')df1 = df.reset_index(level=0, col_level=0, col_fill=None)print(df1)print('\n')df2 = df.reset_index(level=0, col_level=1, col_fill='species')print(df2)print('\n')df3 = df.reset_index(level=0, col_level=0, col_fill='genus')print(df3)print('\n')- 输出:
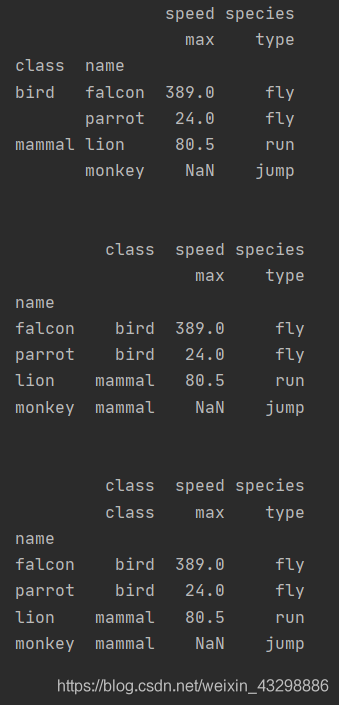
参考
【1】https://blog.csdn.net/weixin_43298886/article/details/108090189
来源地址:https://blog.csdn.net/qq_51392112/article/details/130669791








