
这期内容当中小编将会给大家带来有关如何解析Kafka中的时间轮问题,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
写在前面
kafka是一个分布式消息中间件,其高可用高吞吐的特点是大数据领域首选的消息中间件,Kafka是分布式消息队列的顺序读写文件分段组织串联起来思想的鼻祖,包括RocketMq这些消息队列都是借鉴了Kafka早期的架构和设计思路改造而来,所以在架构设计层面,Kafka有非常多值得借鉴的地方。PS:执行流程和代码来自Kafka0.10.2版本。
引子:
从2个面试题说起,第1个问题,如果一台机器上有10w个定时任务,如何做到高效触发?
具体场景是:
有一个APP实时消息通道系统,对每个用户会维护一个APP到服务器的TCP连接,用来实时收发消息,对这个TCP连接,有这样一个需求:“如果连续30s没有请求包(例如登录,消息,keepalive包),服务端就要将这个用户的状态置为离线”。
其中,单机TCP同时在线量约在10w级别,keepalive请求包较分散大概30s一次,吞吐量约在3000qps。
怎么做?
常用方案使用time定时任务,每秒扫描一次所有连接的集合Map<uid, last_packet_time>,把连接时间(每次有新的请求更新对应连接的连接时间)比当前时间的差值大30s的连接找出来处理。
另一种方案,使用环形队列法:
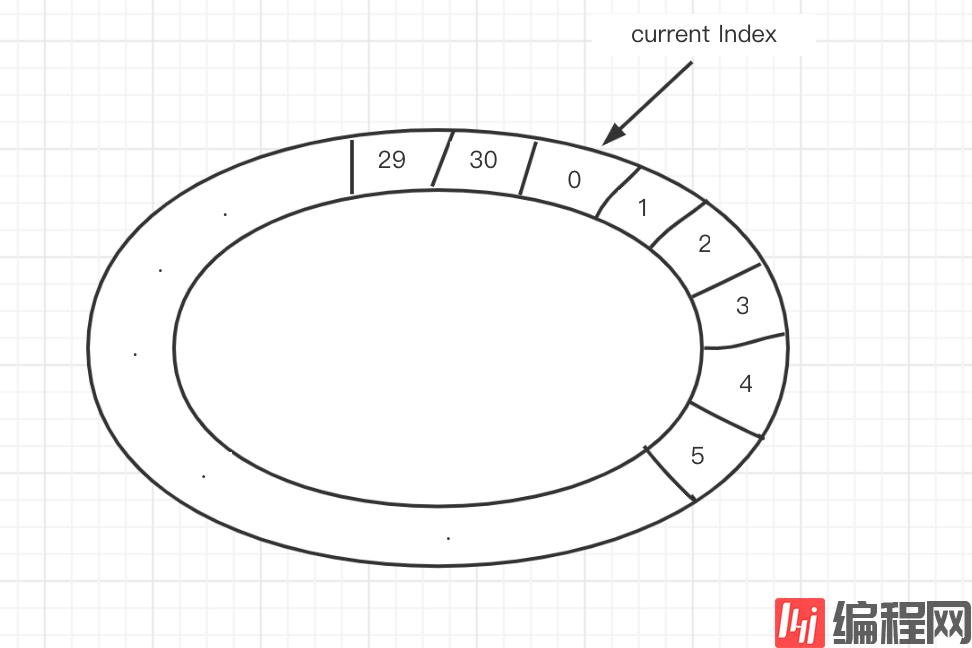
(图1)
三个重要的数据结构:
1)30s超时,就创建一个index从0到30的环形队列(本质是个数组)
2)环上每一个slot是一个Set<uid>,任务集合
3)同时还有一个Map<uid, index>,记录uid落在环上的哪个slot里
这样当有某用户uid有请求包到达时:
1)从Map结构中,查找出这个uid存储在哪一个slot里
2)从这个slot的Set结构中,删除这个uid
3)将uid重新加入到新的slot中,具体是哪一个slot呢 => Current Index指针所指向的上一个slot,因为这个slot,会被timer在30s之后扫描到
4)更新Map,这个uid对应slot的index值
哪些元素会被超时掉呢?
Current Index每秒种移动一个slot,这个slot对应的Set<uid>中所有uid都应该被集体超时!如果最近30s有请求包来到,一定被放到Current Index的前一个slot了,Current Index所在的slot对应Set中所有元素,都是最近30s没有请求包来到的。
所以,当没有超时时,Current Index扫到的每一个slot的Set中应该都没有元素。
两种方案对比:
方案一每次都要轮询所有数据,而方案二使用环形队列只需要轮询这一刻需要过期的数据,如果没有数据过期则没有数据要处理,并且是批量超时,并且由于是环形结构更加节约空间,这很适合高性能场景。
第二个问题:在开发过程中有延迟一定时间的任务要执行,怎么做?
如果不重复造轮子的话,我们的选择当然是延迟队列或者Timer。
延迟队列和在Timer中增 加延时任务采用数组表示的最小堆的数据结构实现,每次放入新元素和移除队首元素时间复杂度为O(nlog(n))。
时间轮
方案二所采用的环形队列,就是时间轮的底层数据结构,它能够让需要处理的数据(任务的抽象)集中,在Kafka中存在大量的延迟操作,比如延迟生产、延迟拉取以及延迟删除等。Kafka并没有使用JDK自带的Timer或者DelayQueue来实现延迟的功能,而是基于时间轮自定义了一个用于实现延迟功能的定时器(SystemTimer)。JDK的Timer和DelayQueue插入和删除操作的平均时间复杂度为O(nlog(n)),并不能满足Kafka的高性能要求,而基于时间轮可以将插入和删除操作的时间复杂度都降为O(1)。时间轮的应用并非Kafka独有,其应用场景还有很多,在Netty、Akka、Quartz、Zookeeper等组件中都存在时间轮的踪影。
时间轮的数据结构
参考下图,Kafka中的时间轮(TimingWheel)是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList)。TimerTaskList是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务TimerTask。在Kafka源码中对这个TimeTaskList是用一个名称为buckets的数组表示的,所以后面介绍中可能TimerTaskList也会被称为bucket。

(图2:图片来源于《Kafka解惑之时间轮(TimingWheel)》)
针对上图的几个名词简单解释下:
tickMs:时间轮由多个时间格组成,每个时间格就是tickMs,它代表当前时间轮的基本时间跨度。
wheelSize:代表每一层时间轮的格数
interval:当前时间轮的总体时间跨度,interval=tickMs × wheelSize
startMs:构造当层时间轮时候的当前时间,第一层的时间轮的startMs是TimeUnit.NANOSECONDS.toMillis(nanoseconds()),上层时间轮的startMs为下层时间轮的currentTime。
currentTime:表示时间轮当前所处的时间,currentTime是tickMs的整数倍(通过currentTime=startMs - (startMs % tickMs来保正currentTime一定是tickMs的整数倍),这个运算类比钟表中分钟里65秒分钟指针指向的还是1分钟)。currentTime可以将整个时间轮划分为到期部分和未到期部分,currentTime当前指向的时间格也属于到期部分,表示刚好到期,需要处理此时间格所对应的TimerTaskList的所有任务。
时间轮中的任务存放
若时间轮的tickMs=1ms,wheelSize=20,那么可以计算得出interval为20ms。初始情况下表盘指针currentTime指向时间格0,此时有一个定时为2ms的任务插入进来会存放到时间格为2的TimerTaskList中。随着时间的不断推移,指针currentTime不断向前推进,过了2ms之后,当到达时间格2时,就需要将时间格2所对应的TimeTaskList中的任务做相应的到期操作。此时若又有一个定时为8ms的任务插入进来,则会存放到时间格10中,currentTime再过8ms后会指向时间格10。如果同时有一个定时为19ms的任务插入进来怎么办?新来的TimerTaskEntry会复用原来的TimerTaskList,所以它会插入到原本已经到期的时间格1中。总之,整个时间轮的总体跨度是不变的,随着指针currentTime的不断推进,当前时间轮所能处理的时间段也在不断后移,总体时间范围在currentTime和currentTime+interval之间。
时间轮的升降级
如果此时有个定时为350ms的任务该如何处理?直接扩充wheelSize的大小么?Kafka中不乏几万甚至几十万毫秒的定时任务,这个wheelSize的扩充没有底线,就算将所有的定时任务的到期时间都设定一个上限,比如100万毫秒,那么这个wheelSize为100万毫秒的时间轮不仅占用很大的内存空间,而且效率也会拉低。Kafka为此引入了层级时间轮的概念,当任务的到期时间超过了当前时间轮所表示的时间范围时,就会尝试添加到上层时间轮中

(图3:图片来源于《Kafka解惑之时间轮(TimingWheel)》)
参考上图,复用之前的案例,第一层的时间轮tickMs=1ms, wheelSize=20, interval=20ms。第二层的时间轮的tickMs为第一层时间轮的interval,即为20ms。每一层时间轮的wheelSize是固定的,都是20,那么第二层的时间轮的总体时间跨度interval为400ms。以此类推,这个400ms也是第三层的tickMs的大小,第三层的时间轮的总体时间跨度为8000ms。
刚才提到的350ms的任务,不会插入到第一层时间轮,会插入到interval=20*20的第二层时间轮中,具体插入到时间轮的哪个bucket呢?先用350/tickMs(20)=virtualId(17),然后virtualId(17) %wheelSize (20) = 17,所以350会放在第17个bucket。如果此时有一个450ms后执行的任务,那么会放在第三层时间轮中,按照刚才的计算公式,会放在第0个bucket。第0个bucket里会包含
[400,800)ms的任务。随着时间流逝,当时间过去了400ms,那么450ms后就要执行的任务还剩下50ms的时间才能执行,此时有一个时间轮降级的操作,将50ms任务重新提交到层级时间轮中,那么此时50ms的任务根据公式会放入第二个时间轮的第2个bucket中,此bucket的时间范围为[40,60)ms,然后再经过40ms,这个50ms的任务又会被监控到,此时距离任务执行还有10ms,同样将10ms的任务提交到层级时间轮,此时会加入到第一层时间轮的第10个bucket,所以再经过10ms后,此任务到期,最终执行。
整个时间轮的升级降级操作是不是很类似于我们的时钟? 第一层时间轮tickMs=1s, wheelSize=60,interval=1min,此为秒钟;第二层tickMs=1min,wheelSize=60,interval=1hour,此为分钟;第三层tickMs=1hour,wheelSize为12,interval为12hours,此为时钟。而钟表的指针就对应程序中的currentTime,这个后面分析代码时候会讲到(对这个的理解也是时间轮理解的重点和难点)。
任务添加和驱动时间轮滚动核心流程图
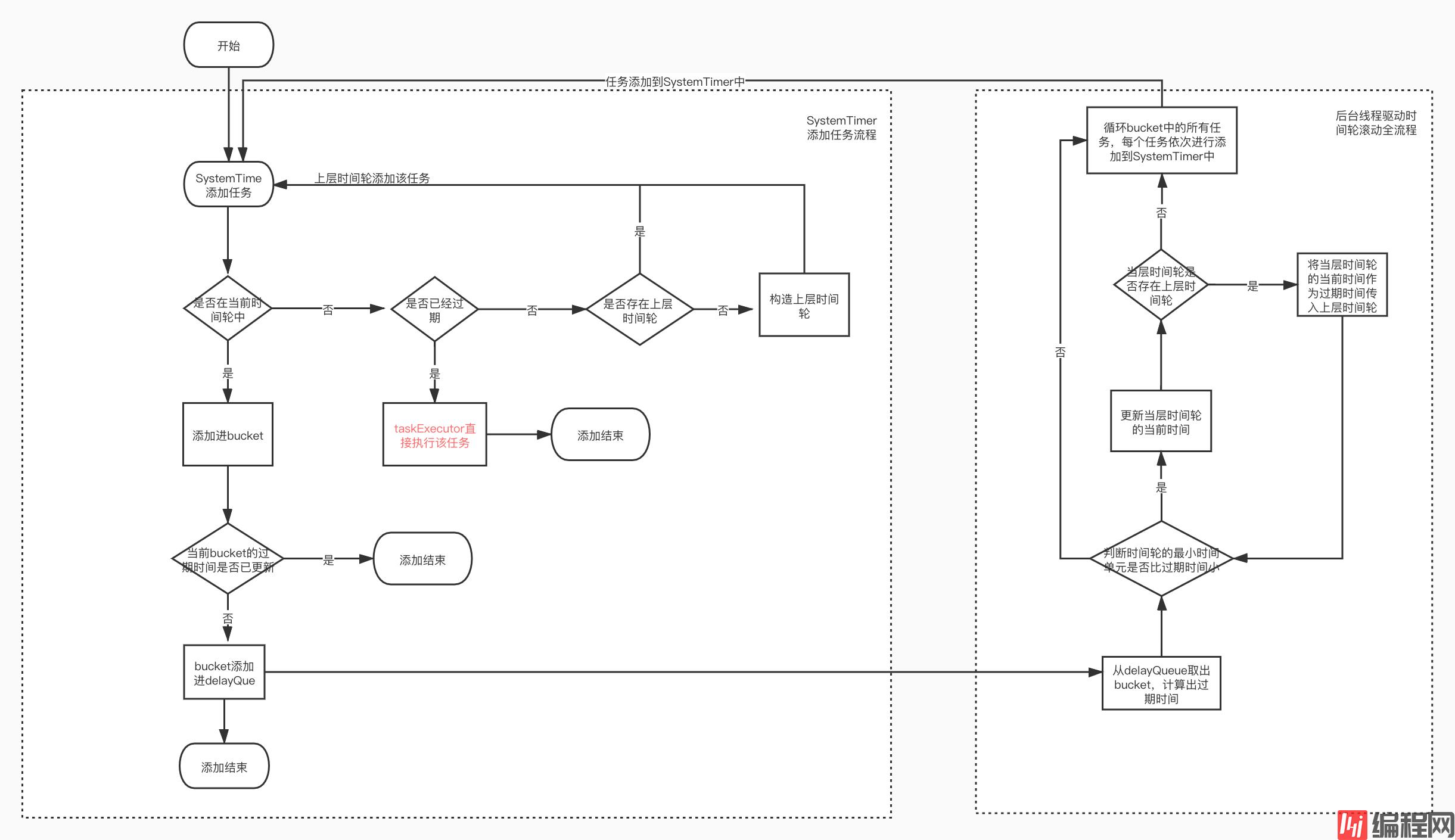
(图4)
重点代码介绍
这是往SystenTimer中添加一个任务
//在Systemtimer中添加一个任务,任务被包装为一个TimerTaskEntryprivate def addTimerTaskEntry(timerTaskEntry: TimerTaskEntry): Unit = {//先判断是否可以添加进时间轮中,如果不可以添加进去代表任务已经过期或者任务被取消,注意这里的timingWheel持有上一层时间轮的引用,所以可能存在递归调用 if (!timingWheel.add(timerTaskEntry)) { // Already expired or cancelled if (!timerTaskEntry.cancelled) //过期任务直接线程池异步执行掉 taskExecutor.submit(timerTaskEntry.timerTask) }}timingWheel添加任务,递归添加直到添加该任务进合适的时间轮的bucket中def add(timerTaskEntry: TimerTaskEntry): Boolean = { val expiration = timerTaskEntry.expirationMs //任务取消 if (timerTaskEntry.cancelled) { // Cancelled false } else if (expiration < currentTime + tickMs) { // 任务过期后会被执行 false } else if (expiration < currentTime + interval) {//任务过期时间比当前时间轮时间加周期小说明任务过期时间在本时间轮周期内 val virtualId = expiration / tickMs //找到任务对应本时间轮的bucket val bucket = buckets((virtualId % wheelSize.toLong).toInt) bucket.add(timerTaskEntry) // Set the bucket expiration time //只有本bucket内的任务都过期后才会bucket.setExpiration返回true此时将bucket放入延迟队列 if (bucket.setExpiration(virtualId * tickMs)) { //bucket是一个TimerTaskList,它实现了java.util.concurrent.Delayed接口,里面是一个多任务组 成的链表,图2有说明 queue.offer(bucket) } true } else { // Out of the interval. Put it into the parent timer //任务的过期时间不在本时间轮周期内说明需要升级时间轮,如果不存在则构造上一层时间轮,继续用 上一层时间轮添加任务 if (overflowWheel == null) addOverflowWheel() overflowWheel.add(timerTaskEntry) }}在本层级时间轮里添加上一层时间轮里的过程,注意的是在下一层时间轮的interval为上一层时间轮的tickMs
private[this] def addOverflowWheel(): Unit = { synchronized { if (overflowWheel == null) { overflowWheel = new TimingWheel( tickMs = interval, wheelSize = wheelSize, startMs = currentTime, taskCounter = taskCounter, queue ) } }}驱动时间轮滚动过程:
注意这里会存在一个递归,一直驱动时间轮的指针滚动直到时间不足于驱动上层的时间轮滚动。
def advanceClock(timeMs: Long): Unit = { if (timeMs >= currentTime + tickMs) { //把当前时间打平为时间轮tickMs的整数倍 currentTime = timeMs - (timeMs % tickMs) // Try to advance the clock of the overflow wheel if present //驱动上层时间轮,这里的传给上层的currentTime时间是本层时间轮打平过的,但是在上层时间轮还是会继续打平 if (overflowWheel != null) overflowWheel.advanceClock(currentTime) }}驱动源:
//循环bucket里面的任务列表,一个个重新添加进时间轮,对符合条件的时间轮进行升降级或者执行任务private[this] val reinsert = (timerTaskEntry: TimerTaskEntry) => addTimerTaskEntry(timerTaskEntry) def advanceClock(timeoutMs: Long): Boolean = { var bucket = delayQueue.poll(timeoutMs, TimeUnit.MILLISECONDS) if (bucket != null) { writeLock.lock() try { while (bucket != null) { //驱动时间轮 timingWheel.advanceClock(bucket.getExpiration()) //循环buckek也就是任务列表,任务列表一个个继续添加进时间轮以此来升级或者降级时间轮, 把过期任务找出来执行 bucket.flush(reinsert) //循环 //这里就是从延迟队列取出bucket,bucket是有延迟时间的,取出代表该bucket过期,我们通过 bucket能取到bucket包含的任务列表 bucket = delayQueue.poll() } } finally { writeLock.unlock() } true } else { false }}kafka的延迟队列使用时间轮实现,能够支持大量任务的高效触发,但是在kafka延迟队列实现方案里还是看到了delayQueue的影子,使用delayQueue是对时间轮里面的bucket放入延迟队列,以此来推动时间轮滚动,但是基于将插入和删除操作则放入时间轮中,将这些操作的时间复杂度都降为O(1),提升效率。Kafka对性能的极致追求让它把最合适的组件放在最适合的位置。
上述就是小编为大家分享的如何解析Kafka中的时间轮问题了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注编程网行业资讯频道。









