
文章目录
1、RDD 概念
RDD 英文全称为 " Resilient Distributed Datasets " , 对应中文名称 是 " 弹性分布式数据集 " ;
Spark 是用于 处理大规模数据 的 分布式计算引擎 ;
RDD 是 Spark 的基本数据单元 , 该 数据结构 是 只读的 , 不可写入更改 ;
RDD 对象 是 通过 SparkContext 执行环境入口对象 创建的 ;
SparkContext 读取数据时 , 通过将数据拆分为多个分区 , 以便在 服务器集群 中进行并行处理 ;
每个 RDD 数据分区 都可以在 服务器集群 中的 不同服务器节点 上 并行执行 计算任务 , 可以提高数据处理速度 ;
2、RDD 中的数据存储与计算
PySpark 中 处理的 所有的数据 ,
- 数据存储 : PySpark 中的数据都是以 RDD 对象的形式承载的 , 数据都存储在 RDD 对象中 ;
- 计算方法 : 大数据处理过程中使用的计算方法 , 也都定义在了 RDD 对象中 ;
- 计算结果 : 使用 RDD 中的计算方法对 RDD 中的数据进行计算处理 , 获得的结果数据也是封装在 RDD 对象中的 ;
PySpark 中 , 通过 SparkContext 执行环境入口对象 读取 基础数据到 RDD 对象中 , 调用 RDD 对象中的计算方法 , 对 RDD 对象中的数据进行处理 , 得到新的 RDD 对象 其中有 上一次的计算结果 , 再次对新的 RDD 对象中的数据进行处理 , 执行上述若干次计算 , 会 得到一个最终的 RDD 对象 , 其中就是数据处理结果 , 将其保存到文件中 , 或者写入到数据库中 ;
1、RDD 转换
在 Python 中 , 使用 PySpark 库中的 SparkContext # parallelize 方法 , 可以将 Python 容器数据 转换为 PySpark 的 RDD 对象 ;
PySpark 支持下面几种 Python 容器变量 转为 RDD 对象 :
- 列表 list : 可重复 , 有序元素 ;
- 元组 tuple : 可重复 , 有序元素 , 可读不可写 , 不可更改 ;
- 集合 set : 不可重复 , 无序元素 ;
- 字典 dict : 键值对集合 , 键 Key 不可重复 ;
- 字符串 str : 字符串 ;
2、转换 RDD 对象相关 API
调用 SparkContext # parallelize 方法 可以将 Python 容器数据转为 RDD 对象 ;
# 将数据转换为 RDD 对象rdd = sparkContext.parallelize(data)调用 RDD # getNumPartitions 方法 , 可以获取 RDD 的分区数 ;
print("RDD 分区数量: ", rdd.getNumPartitions())调用 RDD # collect 方法 , 可以查看 RDD 数据 ;
print("RDD 元素: ", rdd.collect())完整代码示例 :
# 创建一个包含列表的数据data = [1, 2, 3, 4, 5]# 将数据转换为 RDD 对象rdd = sparkContext.parallelize(data)# 打印 RDD 的分区数和元素print("RDD 分区数量: ", rdd.getNumPartitions())print("RDD 元素: ", rdd.collect())3、代码示例 - Python 容器转 RDD 对象 ( 列表 )
在下面的代码中 ,
首先 , 创建 SparkConf 对象 , 并将 PySpark 任务 命名为 " hello_spark " , 并设置为本地单机运行 ;
# 创建 SparkConf 实例对象 , 该对象用于配置 Spark 任务# setMaster("local[*]") 表示在单机模式下 本机运行# setAppName("hello_spark") 是给 Spark 程序起一个名字sparkConf = SparkConf() \ .setMaster("local[*]") \ .setAppName("hello_spark")然后 , 创建了一个 SparkContext 对象 , 传入 SparkConf 实例对象作为参数 ;
# 创建 PySpark 执行环境 入口对象sparkContext = SparkContext(conf=sparkConf)再后 , 创建一个包含整数的简单列表 ;
# 创建一个包含列表的数据data = [1, 2, 3, 4, 5]再后 , 并使用 parallelize() 方法将其转换为 RDD 对象 ;
# 将数据转换为 RDD 对象rdd = sparkContext.parallelize(data)最后 , 我们打印出 RDD 的分区数和所有元素 ;
# 打印 RDD 的分区数和元素print("RDD 分区数量: ", rdd.getNumPartitions())print("RDD 元素: ", rdd.collect())代码示例 :
"""PySpark 数据处理"""# 导入 PySpark 相关包from pyspark import SparkConf, SparkContext# 创建 SparkConf 实例对象 , 该对象用于配置 Spark 任务# setMaster("local[*]") 表示在单机模式下 本机运行# setAppName("hello_spark") 是给 Spark 程序起一个名字sparkConf = SparkConf() \ .setMaster("local[*]") \ .setAppName("hello_spark")# 创建 PySpark 执行环境 入口对象sparkContext = SparkContext(conf=sparkConf)# 打印 PySpark 版本号print("PySpark 版本号 : ", sparkContext.version)# 创建一个包含列表的数据data = [1, 2, 3, 4, 5]# 将数据转换为 RDD 对象rdd = sparkContext.parallelize(data)# 打印 RDD 的分区数和元素print("RDD 分区数量: ", rdd.getNumPartitions())print("RDD 元素: ", rdd.collect())# 停止 PySpark 程序sparkContext.stop()执行结果 :
Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\Scripts\python.exe Y:/002_WorkSpace/PycharmProjects/HelloPython/hello.py23/07/30 20:11:35 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblemsSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).23/07/30 20:11:35 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicablePySpark 版本号 : 3.4.1RDD 分区数量: 12RDD 元素: [1, 2, 3, 4, 5]Process finished with exit code 0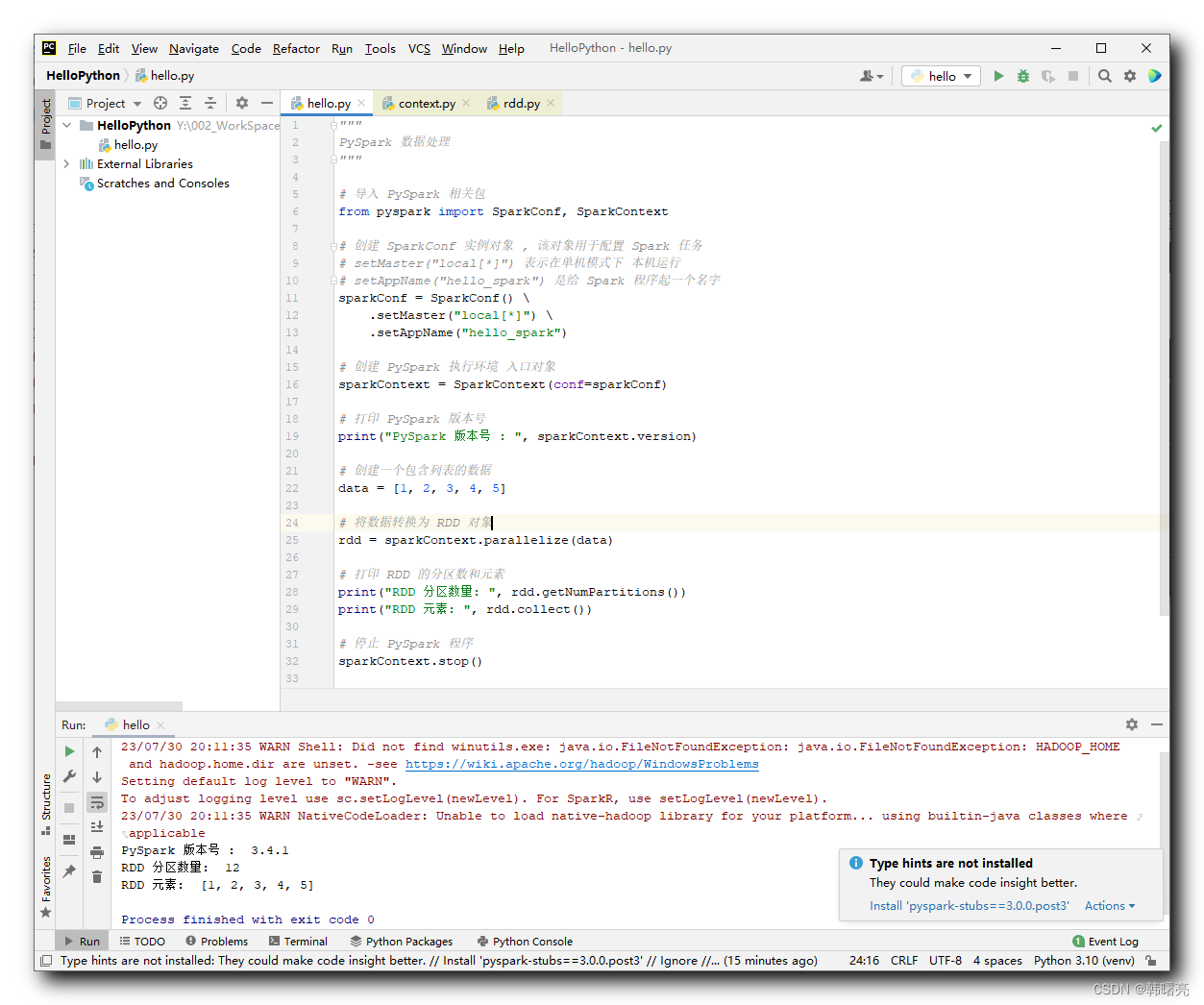
4、代码示例 - Python 容器转 RDD 对象 ( 列表 / 元组 / 集合 / 字典 / 字符串 )
除了 列表 list 之外 , 还可以将其他容器数据类型 转换为 RDD 对象 , 如 : 元组 / 集合 / 字典 / 字符串 ;
调用 RDD # collect 方法 , 打印出来的 RDD 数据形式 :
- 列表 / 元组 / 集合 转换后的 RDD 数据打印出来都是列表 ;
data1 = [1, 2, 3, 4, 5]data2 = (1, 2, 3, 4, 5)data3 = {1, 2, 3, 4, 5}# 输出结果rdd1 分区数量和元素: 12 , [1, 2, 3, 4, 5]rdd2 分区数量和元素: 12 , [1, 2, 3, 4, 5]rdd3 分区数量和元素: 12 , [1, 2, 3, 4, 5]- 字典 转换后的 RDD 数据打印出来只有 键 Key , 没有值 ;
data4 = {"Tom": 18, "Jerry": 12}# 输出结果rdd4 分区数量和元素: 12 , ['Tom', 'Jerry']- 字符串 转换后的 RDD 数据打印出来 是 列表 , 元素是单个字符 ;
data5 = "Tom"# 输出结果rdd5 分区数量和元素: 12 , ['T', 'o', 'm']代码示例 :
"""PySpark 数据处理"""# 导入 PySpark 相关包from pyspark import SparkConf, SparkContext# 创建 SparkConf 实例对象 , 该对象用于配置 Spark 任务# setMaster("local[*]") 表示在单机模式下 本机运行# setAppName("hello_spark") 是给 Spark 程序起一个名字sparkConf = SparkConf() \ .setMaster("local[*]") \ .setAppName("hello_spark")# 创建 PySpark 执行环境 入口对象sparkContext = SparkContext(conf=sparkConf)# 打印 PySpark 版本号print("PySpark 版本号 : ", sparkContext.version)# 创建一个包含列表的数据data1 = [1, 2, 3, 4, 5]data2 = (1, 2, 3, 4, 5)data3 = {1, 2, 3, 4, 5}data4 = {"Tom": 18, "Jerry": 12}data5 = "Tom"# 将数据转换为 RDD 对象rdd1 = sparkContext.parallelize(data1)rdd2 = sparkContext.parallelize(data2)rdd3 = sparkContext.parallelize(data3)rdd4 = sparkContext.parallelize(data4)rdd5 = sparkContext.parallelize(data5)# 打印 RDD 的元素print("rdd1 分区数量和元素: ", rdd1.getNumPartitions(), " , ", rdd1.collect())print("rdd2 分区数量和元素: ", rdd2.getNumPartitions(), " , ", rdd2.collect())print("rdd3 分区数量和元素: ", rdd3.getNumPartitions(), " , ", rdd3.collect())print("rdd4 分区数量和元素: ", rdd4.getNumPartitions(), " , ", rdd4.collect())print("rdd5 分区数量和元素: ", rdd5.getNumPartitions(), " , ", rdd5.collect())# 停止 PySpark 程序sparkContext.stop()执行结果 :
Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\Scripts\python.exe Y:/002_WorkSpace/PycharmProjects/HelloPython/hello.py23/07/30 20:37:03 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblemsSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).23/07/30 20:37:03 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicablePySpark 版本号 : 3.4.1rdd1 分区数量和元素: 12 , [1, 2, 3, 4, 5]rdd2 分区数量和元素: 12 , [1, 2, 3, 4, 5]rdd3 分区数量和元素: 12 , [1, 2, 3, 4, 5]rdd4 分区数量和元素: 12 , ['Tom', 'Jerry']rdd5 分区数量和元素: 12 , ['T', 'o', 'm']Process finished with exit code 0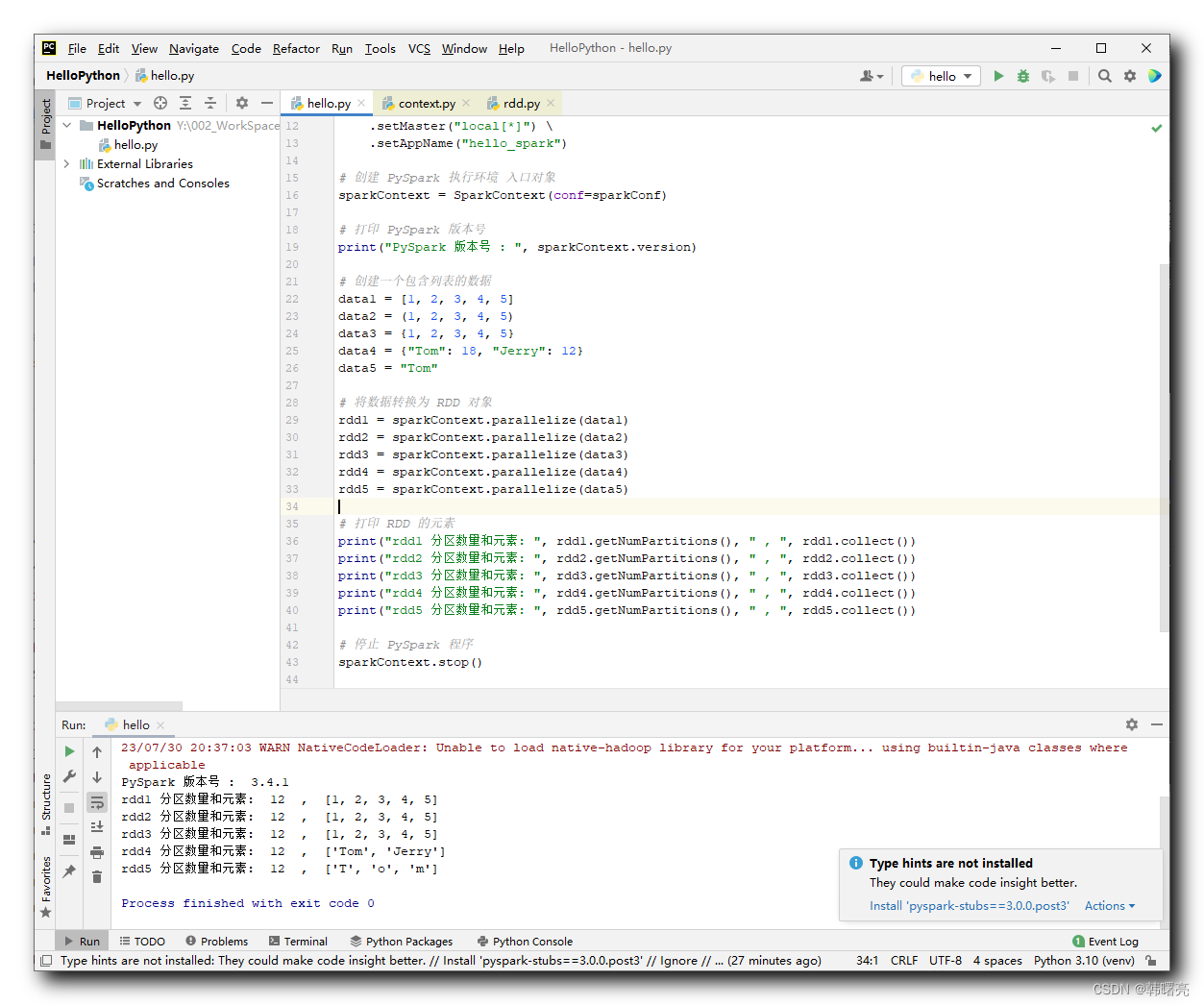
调用 SparkContext#textFile 方法 , 传入 文件的 绝对路径 或 相对路径 , 可以将 文本文件 中的数据 读取并转为 RDD 数据 ;
文本文件数据 :
Tom18Jerry12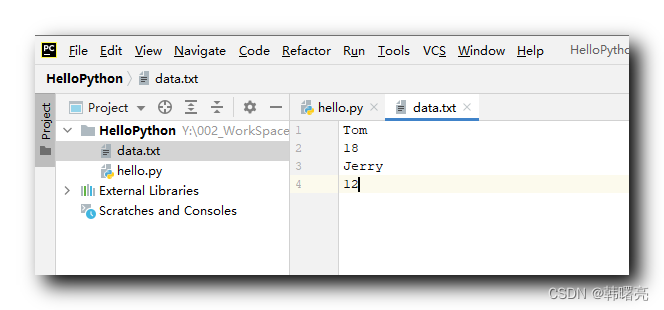
代码示例 :
"""PySpark 数据处理"""# 导入 PySpark 相关包from pyspark import SparkConf, SparkContext# 创建 SparkConf 实例对象 , 该对象用于配置 Spark 任务# setMaster("local[*]") 表示在单机模式下 本机运行# setAppName("hello_spark") 是给 Spark 程序起一个名字sparkConf = SparkConf() \ .setMaster("local[*]") \ .setAppName("hello_spark")# 创建 PySpark 执行环境 入口对象sparkContext = SparkContext(conf=sparkConf)# 打印 PySpark 版本号print("PySpark 版本号 : ", sparkContext.version)# 读取文件内容到 RDD 中rdd = sparkContext.textFile("data.txt")# 打印 RDD 的元素print("rdd1 分区数量和元素: ", rdd.getNumPartitions(), " , ", rdd.collect())# 停止 PySpark 程序sparkContext.stop()执行结果 :
Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\Scripts\python.exe Y:/002_WorkSpace/PycharmProjects/HelloPython/hello.py23/07/30 20:43:21 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblemsSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).23/07/30 20:43:21 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicablePySpark 版本号 : 3.4.1rdd1 分区数量和元素: 2 , ['Tom', '18', 'Jerry', '12']Process finished with exit code 0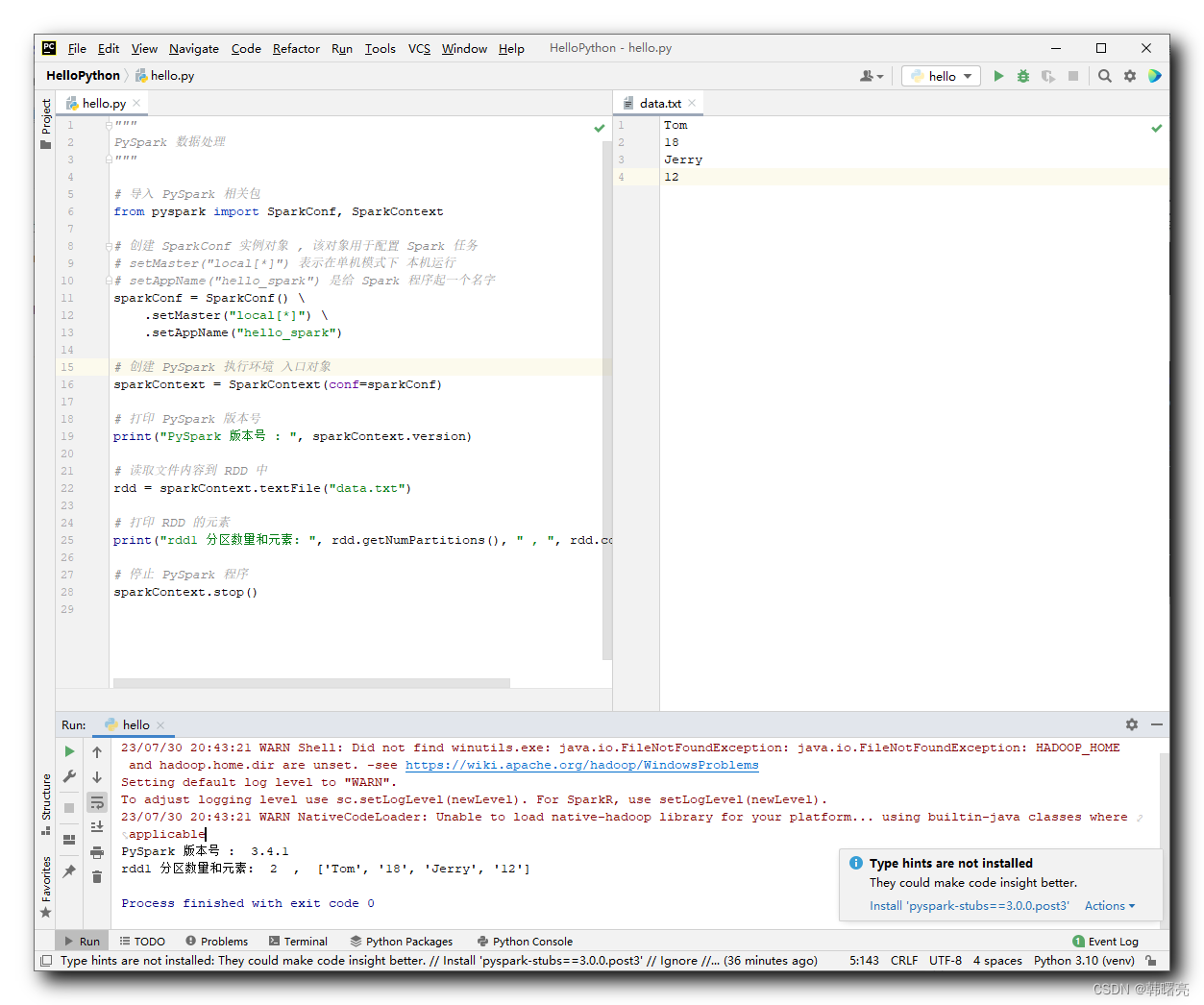
来源地址:https://blog.csdn.net/han1202012/article/details/132006013







