
数据库生成环境中经常会遇到表中有重复的数据,或者进行关联过程中产生重复数据,下面介绍三种剔除重复数据的方法,请针对自己的应用场景选择使用。
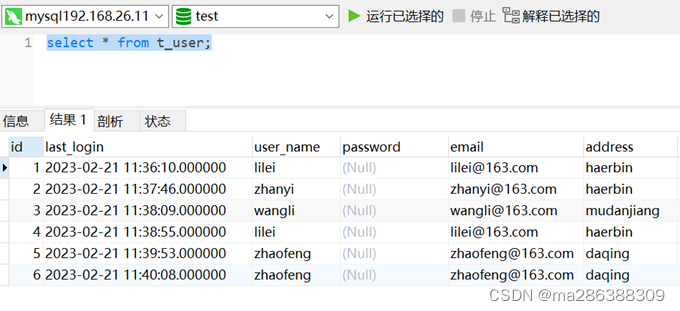
下图测试数据中user_name为lilei、zhaofeng的用户是重复数据。
1.方法一:使用distinct
代码如下(示例):
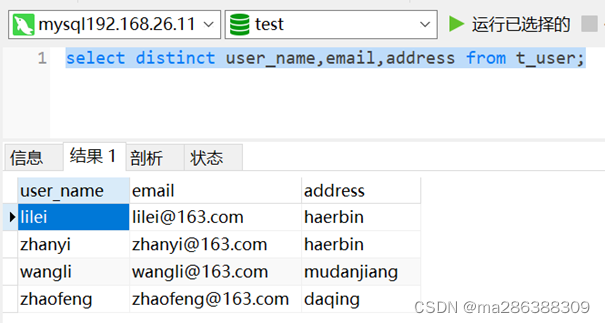
select distinct user_name,email,address from t_user;如下图,已将数据剔重,重复数据仅保留1条。
2.方法二:使用group by
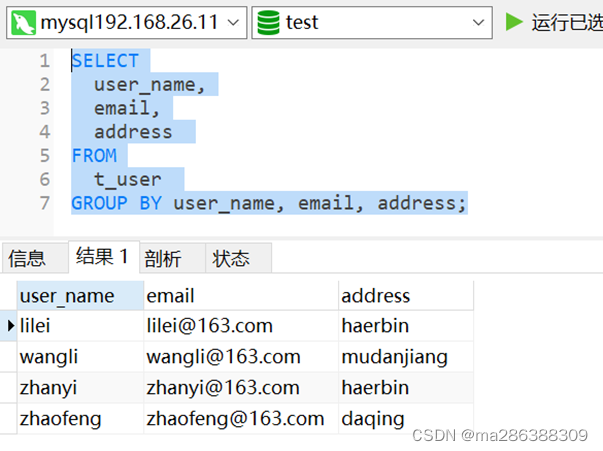
SELECT user_name,email,address FROM t_user GROUP BY user_name, email, address;如下图,已将数据剔重,重复数据仅保留1条。
3.方法三:使用开窗函数
(1)如果你的数据库是MySQL8以上版本你可以直接使用开窗函数row_number()
SELECT *FROM( SELECT t.*, ROW_NUMBER() OVER(PARTITION BY user_name ORDER BY last_login DESC) rn FROM table AS t) AS t_userWHERE rn = 1;(2)如果你的数据库版本低于MySQL8,使用类row_number()方法
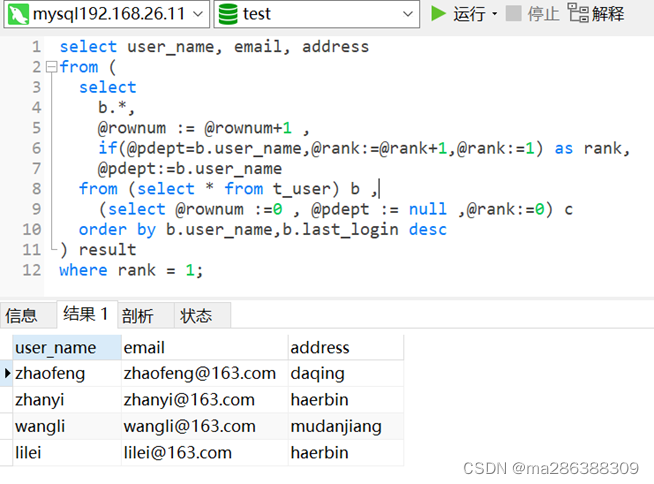
select user_name, email, address from (select b.*,@rownum := @rownum+1 ,-- 定义用户变量@rownum来记录数据的行号if(@pdept=b.user_name,@rank:=@rank+1,@rank:=1) as rank,-- 如果当前分组user_name和上一次分组user_name相同,则@rank(对每一组的数据进行编号)值加1,否则表示为新的分组,从1开始@pdept:=b.user_name -- 定义变量@pdept用来保存上一次的分组idfrom (select * from t_user) b ,(select @rownum :=0 , @pdept := null ,@rank:=0) c -- 初始化自定义变量值order by b.user_name,b.last_login desc -- 该排序必须,否则结果会不对) resultwhere rank = 1;如下图,已将数据剔重,重复数据仅保留1条。
word文档下载地址:mysql去重查询的三种方法
来源地址:https://blog.csdn.net/ma286388309/article/details/129261927












