
前言
过去半年,随着ChatGPT的火爆,直接带火了整个LLM这个方向,然LLM毕竟更多是基于过去的经验数据预训练而来,没法获取最新的知识,以及各企业私有的知识
- 为了获取最新的知识,ChatGPT plus版集成了bing搜索的功能,有的模型则会调用一个定位于 “链接各种AI模型、工具的langchain”的bing功能
- 为了处理企业私有的知识,要么基于开源模型微调,要么也可以基于langchain的思想调取一个外挂的向量知识库(类似存在本地的数据库一样)
所以越来越多的人开始关注langchain并把它与LLM结合起来应用,更直接推动了数据库、知识图谱与LLM的结合应用
本文侧重讲解
- LLM与langchain/数据库/知识图谱的结合应用
比如,虽说基于知识图谱的问答 早在2019年之前就有很多研究了,但谁会想到今年KBQA因为LLM如此突飞猛进呢
再比如,还会解读langchain-ChatGLM项目的关键源码,不只是把它当做一个工具使用,因为对工具的原理更了解,则对工具的使用更顺畅 - 其中,解读langchain-ChatGLM项目源码其实不易,因为涉及的项目、技术点不少,所以一开始容易绕晕,好在根据该项目的流程一步步抽丝剥茧之后,给大家呈现了清晰的代码架构
过程中,我从接触该langchain-ChatGLM项目到整体源码梳理清晰并写清楚历时了近一周,而大家有了本文之后,可能不到一天便可以理清了(提升近7倍效率) ,这便是本文的价值和意义之一
阅读过程中若有任何问题,欢迎随时留言,会一一及时回复/解答,共同探讨、共同深挖
第一部分 什么是LangChain:LLM的外挂/功能库
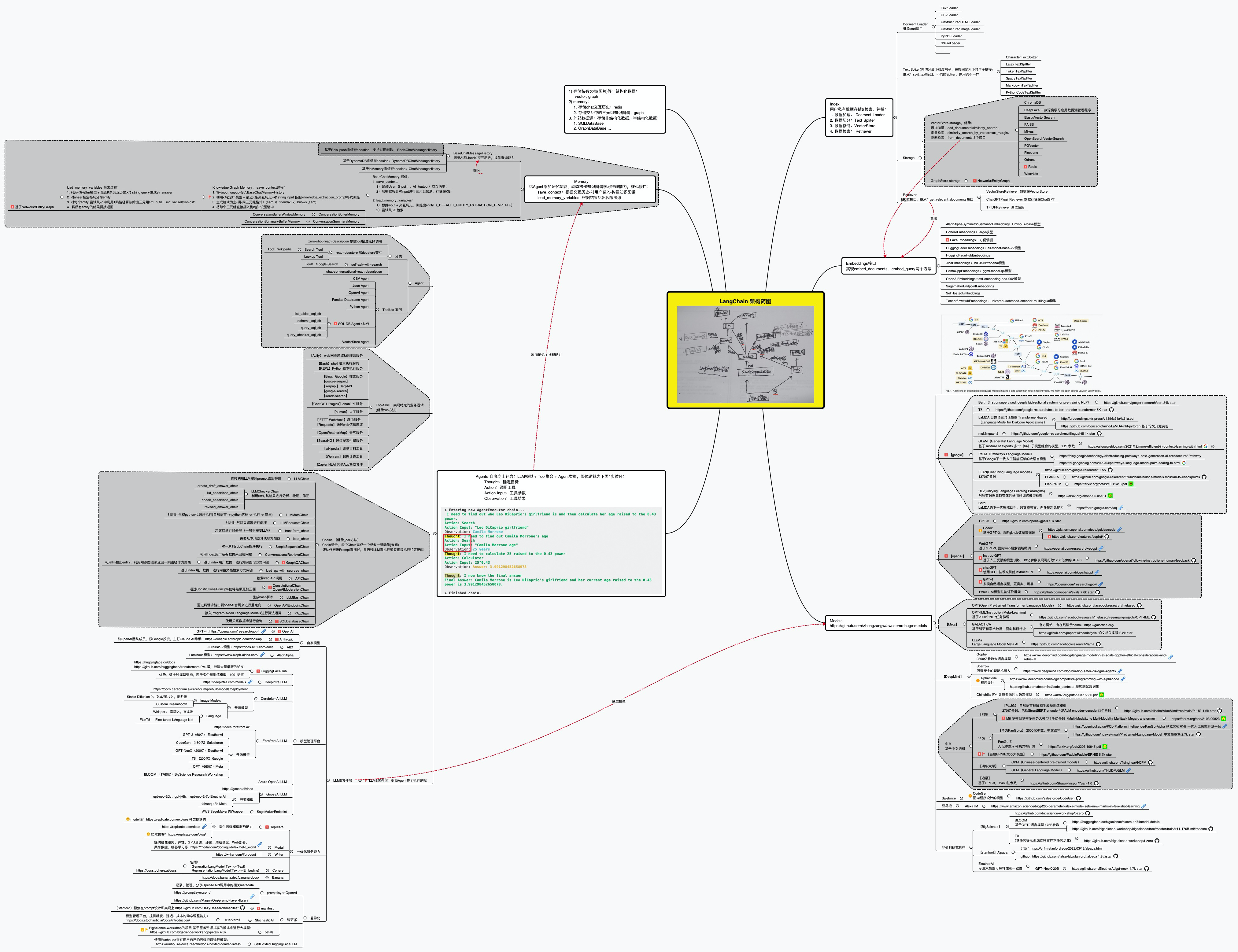
1.1 langchain的整体组成架构
通俗讲,所谓langchain (官网地址、GitHub地址),即把AI中常用的很多功能都封装成库,且有调用各种商用模型API、开源模型的接口,支持以下各种组件

初次接触的朋友一看这么多组件可能直接晕了(封装的东西非常多,感觉它想把LLM所需要用到的功能/工具都封装起来),为方便理解,我们可以先从大的层面把整个langchain库划分为三个大层:基础层、能力层、应用层
1.1.1 基础层:models、LLMs、index
Models:模型
各种类型的模型和模型集成,比如OpenAI的各个API/GPT-4等等,为各种不同基础模型提供统一接口
比如通过API完成一次问答
import osos.environ["OPENAI_API_KEY"] = '你的api key'from langchain.llms import OpenAIllm = OpenAI(model_name="text-davinci-003",max_tokens=1024)llm("怎么评价人工智能")得到的回答如下图所示

LLMS层
这一层主要强调对models层能力的封装以及服务化输出能力,主要有:
- 各类LLM模型管理平台:强调的模型的种类丰富度以及易用性
- 一体化服务能力产品:强调开箱即用
- 差异化能力:比如聚焦于Prompt管理(包括提示管理、提示优化和提示序列化)、基于共享资源的模型运行模式等等
比如Google's PaLM Text APIs,再比如 llms/openai.py 文件下
model_token_mapping = { "gpt-4": 8192, "gpt-4-0314": 8192, "gpt-4-0613": 8192, "gpt-4-32k": 32768, "gpt-4-32k-0314": 32768, "gpt-4-32k-0613": 32768, "gpt-3.5-turbo": 4096, "gpt-3.5-turbo-0301": 4096, "gpt-3.5-turbo-0613": 4096, "gpt-3.5-turbo-16k": 16385, "gpt-3.5-turbo-16k-0613": 16385, "text-ada-001": 2049, "ada": 2049, "text-babbage-001": 2040, "babbage": 2049, "text-curie-001": 2049, "curie": 2049, "davinci": 2049, "text-davinci-003": 4097, "text-davinci-002": 4097, "code-davinci-002": 8001, "code-davinci-001": 8001, "code-cushman-002": 2048, "code-cushman-001": 2048, }Index(索引):Vector方案、KG方案
对用户私域文本、图片、PDF等各类文档进行存储和检索(相当于结构化文档,以便让外部数据和模型交互),具体实现上有两个方案:一个Vector方案、一个KG方案
对于Vector方案:即对文件先切分为Chunks,在按Chunks分别编码存储并检索,可参考此代码文件:langchain/libs/langchain/langchain/indexes /vectorstore.py
该代码文件依次实现
模块导入:导入了各种类型检查、数据结构、预定义类和函数
接下来,实现了一个函数_get_default_text_splitter,两个类VectorStoreIndexWrapper、VectorstoreIndexCreator
_get_default_text_splitter 函数:
这是一个私有函数,返回一个默认的文本分割器,它可以将文本递归地分割成大小为1000的块,且块与块之间有重叠
# 默认的文本分割器函数def _get_default_text_splitter() -> TextSplitter: return RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)接下来是,VectorStoreIndexWrapper 类:
这是一个包装类,主要是为了方便地访问和查询向量存储(Vector Store)
- vectorstore: 一个向量存储对象的属性
vectorstore: VectorStore # 向量存储对象 class Config: """Configuration for this pydantic object.""" extra = Extra.forbid # 额外配置项 arbitrary_types_allowed = True # 允许任意类型 - query: 一个方法,它接受一个问题字符串并查询向量存储来获取答案
解释一下上面出现的提取器# 查询向量存储的函数def query( self, question: str, # 输入的问题字符串 llm: Optional[BaseLanguageModel] = None, # 可选的语言模型参数,默认为None retriever_kwargs: Optional[Dict[str, Any]] = None, # 提取器的可选参数,默认为None **kwargs: Any # 其他关键字参数) -> str: """Query the vectorstore."""# 函数的文档字符串,描述函数的功能 # 如果没有提供语言模型参数,则使用OpenAI作为默认语言模型,并设定温度参数为0 llm = llm or OpenAI(temperature=0) # 如果没有提供提取器的参数,则初始化为空字典 retriever_kwargs = retriever_kwargs or {} # 创建一个基于语言模型和向量存储提取器的检索QA链 chain = RetrievalQA.from_chain_type( llm, retriever=self.vectorstore.as_retriever(**retriever_kwargs), **kwargs ) # 使用创建的QA链运行提供的问题,并返回结果 return chain.run(question)提取器首先从大型语料库中检索与问题相关的文档或片段,然后生成器根据这些检索到的文档生成答案。
提取器可以基于许多不同的技术,包括:
a.基于关键字的检索:使用关键字匹配来查找相关文档
b.向量空间模型:将文档和查询都表示为向量,并通过计算它们之间的相似度来检索相关文档
c.基于深度学习的方法:使用预训练的神经网络模型(如BERT、RoBERTa等)将文档和查询编码为向量,并进行相似度计算
d.索引方法:例如倒排索引,这是搜索引擎常用的技术,可以快速找到包含特定词或短语的文档
这些方法可以独立使用,也可以结合使用,以提高检索的准确性和速度 - query_with_sources: 类似于query,但它还返回与查询结果相关的数据源
# 查询向量存储并返回数据源的函数 def query_with_sources( self, question: str, llm: Optional[BaseLanguageModel] = None, retriever_kwargs: Optional[Dict[str, Any]] = None, **kwargs: Any ) -> dict: """Query the vectorstore and get back sources.""" llm = llm or OpenAI(temperature=0) # 默认使用OpenAI作为语言模型 retriever_kwargs = retriever_kwargs or {} # 提取器参数 chain = RetrievalQAWithSourcesChain.from_chain_type( llm, retriever=self.vectorstore.as_retriever(**retriever_kwargs), **kwargs ) return chain({chain.question_key: question})
最后是VectorstoreIndexCreator 类:
这是一个创建向量存储索引的类
- vectorstore_cls: 使用的向量存储类,默认为Chroma
一个简化的向量存储可以看作是一个大型的表格或数据库,其中每行代表一个项目(如文档、图像、句子等),而每个项目则有一个与之关联的高维向量。向量的维度可以从几十到几千,取决于所使用的嵌入模型vectorstore_cls: Type[VectorStore] = Chroma # 默认使用Chroma作为向量存储类
例如: - embedding: 使用的嵌入类,默认为OpenAIEmbeddings
embedding: Embeddings = Field(default_factory=OpenAIEmbeddings) # 默认使用OpenAIEmbeddings作为嵌入类 - text_splitter: 用于分割文本的文本分割器
text_splitter: TextSplitter = Field(default_factory=_get_default_text_splitter) # 默认文本分割器 - from_loaders: 从给定的加载器列表中创建一个向量存储索引
# 从加载器创建向量存储索引的函数 def from_loaders(self, loaders: List[BaseLoader]) -> VectorStoreIndexWrapper: """Create a vectorstore index from loaders.""" docs = [] for loader in loaders: # 遍历加载器 docs.extend(loader.load()) # 加载文档 return self.from_documents(docs) - from_documents: 从给定的文档列表中创建一个向量存储索引
# 从文档创建向量存储索引的函数 def from_documents(self, documents: List[Document]) -> VectorStoreIndexWrapper: """Create a vectorstore index from documents.""" sub_docs = self.text_splitter.split_documents(documents) # 分割文档 vectorstore = self.vectorstore_cls.from_documents( sub_docs, self.embedding, **self.vectorstore_kwargs # 从文档创建向量存储 ) return VectorStoreIndexWrapper(vectorstore=vectorstore) # 返回向量存储的包装对象
对于KG方案:这部分利用LLM抽取文件中的三元组,将其存储为KG供后续检索,可参考此代码文件:langchain/libs/langchain/langchain/indexes /graph.py
"""Graph Index Creator.""" # 定义"图索引创建器"的描述# 导入相关的模块和类型定义from typing import Optional, Type # 导入可选类型和类型的基础类型from langchain import BasePromptTemplate # 导入基础提示模板from langchain.chains.llm import LLMChain # 导入LLM链from langchain.graphs.networkx_graph import NetworkxEntityGraph, parse_triples # 导入Networkx实体图和解析三元组的功能from langchain.indexes.prompts.knowledge_triplet_extraction import ( # 从知识三元组提取模块导入对应的提示 KNOWLEDGE_TRIPLE_EXTRACTION_PROMPT,)from langchain.pydantic_v1 import BaseModel # 导入基础模型from langchain.schema.language_model import BaseLanguageModel # 导入基础语言模型的定义class GraphIndexCreator(BaseModel): # 定义图索引创建器类,继承自BaseModel """Functionality to create graph index.""" # 描述该类的功能为"创建图索引" llm: Optional[BaseLanguageModel] = None # 定义可选的语言模型属性,默认为None graph_type: Type[NetworkxEntityGraph] = NetworkxEntityGraph # 定义图的类型,默认为NetworkxEntityGraph def from_text( self, text: str, prompt: BasePromptTemplate = KNOWLEDGE_TRIPLE_EXTRACTION_PROMPT ) -> NetworkxEntityGraph: # 定义一个方法,从文本中创建图索引 """Create graph index from text.""" # 描述该方法的功能 if self.llm is None: # 如果语言模型为None,则抛出异常 raise ValueError("llm should not be None") graph = self.graph_type() # 创建一个新的图 chain = LLMChain(llm=self.llm, prompt=prompt) # 使用当前的语言模型和提示创建一个LLM链 output = chain.predict(text=text) # 使用LLM链对文本进行预测 knowledge = parse_triples(output) # 解析预测输出得到的三元组 for triple in knowledge: # 遍历所有的三元组 graph.add_triple(triple) # 将三元组添加到图中 return graph # 返回创建的图 async def afrom_text( # 定义一个异步版本的from_text方法 self, text: str, prompt: BasePromptTemplate = KNOWLEDGE_TRIPLE_EXTRACTION_PROMPT ) -> NetworkxEntityGraph: """Create graph index from text asynchronously.""" # 描述该异步方法的功能 if self.llm is None: # 如果语言模型为None,则抛出异常 raise ValueError("llm should not be None") graph = self.graph_type() # 创建一个新的图 chain = LLMChain(llm=self.llm, prompt=prompt) # 使用当前的语言模型和提示创建一个LLM链 output = await chain.apredict(text=text) # 异步使用LLM链对文本进行预测 knowledge = parse_triples(output) # 解析预测输出得到的三元组 for triple in knowledge: # 遍历所有的三元组 graph.add_triple(triple) # 将三元组添加到图中 return graph # 返回创建的图另外,为了索引,便不得不牵涉以下这些能力
- Document Loaders,文档加载的标准接口
与各种格式的文档及数据源集成,比如Arxiv、Email、Excel、Markdown、PDF(所以可以做类似ChatPDF这样的应用)、Youtube …
相近的还有
docstore,其中包含wikipedia.py等
document_transformers - embeddings(langchain/libs/langchain/langchain/embeddings),则涉及到各种embeddings算法,分别体现在各种代码文件中:
elasticsearch.py、google_palm.py、gpt4all.py、huggingface.py、huggingface_hub.py
llamacpp.py、minimax.py、modelscope_hub.py、mosaicml.py
openai.py
sentence_transformer.py、spacy_embeddings.py、tensorflow_hub.py、vertexai.py
1.1.2 能力层:Chains、Memory、Tools
如果基础层提供了最核心的能力,能力层则给这些能力安装上手、脚、脑,让其具有记忆和触发万物的能力,包括:Chains、Memory、Tool三部分
- Chains:链接
简言之,相当于包括一系列对各种组件的调用,可能是一个 Prompt 模板,一个语言模型,一个输出解析器,一起工作处理用户的输入,生成响应,并处理输出
具体而言,则相当于按照不同的需求抽象并定制化不同的执行逻辑,Chain可以相互嵌套并串行执行,通过这一层,让LLM的能力链接到各行各业
比如与Elasticsearch数据库交互的:elasticsearch_database
比如基于知识图谱问答的:graph_qa
其中的代码文件:chains/graph_qa/base.py 便实现了一个基于知识图谱实现的问答系统,具体步骤为
首先,根据提取到的实体在知识图谱中查找相关的信息「这是通过 self.graph.get_entity_knowledge(entity) 实现的,它返回的是与实体相关的所有信息,形式为三元组」
然后,将所有的三元组组合起来,形成上下文
最后,将问题和上下文一起输入到qa_chain,得到最后的答案
比如能自动生成代码并执行的:llm_math等等entities = get_entities(entity_string) # 获取实体列表。 context = "" # 初始化上下文。 all_triplets = [] # 初始化三元组列表。 for entity in entities: # 遍历每个实体 all_triplets.extend(self.graph.get_entity_knowledge(entity)) # 获取实体的所有知识并加入到三元组列表中。 context = "\n".join(all_triplets) # 用换行符连接所有的三元组作为上下文。 # 打印完整的上下文。 _run_manager.on_text("Full Context:", end="\n", verbose=self.verbose) _run_manager.on_text(context, color="green", end="\n", verbose=self.verbose) # 使用上下文和问题获取答案。 result = self.qa_chain( {"question": question, "context": context}, callbacks=_run_manager.get_child(), ) return {self.output_key: result[self.qa_chain.output_key]} # 返回答案
比如面向私域数据的:qa_with_sources,其中的这份代码文件 chains/qa_with_sources/vector_db.py 则是使用向量数据库的问题回答,核心在于以下两个函数
reduce_tokens_below_limit
_get_docs# 定义基于向量数据库的问题回答类class VectorDBQAWithSourcesChain(BaseQAWithSourcesChain): """Question-answering with sources over a vector database.""" # 定义向量数据库的字段 vectorstore: VectorStore = Field(exclude=True) """Vector Database to connect to.""" # 定义返回结果的数量 k: int = 4 # 是否基于令牌限制来减少返回结果的数量 reduce_k_below_max_tokens: bool = False # 定义返回的文档基于令牌的最大限制 max_tokens_limit: int = 3375 # 定义额外的搜索参数 search_kwargs: Dict[str, Any] = Field(default_factory=dict) # 定义函数来根据最大令牌限制来减少文档 def _reduce_tokens_below_limit(self, docs: List[Document]) -> List[Document]: num_docs = len(docs) # 检查是否需要根据令牌减少文档数量 if self.reduce_k_below_max_tokens and isinstance( self.combine_documents_chain, StuffDocumentsChain ): tokens = [ self.combine_documents_chain.llm_chain.llm.get_num_tokens( doc.page_content ) for doc in docs ] token_count = sum(tokens[:num_docs]) # 减少文档数量直到满足令牌限制 while token_count > self.max_tokens_limit: num_docs -= 1 token_count -= tokens[num_docs] return docs[:num_docs]
比如面向SQL数据源的:sql_database,可以重点关注这份代码文件:chains/sql_database/query.py# 获取相关文档的函数 def _get_docs( self, inputs: Dict[str, Any], *, run_manager: CallbackManagerForChainRun ) -> List[Document]: question = inputs[self.question_key] # 从向量存储中搜索相似的文档 docs = self.vectorstore.similarity_search( question, k=self.k, **self.search_kwargs ) return self._reduce_tokens_below_limit(docs)
比如面向模型对话的:chat_models,包括这些代码文件:__init__.py、anthropic.py、azure_openai.py、base.py、fake.py、google_palm.py、human.py、jinachat.py、openai.py、promptlayer_openai.py、vertexai.py
另外,还有比较让人眼前一亮的:
constitutional_ai:对最终结果进行偏见、合规问题处理的逻辑,保证最终的结果符合价值观
llm_checker:能让LLM自动检测自己的输出是否有没有问题的逻辑 - Memory:记忆
简言之,用来保存和模型交互时的上下文状态,处理长期记忆
具体而言,这层主要有两个核心点: 对Chains的执行过程中的输入、输出进行记忆并结构化存储,为下一步的交互提供上下文,这部分简单存储在Redis即可 根据交互历史构建知识图谱,根据关联信息给出准确结果,对应的代码文件为:memory/kg.py
对Chains的执行过程中的输入、输出进行记忆并结构化存储,为下一步的交互提供上下文,这部分简单存储在Redis即可 根据交互历史构建知识图谱,根据关联信息给出准确结果,对应的代码文件为:memory/kg.py - Tools层,工具
其实Chains层可以根据LLM + Prompt执行一些特定的逻辑,但是如果要用Chain实现所有的逻辑不现实,可以通过Tools层也可以实现,Tools层理解为技能比较合理,典型的比如搜索、Wikipedia、天气预报、ChatGPT服务等等
1.1.3 应用层:Agents
- Agents:代理
简言之,有了基础层和能力层,我们可以构建各种各样好玩的,有价值的服务,这里就是Agent
具体而言,Agent 作为代理人去向 LLM 发出请求,然后采取行动,且检查结果直到工作完成,包括LLM无法处理的任务的代理 (例如搜索或计算,类似ChatGPT plus的插件有调用bing和计算器的功能)
比如,Agent 可以使用维基百科查找 Barack Obama 的出生日期,然后使用计算器计算他在 2023 年的年龄
此外,关于Wikipedia可以关注下这个代码文件:langchain/docstore/wikipedia.py ...# pip install wikipediafrom langchain.agents import load_toolsfrom langchain.agents import initialize_agentfrom langchain.agents import AgentTypetools = load_tools(["wikipedia", "llm-math"], llm=llm)agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)agent.run("奥巴马的生日是哪天? 到2023年他多少岁了?")
最终langchain的整体技术架构可以如下图所示 (查看高清大图,此外,这里还有另一个架构图)

1.2 langchain的部分应用示例:联网搜索 + 文档问答
但看理论介绍,你可能没法理解langchain到底有什么用,为方便大家理解,特举几个langchain的应用示例
1.2.1 通过 Google 搜索并返回答案
由于需要借助 Serpapi 来进行实现,而Serpapi 提供了 Google 搜索的API 接口
故先到 Serpapi 官网(https://serpapi.com/)上注册一个用户,并复制他给我们生成 API key,然后设置到环境变量里面去
import osos.environ["OPENAI_API_KEY"] = '你的api key'os.environ["SERPAPI_API_KEY"] = '你的api key'然后,开始编写代码
from langchain.agents import load_toolsfrom langchain.agents import initialize_agentfrom langchain.llms import OpenAIfrom langchain.agents import AgentType# 加载 OpenAI 模型llm = OpenAI(temperature=0,max_tokens=2048) # 加载 serpapi 工具tools = load_tools(["serpapi"])# 如果搜索完想再计算一下可以这么写# tools = load_tools(['serpapi', 'llm-math'], llm=llm)# 如果搜索完想再让他再用python的print做点简单的计算,可以这样写# tools=load_tools(["serpapi","python_repl"])# 工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)# 运行 agentagent.run("What's the date today? What great events have taken place today in history?")1.2.2 用不到 50 行代码实现一个文档对话机器人
众所周知,由于ChatGPT训练的数据只更新到 2021 年,因此它不知道互联网最新的知识(除非它调用搜索功能bing),而利用 “LangChain + ChatGPT的API” 则可以用不到 50 行的代码然后实现一个和既存文档的对话机器人
假设所有 2022 年更新的内容都存在于 2022.txt 这个文档中,那么通过如下的代码,就可以让 ChatGPT 来支持回答 2022 年的问题
其中原理也很简单:
- 对用户的输入/prompt向量化
- 文档分词
- 文档分割
- 文本向量化
向量化了才能进行向量之间相似度的计算 - 向量化的文本存到向量数据库里
- 根据用户的输入/prompt去向量数据里寻找答案(答案的判定是基于prompt/输入与文本中相关段落向量的相似性匹配)
- 最后通过LLM返回答案
#!/usr/bin/python# -*- coding: UTF-8 -*-import os# 导入os模块,用于操作系统相关的操作import jieba as jb # 导入结巴分词库from langchain.chains import ConversationalRetrievalChain # 导入用于创建对话检索链的类from langchain.chat_models import ChatOpenAI # 导入用于创建ChatOpenAI对象的类from langchain.document_loaders import DirectoryLoader # 导入用于加载文件的类from langchain.embeddings import OpenAIEmbeddings # 导入用于创建词向量嵌入的类from langchain.text_splitter import TokenTextSplitter # 导入用于分割文档的类from langchain.vectorstores import Chroma # 导入用于创建向量数据库的类# 初始化函数,用于处理输入的文档def init(): files = ['2022.txt'] # 需要处理的文件列表 for file in files: # 遍历每个文件 with open(f"./data/{file}", 'r', encoding='utf-8') as f: # 以读模式打开文件 data = f.read() # 读取文件内容 cut_data = " ".join([w for w in list(jb.cut(data))]) # 对读取的文件内容进行分词处理 cut_file = f"./data/cut/cut_{file}" # 定义处理后的文件路径和名称 with open(cut_file, 'w') as f: # 以写模式打开文件 f.write(cut_data) # 将处理后的内容写入文件# 新建一个函数用于加载文档def load_documents(directory): # 创建DirectoryLoader对象,用于加载指定文件夹内的所有.txt文件 loader = DirectoryLoader(directory, glob='***.txt", loader_cls=TextLoader)#读取文本文件documents = loader.load()# 使用text_splitter对文档进行分割split_text = text_splitter.split_documents(documents)try:for document in tqdm(split_text):# 获取向量并储存到pineconePinecone.from_documents([document], embeddings, index_name=pinecone_index)except Exception as e: print(f"Error: {e}") quit()3.8 vectorstores:MyFAISS.py
两个文件,一个__init__.py (就一行代码:from .MyFAISS import MyFAISS),另一个MyFAISS.py,如下代码所示
# 从langchain.vectorstores库导入FAISSfrom langchain.vectorstores import FAISS# 从langchain.vectorstores.base库导入VectorStore from langchain.vectorstores.base import VectorStore# 从langchain.vectorstores.faiss库导入dependable_faiss_importfrom langchain.vectorstores.faiss import dependable_faiss_import from typing import Any, Callable, List, Dict # 导入类型检查库from langchain.docstore.base import Docstore # 从langchain.docstore.base库导入Docstore# 从langchain.docstore.document库导入Documentfrom langchain.docstore.document import Document import numpy as np # 导入numpy库,用于科学计算import copy # 导入copy库,用于数据复制import os # 导入os库,用于操作系统相关的操作from configs.model_config import * # 从configs.model_config库导入所有内容# 定义MyFAISS类,继承自FAISS和VectorStore两个父类class MyFAISS(FAISS, VectorStore):接下来,逐一实现以下函数
3.8.1 定义类的初始化函数:__init__
# 定义类的初始化函数 def __init__( self, embedding_function: Callable, index: Any, docstore: Docstore, index_to_docstore_id: Dict[int, str], normalize_L2: bool = False, ): # 调用父类FAISS的初始化函数 super().__init__(embedding_function=embedding_function, index=index, docstore=docstore, index_to_docstore_id=index_to_docstore_id, normalize_L2=normalize_L2) # 初始化分数阈值 self.score_threshold=VECTOR_SEARCH_SCORE_THRESHOLD # 初始化块大小 self.chunk_size = CHUNK_SIZE # 初始化块内容 self.chunk_conent = False3.8.2 seperate_list:将一个列表分解成多个子列表
# 定义函数seperate_list,将一个列表分解成多个子列表,每个子列表中的元素在原列表中是连续的 def seperate_list(self, ls: List[int]) -> List[List[int]]: # TODO: 增加是否属于同一文档的判断 lists = [] ls1 = [ls[0]] for i in range(1, len(ls)): if ls[i - 1] + 1 == ls[i]: ls1.append(ls[i]) else: lists.append(ls1) ls1 = [ls[i]] lists.append(ls1) return lists3.8.3 similarity_search_with_score_by_vector,根据输入的向量,查找最接近的k个文本
similarity_search_with_score_by_vector 函数用于通过向量进行相似度搜索,返回与给定嵌入向量最相似的文本和对应的分数
# 定义函数similarity_search_with_score_by_vector,根据输入的向量,查找最接近的k个文本 def similarity_search_with_score_by_vector( self, embedding: List[float], k: int = 4 ) -> List[Document]: # 调用dependable_faiss_import函数,导入faiss库 faiss = dependable_faiss_import() # 将输入的列表转换为numpy数组,并设置数据类型为float32 vector = np.array([embedding], dtype=np.float32) # 如果需要进行L2归一化,则调用faiss.normalize_L2函数进行归一化 if self._normalize_L2: faiss.normalize_L2(vector) # 调用faiss库的search函数,查找与输入向量最接近的k个向量,并返回他们的分数和索引 scores, indices = self.index.search(vector, k) # 初始化一个空列表,用于存储找到的文本 docs = [] # 初始化一个空集合,用于存储文本的id id_set = set() # 获取文本库中文本的数量 store_len = len(self.index_to_docstore_id) # 初始化一个布尔变量,表示是否需要重新排列id列表 rearrange_id_list = False # 遍历找到的索引和分数 for j, i in enumerate(indices[0]): # 如果索引为-1,或者分数小于阈值,则跳过这个索引 if i == -1 or 0 < self.score_threshold < scores[0][j]: # This happens when not enough docs are returned. continue # 如果索引存在于index_to_docstore_id字典中,则获取对应的文本id if i in self.index_to_docstore_id: _id = self.index_to_docstore_id[i] # 如果索引不存在于index_to_docstore_id字典中,则跳过这个索引 else: continue # 从文本库中搜索对应id的文本 doc = self.docstore.search(_id) # 如果不需要拆分块内容,或者文档的元数据中没有context_expand字段,或者context_expand字段的值为false,则执行以下代码 if (not self.chunk_conent) or ("context_expand" in doc.metadata and not doc.metadata["context_expand"]): # 匹配出的文本如果不需要扩展上下文则执行如下代码 # 如果搜索到的文本不是Document类型,则抛出异常 if not isinstance(doc, Document): raise ValueError(f"Could not find document for id {_id}, got {doc}") # 在文本的元数据中添加score字段,其值为找到的分数 doc.metadata["score"] = int(scores[0][j]) # 将文本添加到docs列表中 docs.append(doc) continue # 将文本id添加到id_set集合中 id_set.add(i) # 获取文本的长度 docs_len = len(doc.page_content) # 遍历范围在1到i和store_len - i之间的数字k for k in range(1, max(i, store_len - i)): # 初始化一个布尔变量,表示是否需要跳出循环 break_flag = False # 如果文本的元数据中有context_expand_method字段,并且其值为"forward",则扩展范围设置为[i + k] if "context_expand_method" in doc.metadata and doc.metadata["context_expand_method"] == "forward": expand_range = [i + k] # 如果文本的元数据中有context_expand_method字段,并且其值为"backward",则扩展范围设置为[i - k] elif "context_expand_method" in doc.metadata and doc.metadata["context_expand_method"] == "backward": expand_range = [i - k] # 如果文本的元数据中没有context_expand_method字段,或者context_expand_method字段的值不是"forward"也不是"backward",则扩展范围设置为[i + k, i - k] else: expand_range = [i + k, i - k] # 遍历扩展范围 for l in expand_range: # 如果l不在id_set集合中,并且l在0到len(self.index_to_docstore_id)之间,则执行以下代码 if l not in id_set and 0 <= l < len(self.index_to_docstore_id): # 获取l对应的文本id _id0 = self.index_to_docstore_id[l] # 从文本库中搜索对应id的文本 doc0 = self.docstore.search(_id0) # 如果文本长度加上新文档的长度大于块大小,或者新文本的源不等于当前文本的源,则设置break_flag为true,跳出循环 if docs_len + len(doc0.page_content) > self.chunk_size or doc0.metadata["source"] != \ doc.metadata["source"]:break_flag = Truebreak # 如果新文本的源等于当前文本的源,则将新文本的长度添加到文本长度上,将l添加到id_set集合中,设置rearrange_id_list为true elif doc0.metadata["source"] == doc.metadata["source"]:docs_len += len(doc0.page_content)id_set.add(l)rearrange_id_list = True # 如果break_flag为true,则跳出循环 if break_flag: break # 如果不需要拆分块内容,或者不需要重新排列id列表,则返回docs列表 if (not self.chunk_conent) or (not rearrange_id_list): return docs # 如果id_set集合的长度为0,并且分数阈值大于0,则返回空列表 if len(id_set) == 0 and self.score_threshold > 0: return [] # 对id_set集合中的元素进行排序,并转换为列表 id_list = sorted(list(id_set)) # 调用seperate_list函数,将id_list分解成多个子列表 id_lists = self.seperate_list(id_list) # 遍历id_lists中的每一个id序列 for id_seq in id_lists: # 遍历id序列中的每一个id for id in id_seq: # 如果id等于id序列的第一个元素,则从文档库中搜索对应id的文本,并深度拷贝这个文本 if id == id_seq[0]: _id = self.index_to_docstore_id[id] # doc = self.docstore.search(_id) doc = copy.deepcopy(self.docstore.search(_id)) # 如果id不等于id序列的第一个元素,则从文本库中搜索对应id的文档,将新文本的内容添加到当前文本的内容后面 else: _id0 = self.index_to_docstore_id[id] doc0 = self.docstore.search(_id0) doc.page_content += " " + doc0.page_content # 如果搜索到的文本不是Document类型,则抛出异常 if not isinstance(doc, Document): raise ValueError(f"Could not find document for id {_id}, got {doc}") # 计算文本的分数,分数等于id序列中的每一个id在分数列表中对应的分数的最小值 doc_score = min([scores[0][id] for id in [indices[0].tolist().index(i) for i in id_seq if i in indices[0]]]) # 在文本的元数据中添加score字段,其值为文档的分数 doc.metadata["score"] = int(doc_score) # 将文本添加到docs列表中 docs.append(doc) # 返回docs列表 return docs3.8.4 delete_doc方法:删除文本库中指定来源的文本
#定义了一个名为 delete_doc 的方法,这个方法用于删除文本库中指定来源的文本 def delete_doc(self, source: str or List[str]): # 使用 try-except 结构捕获可能出现的异常 try: # 如果 source 是字符串类型 if isinstance(source, str): # 找出文本库中所有来源等于 source 的文本的id ids = [k for k, v in self.docstore._dict.items() if v.metadata["source"] == source] # 获取向量存储的路径 vs_path = os.path.join(os.path.split(os.path.split(source)[0])[0], "vector_store") # 如果 source 是列表类型 else: # 找出文本库中所有来源在 source 列表中的文本的id ids = [k for k, v in self.docstore._dict.items() if v.metadata["source"] in source] # 获取向量存储的路径 vs_path = os.path.join(os.path.split(os.path.split(source[0])[0])[0], "vector_store") # 如果没有找到要删除的文本,返回失败信息 if len(ids) == 0: return f"docs delete fail" # 如果找到了要删除的文本 else: # 遍历所有要删除的文本id for id in ids: # 获取该id在索引中的位置 index = list(self.index_to_docstore_id.keys())[list(self.index_to_docstore_id.values()).index(id)] # 从索引中删除该id self.index_to_docstore_id.pop(index) # 从文本库中删除该id对应的文本 self.docstore._dict.pop(id) # TODO: 从 self.index 中删除对应id,这是一个未完成的任务 # self.index.reset() # 保存当前状态到本地 self.save_local(vs_path) # 返回删除成功的信息 return f"docs delete success" # 捕获异常 except Exception as e: # 打印异常信息 print(e) # 返回删除失败的信息 return f"docs delete fail"3.8.5 update_doc和lists_doc
# 定义了一个名为 update_doc 的方法,这个方法用于更新文档库中的文档 def update_doc(self, source, new_docs): # 使用 try-except 结构捕获可能出现的异常 try: # 删除旧的文档 delete_len = self.delete_doc(source) # 添加新的文档 ls = self.add_documents(new_docs) # 返回更新成功的信息 return f"docs update success" # 捕获异常 except Exception as e: # 打印异常信息 print(e) # 返回更新失败的信息 return f"docs update fail" # 定义了一个名为 list_docs 的方法,这个方法用于列出文档库中所有文档的来源 def list_docs(self): # 遍历文档库中的所有文档,取出每个文档的来源,转换为集合,再转换为列表,最后返回这个列表 return list(set(v.metadata["source"] for v in self.docstore._dict.values()))第四部分 LLM与知识图谱的结合
4.1 LLM为何要与知识图谱相结合
通过本文之前或本博客内之前的内容可知,由于大部分LLM都是基于过去互联网旧的预训练语料训练、推理而来,由此会引发两大问题
- 无法获取最新的知识,为解决这个问题,ChatGPT plus版一开始是通过引入bing搜索这个插件去获取最新知识(不过 现因商业问题而暂时下架),而ChatGPT的竞品Claude则通过更新其预训练的数据 比如2013年的数据
- 面对少部分专业性比较强的问题,没法更好的回答,有时推理时会犯一些事实性的知识错误
面对第二个问题,我们在上文已经展示了可以通过与langchain结合搭建本地知识库的办法解决,此外,还可以考虑让LLM与知识图谱结合
- 知识图谱能以三元组(即头实体、关系、尾实体)的形式存储结构化知识,因此知识图谱是一种结构化和决断性的知识表征形式,例子包括 Wikidata、YAGO 和 NELL
- 知识图谱能提供准确、明确的知识,且还具有很棒的符号推理能力,这能生成可解释的结果
- 知识图谱还能随着新知识的持续输入而积极演进。当然 知识图谱本身也有其不足,比如泛化能力不足
根据所存储信息的不同,现有的知识图谱可分为四大类:百科知识型知识图谱、常识型知识图谱、特定领域型知识图谱、多模态知识图谱

而下图总结了 LLM 和知识图谱各自的优缺点

而实际上,LLM与知识图谱可以互相促进、增强彼此
- 如果用知识图谱增强 LLM,那么知识图谱不仅能被集成到 LLM 的预训练和推理阶段,从而用来提供外部知识,还能被用来分析 LLM 以提供可解释性
- 而在用 LLM 来增强知识图谱方面,LLM 已被用于多种与知识图谱相关的应用,比如知识图谱嵌入、知识图谱补全、知识图谱构建、知识图谱到文本的生成、知识图谱问答。LLM 能够提升知识图谱的性能并助益其应用
总之,在 LLM 与知识图谱协同的相关研究中,研究者将 LLM 和知识图谱的优点融合,让它们在知识表征和推理方面的能力得以互相促进
4.2 用知识图谱增强 LLM的预训练、推理、可解释性
今年6月份,一篇论文《Unifying Large Language Models and Knowledge Graphs: A Roadmap》指出,用知识图谱增强 LLM具体的方式有几种
- 一是使用知识图谱增强 LLM 预训练,其目的是在预训练阶段将知识注入到 LLM 中
- 二是使用知识图谱增强 LLM 推理,这能让 LLM 在生成句子时考虑到最新知识
- 三是使用知识图谱增强 LLM 可解释性,从而让我们更好地理解 LLM 的行为
下表总结了用知识图谱增强 LLM 的典型方法

4.2.1 使用知识图谱增强 LLM 预训练
现有的 LLM 主要依靠在大规模语料库上执行自监督训练。尽管这些模型在下游任务上表现卓越,它们却缺少与现实世界相关的实际知识。在将知识图谱整合进 LLM 方面,之前的研究可以分为三类:
- 将知识图谱整合进训练目标
如下图所示,通过文本 - 知识对齐损失将知识图谱信息注入到 LLM 的训练目标中,其中 h 表示 LLM 生成的隐含表征
- 将知识图谱整合进 LLM 的输入
如下图所示,使用图结构将知识图谱信息注入到 LLM 的输入中
- 将知识图谱整合进附加的融合模块
如下图所示,即通过附加的融合模块将知识图谱整合到 LLM 中
4.2.2 用知识图谱增强 LLM 推理
上文的方法可以有效地将知识与LLM中的文本表示进行融合。但是,真实世界的知识会变化,这些方法的局限是它们不允许更新已整合的知识,除非对模型重新训练。因此在推理时,它们可能无法很好地泛化用于未见过的知识(比如ChatGPT的预训练数据便截止到的2021年9月份,为解决这个知识更新的问题,它曾借助接入外部插件bing搜索去解决)
所以,相当多的研究致力于保持知识空间和文本空间的分离,并在推理时注入知识。这些方法主要关注的是问答QA任务,因为问答既需要模型捕获文本语义,还需要捕获最新的现实世界知识,比如
- 融合动态知识图谱用于LLM推理
具体而言,一种直接的方法是利用双塔架构,其中一个分离的模块处理文本输入,另一个处理相关的知识图谱输入。然而,这种方法缺乏文本和知识之间的交互
因此,KagNet建议首先对输入的KG进行编码,然后增强输入的文本表示。相比之下,MHGRN使用输入文本的最终LLM输出来指导推理
再比如,JointLK提出了一个框架,通过LM-to-KG和KG-to- lm双向注意机制,在文本输入中的任何tokens和任何KG实体之间进行细粒度交互(JointLK then proposes a framework with fine-grainedinteraction between any tokens in the textual inputs and anyKG entities through LM-to-KG and KG-to-LM bi-directionalattention mechanism)
如下图所示,在所有文本标记和KG实体上计算成对点积分数,分别计算双向注意分数(pairwise dot-product scores are calculated over all textual tokens and KGentities, the bi-directional attentive scores are computed sep-arately)
- 通过检索外部知识来增强 LLM 生成

更多细节在我司的langchain实战课程上见
4.2.3 用知识图谱增强 LLM 可解释性
// 待更..
4.3 用LLM增强知识图谱
// 待更..
4.4 LLM与知识图谱的协同
// 待更..
4.5 LLM结合KG的项目实战:知识抽取KnowLM
KnowLM是一个结合LLM能力的知识抽取项目,其基于llama 13b利用自己的数据+公开数据对模型做了pretrain,然后在pretrain model之上用指令语料做了lora微调,最终可以达到的效果如下图所示 (图源),当面对同一个输入input时,在分别给定4种不同指令任务instruction时,KnowLM可以分别得到对应的输出output

下图展示了训练的整个流程和数据集构造。整个训练过程分为两个阶段:
- 全量预训练阶段,该阶段的目的是增强模型的中文能力和知识储备
- 使用LoRA的指令微调阶段,该阶段让模型能够理解人类的指令并输出合适的内容

4.5.1 预训练数据集构建与训练过程
- 为了在保留原来的代码能力和英语能力的前提下,来提升模型对于中文的理解能力,他们并没有对词表进行扩增,而是搜集了中文语料、英文语料和代码语料,其中 中文语料来自于百度百科、悟道和中文维基百科 英文数据集是从LLaMA原始的英文语料中进行采样,不同的是维基数据,原始论文中的英文维基数据的最新时间点是2022年8月,他们额外爬取了2022年9月到2023年2月,总共六个月的数据 而代码数据集,由于
Pile数据集中的代码质量不高,他们去爬取了Github、Leetcode的代码数据,一部分用于预训练,另外一部分用于指令微调
对上面爬取到的数据集,他们使用了启发式的方法,剔除了数据集中有害的内容,此外,我们还剔除了重复的数据 - 详细的数据处理代码和训练代码、完整的训练脚本、详细的训练情况可以在./pretrain找到
在训练之前,首先需要对数据进行分词。他们设置的单个样本的最大长度是1024,而大多数的文档的长度都远远大于这个长度,因此需要对这些文档进行划分。设计了一个贪心算法来对文档进行切分,贪心的目标是在保证每个样本都是完整的句子、分割的段数尽可能少的前提下,尽可能保证每个样本的长度尽可能长
此外,由于数据源的多样性,设计了一套完整的数据预处理工具,可以对各个数据源进行处理然后合并
最后,由于数据量很大,如果直接将数据加载到内存,会导致硬件压力过大,于是他们参考了DeepSpeed-Megatron,使用mmap的方法对数据进行处理和加载,即将索引读入内存,需要的时候根据索引去硬盘查找
最后在5500K条中文样本、1500K条英文样本、900K条代码样本进行预训练。他们使用了transformers的trainer搭配Deepspeed ZeRO3 (实测使用ZeRO2在多机多卡场景的速度较慢),在3个Node(每个Node上为8张32GB V100卡)进行多机多卡训练。下表是训练速度:参数 值 micro batch size(单张卡的batch size大小) 20 gradient accumulation(梯度累积) 3 global batch size(一个step的、全局的batch size) 20*3*24=1440 一个step耗时 260s
4.5.2 指令微调数据集构建与指令微调训练过程
- 在目前千篇一律的模型中,除了要加入通用的能力(比如推理能力、代码能力等),还额外增加了信息抽取能力(包括
NER、RE、EE)。需要注意的是,由于许多开源的数据集,比如alpaca数据集CoT数据集代码数据集都是英文的,因此为了获得对应的中文数据集,对这些英文数据集使用GPT4进行翻译
有两种情况:
1. 直接对问题和答案进行成中文
2. 将英文问题输入给模型,让模型输出中文回答
对通用的数据集使用第二种情况,对于其他数据集如CoT数据集代码数据集使用第一种情况
对于信息抽取(IE)数据集,英文部分,使用CoNLLACECASIS等开源的IE数据集,构造相应的英文指令数据集。中文部分,不仅使用了开源的数据集如DuEE、PEOPLE DAILY、DuIE等,还采用了他们自己构造的KG2Instruction,构造相应的中文指令数据集
具体来说,KG2Instruction(InstructIE)是一个在中文维基百科和维基数据上通过远程监督获得的中文信息抽取数据集,涵盖广泛的领域以满足真实抽取需求
此外,他们额外手动构建了中文的通用数据集,使用第二种策略将其翻译成英文。最后我们的数据集分布如下:数据集类型 条数 COT(中英文) 202,333 通用数据集(中英文) 105,216 代码数据集(中英文) 44,688 英文指令抽取数据集 537,429 中文指令抽取数据集 486,768 - KG2Instruction及其他指令微调数据集

- 目前大多数的微调脚本都是基于alpaca-lora,因此此处不再赘述,另详细的指令微调训练参数、训练脚本可以在./finetune/lora找到
附录
- https://github.com/zjunlp/KnowLM
- https://github.com/kaixindelele/ChatSensitiveWords
利用LLM+敏感词库,来自动判别是否涉及敏感词 - https://github.com/XLabCU/gpt3-relationship-extraction-to-kg
- https://github.com/niris/KGExtract/blob/main/get_kg.py
- https://github.com/semantic-systems/coypu-LlamaKGQA/blob/main/knowledge_graph_coypu.py
- https://github.com/xixi019/coypu-LlamaKGQA
- https://github.com/jamesdouglaspearce/kg-llama-7b
- https://github.com/zhuojianc/financial_chatglm_KG
另外,这是:关于LLM与知识图谱的一席论文列表
第五部分 LLM与数据库的结合:DB-GPT
https://github.com/csunny/DB-GPT
5.1 DB-GPT的架构:用私有化LLM技术定义数据库下一代交互方式
DB-GPT基于 FastChat 构建大模型运行环境,并提供 vicuna 作为基础的大语言模型。此外,通过LangChain提供私域知识库问答能力,且有统一的数据向量化存储与索引:提供一种统一的方式来存储和索引各种数据类型,同时支持插件模式,在设计上原生支持Auto-GPT插件,具备以下功能或能力
- 根据自然语言对话生成分析图表、生成SQL
- 与数据库元数据信息进行对话, 生成准确SQL语句
- 与数据对话, 直接查看执行结果
- 知识库管理(目前支持 txt, pdf, md, html, doc, ppt, and url)
- 根据知识库对话, 比如pdf、csv、txt、words等等
- 支持多种大语言模型, 当前已支持Vicuna(7b,13b), ChatGLM-6b(int4,int8), guanaco(7b,13b,33b), Gorilla(7b,13b), llama-2(7b,13b,70b), baichuan(7b,13b)
整个DB-GPT的架构,如下图所示(图源)

5.2 DB-GPT的应用
通过QLoRA(4-bit级别的量化+LoRA)的方法,用3090在DB-GPT上打造基于33B LLM的个人知识库
// 待更
更多课上见:七月LLM与langchain/知识图谱/数据库的实战 [解决问题、实用为王]
参考文献与推荐阅读
- langchain官网:LangChain、https://python.langchain.com/,API列表:https://api.python.langchain.com/en/latest/api_reference.html
langchain中文网(翻译暂不佳) - LangChain全景图
- 一文搞懂langchain(忽略本标题,因为单看此文还不够)
- How to Build a Smart Chatbot in 10 mins with LangChain
- 关于FAISS的几篇教程:Faiss入门及应用经验记录、
- QLoRA:4-bit级别的量化+LoRA方法,用3090在DB-GPT上打造基于33B LLM的个人知识库
- 基于LangChain+LLM构建增强QA、用LangChain构建大语言模型应用、LangChain 是什么
- LangChain 中文入门教程
- 大型语言模型与知识图谱协同研究综述:两大技术优势互补
- csunny/DB-GPT,https://db-gpt.readthedocs.io/en/latest/
- 关于KBQA的一系列论文:RUCAIBox / Awesome-KBQA
- 七月LLM与langchain/知识图谱/数据库的实战 [解决问题、实用为王]
后记
本文经历了三个阶段
- 对langchain的梳理
langchain的组件很多,想理解透彻的话,需要一步步来
包括我自己刚开始看这个库的时候 真心是晕,无从下手,后来10天过后,可以直接一个文件一个文件的点开 直接看..
总之,凡事都是一个过程 - 对langchain-ChatGLM项目源码的解读
说实话,一开始也是挺晕的,因为各种项目文件又很多,好在后来历时一周总算梳理清楚了 - LLM与知识图谱、数据库的结合
创作、修改、优化记录
- 7.5-7.9日,每天写一一部分
- 7.10,完善第一部分关于什么是langchain的介绍
- 7.11,根据langchain-ChatGLM项目的最新更新,整理已写内容
- 7.12 写完前3.8节,且根据项目流程调整各个文件夹的解读顺序
相当于历时近一周,总算把 “langchain-ChatGLM的整体代码架构” 梳理清楚了 - 7.15,补充langchain架构相关的内容,且为方便理解,把整个langchain库划分为三个大层:基础层、能力层、应用层
- 7.17,开始写第四部分,重点是4.2节:用知识图谱增强 LLM的预训练、推理、可解释性
- 7.26,续写第四部分,开始更新第五部分:LLM与数据库的结合
来源地址:https://blog.csdn.net/v_JULY_v/article/details/131552592








{kind=link}
{kind=link}