
本篇内容介绍了“适合面向ChatGPT编程的架构源码分析”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
新的需求
我们前面爬虫的需求呢,有些平台说因为引起争议,所以不让发,好吧,那我们换个需求,本来那个例子也不好扩展了。最近AI画图也是比较火的,那么我们来试试做个程序帮我们生成AI画图的prompt。
首先讲一下AI话题的prompt的关键要素,大部分的AI画图都是有一个个由逗号分割的关键字,也叫subject,类似下面这样:
a cute cat, smile, running, look_at_viewer, full_body, side_view,然后还有negative prompt,就是你不想出现的关键字,跟上面的写法一样,只是写下来表示不希望它画出来的,比如我们想画一堆猫的图片,不想出现狗,不想出现人,我们可以这么写:
dog, human,这样大概率就不会出现狗和人了(当然也不一定,懂得都懂)。
领域知识
那么说干就干,开始之前要了解一下领域知识。
首先是关键字,在这个需求里只是基础知识,没有什么难的,大概有下面几条规则:
内容,这些关键字呢,说是关键字,其实你写一句话也没人管你。简化处理,我们这里就只用词和短语。另外,空格可以用下划线代替,这样可能会避免被分词,具体我也不确定,没有深入研究。但是这个不重要,可以完全看成两种关键字去排列组合好了。
关键字是可以有权重的,通常的表达方式是:
(a cute cat:1.5)这个很重要,通常我们想尝试好的方式,需要给每个关键字设置权重。
LoRA,英文全称Low-Rank Adaptation of Large Language Models,直译为大语言模型的低阶适应,这是微软的研究人员为了解决大语言模型微调而开发的一项技术,在我们这个场景下就是我们多了一种关键字,这种关键字大概是这么写:
<lora:wanostyle_2_offset:1>, monkey d luffy,它多了一些尖括号,也有权重,同时他会被其他关键字触发,比如上面这个就可以画个海贼王风格的路飞出来。
但总的来说,对关键字本身的建模影响不大
接着我们来了解一下排列组合的逻辑,这个将是我们的关键难点。
在这个领域,影响生成的因素主要有几个:
模型
sample
step
宽高
seed
negative prompt
prompt
在prompt中我们的关键字还可以根据使用目的分类,比如于生成画面风格的、用于生成背景的、用于生成人物的、用于成表情的等等
在prompt中,关键字的摆放顺序有时候还会造成点不同。
还有更复杂的Control Net,这个例子里我们先不考虑。
生成的时候,某些关键字要获得最好的效果,可能自己对模型、sample以及其他关键字的存在和权重都有自己的要求,比某关键字在某模型下权重为0.3,而在另一个模型下权重需要0.7。比如路飞会带草帽,那么这个人物出现的时候,必须配上帽的关键字才对味,而其他的人物就不要跟草帽组合了,又浪时间又没有意义。所以组合上要考虑各种因素之间的互斥和强依赖等场景。
架构设计
好,这大概是一个比较复杂的需求了。回到上篇文章遗留的问题,聊聊当我们面对一个比较复杂的需求,而且我们接下来要用ChatGPT把它实现的时候,我们应该怎么设计架构。
管道架构
在这个需求里,我们首先要知道,这类AI都是有REST API的,比如说stable diffusion WebUI,就有一个自己的API,他们的API接受一个固定格式的JSON,其结构大概是这个样子:
{"prompt": "","negative_prompt": "","controlnet_input_image": [],"controlnet_mask": [],"controlnet_module": "","controlnet_model": "","controlnet_weight": 1,"controlnet_resize_mode": "Scale to Fit (Inner Fit)","controlnet_lowvram": true,"controlnet_processor_res": 512,"controlnet_threshold_a": 64,"controlnet_threshold_b": 64,"controlnet_guidance": 1,"controlnet_guessmode": true,"enable_hr": false,"denoising_strength": 0.5,"hr_scale": 1.5,"hr_upscale": "Latent","seed": -1,"subseed": -1,"subseed_strength": -1,"sampler_index": "","batch_size": 1,"n_iter": 1,"steps": 20,"cfg_scale": 7,"width": 512,"height": 512,"restore_faces": true,"override_settings": {},"override_settings_restore_afterwards": true}那么这就是类似他们的意图描述,可以把它看成一种DSL。
而在我们这个领域里,我们要做的是排列组合,那么对于排列组合,我们要设计我们排列组合的意图描述,这可以看成另一种DSL,这种DSL只作简单排列组合,不做复杂的互斥和强依赖逻辑的计算,其结构可能是这个样子:
- base_share_composite_intentions: base: steps: 10 batch_size: 1 width: 512 height: 512 cfg_scale: 7 sampler: "Euler a" seed: -1 restore_faces: true output_folder: output/txt2img file_full_name_strategy: date_seed_name_strategy sd_host: http://localhost:7860 negative_prompt: a dog poly: - template_prompt: template: > a cat, ${ view_angle } ${ portrait } ${ facial_expressions } ${ pose } meta: - view_angle: - side_view, - front_view, portrait: - full body, facial_expressions: - (smile:1.5), - (smile:1.2), - smile, pose: "" - view_angle: - front_view, portrait: - "" facial_expressions: - smile, pose: - run, - jump, - rolling, steps: 20然后在这个DSL之上,我们可以再做一个DSL,这个DSL用于处理复杂的互斥和强依赖逻辑的计算,前面说了那么多,真正这个地方到底有多复杂我也想不清楚。那干脆,搞个模板引擎来吧,这就什么都能干了,慢慢搞明白了再封装。最终其结构可能是这个样子:
<% const randomNum = Math.floor(Math.random() * 900000000) + 100000000;var intention = { is_override_settings: true, seed: randomNum,}%><% var status = {charas:{ values_of_chara_$ref: [ "cats.yml#Abyssinian", "cats.yml#cats_in_boots", ], current_chara_index: 0, next_chara(){ this.current_chara_index++; }},themes:{ values_of_theme: [ { $ref: "outdoor" }, ], current_theme_index: 0, next_theme(){ this.current_theme_index++; }, reset_theme(){ this.current_theme_index = 0; }}}%><%common_theme_file = "common/chara_based_themes.yml"%><% while (status.charas.current_chara_index < status.charas.values_of_chara_$ref.length) { %>- base_share_composite_intentions: common: theme: base: steps: 20 batch_size: 1 width: 512 height: 512 cfg_scale: 7 sampler: "DPM++ 2M Karras" seed: <%- intention.seed %> restore_faces: false output_folder: output/txt2img file_full_name_strategy: date_seed_name_strategy sd_host: http://localhost:7860 <% if(intention.is_override_settings){ %> override_settings: CLIP_stop_at_last_layers: 2 eta_noise_seed_delta: 31337 <%}%> negative_prompt: > dog, human, bad anatomy, EasyNegative,paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, poly: <% while (status.themes.current_theme_index < status.themes.values_of_theme.length) { %> - $p_ref: $ref: "<%-common_theme_file%>#<%- status.themes.values_of_theme[status.themes.current_theme_index].$ref%>" params: base_prompt_features: $p_ref: $ref: <%- status.charas.values_of_chara_$ref[status.charas.current_chara_index] %> params: is_full_chara: true chara_weight: 0.2 pose: sit facial_expressions: (smile:1.1),(open mouth), - $p_ref: $ref: "<%-common_theme_file%>#<%- status.themes.values_of_theme[status.themes.current_theme_index].$ref%>" params: base_prompt_features: $p_ref: $ref: <%- status.charas.values_of_chara_$ref[status.charas.current_chara_index] %> params: is_full_chara: true chara_weight: 0.6 pose: run facial_expressions: (smile:1.2),(closed mouth), <% status.themes.next_theme(); %> <% } %><% status.themes.reset_theme(); %><% status.charas.next_chara(); %><% } %>于是我们有了三个DSL,他们层层转换,最终驱动AI画图。那么我们的程序可能就会是下面这个样子:

可以看出,这样我们就得到了大名鼎鼎的管道架构,经常使用Linux/Unix命令行的人,可能已经体会过管道架构恐怖的扩展能力,这次我们只能说,是Linux/Unix哲学再一次展现出威力。
我们之前讲了,ChatGPT可以快速写出一些小程序,但是长一点的总是会出错,那么其实除了从规模上进行分解将任务复杂度降低之外,通过抽象建立分层的DSL也是一种降低复杂度的方案。
分层架构
说到分层,其实从另一个角度看,我们这个架构也是一个分层架构。
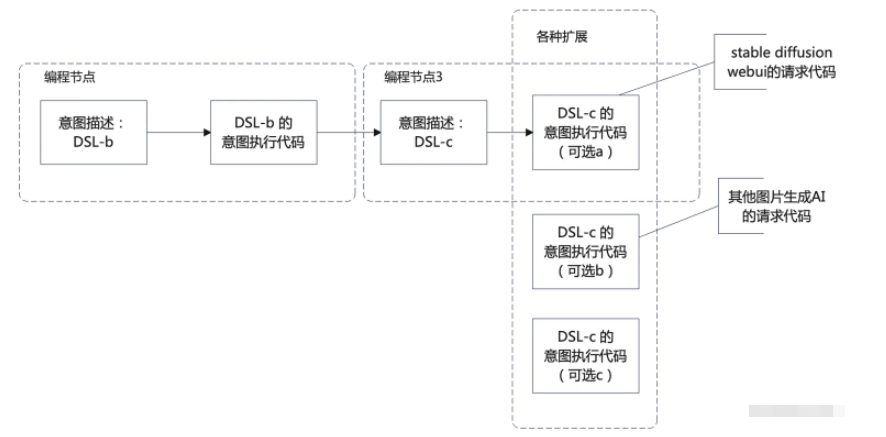
可以看到,我们可以轻易地替换调用不同REST API的代码以做到对于不同AI的适配,实现了隔离。
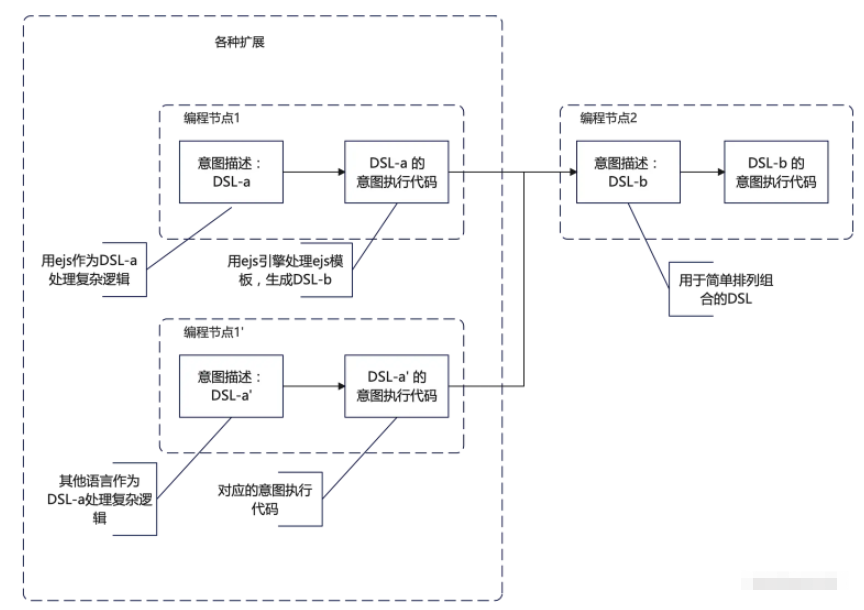
同理,不但意图执行可以切换,意图描述也可以跟着切换:
既可以有技术维度上的扩展,也可以有业务维度上的扩展:
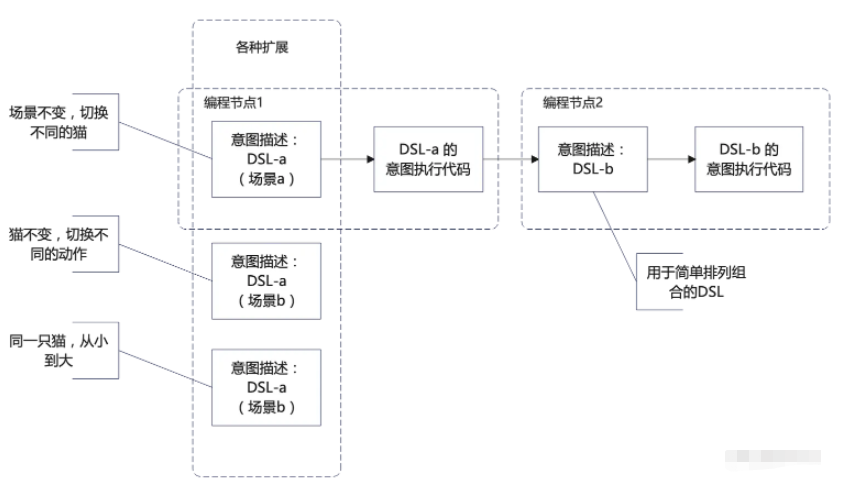
所以从这个角度来说,每一个管段,都是可以看作是一层。
类分层神经网络的架构
而到这还不算完,具体在执行的时候,可能受环境的影响,可能受上层意图影响等等,总之是需要进行每一层的路径选择的。这种选择,可能是由另一个引擎来完成的。那么最终我们的架构的完整形态他可能是这个样子的:
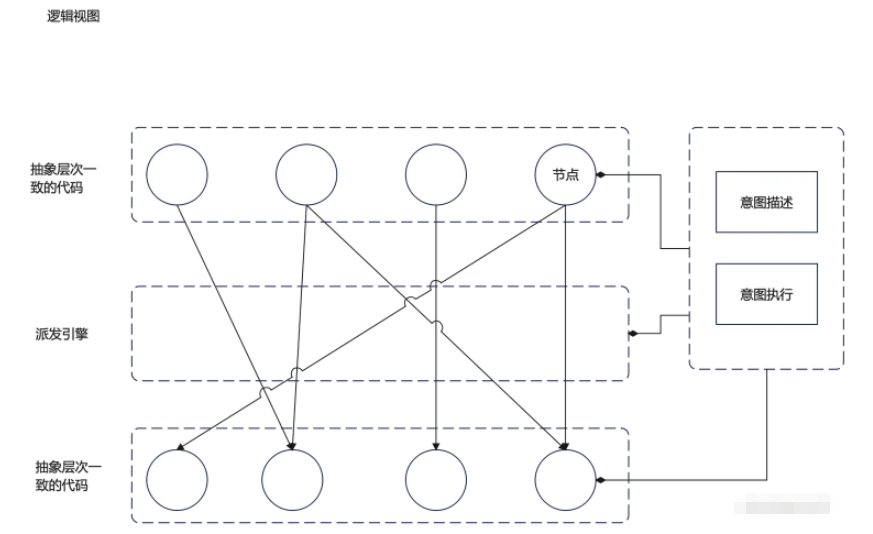
当然其运行视图可能是这样的:
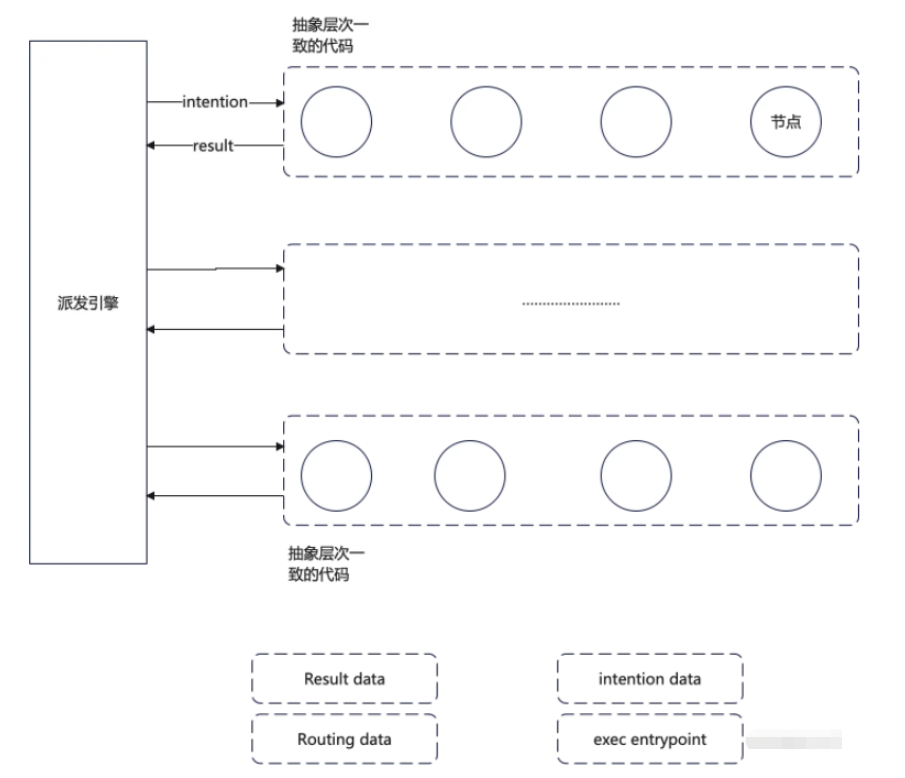
到此,我们得到了我们架构比较完整的形态,他是一个集成了管道架构和分层架构,在一个派发引擎的支撑下的一个类分层神经网络的结构。
“适合面向ChatGPT编程的架构源码分析”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注编程网网站,小编将为大家输出更多高质量的实用文章!








