
索引构建完成后又是如何去持久化数据的呢?保存的数据又是怎样的格式呢?本节我们将对此进行详细讲解。
前文我们介绍了当插入数据的时候会先去添加索引数据,索引构建完成后又是如何去持久化数据的呢?保存的数据又是怎样的格式呢?本节我们将对此进行详细讲解。
添加索引数据
索引构建完成后会调用 AddItems 函数将索引添加到 Table 中去:
复制
1. // lib/mergeset/table.go
2. // AddItems 添加指定的 items 到 table 中去
3. func (tb *Table) AddItems(items [][]byte) error {
4. if err := tb.rawItems.addItems(tb, items); err != nil {
5. return fmt.Errorf("cannot insert data into %q: %w", tb.path, err)
6. }
7. return nil
8. }
Table 的结构如下所示:
复制
1. // lib/mergeset/table.go
2. // Table 代表 mergeset table.
3. type Table struct {
4. activeMerges uint64
5. mergesCount uint64
6. itemsMerged uint64
7. assistedMerges uint64
8. // merge 索引
9. mergeIdx uint64
10. // 路径
11. path string
12. // flush回调
13. flushCallback func()
14. flushCallbackWorkerWG sync.WaitGroup
15. needFlushCallbackCall uint32
16. // 在将指定项的整个块刷新到持久存储之前,在合并期间调用的回调
17. prepareBlock PrepareBlockCallback
18. // parts 列表
19. partsLock sync.Mutex
20. parts []*partWrapper
21. // rawItems 包含最近添加的尚未转换为 parts 的数据
22. // 出于性能原因,未在搜索中使用 rawItems
23. rawItems rawItemsShards
24. snapshotLock sync.RWMutex
25. flockF *os.File
26. stopCh chan struct{}
27. partMergersWG syncwg.WaitGroup
28. rawItemsFlusherWG sync.WaitGroup
29. convertersWG sync.WaitGroup
30. rawItemsPendingFlushesWG syncwg.WaitGroup
31. }
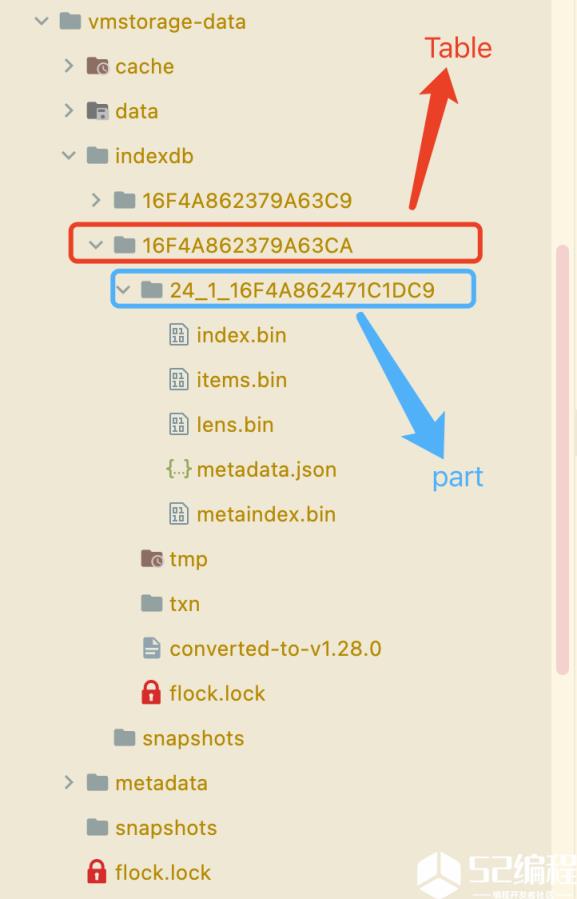
一个索引 Table 就对应着一个 indexDB,也就是数据目录 indexdb 下面的文件夹:
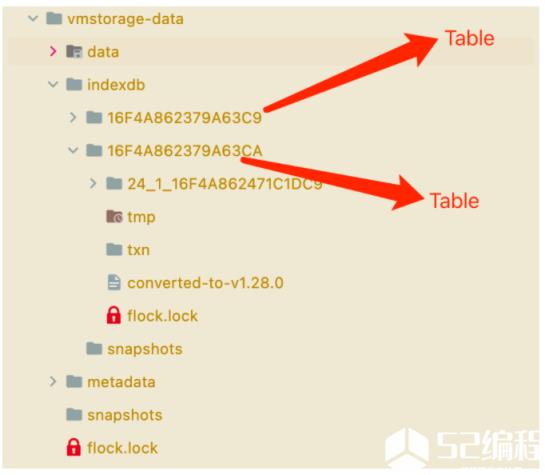
其中核心的是 parts 和 rawItems 两个属性。
parts 主要是存储 merge 后的 blocks,一个part 与文件系统上的一个目录对应,比如上图中的24_1_16F4A862471C1DC9 目录就是一个part。
rawItems 是用于预处理Items 的,是一个rawItemsShards 对象。
rawItemsShards 结构体定义如下所示:
复制
1. // lib/mergeset/table.go
2. type rawItemsShards struct {
3. shardIdx uint32
4. // 在多 cpu 系统上添加 rows 数据时,shards 分片可以减少锁竞争
5. shards []rawItemsShard
6. }
7. // 每个 table 的 rawItems 分片数
8. var rawItemsShardsPerTable = cgroup.AvailableCPUs()
9. // 每个分片最大的Block数
10. const maxBlocksPerShard = 512
11. // 当在打开Table的时候就会调用该函数进行初始化
12. func (riss *rawItemsShards) init() {
13. riss.shards = make([]rawItemsShard, rawItemsShardsPerTable)
14. }
15. // 添加 items 元素
16. func (riss *rawItemsShards) addItems(tb *Table, items [][]byte) error {
17. n := atomic.AddUint32(&riss.shardIdx, 1)
18. shards := riss.shards
19. idx := n % uint32(len(shards))
20. shard := &shards[idx]
21. return shard.addItems(tb, items)
22. }
rawItemsShards 其实就是加了一个分片功能用于保存索引数据,addItems 函数就是将要添加的数据添加到对应的分片上去,最终执行的逻辑是 shard.addItems。
复制
1. // lib/mergeset/table.go
2. type rawItemsShard struct {
3. mu sync.Mutex
4. ibs []*inmemoryBlock
5. lastFlushTime uint64
6. }
7. // 添加items元素
8. func (ris *rawItemsShard) addItems(tb *Table, items [][]byte) error {
9. var err error
10. var blocksToFlush []*inmemoryBlock
11. ris.mu.Lock()
12. ibs := ris.ibs
13. if len(ibs) == 0 {
14. ib := getInmemoryBlock()
15. ibs = append(ibs, ib)
16. ris.ibs = ibs
17. }
18. // 取最后一个内存块
19. ib := ibs[len(ibs)-1]
20. for _, item := range items {
21. // 添加索引item到内存块
22. if !ib.Add(item) { // 超过了内存块大小
23. // 重新获取一个内存块,此时肯定为空
24. ib = getInmemoryBlock()
25. // 重新添加
26. if !ib.Add(item) {
27. putInmemoryBlock(ib)
28. err = fmt.Errorf("cannot insert an item %q into an empty inmemoryBlock; it looks like the item is too large? len(item)=%d", item, len(item))
29. break
30. }
31. ibs = append(ibs, ib)
32. ris.ibs = ibs
33. }
34. }
35. // 超过了每个分片的最大内存块的数量
36. if len(ibs) >= maxBlocksPerShard {
37. // 将内存块放到待刷新的内存块列表中去
38. blocksToFlush = append(blocksToFlush, ibs...)
39. // 释放前面的内存块资源
40. for i := range ibs {
41. ibs[i] = nil
42. }
43. ris.ibs = ibs[:0]
44. ris.lastFlushTime = fasttime.UnixTimestamp()
45. }
46. ris.mu.Unlock()
47. // 执行merge合并操作
48. tb.mergeRawItemsBlocks(blocksToFlush, false)
49. return err
50. }
51. // lib/mergeset/encoding.go
52. // 内存中的一个Block块结构
53. type inmemoryBlock struct {
54. commonPrefix []byte
55. data []byte // 用来存储数据
56. items []Item // 用来存储每个item数据的起始偏移量
57. }
58. // Item 表示用于存储在 mergeset 中的单个 item 数据
59. type Item struct {
60. // 数据的开始偏移量
61. Start uint32
62. // 数据的结束偏移量
63. End uint32
64. }
65. // maxInmemoryBlockSize 是 memoryblock.data 的最大值。
66. //
67. // 它必须适合 CPU 缓存大小,即当前 CPU 的缓存大小为64kb。
68. const maxInmemoryBlockSize = 64 * 1024
69. // Add 将 x 添加到内存卡 ib 的末尾
70. //
71. // 如果由于块大小限制,x 未添加到 ib,则返回 false
72. func (ib *inmemoryBlock) Add(x []byte) bool {
73. data := ib.data
74. // 操过块大小限制了
75. if len(x)+len(data) > maxInmemoryBlockSize {
76. return false
77. }
78. if cap(data) == 0 {
79. // 预分配 data 和 items 以减少内存分配
80. data = make([]byte, 0, maxInmemoryBlockSize)
81. ib.items = make([]Item, 0, 512)
82. }
83. dataLen := len(data)
84. data = append(data, x...) // 将 x 添加到 data
85. ib.items = append(ib.items, Item{ // 更新 items
86. Start: uint32(dataLen),
87. End: uint32(len(data)),
88. })
89. ib.data = data
90. return true
91. }
rawItemsShard 表示保存索引数据的一个分片,里面其实就是一个 inmemoryBlock 的内存块切片,每个分片最多有 512 个内存块,每个内存块占用 64KB 的容量,当每个分片中的内存块数量超过最大数量(512)会去将内存块数据刷新为 Part。
如果分片中的内存块数量没超过上限,则会通过一个任务去定时(1s)将 rawItem 数据刷新(转换)为 Part,以便它们对搜索可见。
复制
1. // lib/mergeset/table.go
2. // 将最近的 rawItem 刷新(转换)为 Part,以便它们对搜索可见。
3. const rawItemsFlushInterval = time.Second
4. // 启动 rawItems Flusher 任务
5. func (tb *Table) startRawItemsFlusher() {
6. tb.rawItemsFlusherWG.Add(1)
7. go func() {
8. tb.rawItemsFlusher()
9. tb.rawItemsFlusherWG.Done()
10. }()
11. }
12. func (tb *Table) rawItemsFlusher() {
13. ticker := time.NewTicker(rawItemsFlushInterval)
14. defer ticker.Stop()
15. for {
16. select {
17. case <-tb.stopCh:
18. return
19. case <-ticker.C:
20. tb.flushRawItems(false)
21. }
22. }
23. }
合并内存数据
将内存块数据转换为 Part 都是通过 mergeRawItemsBlocks 函数去实现的。
复制
1. // lib/mergeset/table.go
2. // 一次合并的默认 parts 数
3. //
4. // 这个数字是根据经验得出的,它提供了尽可能低的开销
5. // 有关详细信息,请参阅 appendPartsToMerge test
6. const defaultPartsToMerge = 15
7. // merge 内存块数据
8. func (tb *Table) mergeRawItemsBlocks(ibs []*inmemoryBlock, isFinal bool) {
9. if len(ibs) == 0 {
10. return
11. }
12. tb.partMergersWG.Add(1)
13. defer tb.partMergersWG.Done()
14. pws := make([]*partWrapper, 0, (len(ibs)+defaultPartsToMerge-1)/defaultPartsToMerge)
15. var pwsLock sync.Mutex
16. var wg sync.WaitGroup
17. for len(ibs) > 0 {
18. // 一次最大合并的内存块数量
19. n := defaultPartsToMerge
20. if n > len(ibs) {
21. n = len(ibs)
22. }
23. wg.Add(1)
24. go func(ibsPart []*inmemoryBlock) {
25. defer wg.Done()
26. // merge inmemoryBlock
27. pw := tb.mergeInmemoryBlocks(ibsPart)
28. if pw == nil {
29. return
30. }
31. pw.isInMerge = true
32. pwsLock.Lock()
33. pws = append(pws, pw)
34. pwsLock.Unlock()
35. }(ibs[:n])
36. ibs = ibs[n:]
37. }
38. wg.Wait()
39. if len(pws) > 0 {
40. if err := tb.mergeParts(pws, nil, true); err != nil {
41. logger.Panicf("FATAL: cannot merge raw parts: %s", err)
42. }
43. if tb.flushCallback != nil {
44. if isFinal {
45. tb.flushCallback()
46. } else {
47. atomic.CompareAndSwapUint32(&tb.needFlushCallbackCall, 0, 1)
48. }
49. }
50. }
51. for {
52. tb.partsLock.Lock()
53. ok := len(tb.parts) <= maxParts
54. tb.partsLock.Unlock()
55. if ok {
56. return
57. }
58. // The added part exceeds maxParts count. Assist with merging other parts.
59. //
60. // Prioritize assisted merges over searches.
61. storagepacelimiter.Search.Inc()
62. err := tb.mergeExistingParts(false)
63. storagepacelimiter.Search.Dec()
64. if err == nil {
65. atomic.AddUint64(&tb.assistedMerges, 1)
66. continue
67. }
68. if errors.Is(err, errNothingToMerge) || errors.Is(err, errForciblyStopped) {
69. return
70. }
71. logger.Panicf("FATAL: cannot merge small parts: %s", err)
72. }
73. }
mergeRawItemsBlocks 函数将指定的内存块进行 merge 合并操作,一次合并最大的内存块数量为 15,然后在独立的 goroutine 中去进行合并操作,使用 mergeInmemoryBlocks 函数。
复制
1. // lib/mergeset/table.go
2. // merge InmemoryBlocks
3. func (tb *Table) mergeInmemoryBlocks(ibs []*inmemoryBlock) *partWrapper {
4. // 将 InmemoryBlock 列表转换成 inmemoryPart 列表
5. // inmemoryPart 表示内存中的Part
6. mps := make([]*inmemoryPart, 0, len(ibs))
7. for _, ib := range ibs {
8. if len(ib.items) == 0 {
9. continue
10. }
11. mp := getInmemoryPart()
12. mp.Init(ib) // 将inmemoryBlock转换为inmemoryPart
13. putInmemoryBlock(ib)
14. mps = append(mps, mp)
15. }
16. if len(mps) == 0 {
17. return nil
18. }
19. if len(mps) == 1 {
20. // 没有要合并的内容。只需返回单个 inmemory part。
21. mp := mps[0]
22. p := mp.NewPart()
23. return &partWrapper{
24. p: p,
25. mp: mp,
26. refCount: 1,
27. }
28. }
29. defer func() {
30. for _, mp := range mps {
31. putInmemoryPart(mp)
32. }
33. }()
34. atomic.AddUint64(&tb.mergesCount, 1)
35. atomic.AddUint64(&tb.activeMerges, 1)
36. defer atomic.AddUint64(&tb.activeMerges, ^uint64(0))
37. // 为每个 `inmemoryPart` 构造 `blockStreamReader`, 用于迭代读取 items
38. bsrs := make([]*blockStreamReader, 0, len(mps))
39. for _, mp := range mps {
40. bsr := getBlockStreamReader()
41. bsr.InitFromInmemoryPart(mp)
42. bsrs = append(bsrs, bsr)
43. }
44. // 准备一个 blockStreamWriter 用于合并写入的 part
45. bsw := getBlockStreamWriter()
46. // 不要通过 getInmemoryPart() 获取 mpDst,因为与池中的其他条目相比,它的大小可能太大。
47. // 这可能会导致内存使用量增加,因为存在大量的碎片。
48. // 创建一个新的 inmemoryPart,接收合并的数据
49. mpDst := &inmemoryPart{}
50. bsw.InitFromInmemoryPart(mpDst)
51. // 开始 merge 数据
52. // 该 merge 不应该被 stopCh 中断,因为它可能是 stopCh 关闭后的最终结果
53. err := mergeBlockStreams(&mpDst.ph, bsw, bsrs, tb.prepareBlock, nil, &tb.itemsMerged)
54. if err != nil {
55. logger.Panicf("FATAL: cannot merge inmemoryBlocks: %s", err)
56. }
57. putBlockStreamWriter(bsw)
58. for _, bsr := range bsrs {
59. putBlockStreamReader(bsr)
60. }
61. p := mpDst.NewPart()
62. return &partWrapper{
63. p: p,
64. mp: mpDst,
65. refCount: 1,
66. }
67. }
上面的函数会将指定的内存块转换成 partWrapper,该结构就是一个包含 part 和 inmemoryPart 的包装器。
复制
1. // lib/mergeset/table.go
2. type partWrapper struct {
3. p *part
4. mp *inmemoryPart
5. refCount uint64
6. isInMerge bool
7. }
part 的结构如下所示:
复制
1. // lib/mergeset/part.go
2. type part struct {
3. ph partHeader
4. path string
5. size uint64
6. mrs []metaindexRow
7. indexFile fs.MustReadAtCloser
8. itemsFile fs.MustReadAtCloser
9. lensFile fs.MustReadAtCloser
10. }
一个 part 就是 Table 下面的一个数据目录。
part 中包含一个 partHeader,该属性中包含当前 part 的一些 Meta 信息,一共有多少个 items、有多少 blocks、第一个和最后一个 item,对应着 part 目录下面的 metadata.json 文件。
复制
1. // lib/mergeset/part_header.go
2. type partHeader struct {
3. // part 包含的 items 数
4. itemsCount uint64
5. // part 包含的 blocks 数
6. blocksCount uint64
7. // part 中的第一个 item
8. firstItem []byte
9. // part 中的最后一个 item
10. lastItem []byte
11. }
part 中另外的属性 path 表示当前 part 的路径,size 表示大小,另外三个属性 indexFile、itemsFile、lensFile 对应中 part 目录下面的三个文件:index.bin、items.bin、lens.bin。此外 part 结构中还有最后一个 mrs 属性,是一个 []metaindexRow。
复制
1. // lib/mergeset/metaindex_row.go
2. // metaindexRow 描述了一个 blockHeaders 即索引块。
3. type metaindexRow struct {
4. // 第一个 block 中的第一个 item 元素
5. // 它用于快速查找所需的索引块
6. firstItem []byte
7. // 块包含的 blockHeaders 的数量
8. blockHeadersCount uint32
9. // 索引文件中块的偏移量
10. indexBlockOffset uint64
11. // 索引文件中块的大小
12. indexBlockSize uint32
13. }
除了 part 之外还有一个内存中的 inmemoryPart 结构,其基本结构和 part 类似,不同的是几个相关的属性不是文件对象,而是 ByteBuffer,因为是内存中的结构。
复制
1. // lib/mergeset/inmemory_part.go
2. // 在内存中的 Part 结构
3. type inmemoryPart struct {
4. // partHeader 记录 itemsCount, blocksCount, firstItem, lastItem 信息, 最后会序列化到 metadata.json
5. ph partHeader
6. // 当前 block 的 header 信息,有 commonPrefix, firstItem, marshalType, itemsCount, itemsBlockOffset, lenBlockOffset, itemsBlockSize, lenBlockSize
7. bh blockHeader
8. // 当前 block 的 metaindex 信息,存储了当前 blockHeader 的 firstItem, blockHeaderCount, indexBlockOffset, indexBlockSize
9. mr metaindexRow
10. // 用于序列化后写入内存/磁盘文件使用
11. metaindexData bytesutil.ByteBuffer // -> metaindex.bin
12. indexData bytesutil.ByteBuffer // -> index.bin
13. itemsData bytesutil.ByteBuffer // -> items.bin
14. lensData bytesutil.ByteBuffer // -> lens.bin
15. }
其他几个属性上面介绍过,blockHeader 结构如下所示,用于记录 block 头信息:
复制
1. // lib/mergeset/block_header.go
2. type blockHeader struct {
3. // 块中所有 items 的公用前缀
4. commonPrefix []byte
5. // 第一个 item
6. firstItem []byte
7. // 用于块压缩的 Marshal 类型
8. marshalType marshalType
9. // 块中的 items 数,不包括第一个 item
10. itemsCount uint32
11. // items block 的偏移量
12. itemsBlockOffset uint64
13. // lens block 的偏移量
14. lensBlockOffset uint64
15. // items block 的大小
16. itemsBlockSize uint32
17. // lens block 的大小
18. lensBlockSize uint32
19. }
整个 part 的结构看上去确实比较复杂,为什么需要设计这些属性?核心肯定就是为了快速索引,我们先往下分析,待会再回过头来看。
inmemoryPart 是 part 读入内存中的结构, 在 inmemoryBlock merge 之前,每个 inmemoryBlock 都会先通过 mp.Init 转换成一个 inmemoryPart 的结构,inmemoryPart 中 metaindexData、indexData、itemsData、lensData 数据结构与磁盘对应的文件内容一致。
序列化数据
现在我们再回到上面的 mergeInmemoryBlocks 函数,流程如下所示:
1.将所有的inmemoryBlock 转换为inmemoryPart 结构。
2.为每个inmemoryPart 构造blockStreamReader,用于迭代读取 items。
3.创建一个新的inmemoryPart,并构造一个blockSteamWriter 用于合并写入的数据。
4.然后调用mergeBlockStreams 函数执行真正的merge操作。
首先通过 Init 函数将 inmemoryBlock 转换为 inmemoryPart 结构。
复制
1. // lib/mergeset/inmemory_part.go
2. // Init 初始化 mp 从 ib.
3. func (mp *inmemoryPart) Init(ib *inmemoryBlock) {
4. mp.Reset()
5. sb := &storageBlock{}
6. sb.itemsData = mp.itemsData.B[:0]
7. sb.lensData = mp.lensData.B[:0]
8. // 使用尽可能小的压缩等级来压缩 inmemoryPart,因为它很快就会被合并到文件 part 去。
9. compressLevel := -5
10. // 序列化乱序的数据
11. mp.bh.firstItem, mp.bh.commonPrefix, mp.bh.itemsCount, mp.bh.marshalType = ib.MarshalUnsortedData(sb, mp.bh.firstItem[:0], mp.bh.commonPrefix[:0], compressLevel)
12. // 获取 partHeader 值
13. mp.ph.itemsCount = uint64(len(ib.items))
14. mp.ph.blocksCount = 1
15. mp.ph.firstItem = append(mp.ph.firstItem[:0], ib.items[0].String(ib.data)...)
16. mp.ph.lastItem = append(mp.ph.lastItem[:0], ib.items[len(ib.items)-1].String(ib.data)...)
17. // 获取itemsData,更新blockHeader的items偏移和数量
18. mp.itemsData.B = sb.itemsData
19. mp.bh.itemsBlockOffset = 0
20. mp.bh.itemsBlockSize = uint32(len(mp.itemsData.B))
21. // 获取lensData,更新blockHeader的lens偏移和数量
22. mp.lensData.B = sb.lensData
23. mp.bh.lensBlockOffset = 0
24. mp.bh.lensBlockSize = uint32(len(mp.lensData.B))
25. // 获取 indexData,blockHeader序列化的值
26. bb := inmemoryPartBytePool.Get()
27. bb.B = mp.bh.Marshal(bb.B[:0])
28. mp.indexData.B = encoding.CompressZSTDLevel(mp.indexData.B[:0], bb.B, 0)
29. // 获取 metaindexData,metaindexRow序列化的值
30. mp.mr.firstItem = append(mp.mr.firstItem[:0], mp.bh.firstItem...)
31. mp.mr.blockHeadersCount = 1
32. mp.mr.indexBlockOffset = 0
33. mp.mr.indexBlockSize = uint32(len(mp.indexData.B))
34. bb.B = mp.mr.Marshal(bb.B[:0])
35. mp.metaindexData.B = encoding.CompressZSTDLevel(mp.metaindexData.B[:0], bb.B, 0)
36. inmemoryPartBytePool.Put(bb)
37. }
上面的函数将 inmemoryBlock 转换成 inmemoryPart,首先会通过一个 MarshalUnsortedData 函数来序列化未排序的数据。
复制
1. // MarshalUnsortedData 序列化未排序的 items 从 ib 到 sb.
2. //
3. // It also:
4. // - 将第一个 item 追加到 firstItemDst 并返回结果
5. // - 将所有 item 的公共前缀附加到 commonPrefixDst 并返回结果
6. // - 返回包含第一个 item 的编码项的数量
7. // - 返回用于编码的 marshal 类型
8. func (ib *inmemoryBlock) MarshalUnsortedData(sb *storageBlock, firstItemDst, commonPrefixDst []byte, compressLevel int) ([]byte, []byte, uint32, marshalType) {
9. if !ib.isSorted() {
10. sort.Sort(ib) // 排序
11. }
12. // 更新内存块的公共前缀
13. ib.updateCommonPrefix()
14. // 序列化数据
15. return ib.marshalData(sb, firstItemDst, commonPrefixDst, compressLevel)
16. }
上面的序列化函数中首先会对未排序的数据进行排序,然后更新内存块的公共前缀:
复制
1. // lib/mergeset/encoding.go
2. // 更新公共前缀
3. func (ib *inmemoryBlock) updateCommonPrefix() {
4. ib.commonPrefix = ib.commonPrefix[:0] // 公共前缀
5. if len(ib.items) == 0 {
6. return
7. }
8. items := ib.items // 数据前后位置
9. data := ib.data // 数据
10. cp := items[0].Bytes(data) // 第一段数据
11. if len(cp) == 0 {
12. return
13. }
14. for _, it := range items[1:] { // 后面的数据
15. // 计算公共前缀的长度
16. cpLen := commonPrefixLen(cp, it.Bytes(data))
17. if cpLen == 0 {
18. return
19. }
20. // 截取公共前缀数据
21. cp = cp[:cpLen]
22. }
23. // 设置内存块的公共前缀
24. ib.commonPrefix = append(ib.commonPrefix[:0], cp...)
25. }
公共前缀就是把每段数据包含的共同前缀提取出来,这样存储的时候后面就可以不需要存储共同的部分了,减少存储空间。
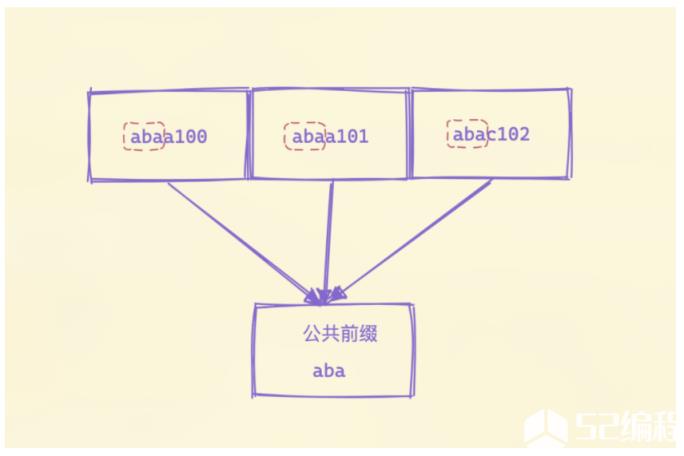
公共前缀提取出来后,接下来调用 marshalData 函数去序列化数据。
复制
1. // lib/mergeset/encoding.go
2. // 前提条件:
3. // - ib.items 必须排序
4. // - updateCommonPrefix 必须被调用
5. // 序列化数据
6. func (ib *inmemoryBlock) marshalData(sb *storageBlock, firstItemDst, commonPrefixDst []byte, compressLevel int) ([]byte, []byte, uint32, marshalType) {
7. ......
8. // 拷贝 inmemoryBlock 数据块的 firstItem(排序后的第一条数据)
9. data := ib.data // 内存块数据
10. firstItem := ib.items[0].Bytes(data) // 第一条数据
11. firstItemDst = append(firstItemDst, firstItem...)
12. // 最大公共前缀
13. commonPrefixDst = append(commonPrefixDst, ib.commonPrefix...)
14. // 内存块数据小于2段或(数据大小-公共前缀长度*数据段大小 < 64) 则定义为小块
15. if len(data)-len(ib.commonPrefix)*len(ib.items) < 64 || len(ib.items) < 2 {
16. // 对small block使用普通序列化,因为它更便宜
17. ib.marshalDataPlain(sb)
18. return firstItemDst, commonPrefixDst, uint32(len(ib.items)), marshalTypePlain
19. }
20. bbItems := bbPool.Get()
21. bItems := bbItems.B[:0] // 保存目的 items 数据的内存 buffer
22. bbLens := bbPool.Get()
23. bLens := bbLens.B[:0] // 保存目的 lens 数据的内存buffer
24. // 序列化 items 数据
25. // 第一项数据不需要存储,所以获取的 Uint64s 大小要减1
26. xs := encoding.GetUint64s(len(ib.items) - 1)
27. defer encoding.PutUint64s(xs)
28. cpLen := len(ib.commonPrefix) // 公共前缀的长度
29. prevItem := firstItem[cpLen:] // 第一项数据(排除公共前缀)
30. prevPrefixLen := uint64(0)
31. // 从第二个元素开始遍历(第一个 firstItem 单独存储)
32. for i, it := range ib.items[1:] {
33. // 偏移到公共前缀之后的位置
34. it.Start += uint32(cpLen)
35. // Bytes(data) 得到的数据不包含公共前缀的部分
36. item := it.Bytes(data)
37. // 计算第 N 项和 N-1 项的公共前缀长度
38. prefixLen := uint64(commonPrefixLen(prevItem, item))
39. // 仅仅只把差异的部分拷贝到目的buffer
40. bItems = append(bItems, item[prefixLen:]...)
41. // 第一次,与0异或,还是等于原值。异或后,两个整数值前面相同的部分都为0了,数值变得更短,能够便于压缩。
42. xLen := prefixLen ^ prevPrefixLen
43. // 上次的除去公共前缀的item
44. prevItem = item
45. // 上次计算得到的公共前缀长度
46. prevPrefixLen = prefixLen
47. xs.A[i] = xLen // 异或后的公共前缀值
48. }
49. // 对N-1个长度进行序列化(将uint64数组序列化成byte数组)
50. bLens = encoding.MarshalVarUint64s(bLens, xs.A)
51. // 将items数据(只有差异的部分)ZSTD压缩后,写入storageBlock
52. sb.itemsData = encoding.CompressZSTDLevel(sb.itemsData[:0], bItems, compressLevel)
53. bbItems.B = bItems
54. bbPool.Put(bbItems)
55. // 序列化 lens 数据
56. // 第一项数据大小(排除公共前缀)
57. prevItemLen := uint64(len(firstItem) - cpLen)
58. for i, it := range ib.items[1:] { // 从第二个元素开始遍历
59. // item长度 = End-Start-公共前缀大小
60. itemLen := uint64(int(it.End-it.Start) - cpLen)
61. // 与前面一个元素长度异或
62. xLen := itemLen ^ prevItemLen
63. // 上次去除公共前缀的长度
64. prevItemLen = itemLen
65. xs.A[i] = xLen // 异或后的元素长度
66. }
67. // 前面记录的是两两相对的长度,这里记录的是数据的真实长度
68. // 长度信息包含两种,相对长度和总长度
69. bLens = encoding.MarshalVarUint64s(bLens, xs.A)
70. // 将lens数据进行ZSTD压缩后,写入storageBlock
71. sb.lensData = encoding.CompressZSTDLevel(sb.lensData[:0], bLens, compressLevel)
72. bbLens.B = bLens
73. bbPool.Put(bbLens)
74. // 如果压缩不到90%则选择不压缩
75. if float64(len(sb.itemsData)) > 0.9*float64(len(data)-len(ib.commonPrefix)*len(ib.items)) {
76. // 压缩率不高的时候,选择不压缩
77. ib.marshalDataPlain(sb)
78. return firstItemDst, commonPrefixDst, uint32(len(ib.items)), marshalTypePlain
79. }
80. // 很好的压缩率
81. return firstItemDst, commonPrefixDst, uint32(len(ib.items)), marshalTypeZSTD
82. }
上面的序列化函数看上去比较复杂,实际上核心的一点就是想办法尽可能减少存储空间。首先将数据块的第一个数据拷贝出来放入 firstItemDst,然后后面就从第二个元素开始去循环处理,首先计算第 N 项和 N-1 项的公共前缀长度,然后将差异的数据部分保存起来,为了能够反序列化回数据,还需要将两两之间公共前缀的长度保存下来,为了能够便于压缩,使用异或的方式来计算两两之间的公共前缀长度值。
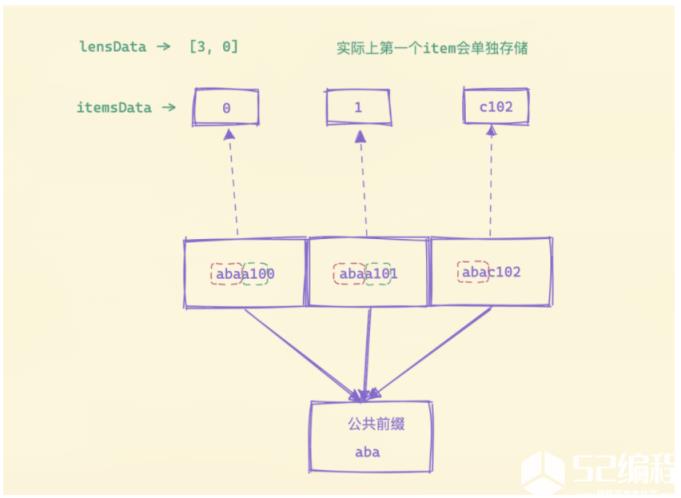
循环计算后,将保存的两两之间的公共前缀长度进行序列化,下面的函数将一个 uint64 类型的切片转换成字节切片,如果数据小于 128 直接转换即可,如果大于 127 则用一个 7bit 来表示数值的内容,最高位后面的一个字节用来表示长度,这样就可以用变长长度来序列化数值,而不是每个数值都占用固定的长度。
复制
1. // lib/encoding/int.go
2. // 将uint64切片转成字节切片
3. func MarshalVarUint64s(dst []byte, us []uint64) []byte {
4. for _, u := range us {
5. if u < 0x80 { // 小于128,直接加入到 dst,能直接存到 byte 中去
6. // Fast path
7. dst = append(dst, byte(u))
8. continue
9. }
10. for u > 0x7f { // 大于127,则超过的部分保留为 0x80,低位右移7位继续计算
11. dst = append(dst, 0x80|byte(u))
12. u >>= 7
13. }
14. dst = append(dst, byte(u))
15. }
16. return dst
17. }
长度数据序列化后,将 items 数据(只有差异的部分)进行 ZSTD 压缩后,写入 storageBlock。
只记录两两之间的公共前缀长度还不够,还需要记录数据的真实长度,最后同样再将 lens 数据进行 ZSTD 压缩后,写入 storageBlock。
如果最后的结果压缩不到 90% 则选择不压缩,不压缩则使用 marshalDataPlain 函数进行序列化:
复制
1. // lib/mergeset/encoding.go
2. // 普通序列化数据
3. func (ib *inmemoryBlock) marshalDataPlain(sb *storageBlock) {
4. data := ib.data
5. // 序列化 items 数据
6. // 不需要序列化第一项数据,因为它会在 marshalData 中返回给调用者。
7. cpLen := len(ib.commonPrefix) // 公共前缀长度
8. b := sb.itemsData[:0]
9. for _, it := range ib.items[1:] { // 第一项之后的数据
10. it.Start += uint32(cpLen) // 跳过公共前缀
11. b = append(b, it.String(data)...) // 添加移出公共前缀的数据
12. }
13. sb.itemsData = b // itemsData数据
14. // 序列化 lens 数据
15. b = sb.lensData[:0]
16. for _, it := range ib.items[1:] { // 第一项之后的数据
17. // 原始的End-Start-公共前缀长度
18. b = encoding.MarshalUint64(b, uint64(int(it.End-it.Start)-cpLen))
19. }
20. sb.lensData = b
21. }
经过上面的序列化过后就可以得到第一个数据、公共前缀、items 个数以及序列化类型,然后将这些数据存入 blockHeader 中去,后面就是一些比较简单的常规操作。
转换成 inmemoryPart 后,再包装成 blockStreamReader,创建一个新的 inmemoryPart,并构造一个 blockSteamWriter 用于合并写入的数据,然后调用 mergeBlockStreams 函数执行真正的 merge 操作。
复制
1. // lib/mergeset/merge.go
2. // mergeBlockStreams 合并 bsrs 并将结果写入 bsw
3. //
4. // 也填充了 ph
5. //
6. // prepareBlock 是可选的
7. //
8. // 当 stopCh 关闭时,该函数立即返回
9. //
10. // 它还以原子方式将合并的 items 添加到 itemsMerged
11. func mergeBlockStreams(ph *partHeader, bsw *blockStreamWriter, bsrs []*blockStreamReader, prepareBlock PrepareBlockCallback, stopCh <-chan struct{},
12. itemsMerged *uint64) error {
13. // 将多个 blockStreamReader 构造成一个 blockStreamMerger 结构
14. bsm := bsmPool.Get().(*blockStreamMerger)
15. if err := bsm.Init(bsrs, prepareBlock); err != nil {
16. return fmt.Errorf("cannot initialize blockStreamMerger: %w", err)
17. }
18. err := bsm.Merge(bsw, ph, stopCh, itemsMerged)
19. bsm.reset()
20. bsmPool.Put(bsm)
21. bsw.MustClose()
22. if err == nil {
23. return nil
24. }
25. return fmt.Errorf("cannot merge %d block streams: %s: %w", len(bsrs), bsrs, err)
26. }
首先把多个 blockStreamReader 构造成一个 blockStreamMerger 结构, merger 里面主要是一个 bsrHeap 堆用于维护 bsrs,用于 merge 数据时的排序。首先通过 merger 的 Init 函数构造堆排序的结构,然后核心是调用 merger 的 Merge 函数进行处理。
复制
1. // lib/mergeset/merge.go
2. func (bsm *blockStreamMerger) Merge(bsw *blockStreamWriter, ph *partHeader, stopCh <-chan struct{}, itemsMerged *uint64) error {
3. again:
4. if len(bsm.bsrHeap) == 0 {
5. // 将最后的 inmemoryBlock(可能不完整)写入 bsw
6. bsm.flushIB(bsw, ph, itemsMerged)
7. return nil
8. }
9. select {
10. case <-stopCh:
11. return errForciblyStopped
12. default:
13. }
14. // 取出 blockStreamReader
15. bsr := heap.Pop(&bsm.bsrHeap).(*blockStreamReader)
16. var nextItem []byte // 下一个 blockStreamReader
17. hasNextItem := false
18. if len(bsm.bsrHeap) > 0 {
19. nextItem = bsm.bsrHeap[0].bh.firstItem
20. hasNextItem = true
21. }
22. items := bsr.Block.items
23. data := bsr.Block.data
24. // 循环所有的 items
25. for bsr.blockItemIdx < len(bsr.Block.items) {
26. item := items[bsr.blockItemIdx].Bytes(data)
27. if hasNextItem && string(item) > string(nextItem) {
28. break
29. }
30. // 添加元素
31. if !bsm.ib.Add(item) {
32. // bsm.ib 已满,将其刷新到 bsw 并继续
33. bsm.flushIB(bsw, ph, itemsMerged)
34. continue
35. }
36. bsr.blockItemIdx++
37. }
38. if bsr.blockItemIdx == len(bsr.Block.items) {
39. // bsr.Block 已完全读取,处理下一个 block
40. if bsr.Next() {
41. heap.Push(&bsm.bsrHeap, bsr)
42. goto again
43. }
44. if err := bsr.Error(); err != nil {
45. return fmt.Errorf("cannot read storageBlock: %w", err)
46. }
47. goto again
48. }
49. // bsr.Block 中的下一个 item 超过了 nextItem
50. // 调整 bsr.bh.firstItem 并将 bsr 返回到堆
51. bsr.bh.firstItem = append(bsr.bh.firstItem[:0], bsr.Block.items[bsr.blockItemIdx].String(bsr.Block.data)...)
52. heap.Push(&bsm.bsrHeap, bsr)
53. goto again
54. }
这里主要解决的问题是多个有序的字节数组(inmemoryPart),按照字节序排序,合成一个 inmemoryPart 的过程,在 merge 的过程中,每 64KB 会单独创建一个 blockHeader,用于快速索引该 block 里面的 Items。
持久化数据
最后重复上面的过程,将 n 个 inmemoryBlock 合并成 (n-1)/defaultPartsToMerge+1 个 inmemoryPart,最后再调用 mergeParts 函数完成索引持久化操作,持久化后生成的索引 part,主要包含 metaindex.bin、index.bin、lens.bin、items.bin、metadata.json 等 5 个文件。
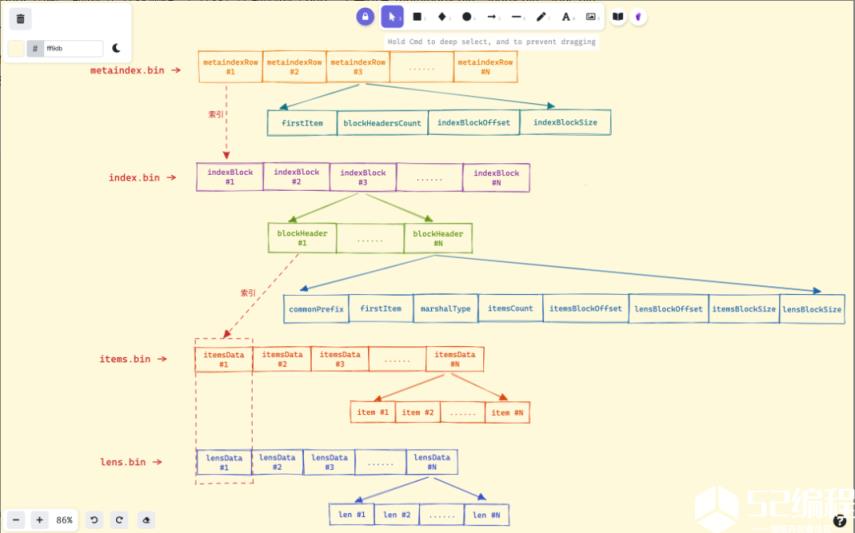
这几个文件的关系如下图所示, metaindex.bin 文件通过 metaindexRow 索引 index.bin 文件,index.bin 文件通过 indexBlock 中的 blockHeader 同时索引 items.bin 文件和 items.bin 文件。
metaindex.bin:文件包含一系列的 metaindexRow 数据,每个 metaindexRow 中包含第一条数据 firstItem、索引块包含的块头部数 blockHeadersCount、索引块偏移 indexBlockOffset 以及索引块大小 indexBlockSize。
metaindexRow 在文件中按照firstItem 的大小的字典序排序存储,以支持二分查找。
metaindex.bin 文件使用 ZSTD 进行压缩。
metaindex.bin 文件中的内容在 part 打开时,会全部读出加载至内存中,以加速查询过滤。
metaindexRow 包含的firstItem 为其索引的indexBlock 中所有blockHeader 中字典序最小的firstItem。
查找时根据firstItem 进行二分检索。
index.bin:文件中包含一系列的 indexBlock, 每个 indexBlock 又包含一系列 blockHeader,每个 blockHeader 包含 item 的公共前缀 commonPrefix、第一项数据 firstItem、itemsData 的序列化类型 marshalType、itemsData 包含的 item 数、item 块的偏移 itemsBlockOffset 等内容,就是前面使用将 inmemoryBlock 转换为 inmemoryPart 结构的 Init 函数得到的。
每个indexBlock 使用ZSTD 压缩算法进行压缩。
在indexBlock 中查找时,根据firstItem 进行二分检索blockHeader。
items.bin 文件中,包含一系列的 itemsData, 每个 itemsData 又包含一系列的 Item。
itemsData 会视情况而定来是否使用 ZTSD 压缩,当 item 个数小于 2 时,或者itemsData 的长度小于 64 字节时,不压缩;当itemsData 使用 ZSTD 压缩后的压缩率大于90%的时候也不压缩。
每个 item 在存储时,去掉了blockHeader 中的公共前缀commonPrefix 以提高压缩率。
lens.bin 文件中,包含一系列的 lensData, 每个 lensData 又包含一系列 8 字节的长度 len, 长度 len 标识 items.bin 文件中对应 item 的长度。在读取或者需要解析 itemsData 中的 item 时,先要读取对应的 lensData 中对应的长度 len。 当 itemsData 进行压缩时,lensData 会先使用异或算法进行压缩,然后再使用 ZSTD 算法进一步压缩。
到这里我们就了解了索引数据是实现和存储原理了,那么真正的指标数据又是如何去存储的呢?
来源: k8s技术圈
>>>>>>点击进入系统运维专题












