
本篇文章给大家分享的是有关Jenkins中怎么实现Pipeline自动化部署,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
使用Jenkins前的一些设置
为了快速搭建Jenkins,我这里使用Docker安装运行Jenkins:
$ sudo docker run -it -d \ --rm \ -u root \ -p 8080:8080 \ -v jenkins-data:/var/jenkins_home \ -v /var/run/docker.sock:/var/run/docker.sock \ -v "$HOME":/home \ --name jenkins jenkinsci/blueocean初次使用jenkins,进入Jenkins页面前,需要密码验证,我们需要进入docker容器查看密码:
$ sudo docker exec -it jenkins /bin/bash$ vi /var/jenkins_home/secrets/initialAdminPasswordDocker安装的Jenkins稍微有那么一点缺陷,shell版本跟CenOS宿主机的版本不兼容,这时我们需要进入Jenkins容器手动设置shell:
$ sudo docker exec -it jenkins /bin/bash$ ln -sf /bin/bash /bin/sh由于我们的Pipeline还需要在远程服务器执行任务,需要通过ssh连接,那么我们就需要在Jenkins里面生成ssh的公钥密钥:
$ sudo docker exec -it jenkins /bin/bash$ ssh-keygen -C "root@jenkins"在远程节点的~/.ssh/authorized_keys中添加jenkins的公钥(id_rsa.pub)
还需要安装一些必要的插件:
Pipeline Maven Integration
SSH Pipeline Steps
安装完插件后,还需要去全局工具那里添加maven:
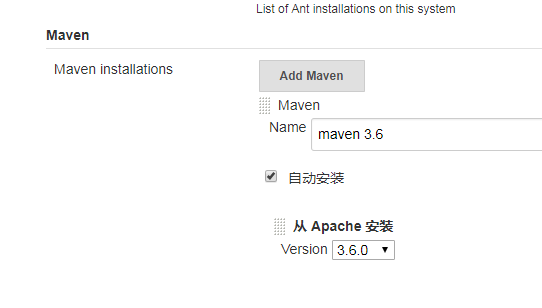
这里后面Jenkinsfile有用到。
mutiBranch多分支构建
由于我们的开发是基于多分支开发,每个开发环境都对应有一条分支,所以普通的Pipeline自动化构建并不能满足现有的开发部署需求,所以我们需要使用Jenkins的mutiBranch Pipeline。
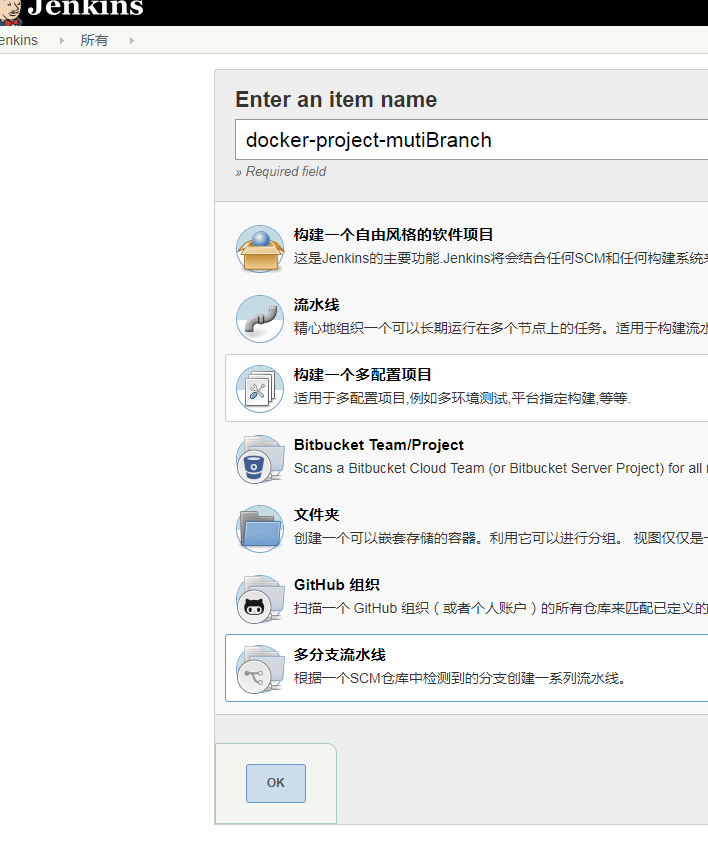
首先当然是新建一个mutiBranch多分支构建job:
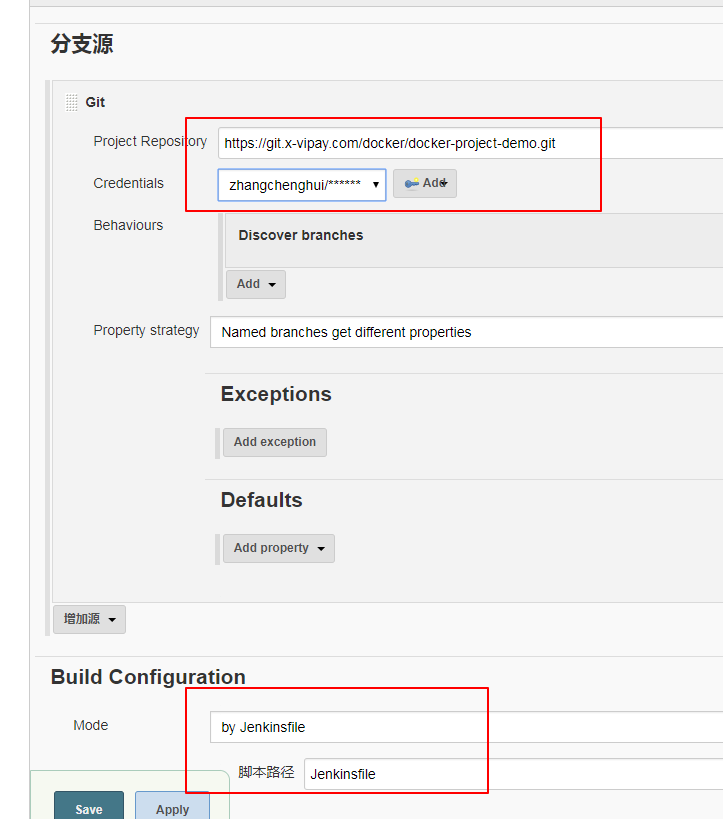
接着设置分支源,分支源就是你项目的git地址,选择Jenkinsfile在项目的路径
接下来Jenkins会在分支源中扫描每个分支下的Jenkinsfile,如果该分支下有Jenkinsfile,那么就会创建一个分支Job
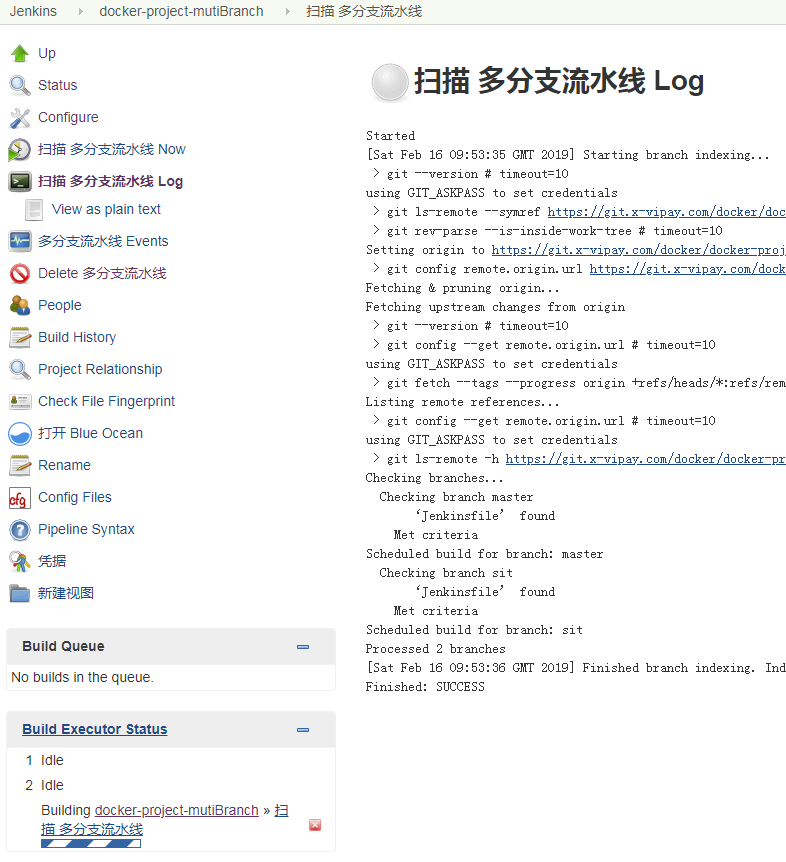
该job下的分支job如下:
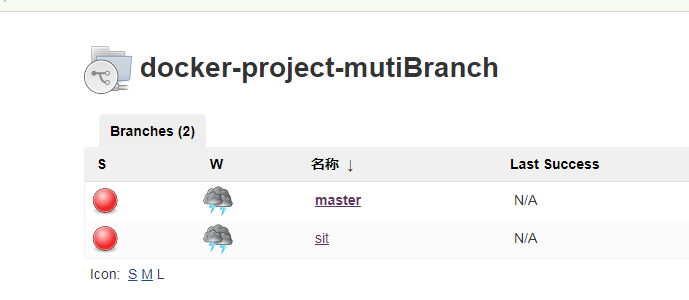
这里需要注意的是,只有需要部署的分支,才加上Jenkinsfile,不然Jenkins会将其余分支也创建一个分支job。
通用化Pipeline脚本
到这里之前,基本就可以基于Pipeline脚本自动化部署了,但如果你是一个追求极致,不甘于平庸的程序员,你一定会想,随着项目的增多,Pipeline脚本不断增多,这会造成越来越大的维护成本,随着业务的增长,难免会在脚本中修改东西,这就会牵扯太多Pipeline脚本了,而且这些脚本基本都相同,那么对于我这么优秀的程序员,怎么会想不到这个问题呢,我第一时间就想到通用化pipeline脚本。所幸,Jenkins已经看出了我不断骚动的心了,Jenkins甩手就给我一个Shared Libraries。
Shared Libraries是什么呢?顾名思义,它就是一个共享库,它的主要作用是用于将通用的Pipeline脚本放在一个地方,其它项目可以从它那里获取到一个全局通用化的Pipeline脚本,项目之间通过不通的变量参数传递,达到通用化的目的。
接下来我们先创建一个用于存储通用Pipeline脚本的git仓库:
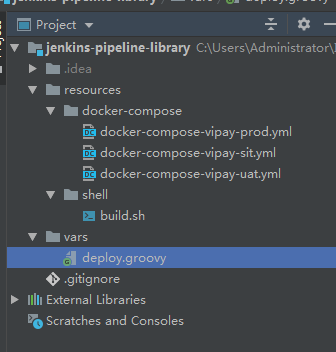
仓库目录不是随便乱添加了,Jenkins有一个严格的规范,下面是官方说明:

官方已经讲得很清楚了,大概意思就是vars目录用于存储通用Pipeline脚本,resources用于存储非Groovy文件。所以我这里就把Pipeline需要的构建脚本以及编排文件都集中放在这里,完全对业务工程师隐蔽,这样做的目的就是为了避免业务工程师不懂瞎几把乱改,导致出bug。
创建完git仓库后,我们还需要在jenkins的Manage Jenkins » Configure System » Global Pipeline Libraries中定义全局库:
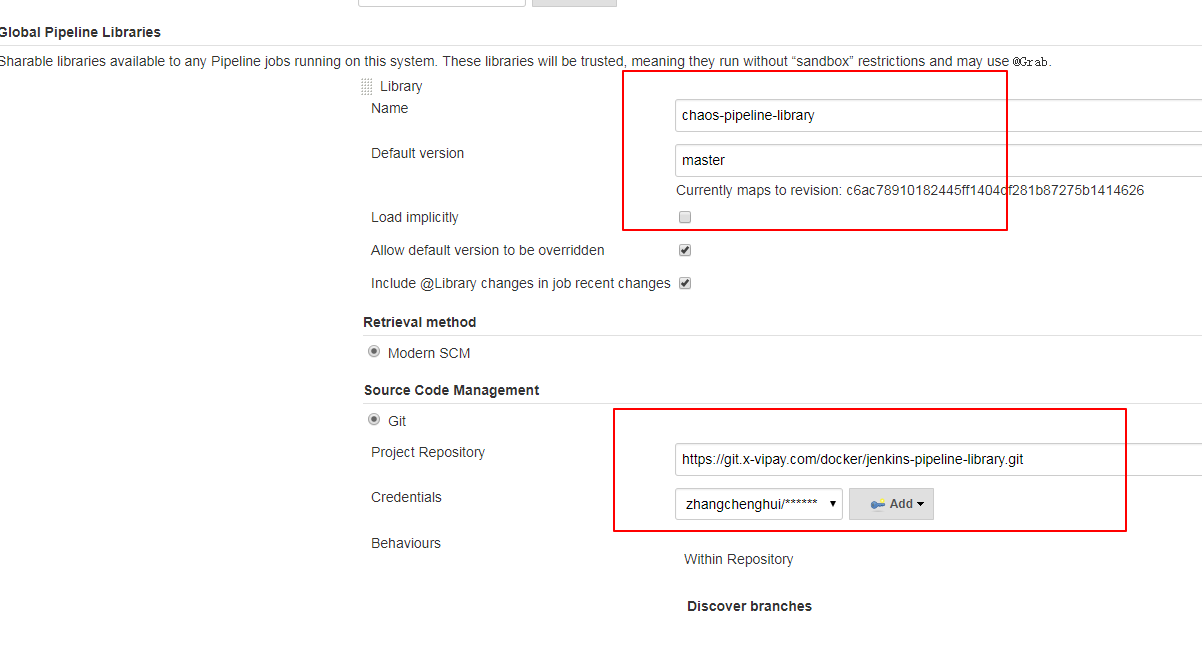
这里的name,可以在jenkinsfile中通过以下命令引用:
@Library 'objcoding-pipeline-library'下面我们来看通用Pipeline脚本的编写规则:
#!groovydef getServer() { def remote = [:] remote.name = 'manager node' remote.user = 'dev' remote.host = "${REMOTE_HOST}" remote.port = 22 remote.identityFile = '/root/.ssh/id_rsa' remote.allowAnyHosts = true return remote}def call(Map map) { pipeline { agent any environment { REMOTE_HOST = "${map.REMOTE_HOST}" REPO_URL = "${map.REPO_URL}" BRANCH_NAME = "${map.BRANCH_NAME}" STACK_NAME = "${map.STACK_NAME}" COMPOSE_FILE_NAME = "docker-compose-" + "${map.STACK_NAME}" + "-" + "${map.BRANCH_NAME}" + ".yml" } stages { stage('获取代码') { steps { git([url: "${REPO_URL}", branch: "${BRANCH_NAME}"]) } } stage('编译代码') { steps { withMaven(maven: 'maven 3.6') { sh "mvn -U -am clean package -DskipTests" } } } stage('构建镜像') { steps { sh "wget -O build.sh https://git.x-vipay.com/docker/jenkins-pipeline-library/raw/master/resources/shell/build.sh" sh "sh build.sh ${BRANCH_NAME} " } } stage('init-server') { steps { script { server = getServer() } } } stage('执行发版') { steps { writeFile file: 'deploy.sh', text: "wget -O ${COMPOSE_FILE_NAME} " + " https://git.x-vipay.com/docker/jenkins-pipeline-library/raw/master/resources/docker-compose/${COMPOSE_FILE_NAME} \n" + "sudo docker stack deploy -c ${COMPOSE_FILE_NAME} ${STACK_NAME}" sshScript remote: server, script: "deploy.sh" } } } }}由于我们需要在远程服务器执行任务,所以定义一个远程服务器的信息其中
remote.identityFile就是我们上面在容器生成的密钥的地址;定义一个call()方法,这个方法用于在各个项目的Jenkinsfile中调用,注意一定得叫call;
在call()方法中定义一个pipeline;
environment参数即是可变通用参数,通过传递参数Map来给定值,该Map是从各个项目中定义的传参;
接下来就是一顿步骤操作啦,“编译代码”这步骤需要填写上面我们在全局工具类设置的maven,“构建镜像”的构建脚本巧妙地利用wget从本远程仓库中拉取下来,”执行发版“的编排文件也是这么做,“init-server”步骤主要是初始化一个server对象,供“执行发版使用”。
从脚本看出来Jenkins将来要推崇的一种思维:配置即代码。
写完通用Pipeline脚本后,接下来我们就需要在各个项目的需要自动化部署的分支的根目录下新建一个Jenkinsfile脚本了:
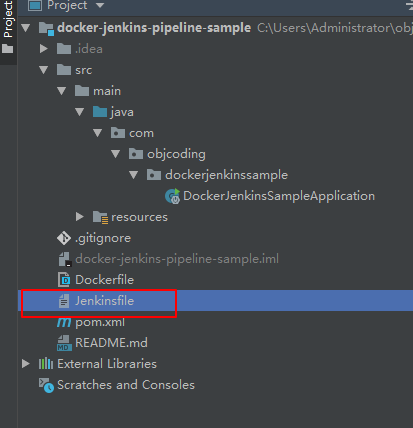
接下来我来解释一下Jenkinsfile内容:
#!groovy// 在多分支构建下,严格规定Jenkinsfile只存在可以发版的分支上// 引用在jenkins已经全局定义好的librarylibrary 'objcoding-pipeline-library'def map = [:]// 远程管理节点地址(用于执行发版)map.put('REMOTE_HOST','xxx.xx.xx.xxx')// 项目gitlab代码地址map.put('REPO_URL','https://github.com/objcoding/docker-jenkins-pipeline-sample.git')// 分支名称map.put('BRANCH_NAME','master')// 服务栈名称map.put('STACK_NAME','vipay')// 调用library中var目录下的build.groovy脚本build(map)通过
library 'objcoding-pipeline-library'引用我们在Jenkins定义的全局库,定义一个map参数;接下来就是将项目具体的参数保存到map中,调用build()方法传递给通用Pipeline脚本。
以上就是Jenkins中怎么实现Pipeline自动化部署,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注编程网行业资讯频道。









