
小编给大家分享一下分布式文件系统HDFS的示例分析,希望大家阅读完这篇文章之后都有所收获,下面让我们一起去探讨吧!
从RAID说起
大数据技术主要要解决的问题的是大规模数据的计算处理问题,那么首先要解决的就是大规模数据的存储问题。大规模数据存储要解决的核心问题有三个方面:
数据存储容量的问题,既然大数据要解决的是数以PB计的数据计算问题,而一般的服务器磁盘容量通常1-2TB,那么如何存储这么大规模的数据。
数据读写速度的问题,一般磁盘的连续读写速度为几十MB,以这样的速度,几十PB的数据恐怕要读写到天荒地老。
数据可靠性的问题,磁盘大约是计算机设备中最易损坏的硬件了,在网站一块磁盘使用寿命大概是一年,如果磁盘损坏了,数据怎么办?
在大数据技术出现之前,人们就需要面对这些关于存储的问题,对应的解决方案就是RAID技术。
RAID(独立磁盘冗余阵列)技术主要是为了改善磁盘的存储容量,读写速度,增强磁盘的可用性和容错能力。目前服务器级别的计算机都支持插入多块磁盘(8块或者更多),通过使用RAID技术,实现数据在多块磁盘上的并发读写和数据备份。
常用RAID技术有以下几种,如图所示。

假设服务器有N块磁盘。
RAID0
数据在从内存缓冲区写入磁盘时,根据磁盘数量将数据分成N份,这些数据同时并发写入N块磁盘,使得数据整体写入速度是一块磁盘的N倍。读取的时候也一样,因此RAID0具有极快的数据读写速度,但是RAID0不做数据备份,N块磁盘中只要有一块损坏,数据完整性就被破坏,所有磁盘的数据都会损坏。
RAID1
数据在写入磁盘时,将一份数据同时写入两块磁盘,这样任何一块磁盘损坏都不会导致数据丢失,插入一块新磁盘就可以通过复制数据的方式自动修复,具有极高的可靠性。
RAID10
结合RAID0和RAID1两种方案,将所有磁盘平均分成两份,数据同时在两份磁盘写入,相当于RAID1,但是在每一份磁盘里面的N/2块磁盘上,利用RAID0技术并发读写,既提高可靠性又改善性能,不过RAID10的磁盘利用率较低,有一半的磁盘用来写备份数据。
RAID3
一般情况下,一台服务器上不会出现同时损坏两块磁盘的情况,在只损坏一块磁盘的情况下,如果能利用其他磁盘的数据恢复损坏磁盘的数据,这样在保证可靠性和性能的同时,磁盘利用率也得到大幅提升。
在数据写入磁盘的时候,将数据分成N-1份,并发写入N-1块磁盘,并在第N块磁盘记录校验数据,任何一块磁盘损坏(包括校验数据磁盘),都可以利用其他N-1块磁盘的数据修复。
但是在数据修改较多的场景中,任何磁盘修改数据都会导致第N块磁盘重写校验数据,频繁写入的后果是第N块磁盘比其他磁盘容易损坏,需要频繁更换,所以RAID3很少在实践中使用。
RAID5
相比RAID3,更多被使用的方案是RAID5。
RAID5和RAID3很相似,但是校验数据不是写入第N块磁盘,而是螺旋式地写入所有磁盘中。这样校验数据的修改也被平均到所有磁盘上,避免RAID3频繁写坏一块磁盘的情况。
RAID6
如果数据需要很高的可靠性,在出现同时损坏两块磁盘的情况下(或者运维管理水平比较落后,坏了一块磁盘但是迟迟没有更换,导致又坏了一块磁盘),仍然需要修复数据,这时候可以使用RAID6。
RAID6和RAID5类似,但是数据只写入N-2块磁盘,并螺旋式地在两块磁盘中写入校验信息(使用不同算法生成)。
在相同磁盘数目(N)的情况下,各种RAID技术的比较如下表所示。

RAID技术有硬件实现,比如专用的RAID卡或者主板直接支持,也可以通过软件实现,在操作系统层面将多块磁盘组成RAID,在逻辑视作一个访问目录。RAID技术在传统关系数据库及文件系统中应用比较广泛,是改善计算机存储特性的重要手段。
RAID技术只是在单台服务器的多块磁盘上组成阵列,大数据需要更大规模的存储空间和访问速度。将RAID技术原理应用到分布式服务器集群上,就形成了Hadoop分布式文件系统HDFS的架构思想。
HDFS架构原理
和RAID在多个磁盘上进行文件存储及并行读写一样思路,HDFS在一个大规模分布式服务器集群上,对数据进行并行读写及冗余存储。因为HDFS可以部署在一个比较大的服务器集群上,集群中所有服务器的磁盘都可以供HDFS使用,所以整个HDFS的存储空间可以达到PB级容量。HDFS架构如图。

HDFS中关键组件有两个,一个是NameNode,一个是DataNode。
DataNode负责文件数据的存储和读写操作,HDFS将文件数据分割成若干块(block),每个DataNode存储一部分block,这样文件就分布存储在整个HDFS服务器集群中。应用程序客户端(Client)可以并行对这些数据块进行访问,从而使得HDFS可以在服务器集群规模上实现数据并行访问,极大地提高访问速度。实践中HDFS集群的DataNode服务器会有很多台,一般在几百台到几千台这样的规模,每台服务器配有数块磁盘,整个集群的存储容量大概在几PB到数百PB。
NameNode负责整个分布式文件系统的元数据(MetaData)管理,也就是文件路径名,数据block的ID以及存储位置等信息,承担着操作系统中文件分配表(FAT)的角色。HDFS为了保证数据的高可用,会将一个block复制为多份(缺省情况为3份),并将三份相同的block存储在不同的服务器上。这样当有磁盘损坏或者某个DataNode服务器宕机导致其存储的block不能访问的时候,Client会查找其备份的block进行访问。
block多份复制存储如下图所示,对于文件/users/sameerp/data/part-0,其复制备份数设置为2,存储的block id为1,3。block1的两个备份存储在DataNode0和DataNode2两个服务器上,block3的两个备份存储DataNode4和DataNode6两个服务器上,上述任何一台服务器宕机后,每个block都至少还有一个备份存在,不会影响对文件/users/sameerp/data/part-0的访问。
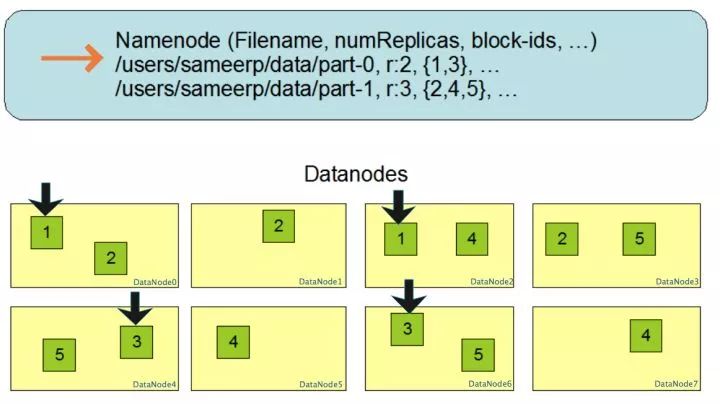
事实上,DataNode会通过心跳和NameNode保持通信,如果DataNode超时未发送心跳,NameNode就会认为这个DataNode已经失效,立即查找这个DataNode上存储的block有哪些,以及这些block还存储在哪些服务器上,随后通知这些服务器再复制一份block到其他服务器上,保证HDFS存储的block备份数符合用户设置的数目,即使再有服务器宕机,也不会丢失数据。
HDFS应用
Hadoop分布式文件系统可以象一般的文件系统那样进行访问:使用命令行或者编程语言API进行文件读写操作。我们以HDFS写文件为例看HDFS处理过程,如下图。

应用程序Client调用HDFS API,请求创建文件,HDFS API包含在Client进程中。
HDFS API将请求参数发送给NameNode服务器,NameNode在meta信息中创建文件路径,并查找DataNode中空闲的block。然后将空闲block的id、对应的DataNode服务器信息返回给Client。因为数据块需要多个备份,所以即使Client只需要一个block的数据量,NameNode也会返回多个NameNode信息。
Client调用HDFS API,请求将数据流写出。
HDFS API连接第一个DataNode服务器,将Client数据流发送给DataNode,该DataNode一边将数据写入本地磁盘,一边发送给第二个DataNode。同理第二个DataNode记录数据并发送给第三个DataNode。
Client通知NameNode文件写入完成,NameNode将文件标记为正常,可以进行读操作了。
HDFS虽然提供了API,但是在实践中,我们很少自己编程直接去读取HDFS中的数据,原因正如开篇提到,在大数据场景下,移动计算比移动数据更划算。于其写程序去读取分布在这么多DataNode上的数据,不如将程序分发到DataNode上去访问其上的block数据。但是如何对程序进行分发?分发出去的程序又如何访问HDFS上的数据?计算的结果如何处理,如果结果需要合并,该如何合并?
Hadoop提供了对存储在HDFS上的大规模数据进行并行计算的框架,就是我们之前讲的MapReduce。
看完了这篇文章,相信你对“分布式文件系统HDFS的示例分析”有了一定的了解,如果想了解更多相关知识,欢迎关注编程网行业资讯频道,感谢各位的阅读!







