
参考视频和资料:2022新版黑马程序员python教程,8天python从入门到精通,学python看这套就够了_哔哩哔哩_bilibili
最后有知识的思维导图!
解释器:pycharm
一、Pycharm快捷键和基础
- 注释多行代码:Ctrl+/
- 单行注释:#
- 搜索:ctrl + f
- 打开软件设置:ctrl+alt+s
- 复制当前行代码:ctrl + d
- 将当前行代码上移或下移:shift + alt +上\下
- 运行当前代码文件:crtl + shift + f10
- 撤回 crtl + z
二、python基础语法
- 常用的值类型

2.注释
单行注释:#
多行注释:””” ****“””
3.变量命名规则
- 变量名必须以字母或下划线字符开头
- 变量名不能以数字开头
- 变量名称只能包含字母数字字符和下划线
- 变量名区分大小写
- 不能与关键字重复
数据类型

5.type()函数
type(被查看类型的数据)
6.字符串定义的三种方式
 7.数据类型转换
7.数据类型转换

注意:
- 任何类型,都可以通过str(),转换成字符串
- 字符串内必须真的是数字,才可以将字符串转换为数字
1.标识符
用户编写代码时,对变量、类、方法等编写的名字,叫做标识符。
2.关键词

3.算术运算符

4.赋值运算符

复合赋值运算符
案例:a+=b 如同a=a+b

6.字符串的引号嵌套
- 单引号定义法,可以内含双引号
- 双引号定义法,可以内含单引号
- 可以使用转移字符(\)来将引号解除效用,变成普通字符串
字符串拼接
案例一:print("学IT来黑马" + "月薪过)
案列二:

注意:字符串无法和非字符串变量进行拼接,因为类型不一致,无法接上。
8.字符串格式化
1)占位:
案列:

%表示:我要占位
s表示:将变量变成字符串放入占位的地方
案列:

我们需要注意的是:

常用的数据类型占位:

案列:

9.数字精度控制
案列:%5.2f:表示将宽度控制为5,将小数点精度设置为2(m.n)
- m,控制宽度,要求是数字(很少使用),设置的宽度小于数字自身,不生效
- .n,控制小数点精度,要求是数字,会进行小数的四舍五入
10.字符串格式化(快速写法)

注意:这种写法不做精度控制,也不理会类型,适用于快速格式化字符串。
11.字符串格式化-表达式的格式化

注意:在无需使用变量进行数据存储的时候,可以直接格式化表达式,简化代码哦.
12.input()函数
案例:name = input()
input语句获取的数据类型:最终的结果都是:字符串类型的数据.
13.判断语句
判断是程序最基础,最核心的逻辑功能。
1)布尔类型的定义:
布尔类型的字面量:
- True 表示真(是、肯定)
- False 表示假 (否、否定)
2)比较运算符

3)if判断语句
If 判断语句:
语句一
- 判断语句的结果,必须是布尔类型True或False
- True会执行if内的代码语句
- False则不会执行
4)if else语句
If 判断语句:
语句一
else:
语句二
注意:
- else后,不需要判断条件
- 和if的代码块一样,else的代码块同样需要4个空格作为缩进
5)if elif else语句
If 判断语句一:
语句一
elif 判断语句二
语句二
...
else:
语句N
案列:

6)判断语句嵌套

注意:
- 嵌套的关键点,在于:空格缩进
- 通过空格缩进,来决定语句之间的:层次关系
案列:

1.while循环语句
While 条件:
语句一
语句二
...
语句n
只要条件满足会无限循环执行。
案例:

1)while的条件需得到布尔类型,True表示继续循环,False表示结束循环。
2)需要设置循环终止的条件,如i += 1配合 i < 100,就能确保100次后停止,否则将无限循环。
3)空格缩进和if判断一样,都需要设置。
2. random.randint(上界1,上界2)
3. While循环的嵌套

基于空格缩进来决定层次关系。
4.print(“hello”,end=’ ’)
在print语句中,加上 end=’’ 即可输出不换行了。
5.制表符\t
可以让我们的多行字符串进行对齐。
效果:

6. for循环
for语句和while语句的区别:
- while循环的循环条件是自定义的,自行控制循环条件
- for循环是一种”轮询”机制,是对一批内容进行”逐个处理”

基本语法:

语法中的:待处理数据集,严格来说,称之为:可迭代类型。可迭代类型指,其内容可以一个个依次取出的一种类型,包括:
- 字符串
- 列表
- 元组
- 等
从待处理数据集中:逐个取出数据赋值给临时变量
案例:

可以看出,for循环是将字符串的内容:依次取出。所以,for循环也被称之为:遍历循环。
- 理论上讲,Python的for循环无法构建无限循环(被处理的数据集不可能无限大)
7. range语句



range的用途很多,多数用在for循环场景。
8.for循环的变量作用域
临时变量,在编程规范上,作用范围(作用域),只限定在for循环内部。
如果在for循环外部访问临时变量:
- 实际上是可以访问到的
- 在编程规范上,是不允许、不建议这么做的
9. for嵌套

10. 循环中断
1)continue
- continue关键字用于:中断本次循环,直接进入下一次循环。
- continue可以用于:for循环和while循环,效果一致。
- continue关键字只可以控制:它所在的循环临时中断
2)Break
- break关键字用于:直接结束所在循环
- break可以用于:for循环和while循环,效果一致
- break关键字同样只可以控制:它所在的循环永久中断
函数的定义


1)函数的传入参数-传参定义

def test(x,y):
sum = x+y
return sum
test(5,6)
函数定义中,提供的x和y,称之为:形式参数(形参),表示函数声明将要使用2个参数。 参数之间使用逗号进行分隔。
函数调用中,提供的5和6,称之为:实际参数(实参),表示函数执行时真正使用的参数值。
传入的时候,按照顺序传入数据,使用逗号分隔。
2)函数的返回值
所谓“返回值”,就是程序中函数完成事情后,最后给调用者的结果。


3)None类型
None表示:空的、无实际意义的意思,其类型是:
None作为一个特殊的字面量,用于表示:空、无意义,其有非常多的应用场景。
- 用在函数无返回值上
- 用在if判断上
1)在if判断中,None等同于False
2)一般用于在函数中主动返回None,配合if判断做相关处理

3.用于声明无内容的变量上
1)定义变量,但暂时不需要变量有具体值,可以用None来代替

12.函数的说明文档

在PyCharm编写代码时,可以通过鼠标悬停,查看调用函数的说明文档。
13. 函数嵌套使用
如果函数A中,调用了另外一个函数B,那么先把函数B中的任务都执行完毕之后才会回到上次 函数A执行的位置。
14. 变量的作用域
变量作用域指的是变量的作用范围,主要分为两类:局部变量和全局变量。
1)局部变量
- 所谓局部变量是定义在函数体内部的变量,即只在函数体内部生效。
- 局部变量的作用:在函数体内部,临时保存数据,即当函数调用完成后,则销毁局部变量
2)全局变量
所谓全局变量,指的是在函数体内、外都能生效的变量
global关键字:
使用 global关键字 可以在函数内部声明变量为全局变量, 如下所

1.数据容器
数据据容器根特点的不同,如:是否支持重复元素、是否可以修改、是否有序,等分为5类,分别是:列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)。
2. List列表
1)列表的定义


2)列表下标索引
列表中的每一个元素,都有其位置下标索引,从前向后的方向,从0开始,依次递增。

反向索引:

嵌套索引:
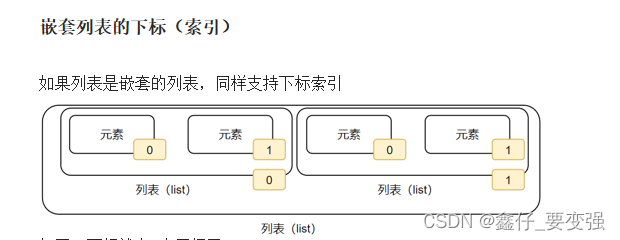
3)列表的常用操作
查找某元素的下标:
语法:列表.index(元素)
index就是列表对象(变量)内置的方法(函数)
修改特定位置(索引)的元素值:语法:列表[下标] = 值

插入元素:
语法:列表.insert(下标, 元素),在指定的下标位置,插入指定的元素
追加元素:
语法:列表.append(元素),将指定元素,追加到列表的尾部
追加元素方式2:
语法:列表.extend(其它数据容器),将其它数据容器的内容取出,依次追加到列表尾部
删除元素:
语法1: del 列表[下标]
语法2:列表.pop(下标)
删除某元素在列表中的第一个匹配项:
语法:列表.remove(元素)
清空列表内容
语法:列表.clear()
统计某元素在列表内的数量
语法:列表.count(元素)
统计列表内,有多少元素
语法:len(列表)
4)列表的方法 - 总览

5)List列表遍历
while循环和for循环的对比:

3.tuple元组
1)元组的定义
元组一旦定义完成,就不可修改。
元组定义:定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型。



2) 元组的相关操作


元组的相关操作 - 注意事项
- 不可以修改元组的内容,否则会直接报错
2.可以修改元组内的list的内容(修改元素、增加、删除、反转等)

3. 不可以替换list为其它list或其它类型
4.str字符串

1)字符串的常用操作
字符串的下标索引
和其它容器如:列表、元组一样,字符串也可以通过下标进行访问
- 从前向后,下标从0开始
- 从后向前,下标从-1开始

同元组一样,字符串是一个:无法修改的数据容器。
查找特定字符串的下标索引值
语法:字符串.index(字符串)

字符串的替换
语法:字符串.replace(字符串1,字符串2)
功能:将字符串内的全部:字符串1,替换为字符串2
注意:不是修改字符串本身,而是得到了一个新字符串哦

可以看到,字符串name本身并没有发生变化,而是得到了一个新字符串对象
字符串的规整操作(去前后空格)
语法:字符串.strip()

字符串的规整操作(去前后指定字符串)
语法:字符串.strip(字符串)

注意,传入的是“12” 其实就是:”1”和”2”都会移除,是按照单个字符。
统计字符串中某字符串的出现次数
语法:字符串.count(字符串)

统计字符串的长度
语法:len(字符串)

- 数字(1、2、3...)
- 字母(abcd、ABCD等)
- 符号(空格、!、@、#、$等)
- 中文
- 均算作1个字符
2)字符串常用操作汇总

1. 序列
序列是指:内容连续、有序,可使用下标索引的一类数据容器。
列表、元组、字符串,均可以可以视为序列

1)序列的常用操作-切片
序列支持切片,即:列表、元组、字符串,均支持进行切片操作
切片:从一个序列中,取出一个子序列
语法:序列[起始下标:结束下标:步长]
表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列:
起始下标表示从何处开始,可以留空,留空视作从头开始
结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
- 步长表示,依次取元素的间隔
- 步长1表示,一个个取元素
- 步长2表示,每次跳过1个元素取
- 步长N表示,每次跳过N-1个元素取
- 步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
注意,此操作不会影响序列本身,而是会得到一个新的序列(列表、元组、字符串)
2. set(集合)
集合,最主要的特点就是:不支持元素的重复(自带去重功能)、并且内容无序
基本语法:

1)小总结
- 列表使用:[]
- 元组使用:()
- 字符串使用:""
- 集合使用:{}
2)集合的常用操作
修改
添加新元素
语法:集合.add(元素)。将指定元素,添加到集合内
结果:集合本身被修改,添加了新元素

移除元素
语法:集合.remove(元素),将指定元素,从集合内移除
结果:集合本身被修改,移除了元素

从集合中随机取出元素
语法:集合.pop(),功能,从集合中随机取出一个元素
结果:会得到一个元素的结果。同时集合本身被修改,元素被移除

清空集合
语法:集合.clear(),功能,清空集合
结果:集合本身被清空

取出2个集合的差集
语法:集合1.difference(集合2),功能:取出集合1和集合2的差集
结果:得到一个新集合,集合1和集合2不变

消除2个集合的差集
语法:集合1.difference_update(集合2)
功能:对比集合1和集合2,在集合1内,删除和集合2相同的元素。
结果:集合1被修改,集合2不

2个集合合并
语法:集合1.union(集合2)
功能:将集合1和集合2组合成新集合
结果:得到新集合,集合1和集合2不变

查看集合的元素数量
语法:len(集合)
功能:统计集合内有多少元素
结果:得到一个整数结果

集合的常用操作 - 遍历
集合同样支持使用for循环遍历

要注意:集合不支持下标索引,所以也就不支持使用while循环。
3)集合常用功能总结

3.dict(字典)
1)定义:字典的定义,同样使用{},不过存储的元素是一个个的:键值对,如下语法:

- 使用{}存储原始,每一个元素是一个键值对
- 每一个键值对包含Key和Value(用冒号分隔)
- 键值对之间使用逗号分隔
- Key和Value可以是任意类型的数据(key不可为字典)
- Key不可重复,重复会对原有数据覆盖
![]()
字典同集合一样,不可以使用下标索引,但是字典可以通过Key值来取得对应的Value

2)字典的嵌套
字典的Key和Value可以是任意数据类型(Key不可为字典)

3) 字典常用操作
新增元素
语法:字典[Key] = Value,结果:字典被修改,新增了元素

更新元素
语法:字典[Key] = Value,结果:字典被修改,元素被更新
注意:字典Key不可以重复,所以对已存在的Key执行上述操作,就是更新Value值

删除元素
语法:字典.pop(Key),结果:获得指定Key的Value,同时字典被修改,指定Key的数据被删除

清空字典
语法:字典.clear(),结果:字典被修改,元素被清空

获取全部的key
语法:字典.keys(),结果:得到字典中的全部Key

遍历字典
语法:for key in 字典.keys()

字典不支持下标索引,所以同样不可以用while循环遍历
计算字典内的全部元素(键值对)数量
语法:len(字典)
结果:得到一个整数,表示字典内元素(键值对)的数量

4)字典的操作总结

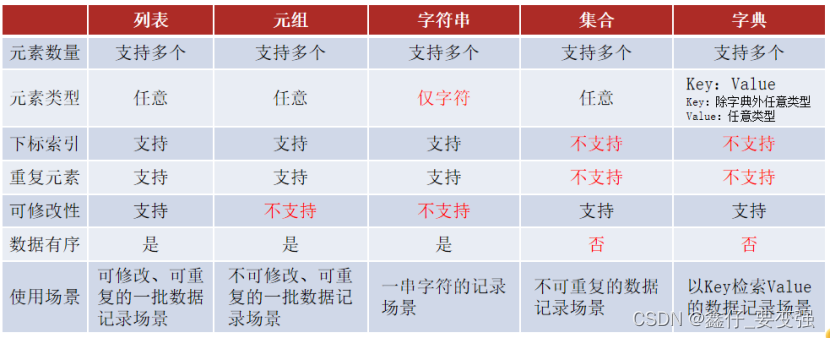
4. 数据容器分类
是否支持下标索引
- 支持:列表、元组、字符串 - 序列类型
- 不支持:集合、字典 - 非序列类型
是否支持重复元素:
- 支持:列表、元组、字符串 - 序列类型
- 不支持:集合、字典 - 非序列类型
是否可以修改
- 支持:列表、集合、字典
- 不支持:元组、字符串
1)数据容器特点对比
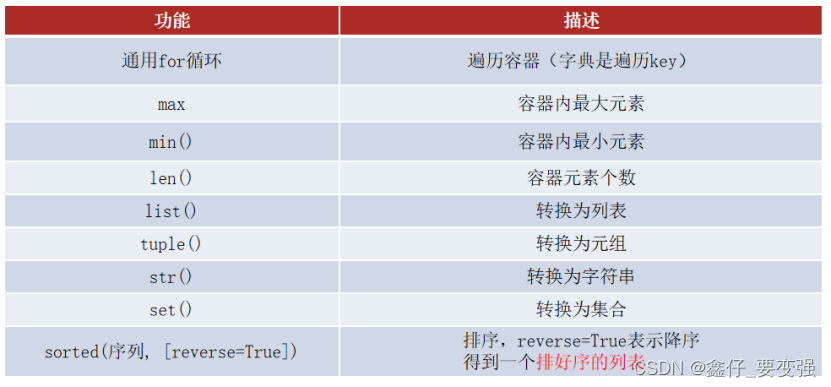
2)数据容器的通用操作 - 遍历
首先,在遍历上:
- 5类数据容器都支持for循环遍历
- 列表、元组、字符串支持while循环,集合、字典不支持(无法下标索引)
- 尽管遍历的形式各有不同,但是,它们都支持遍历操作
3) 数据容器的通用统计功能

4) 容器的通用转换功能

5) 容器通用排序功能
sorted(容器, [reverse=True])
将给定容器进行排序
注意,排序后都会得到列表(list)对象。
6)容器通用功能总览
7)ASCII码表

8)字符串比较
字符串是按位比较,也就是一位位进行对比,只要有一位大,那么整体就大。

从头到尾,一位位进行比较,其中一位大,后面就无需比较了。
5. 函数进阶
1)多个返回值

- 按照返回值的顺序,写对应顺序的多个变量接收即可
- 变量之间用逗号隔开
- 支持不同类型的数据return
2)函数参数种类
使用方式上的不同, 函数有4中常见参数使用方式:
- 位置参数:调用函数时根据函数定义的参数位置来传递参数

注意:
传递的参数和定义的参数的顺序及个数必须一致
2.关键字参数:函数调用时通过“键=值”形式传递参数
作用: 可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求.

注意:
函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序
3.缺省参数:缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用).
作用: 当调用函数时没有传递参数, 就会使用默认是用缺省参数对应的值.

注意:
函数调用时,如果为缺省参数传值则修改默认参数值, 否则使用这个默认值
4.不定长参数:不定长参数也叫可变参数. 用于不确定调用的时候会传递多少个参数(不传参也可以)的场景.
作用: 当调用函数时不确定参数个数时, 可以使用不定长参数
5.不定长参数的类型:
①位置传递

注意:
传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是位置传递
②关键字传递

注意:
参数是“键=值”形式的形式的情况下, 所有的“键=值”都会被kwargs接受, 同时会根据“键=值”组成字典.
3)匿名函数
函数作为参数传递

- 函数compute,作为参数,传入了test_func函数中使用。
- test_func需要一个函数作为参数传入,这个函数需要接收2个数字进行计算,计算逻辑由这个被传入函数决定
- compute函数接收2个数字对其进行计算,compute函数作为参数,传递给了test_func函数使用
- 最终,在test_func函数内部,由传入的compute函数,完成了对数字的计算操作
所以,这是一种,计算逻辑的传递,而非数据的传递。就像上述代码那样,不仅仅是相加,相见、相除、等任何逻辑都可以自行定义并作为函数传入。
Lambda匿名函数
函数的定义中:
- def关键字,可以定义带有名称的函数
- lambda关键字,可以定义匿名函数(无名称)
有名称的函数,可以基于名称重复使用。无名称的匿名函数,只可临时使用一次。
匿名函数定义语法:

lambda 是关键字,表示定义匿名函数
传入参数表示匿名函数的形式参数,如:x, y 表示接收2个形式参数
函数体,就是函数的执行逻辑,要注意:只能写一行,无法写多行代码

使用def和使用lambda,定义的函数功能完全一致,只是lambda关键字定义的函数是匿名的,无法二次使用.
1. 文件编码
编码就是一种规则集合,记录了内容和二进制间进行相互转换的逻辑。
编码有许多中,我们最常用的是UTF-8编码。
常用的编码:UTF-8,GBK,Big5 等。
2、文件的读取
文件的操作步骤:
① 打开文件
② 读写文件
③ 关闭文件
1)open()打开函数
open(name, mode, encoding)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
mode:设置打开文件的模式(访问模式):只读、写入、追加等。
encoding:编码格式(推荐使用UTF-8)
示例代码:
f = open('python.txt', 'r', encoding=”UTF-8)
# encoding的顺序不是第三位,所以不能用位置参数,用关键字参数直接指定。
mode常用的三种基础访问模式:

2)读操作相关方法
read()方法:
文件对象.read(num)
Num:表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。
readlines()方法:
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
f = open('python.txt')
content = f.readlines()
# ['hello world\n', 'abcdefg\n', 'aaa\n', 'bbb\n', 'ccc']
print(content)
# 关闭文件
f.close()
readline()方法:一次读取一行内容
案例:
f = open('python.txt')
content = f.readline()
print(f'第一行:{content}')
content = f.readline()
print(f'第二行:{content}')
# 关闭文件
f.close()
for循环读取文件行
for line in open("python.txt", "r"):
print(line)
# 每一个line临时变量,就记录了文件的一行数据
close() 关闭文件对象
f = open("python.txt", "r")
f.close()
# 最后通过close,关闭文件对象,也就是关闭对文件的占用
# 如果不调用close,同时程序没有停止运行,那么这个文件将一直被Python程序占用。
with open 语法
with open("python.txt", "r") as f:
f.readlines()
# 通过在with open的语句块中对文件进行操作
# 可以在操作完成后自动关闭close文件,避免遗忘掉close方法
文件读取操作汇总:

3、文件的写入
案例:

注意:
- 直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
- 当调用flush的时候,内容会真正写入文件
- 这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)
- w模式,文件不存在,会创建新文件
- w模式,文件存在,会清空原有内容
- close()方法,带有flush()方法的功能
4、文件的追加
案例:

注意:
- a模式,文件不存在会创建文件
- a模式,文件存在会在最后,追加写入文件
5、python 异常
异常就是程序运行的过程中出现了错误。
对可能出现的bug,进行提前准备、提前处理,这种行为我们称之为:异常处理(捕获异常)。
捕获异常的作用在于:提前假设某处会出现异常,做好提前准备,当真的出现异常的时候,可以有后续手段。


捕获指定异常:

注意事项
① 如果尝试执行的代码的异常类型和要捕获的异常类型不一致,则无法捕获异常。
② 一般try下方只放一行尝试执行的代码。
捕获所有异常
基本语法:

异常else

异常的finally
finally表示的是无论是否异常都要执行的代码,例如关闭文件。

异常是具有传递性的
案例:

6、python模块
1)模块的导入
Python模块(Module),是一个Python文件,以.py结尾. 模块能定义函数,类和变量,模块里也能包含可执行的代码.
模块的导入方式
![]()
常用的组合形式如:
- import 模块名
- from 模块名 import 类、变量、方法等
- from 模块名 import *
- import 模块名 as 别名
- from 模块名 import 功能名 as 别名
from 模块名 import * 导入模块的所有方法。
只在当前文件中调用该函数,其他导入的文件内不符合该条件,则不执行相关的函数调用。
if __name__ == '__main__':
test (1, 1)
如果一个模块文件中有`__all__`变量,当使用`from xxx import *`导入时,只能导入这个列表中的元素
__all__

7、python包
从物理上看,包就是一个文件夹,在该文件夹下包含了一个 __init__.py 文件,该文件夹可用于包含多个模块文件,从逻辑上看,包的本质依然是模块。

1)建立一个新的python包
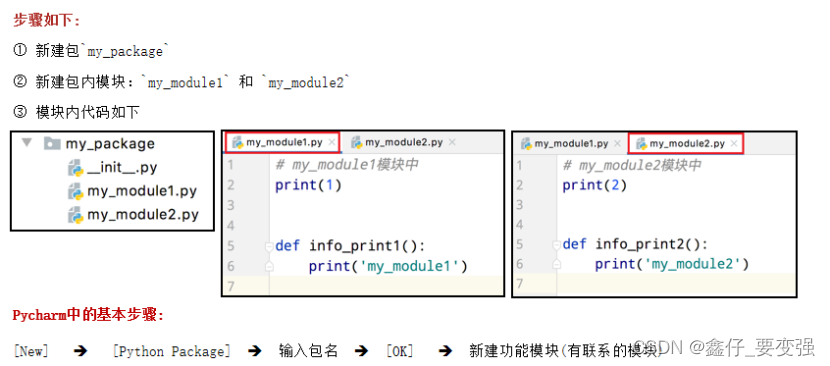
注意:新建包后,包内部会自动创建`__init__.py`文件,这个文件控制着包的导入行为。
2)导入包
方式一:

案例:

方式二:
注意:必须在`__init__.py`文件中添加`__all__ = []`,控制允许导入的模块列表
from 包名 import *















来源地址:https://blog.csdn.net/qq_47541315/article/details/127138652











