
这篇文章主要介绍Python中如何实现MNIST手写体识别,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
1.实验内容简述
1.1 实验环境
本实验采用的软硬件实验环境如表所示:

在Windows操作系统下,采用基于Tensorflow的Keras的深度学习框架,对MNIST进行训练和测试。
采用keras的深度学习框架,keras是一个专为简单的神经网络组装而设计的Python库,具有大量预先包装的网络类型,包括二维和三维风格的卷积网络、短期和长期的网络以及更广泛的一般网络。使用keras构建网络是直接的,keras在其Api设计中使用的语义是面向层次的,网络组建相对直观,所以本次选用Keras人工智能框架,其专注于用户友好,模块化和可扩展性。
1.2 MNIST数据集介绍
MNIST(官方网站)是非常有名的手写体数字识别数据集。它由手写体数字的图片和相对应的标签组成,如:

MNIST数据集分为训练图像和测试图像。训练图像60000张,测试图像10000张,每一个图片代表0-9中的一个数字,且图片大小均为28*28的矩阵。
train-images-idx3-ubyte.gz: training set images (9912422 bytes) 训练图片
train-labels-idx1-ubyte.gz: training set labels (28881 bytes) 训练标签
t10k-images-idx3-ubyte.gz: test set images (1648877 bytes) 测试图片
t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes) 测试标签
1.3 数据预处理
数据预处理阶段对图像进行归一化处理,我们将图片中的这些值缩小到 0 到 1 之间,然后将其馈送到神经网络模型。为此,将图像组件的数据类型从整数转换为浮点数,然后除以 255。这样更容易训练,以下是预处理图像的函数:务必要以相同的方式对训练集和测试集进行预处理:
之后对标签进行one-hot编码处理:将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点;机器学习算法中,特征之间距离的计算或相似度的常用计算方法都是基于欧式空间的;将离散型特征使用one-hot编码,会让特征之间的距离计算更加合理
2.实验核心代码
(1)MLP感知器
# Build MLPmodel = Sequential()model.add(Dense(units=256, input_dim=784, kernel_initializer='normal', activation='relu'))model.add(Dense(units=128, kernel_initializer='normal', activation='relu'))model.add(Dense(units=64, kernel_initializer='normal', activation='relu'))model.add(Dense(units=10, kernel_initializer='normal', activation='softmax'))model.summary()(2)CNN卷积神经网络
# Build LeNet-5model = Sequential()model.add(Conv2D(filters=6, kernel_size=(5, 5), padding='valid', input_shape=(28, 28, 1), activation='relu')) # C1model.add(MaxPooling2D(pool_size=(2, 2))) # S2model.add(Conv2D(filters=16, kernel_size=(5, 5), padding='valid', activation='relu')) # C3model.add(MaxPooling2D(pool_size=(2, 2))) # S4model.add(Flatten())model.add(Dense(120, activation='tanh')) # C5model.add(Dense(84, activation='tanh')) # F6model.add(Dense(10, activation='softmax')) # outputmodel.summary()模型解释
模型训练过程中,我们用到LENET-5的卷积神经网络结构。

第一层,卷积层
这一层的输入是原始的图像像素,LeNet-5 模型接受的输入层大小是28x28x1。第一卷积层的过滤器的尺寸是5x5,深度(卷积核种类)为6,不使用全0填充,步长为1。因为没有使用全0填充,所以这一层的输出的尺寸为32-5+1=28,深度为6。这一层卷积层参数个数是5x5x1x6+6=156个参数(可训练参数),其中6个为偏置项参数。因为下一层的节点矩阵有有28x28x6=4704个节点(神经元数量),每个节点和5x5=25个当前层节点相连,所以本层卷积层总共有28x28x6x(5x5+1)个连接。
第二层,池化层
这一层的输入是第一层的输出,是一个28x28x6=4704的节点矩阵。本层采用的过滤器为2x2的大小,长和宽的步长均为2,所以本层的输出矩阵大小为14x14x6。原始的LeNet-5 模型中使用的过滤器和这里将用到的过滤器有些许的差别,这里不过多介绍。
第三层,卷积层
本层的输入矩阵大小为14x14x6,使用的过滤器大小为5x5,深度为16。本层不使用全0填充,步长为1。本层的输出矩阵大小为10x10x16。按照标准卷积层本层应该有5x5x6x16+16=2416个参数(可训练参数),10x10x16x(5x5+1)=41600个连接。
第四层,池化层
本层的输入矩阵大小是10x10x16,采用的过滤器大小是2x2,步长为2,本层的输出矩阵大小为5x5x16。
第五层,全连接层
本层的输入矩阵大小为5x5x16。如果将此矩阵中的节点拉成一个向量,那么这就和全连接层的输入一样了。本层的输出节点个数为120,总共有5x5x16x120+120=48120个参数。
第六层,全连接层
本层的输入节点个数为120个,输出节点个数为84个,总共参数为120x84+84=10164个。
第七层,全连接层
LeNet-5 模型中最后一层输出层的结构和全连接层的结构有区别,但这里我们用全连接层近似的表示。本层的输入节点为84个,输出节点个数为10个,总共有参数84x10+10=850个。
模型过程
初始参数设定好之后开始训练,每次训练需要微调参数以得到更好的训练结果,经过多次尝试,最终设定参数为:
优化器:adam优化器
训练轮数:10
每次输入的数据量:500
LENET-5的卷积神经网络对MNIST数据集进行训练,并采用上述的模型参数,进行10轮训练,在训练集上达到了95%的准确率

3.结果分析机器总结
3.1 模型测试以及结果分析
为了验证模型的鲁棒性,在上述最优参数下保存在验证集上性能最好的模型,在测试集上进行最终的测试,得到最终的准确率为:95.13%.
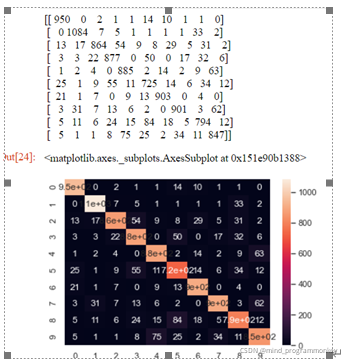
为了更好的分析我们的结果,这里用混淆矩阵来评估我们的模型性能。在模型评估之前,先学习一些指标。
TP(True Positive):将正类预测为正类数,真实为0,预测也为0FN(False Negative):将正类预测为负类数,真实为0,预测为1FP(False Positive):将负类预测为正类数, 真实为1,预测为0。TN(True Negative):将负类预测为负类数,真实为1,预测也为1混淆矩阵定义及表示含义:
混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总。其中矩阵的行表示真实值,矩阵的列表示预测值,下面以本次案例为例,看下矩阵表现形式,如下:

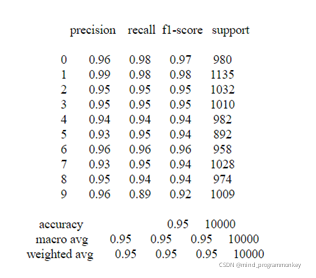
3.2 结果对比
并与四层全连接层模型进行对比,全连接层的模型结构如下:
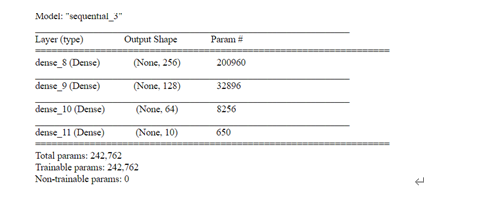
其结果如下:

总之,从结果上来看,最后经过不断地参数调优最终训练出了一个分类正确率在95%左右的模型,并且通过实验证明了模型具有很强的鲁棒性。
3.3 模型的预测
对单张图像进行预测:

以上是“Python中如何实现MNIST手写体识别”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注编程网行业资讯频道!







