
语义分割(Semantic Segmentation)是图像处理和机器视觉一个重要分支。与分类任务不同,语义分割需要判断图像每个像素点的类别,进行精确分割。语义分割目前在自动驾驶、自动抠图、医疗影像等领域有着比较广泛的应用。我总结了使用UNet网络做图像语义分割的方法,教程很详细,学者耐心学习。
目录
配套教程的源码包,下载链接为:添加链接描述,提取码:17pb。当然官网也给了源码包,官网下载链接为:添加链接描述。学者也可以下载官网提供的,建议学者直接下载我提供的学习,我已经补了一些坑,添加过一些实用代码。下载好我提供的源码包,解压后的样纸见下:
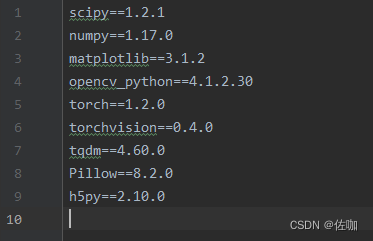
Python的版本选用3.7或者3.8都可以。
1、打标签
数据集的准备,看学者自己个人想要识别什么物体,自行准备即可。我提供的源码包中有我自己喷血已经打好标签的数据集,打标签需要用到的工具叫作labelme,关于labelme工具的具体使用教程,学者看我的另外一篇博客,链接为:添加链接描述
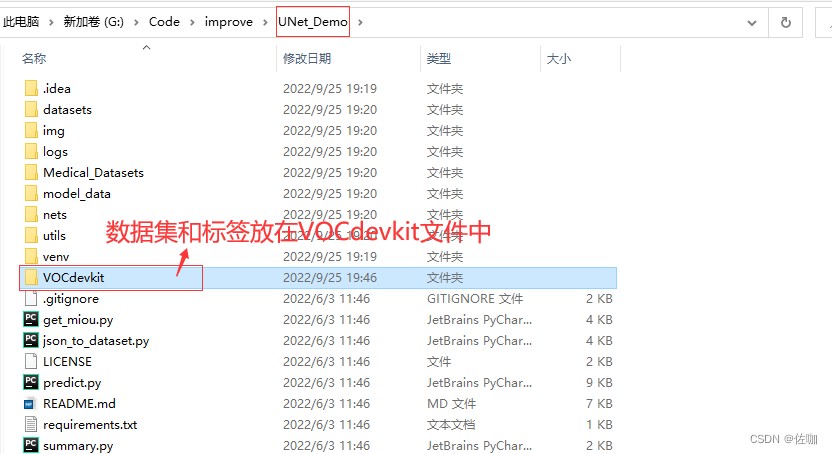
准备好的数据集先存放到工程文件夹下的datasets文件下,具体的文件存放位置关系见下:
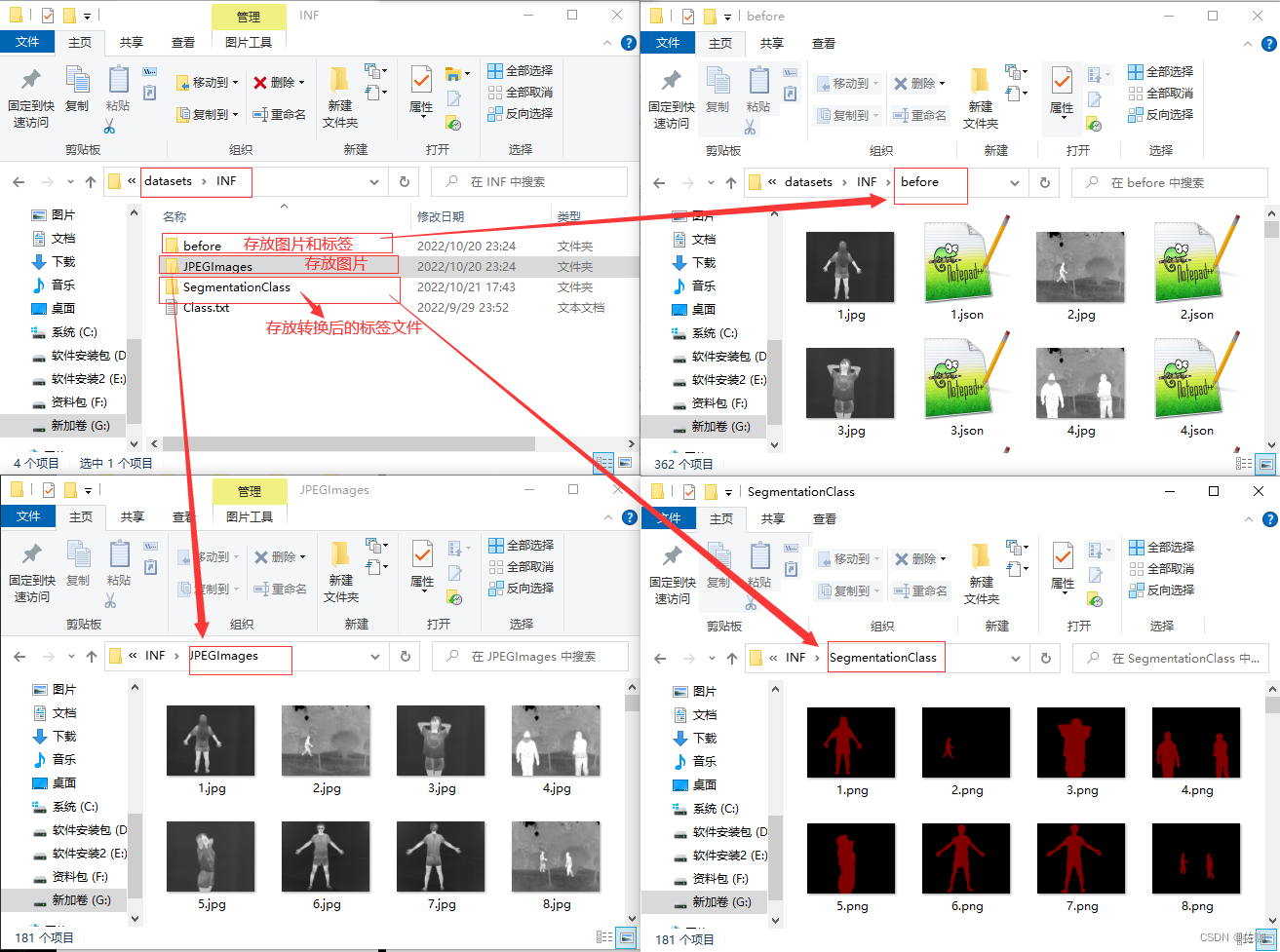
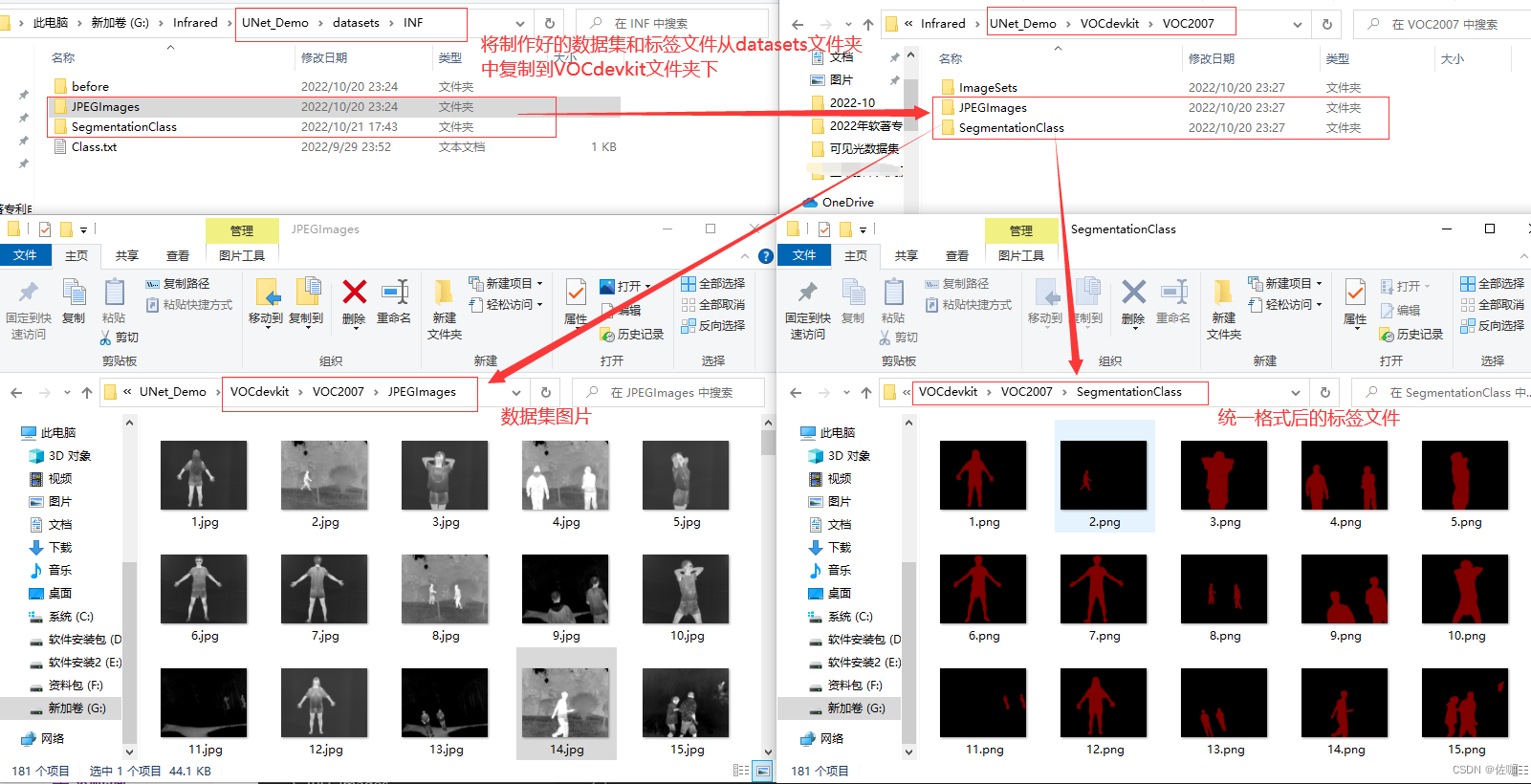
2、复制数据集和标签文件到VOCdevkit文件中
通过上面步骤制作好标签文件后,将数据集和标签文件从datasets文件中复制一份到VOCdevkit文件中,具体见下:
3、提取训练集和验证集图片名称
代码中需要修改到的地方见下:
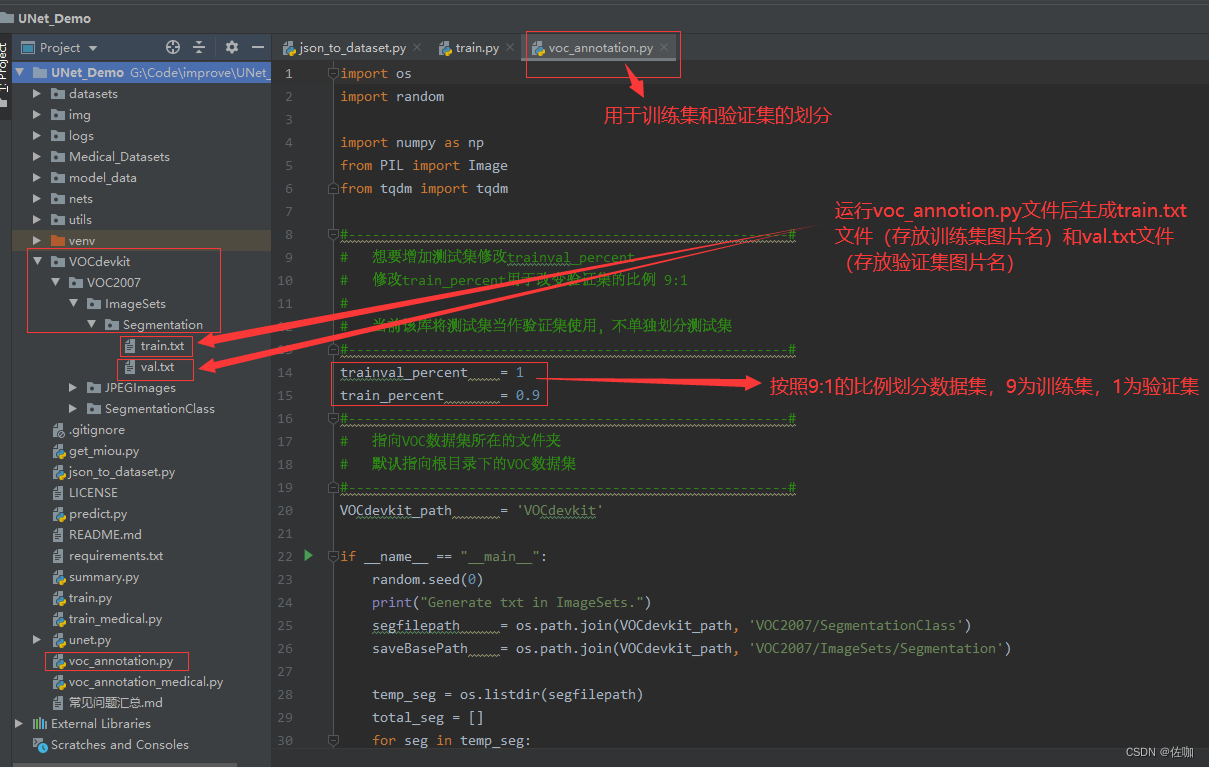
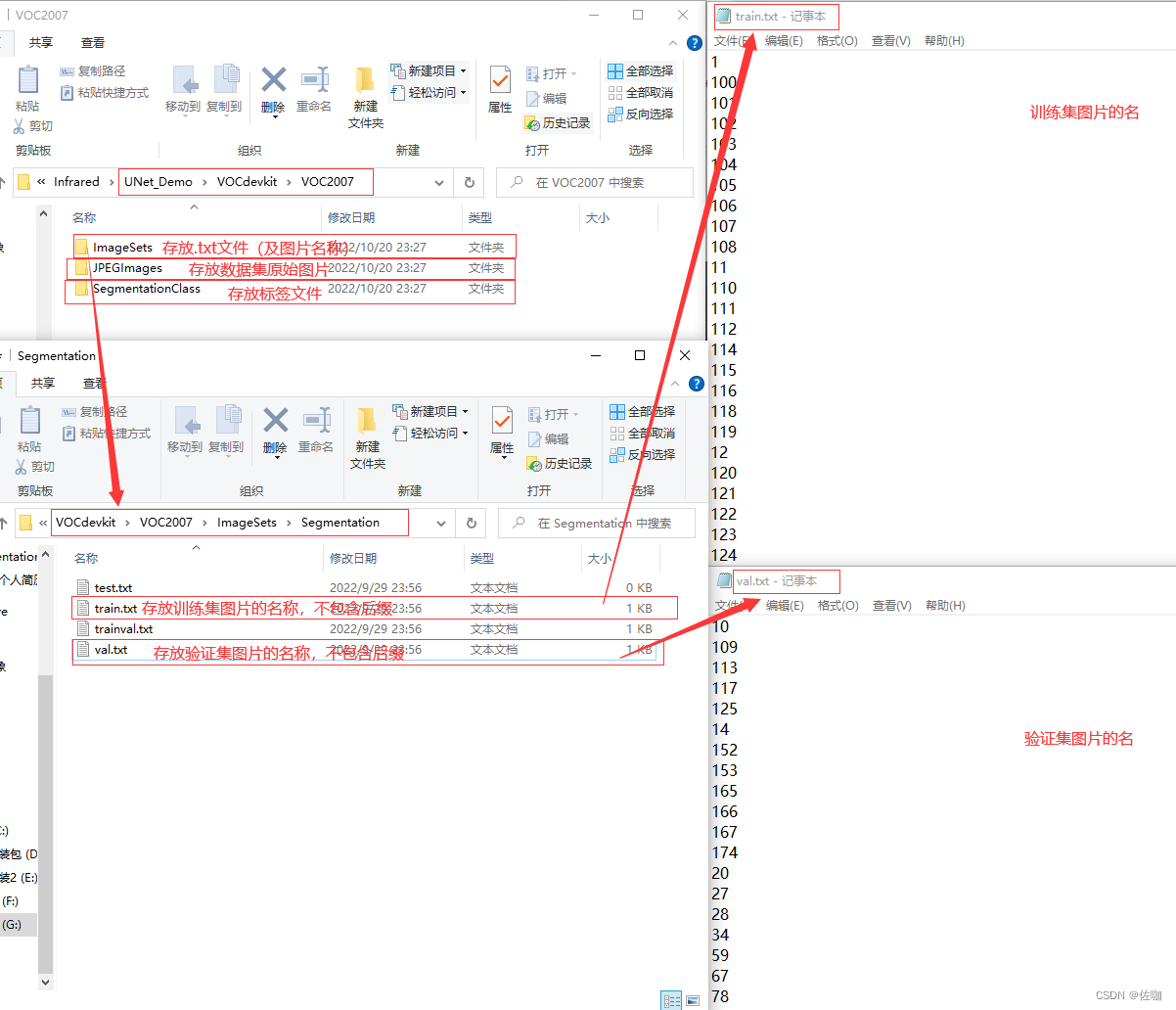
学者只要运行源码包中的voc_annotion.py文件后,就可以在 ./VOCdevkit/VOC2007/ImageSets/Segmentation目录下自动生成train.txt和val.txt文件,具体见下:
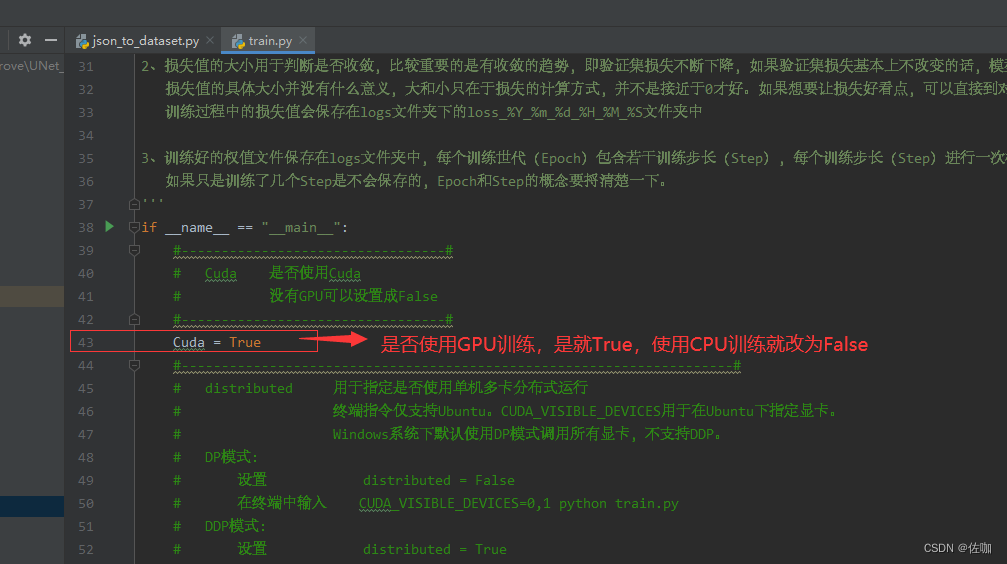
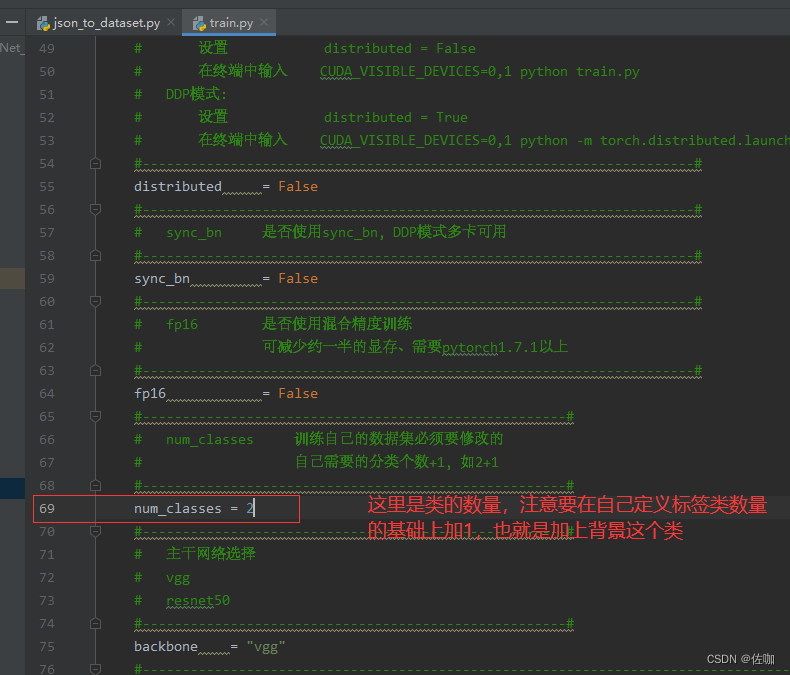
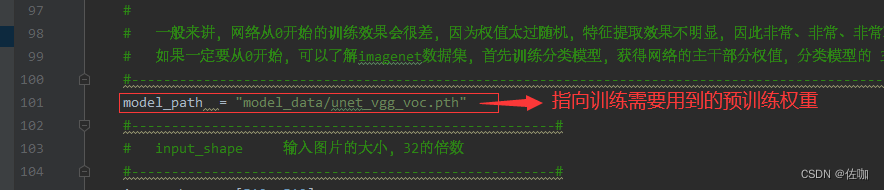
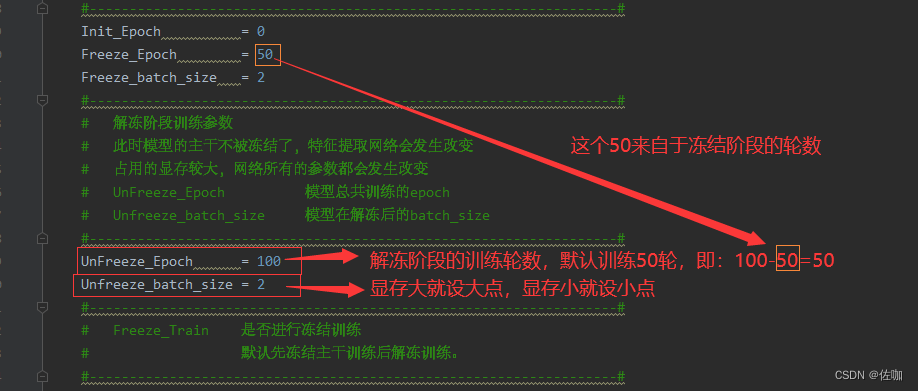
1、训练参数的修改
下面有很多的参数可以修改,学者根据自己的训练情况进行修改即可,训练修改的参数都在train.py文件中,具体见下:











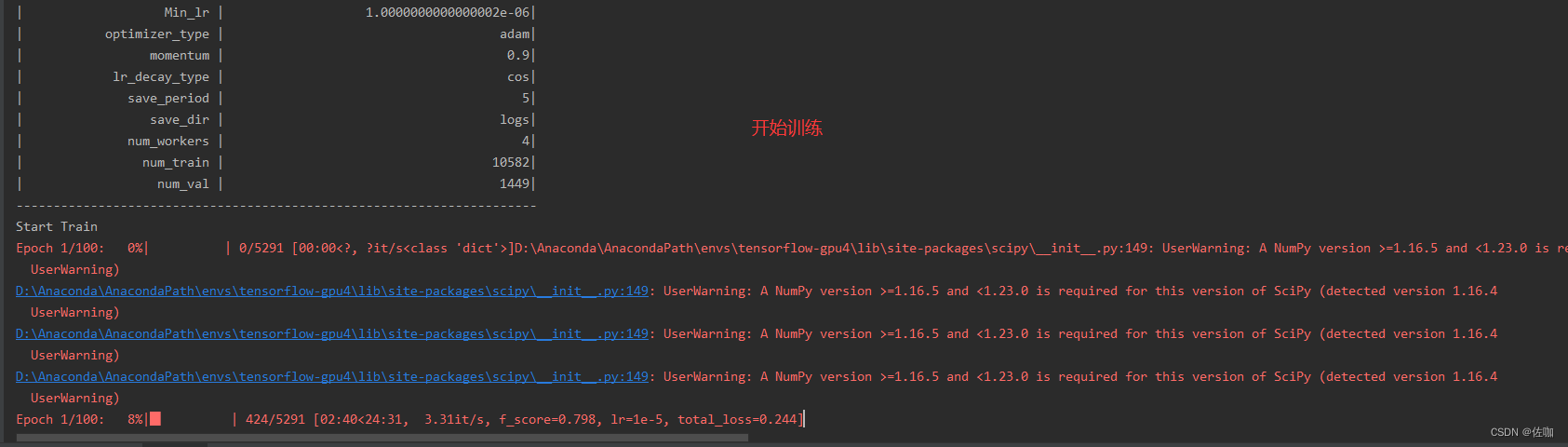
2、开始训练
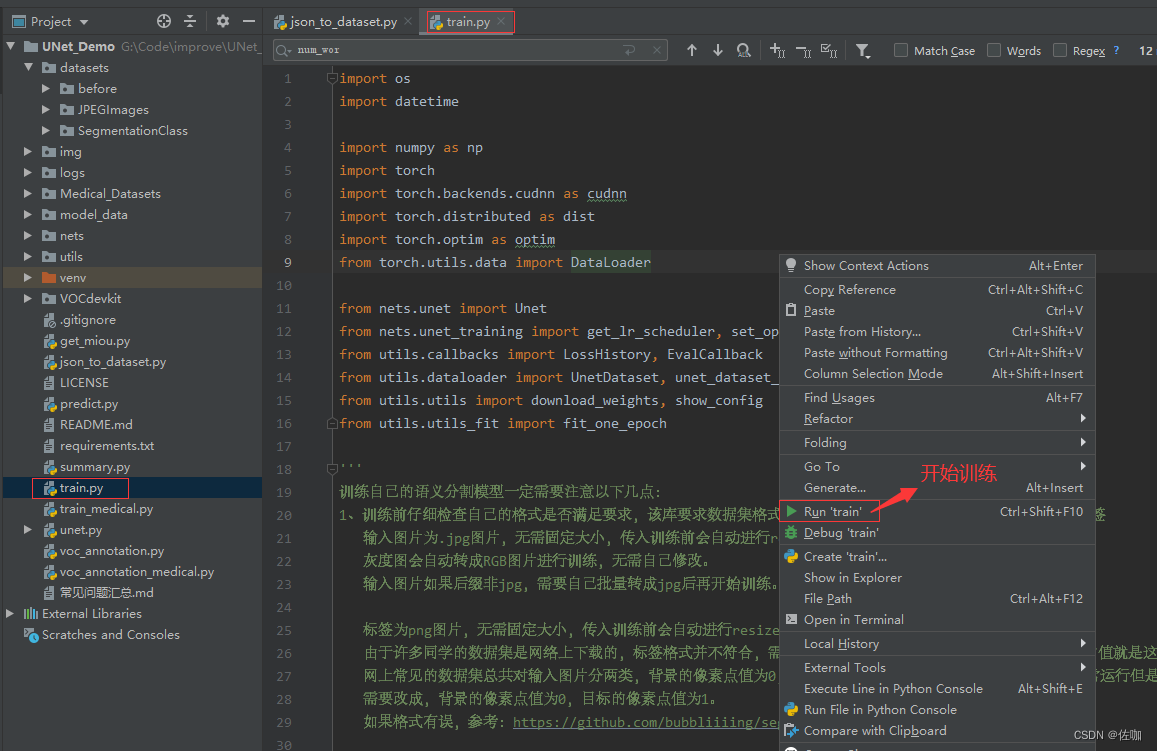
上面的参数修改好后,直接运行train.py文件就开始训练了,见下:
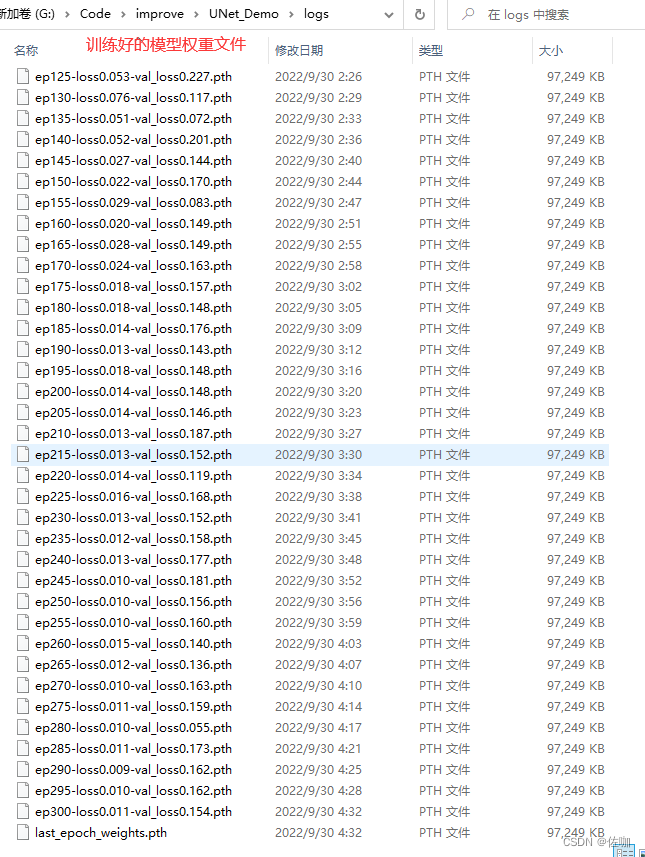
1、保存模型权重文件
上面的训练好后,模型都会被保存到工程文件夹根目录中的logs文件中,见下:
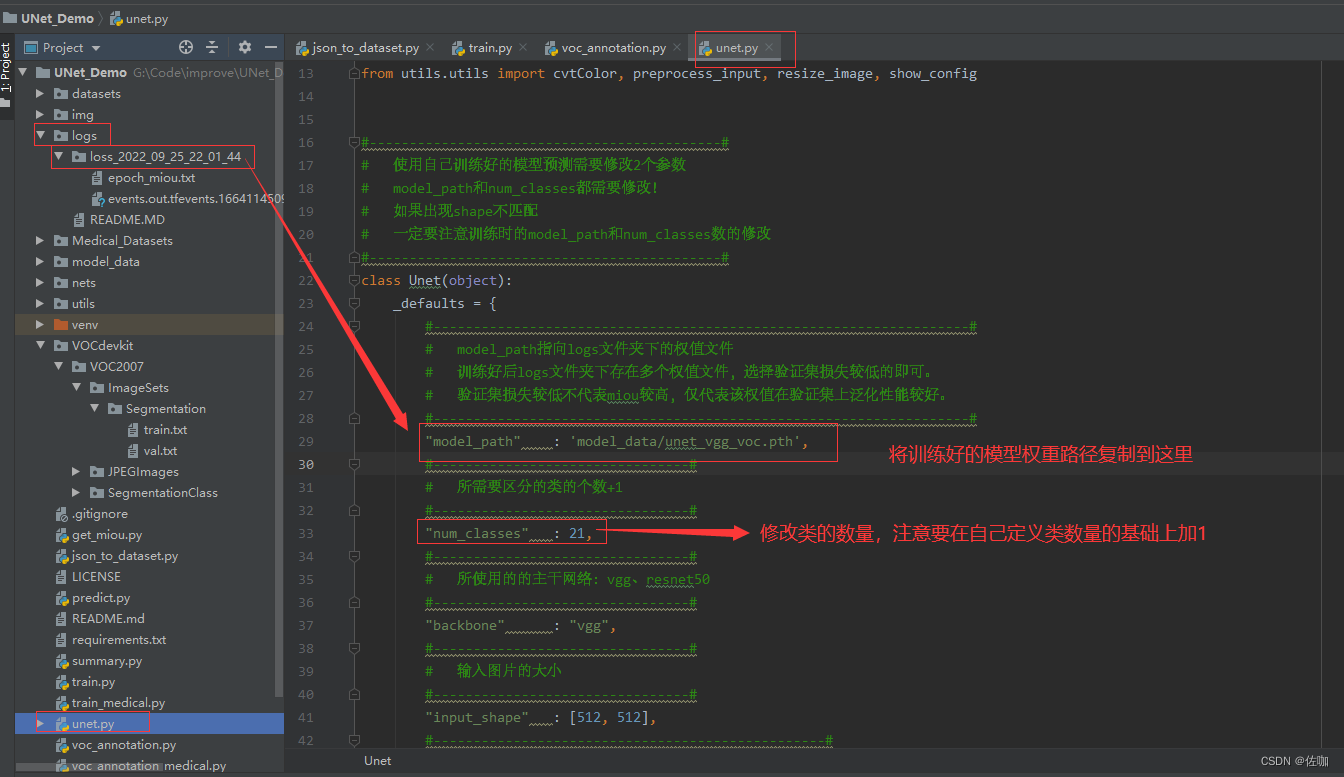
2、修改模型测试参数
测试模型时,需要修改到的地方见下:



学者在测试的时候,有三种模式可以选择,(1)测试图片;(2)测试电脑硬盘中的视频;(3)调用电脑自带摄像头测试。三种模式的选择,学者修改下面代码即可,见下:
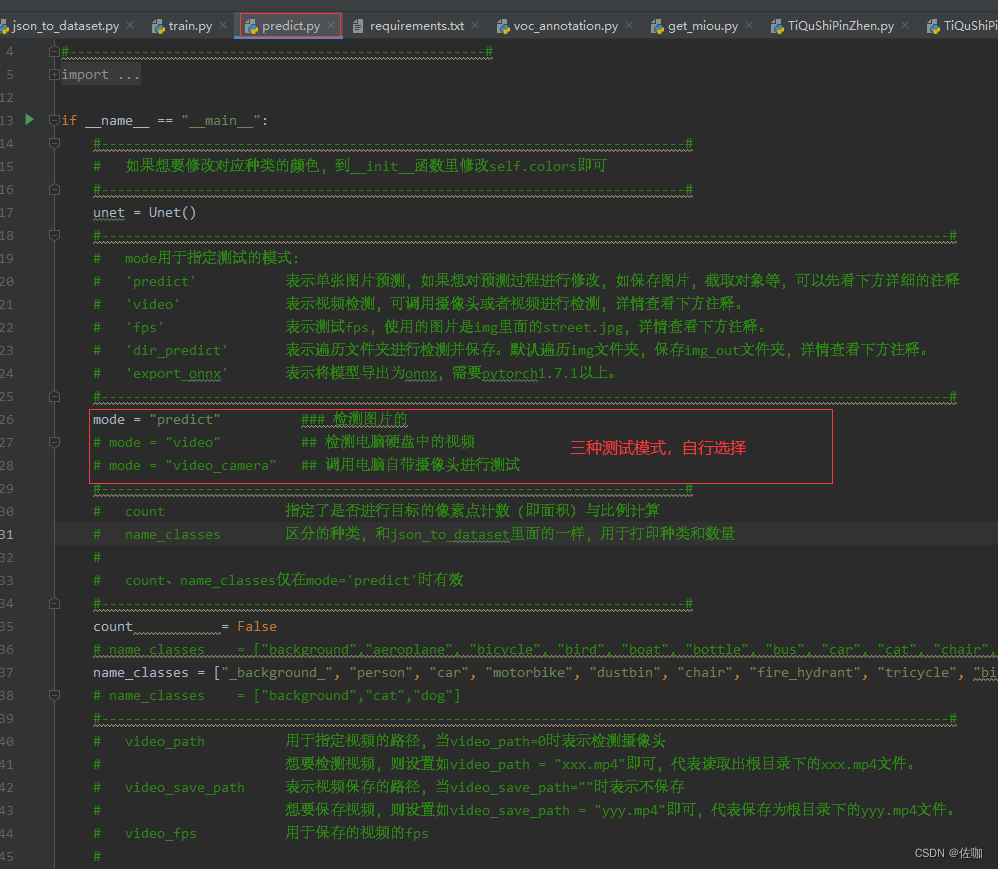
3、开始模型测试
上面的模型测试参数修改好后,直接运行predict.py即可开始预测:
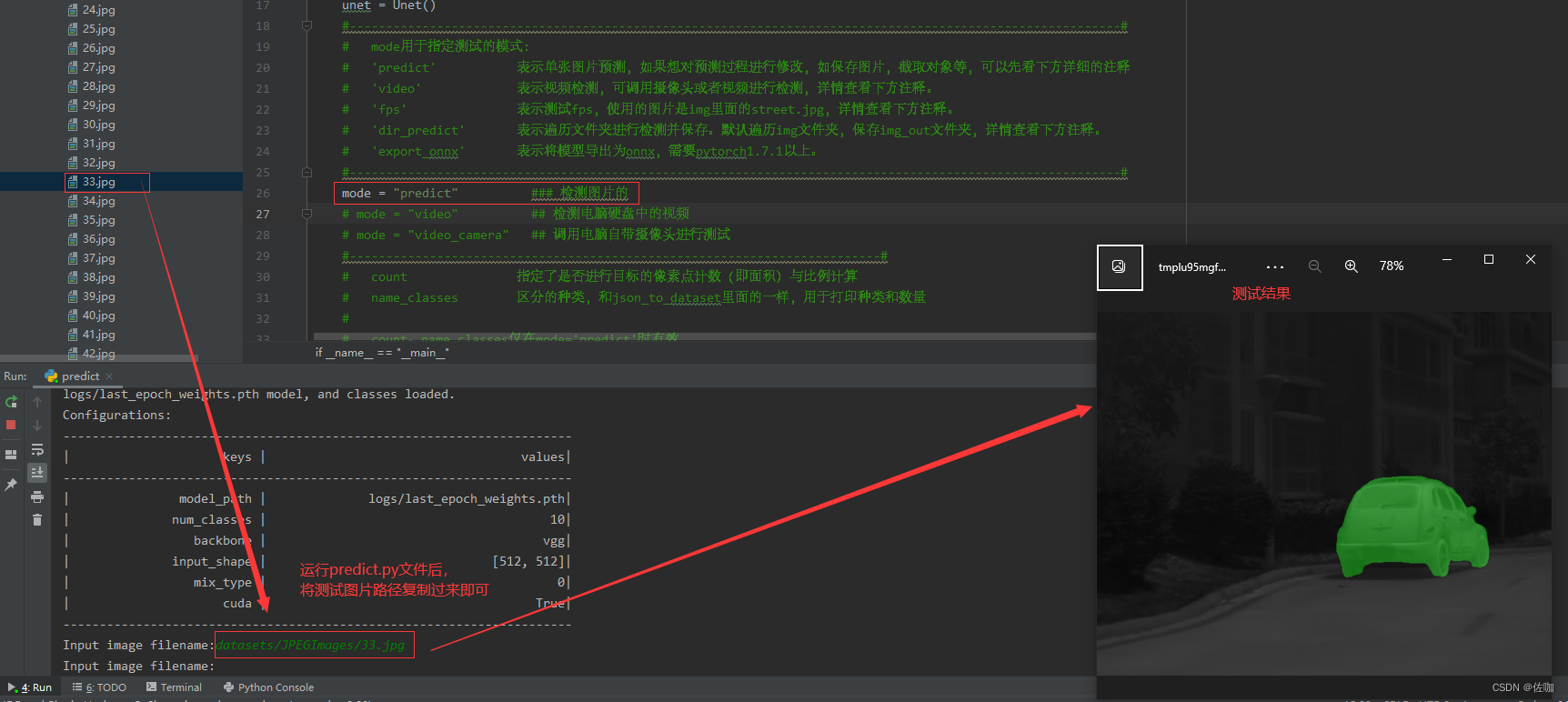
3.1、图片测试
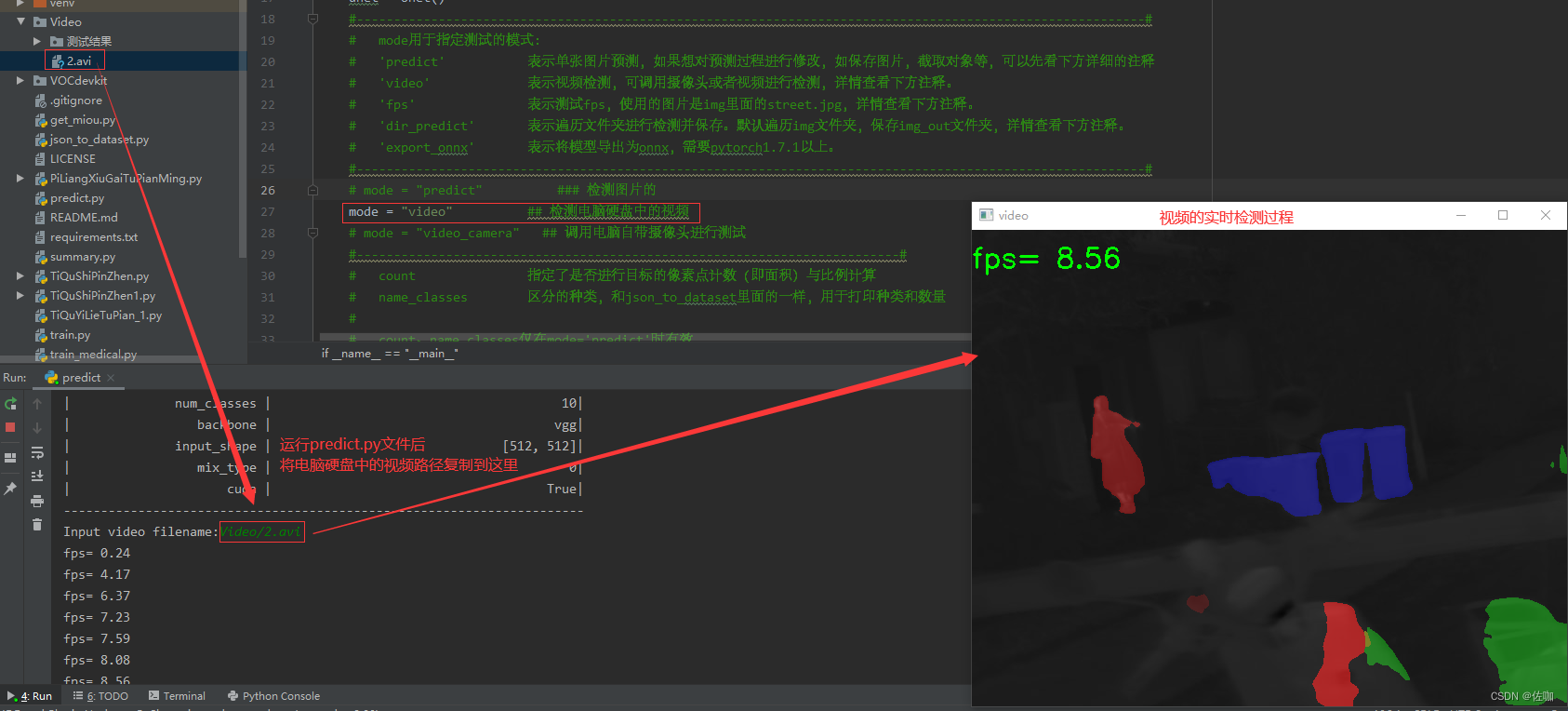
3.2、电脑硬盘中视频测试
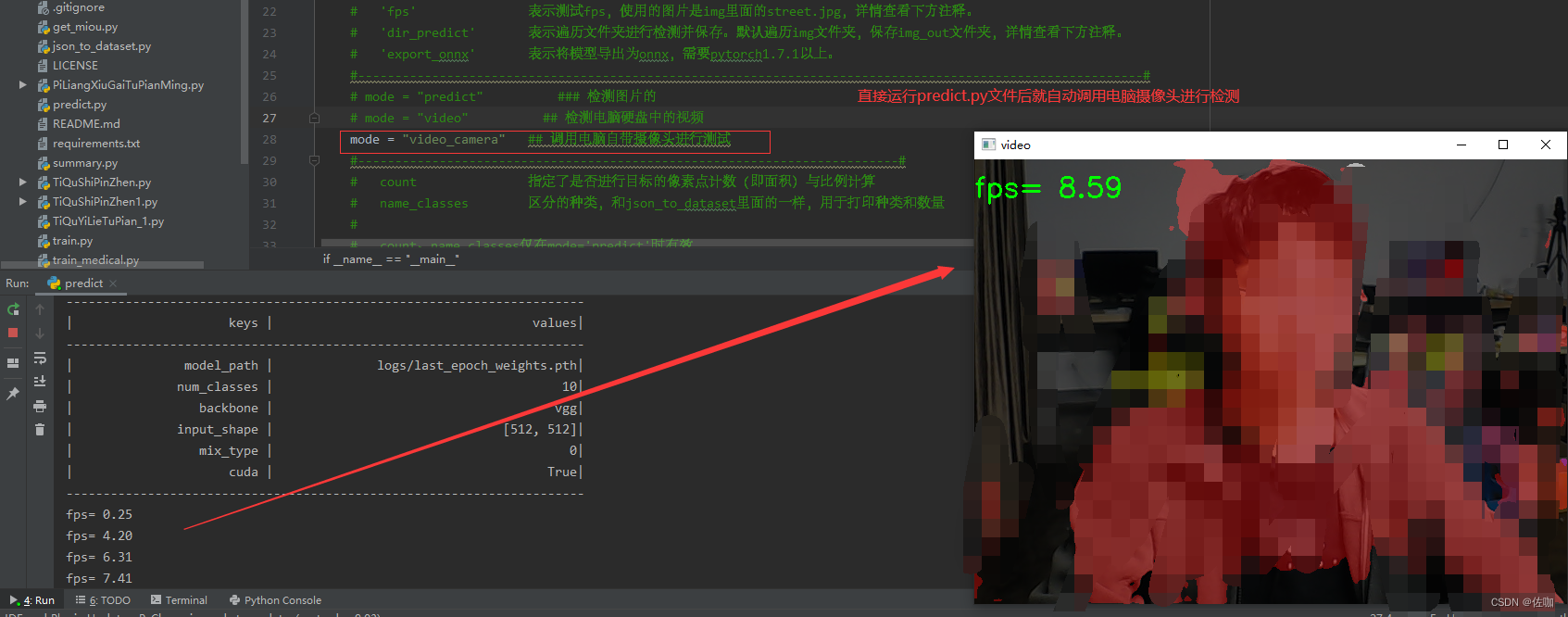
3.3、调用电脑自带摄像头测试
以上就是使用UNet做图像语义分割,自己打标签训练的详细教程,参数调整部分,学者根据需求自行调整,很多参数保持默认即可,参数name_classes的数量和类名一定要根据自己数据集修改。希望我总结的教程帮你快速上手使用,谢谢!
来源地址:https://blog.csdn.net/qq_40280673/article/details/127449624







