
本篇内容介绍了“怎么使用Go实现健壮的内存型缓存”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
使用Go实现健壮的内存型缓存
本文介绍了缓存的常见使用场景、选型以及注意点,比较有价值。
译自:Implementing robust in-memory cache with Go
内存型缓存是一种以消费内存为代价换取应用性能和弹性的方式,同时也推迟了数据的一致性。在使用内存型缓存时需要注意并行更新、错误缓存、故障转移、后台更新、过期抖动,以及缓存预热和转换等问题。
由来
缓存是提升性能的最便捷的方式,但缓存不是万能的,在某些场景下,由于事务或一致性的限制,你无法重复使用某个任务的结果。缓存失效是计算机科学中最常见的两大难题之一。
如果将操作限制在不变的数据上,则无需担心缓存失效。此时缓存仅用于减少网络开销。然而,如果需要与可变数据进行同步,则必须关注缓存失效的问题。
最简单的方式是基于TTL来设置缓存失效。虽然这种方式看起来逊于基于事件的缓存失效方式,但它简单且可移植性高。由于无法保证事件能够即时传递,因此在最坏的场景中(如事件代理短时间下线或过载),事件甚至还不如TTL精确。
短TTL通常是性能和一致性之间的一种折衷方式。它可以作为一道屏障来降低高流量下到数据源的负载。
Demo应用
下面看一个简单的demo应用,它接收带请求参数的URL,并根据请求参数返回一个JSON对象。由于数据存储在数据库中,因此整个交互会比较慢。
下面将使用一个名为plt的工具对应用进行压测,plt包括参数:
cardinality- 生成的唯一的URLs的数据,会影响到缓存命中率group- 一次性发送的URL相似的请求个数,模拟对相同键的并发访问。
go run ./cmd/cplt --cardinality 10000 --group 100 --live-ui --duration 10h --rate-limit 5000 curl --concurrency 200 -X 'GET' 'http://127.0.0.1:8008/hello?name=World&locale=ru-RU' -H 'accept: application/json'上述命令会启动一个client,循环发送10000个不同的URLs,每秒发送5000个请求,最大并发数为200。每个URL会以100个请求为批次将进行发送,用以模仿单个资源的并发,下面展示了实时数据:
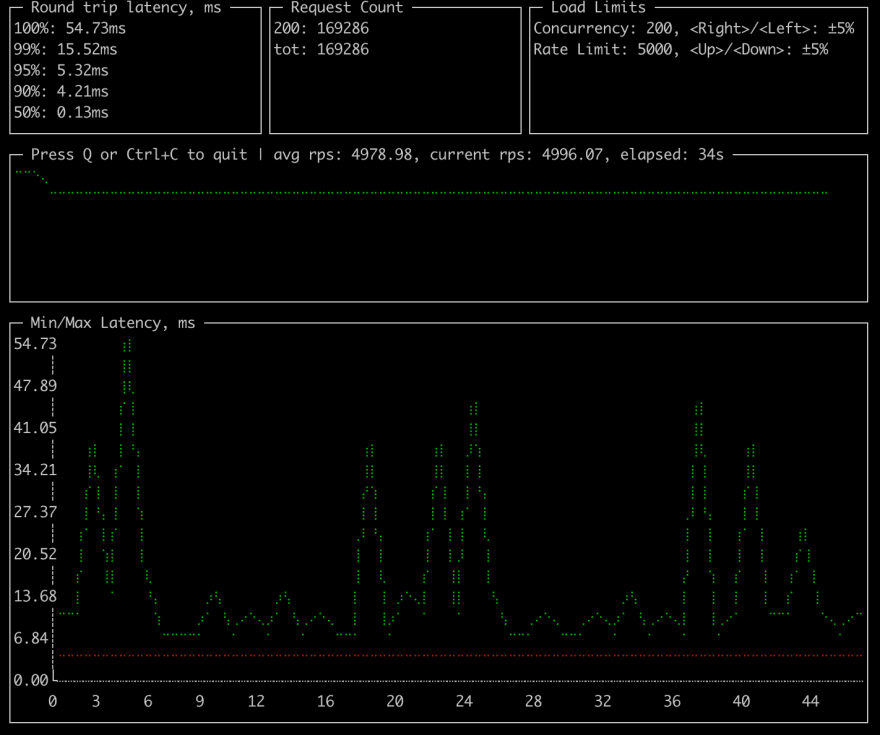
Demo应用通过CACHE环境变量定义了三种操作模式:
none:不使用缓存,所有请求都会涉及数据库naive:使用简单的map,TTL为3分钟advanced:使用github.com/bool64/cache 库,实现了很多特性来提升性能和弹性,TTL也是3分钟。
Demo应用的代码位于:github.com/vearutop/cache-story,可以使用make start-deps run命令启动demo应用。
在不使用缓存的条件下,最大可以达到500RPS,在并发请求达到130之后DB开始因为 Too many connections而阻塞,这种结果不是最佳的,虽然并不严重,但需要提升性能。
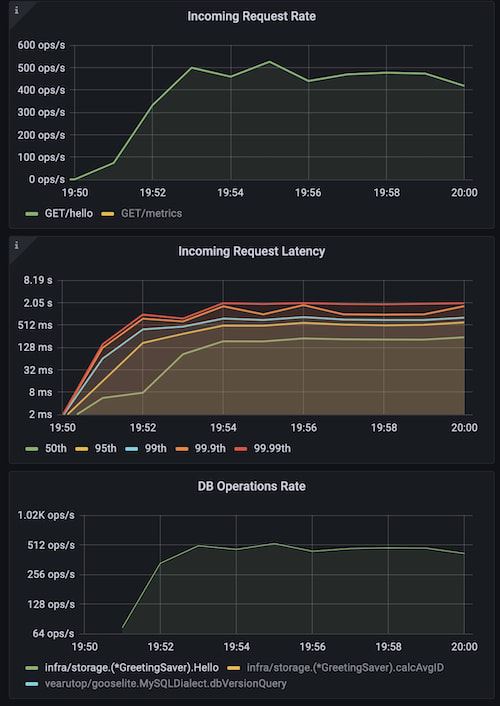
使用advanced缓存的结果如下,吞吐量提升了60倍,并降低了请求延迟以及DB的压力:
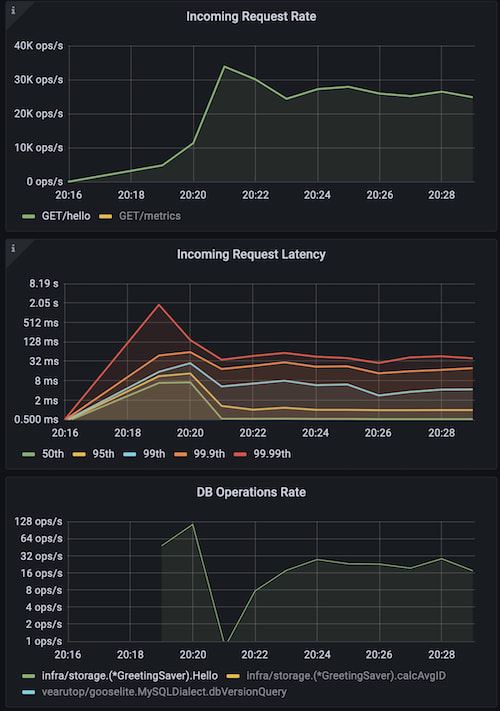
go run ./cmd/cplt --cardinality 10000 --group 100 --live-ui --duration 10h curl --concurrency 100 -X 'GET' 'http://127.0.0.1:8008/hello?name=World&locale=ru-RU' -H 'accept: application/json'Requests per second: 25064.03Successful requests: 15692019Time spent: 10m26.078sRequest latency percentiles:99%: 28.22ms95%: 13.87ms90%: 9.77ms50%: 2.29ms字节 VS 结构体
哪个更佳?
取决于使用场景,字节缓存([]byte)的优势如下:
数据不可变,在访问数据时需要进行解码
由于内存碎片较少,使用的内存也较少
对垃圾回收友好,因为没有什么需要遍历的
便于在线路上传输
允许精确地限制内存
字节缓存的最大劣势是编解码带来的开销,在热点循环中,编解码导致的开销可能会非常大。
结构体的优势:
在访问数据时无需进行编码/解码
更好地表达能力,可以缓存那些无法被序列化的内容
结构体缓存的劣势:
由于结构体可以方便地进行修改,因此可能会被无意间修改
结构体的内存相对比较稀疏
如果使用了大量长时间存在的结构体,GC可能会花费一定的时间进行遍历,来确保这些结构体仍在使用中,因此会对GC采集器造成一定的压力
几乎无法限制缓存实例的总内存,动态大小的项与其他所有项一起存储在堆中。
本文使用了结构体缓存。
Native 缓存
使用了互斥锁保护的map。当需要检索一个键的值时,首先查看缓存中是否存在该数据以及有没有过期,如果不存在,则需要从数据源构造该数据并将其放到缓存中,然后返回给调用者。
整个逻辑比较简单,但某些缺陷可能会导致严重的问题。
并发更新
当多个调用者同时miss相同的键时,它们会尝试构建数据,这可能会导致死锁或因为缓存踩踏导致资源耗尽。此外如果调用者尝试构建值,则会造成额外的延迟。
如果某些构建失败,即使缓存中可能存在有效的值,此时父调用者也会失败。
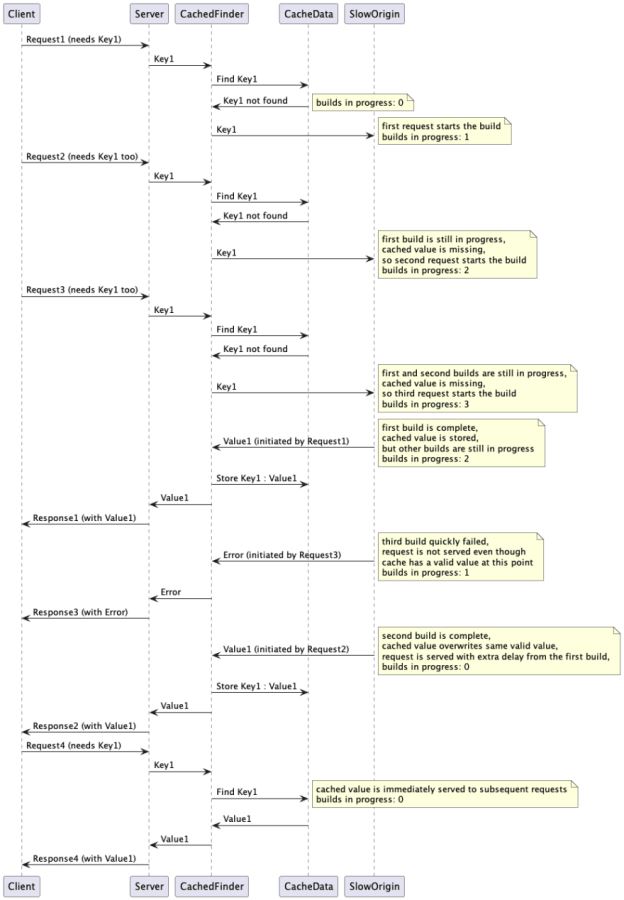
可以使用低cardinality和高group来模拟上述问题:
go run ./cmd/cplt --cardinality 100 --group 1000 --live-ui --duration 10h --rate-limit 5000 curl --concurrency 150 -X 'GET' 'http://127.0.0.1:8008/hello?name=World&locale=ru-RU' -H 'accept: application/json'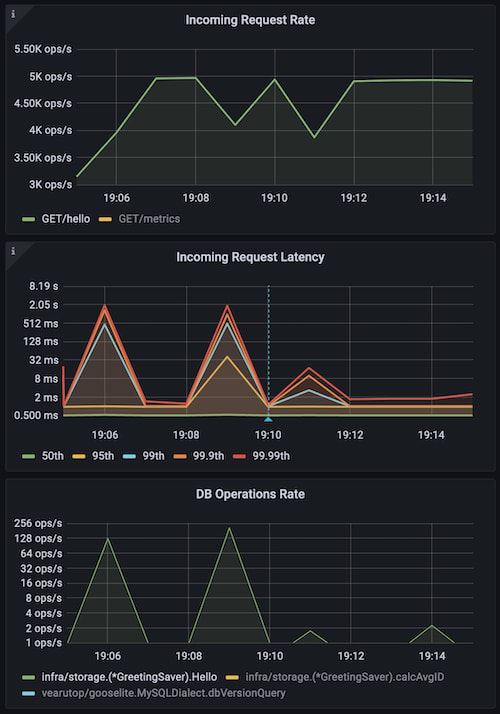
上图展示了使用naive缓存的应用,蓝色标志标识重启并使用advanced缓存。可以看到锁严重影响了性能(Incoming Request Latency)和资源使用(DB Operation Rate)。
一种解决方案是阻塞并行构建,这样每次只能进行一个构建。但如果有大量并发调用者请求各种键,则可能会导致严重的锁竞争。
更好的方式是对每个键的构建单独加锁,这样某个调用者就可以获取锁并执行构建,其他调用者则等待构建好的值即可。
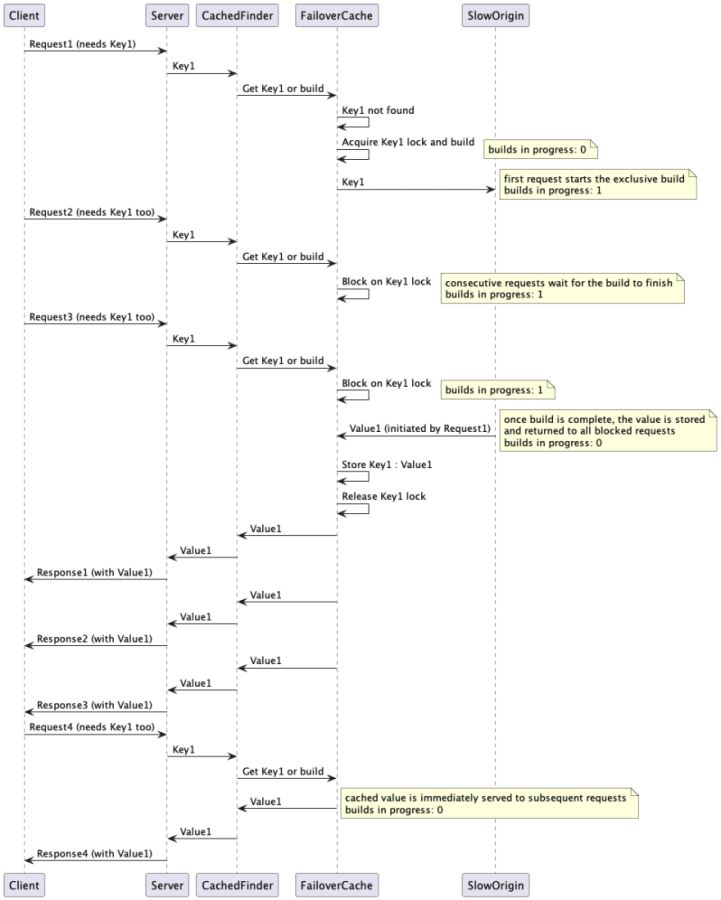
后台更新
当缓存过期时,需要一个新的值,构建新值可能会比较慢。如果同步进行,则可以减慢尾部延迟(99%以上)。可以提前构建那些被高度需要的缓存项(甚至在数据过期前)。如果可以容忍老数据,也可以继续使用这些数据。
这种场景下,可以使用老的/即将过期的数据提供服务,并在后台进行更新。需要注意的是,如果构建依赖父上下文,则在使用完老数据之后可能会取消上下文(如满足父HTTP请求),如果我们使用这类上下文来访问数据,则会得到一个context canceled错误。
解决方案是将上下文与父上下文进行分离,并忽略父上下文的取消行为。
另外一种策略是主动构建那些即将过期的缓存项,而无需父请求,但这样可能会因为一直淘汰那些无人关心的缓存项而导致资源浪费。
同步过期
假设启动了一个使用TTL缓存的实例,由于此时缓存是空的,所有请求都会导致缓存miss并创建值。这样会导致数据源负载突增,每个保存的缓存项的过期时间都非常接近。一旦超过TTL,大部分缓存项几乎会同步过期,这样会导致一个新的负载突增,更新后的值也会有一个非常接近的过期时间,以此往复。
这种问题常见于热点缓存项,最终这些缓存项会同步更新,但需要花费一段时间。
对这种问题的解决办法是在过期时间上加抖动。
如果过期抖动为10%,意味着,过期时间为0.95 * TTL 到1.05 * TTL。虽然这种抖动幅度比较小,但也可以帮助降低同步过期带来的问题。
下面例子中,使用高cardinality 和高concurrency模拟这种情况。它会在短时间内请求大量表项,以此构造过期峰值。
go run ./cmd/cplt --cardinality 10000 --group 1 --live-ui --duration 10h --rate-limit 5000 curl --concurrency 200 -X 'GET' 'http://127.0.0.1:8008/hello?name=World&locale=ru-RU' -H 'accept: application/json'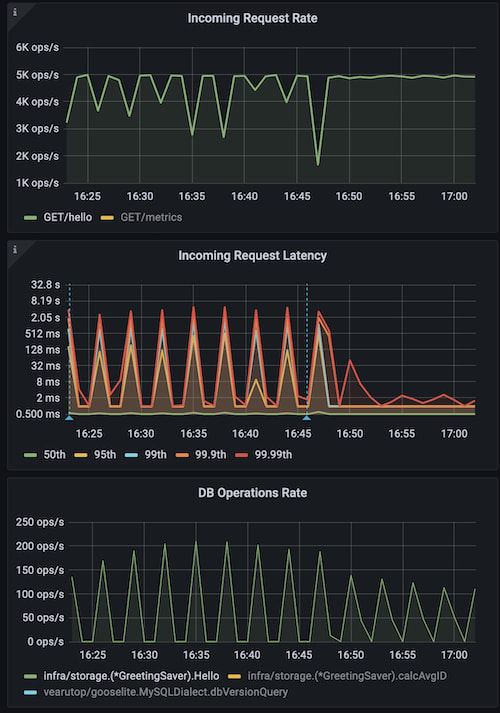
从上图可以看出,使用naive缓存无法避免同步过期问题,蓝色标识符表示重启服务并使用带10%抖动的advanced缓存,可以看到降低了峰值,且整体服务更加稳定。
缓存错误
当构建值失败,最简单的方式就是将错误返回给调用者即可,但这种方式可能会导致严重的问题。
例如,当服务正常工作时可以借助缓存处理10K的RPS,但突然出现缓存构建失败(可能由于短时间内数据库过载、网络问题或如错误校验等逻辑错误),此时所有的10K RPS都会命中数据源(因为此时没有缓存)。
对于高负载系统,使用较短的TTL来缓存错误至关重要。
故障转移模式
有时使用过期的数据要好于直接返回错误,特别是当这些数据刚刚过期,这类数据有很大概率等于后续更新的数据。
故障转移以精确性来换取弹性,通常是分布式系统中的一种折衷方式。
缓存传输
缓存有相关的数据时效果最好。
当启动一个新的实例时,缓存是空的。由于产生有用的数据需要花费一定的时间,因此这段时间内,缓存效率会大大降低。
有一些方式可以解决"冷"缓存带来的问题。如可以通过遍历数据来预热那些可能有用的数据。
例如可以从数据库表中拉取最近使用的内容,并将其保存到缓存中。这种方式比较复杂,且并不一定能够生效。
此外还可以通过定制代码来决定使用哪些数据并在缓存中重构这些表项。但这样可能会对数据库造成一定的压力。
还可以通过共享缓存实例(如redis或memcached)来规避这种问题,但这也带来了另一种问题,通过网络读取数据要远慢于从本地缓存读取数据。此外,网络带宽也可能成为性能瓶颈,网络数据的编解码也增加了延迟和资源损耗。
最简单的办法是将缓存从活动的实例传输到新启动的实例中。
活动实例缓存的数据具有高度相关性,因为这些数据是响应真实用户请求时产生的。
传输缓存并不需要重构数据,因此不会滥用数据源。
在生产系统中,通常会并行多个应用实例。在部署过程中,这些实例会被顺序重启,因此总有一个实例是活动的,且具有高质量的缓存。
Go有一个内置的二进制系列化格式encoding/gob,它可以帮助以最小的代价来传输数据,缺点是这种方式使用了反射,且需要暴露字段。
使用缓存传输的另一个注意事项是不同版本的应用可能有不兼容的数据结构,为了解决这种问题,需要为缓存的结构添加指纹,并在不一致时停止传输。
下面是一个简单的实现:
// RecursiveTypeHash hashes type of value recursively to ensure structural match.func recursiveTypeHash(t reflect.Type, h hash.Hash74, met map[reflect.Type]bool) { for { if t.Kind() != reflect.Ptr { break } t = t.Elem() } if met[t] { return } met[t] = true switch t.Kind() { case reflect.Struct: for i := 0; i < t.NumField(); i++ { f := t.Field(i) // Skip unexported field. if f.Name != "" && (f.Name[0:1] == strings.ToLower(f.Name[0:1])) { continue } if !f.Anonymous { _, _ = h.Write([]byte(f.Name)) } recursiveTypeHash(f.Type, h, met) } case reflect.Slice, reflect.Array: recursiveTypeHash(t.Elem(), h, met) case reflect.Map: recursiveTypeHash(t.Key(), h, met) recursiveTypeHash(t.Elem(), h, met) default: _, _ = h.Write([]byte(t.String())) }}可以通过HTTP或其他合适的协议来传输缓存数据,本例中使用了HTTP,代码为/debug/transfer-cache。注意,缓存可能会包含不应该对外暴露的敏感信息。
在本例中,可以借助于单个启用了不同端口的应用程序实例来执行传输:
CACHE_TRANSFER_URL=http://127.0.0.1:8008/debug/transfer-cache HTTP_LISTEN_ADDR=127.0.0.1:8009 go run main.go2022-05-09T02:33:42.871+0200 INFO cache/http.go:282 cache restored {"processed": 10000, "elapsed": "12.963942ms", "speed": "39.564084 MB/s", "bytes": 537846}2022-05-09T02:33:42.874+0200 INFO brick/http.go:66 starting server, Swagger UI at http://127.0.0.1:8009/docs2022-05-09T02:34:01.162+0200 INFO cache/http.go:175 cache dump finished {"processed": 10000, "elapsed": "12.654621ms", "bytes": 537846, "speed": "40.530944 MB/s", "name": "greetings", "trace.id": "31aeeb8e9e622b3cd3e1aa29fa3334af", "transaction.id": "a0e8d90542325ab4"}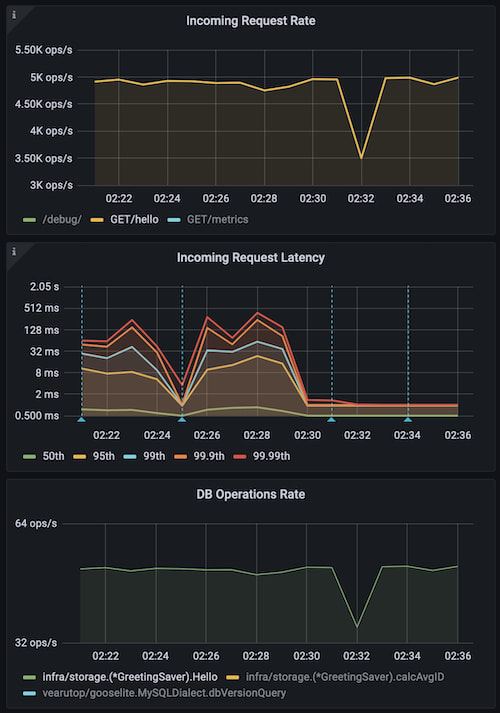
上图中蓝色标识标识应用重启,最后两条为缓存传输。可以看到性能不受影响,而在没有缓存传输的情况下,会受到严重的预热惩罚。
一个不那么明显的好处是,可以将缓存数据传输到本地开发机器,用于重现和调试生产环境的问题。
锁竞争和底层性能
基本每种缓存实现都会使用键值映射来支持并发访问(通常是读)。
大多数场景下可以忽略底层性能带来的影响。例如,如果使用内存型缓存来处理HTTP API,使用最简单的map+mutex就足够了,这是因为IO操作所需的时间要远大于内存操作。记住这一点很重要,以免过早地进行优化以及增加不合理的复杂性。
如果依赖内存型缓存的应用是CPU密集型的,此时锁竞争可能会影响到整体性能。
为了避免并发读写下的数据冲突,可能会引入锁竞争。在使用单个互斥锁的情况下,这种同步可能会限制同一时间内只能进行一个操作,这也意味着多核CPU可能无法发挥作用。
对于以读为主的负载,标准的sync.Map 就可以满足性能要求,但对于以写为主的负载,则会降低其性能。有一种比sync.Map性能更高的方式github.com/puzpuzpuz/xsync.Map,它使用了 Cache-Line Hash Table (CLHT)数据结构。
另一种常见的方式是通过map分片的方式(fastcache, bigcache, bool64/cache)来降低锁竞争,这种方式基于键将值分散到不同的桶中,在易用性和性能之间做了折衷。
内存管理
内存是一个有限的资源,因此缓存不能无限增长。
过期的元素需要从缓存中淘汰,这个步骤可以同步执行,也可以在后台执行。使用后台回收方式不会阻塞应用本身,且如果将后台回收进程配置为延迟回收的方式时,在需要故障转移时就可以使用过期的数据。
如果上述淘汰过期数据的方式无法满足内存回收的要求,可以考虑使用其他淘汰策略。在选择淘汰策略时需要平衡CPU/内存使用和命中/丢失率。总之,淘汰的目的是为了在可接受的性能预算内优化命中/丢失率,这也是评估一个淘汰策略时需要注意的指标。
下面是常见的选择淘汰策略的原则:
最近最少频率使用(LFU),需要在每次访问时维护计数器
最近最少使用(LRU),需要在每次访问时更新元素的时间戳或顺序
先进先出(FIFO),一旦创建缓存就可以使用缓存中的数据,比较轻量
随机元素,性能最佳,不需要任何排序,但精确性最低
上述给出了如何选项一个淘汰策略,下一个问题是"何时以及应该淘汰多少元素?"。
对于[]byte缓存来说,该问题比较容易解决,因为大多数实现中都精确提供了控制内存的方式。
但对于结构体缓存来说就比较棘手了。在应用执行过程中,很难可靠地确定特定结构体对堆内存的影响,GC可能会获取到这些内存信息,但应用本身则无法获取。下面两种获取结构体内存的指标精确度不高,但可用:
缓存中的元素个数
应用使用的总内存
由于这些指标并不与使用的缓存内存成线性比例,因此不能据此计算需要淘汰的元素。一种比较合适的方式是在触发淘汰时,淘汰一部分元素(如占使用内存10%的元素)。
缓存数据的堆影响很大程度上与映射实现有关。可以从下面的性能测试中看到,相比于二进制序列化(未压缩)的数据,map[string]struct{...}占用的内存是前者的4倍。
基准测试
下面是保存1M小结构体(struct { int, bool, string })的基准测试,验证包括10%的读操作以及0.1%的写操作。字节缓存通过编解码结构体来验证。
goos: darwingoarch: amd64cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzname MB/inuse time/op (10%) time/op (0.1%) sync.Map 192 ± 0% 142ns ± 4% 29.8ns ±10% // Great for read-heavy workloads.shardedMap 196 ± 0% 53.3ns ± 3% 28.4ns ±11% mutexMap 182 ± 0% 226ns ± 3% 207ns ± 1% rwMutexMap 182 ± 0% 233ns ± 2% 67.8ns ± 2% // RWMutex perf degrades with more writes.shardedMapOf 181 ± 0% 50.3ns ± 3% 27.3ns ±13% ristretto 346 ± 0% 167ns ± 8% 54.1ns ± 4% // Failed to keep full working set, ~7-15% of the items are evicted.xsync.Map 380 ± 0% 31.4ns ± 9% 22.0ns ±14% // Fastest, but a bit hungry for memory.patrickmn 184 ± 0% 373ns ± 1% 72.6ns ± 5% bigcache 340 ± 0% 75.8ns ± 8% 72.9ns ± 3% // Byte cache.freecache 333 ± 0% 98.1ns ± 0% 77.8ns ± 2% // Byte cache.fastcache 44.9 ± 0% 60.6ns ± 8% 64.1ns ± 5% // A true champion for memory usage, while having decent performance.如果实际场景支持序列化,那么fastcache可以提供最佳的内存使用(fastcache使用动态申请的方式来分配内存)
对于CPU密集型的应用,可以使用xsync.Map。
从上述测试可以看出,字节缓存并不一定意味着高效地利用内存,如bigcache和freecache。
开发者友好
程序并不会总是按照我们期望的方式允许,复杂的逻辑会导致很多非预期的问题,也很难去定位。不幸的是,缓存使得程序的状况变得更糟,这也是为什么让缓存更友好变得如此重要。
缓存可能成为多种问题的诱发因素,因此应该尽快安全地清理相关缓存。为此,可以考虑对所有缓存的元素进行校验,在高载情况下,失效不一定意味着“删除”,一旦一次性删除所有缓存,数据源可能会因为过载而失败。更优雅的方式是为所有元素设置过期时间,并在后台进行更新,更新过程中使用老数据提供服务。
如果有人正在调查特定的数据源问题,缓存项可能会因为过期而误导用户。可以禁用特定请求的缓存,这样就可以排除缓存带来的不精确性。可以通过特定的请求头以及并在中间件上下文中实现。注意这类控制并不适用于外部用户(会导致DOS攻击)。
“怎么使用Go实现健壮的内存型缓存”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注编程网网站,小编将为大家输出更多高质量的实用文章!











