
1. 背景
项目中要做国产化,MySQL要替换成达梦8数据库。项目中MySQL的建表语句和内置数据通过.sql文件维护,安装时会初始化表结构和表内置数据。项目架构为SpringBoot + JPA / Mybatis。适配工作内容包括数据库迁移、数据导出、项目中的配置更改和相关问题解决方案。
2. 数据处理流程
1. 前期装备
1. 安装达梦8数据库
达梦官网有提供安装包,根据自己的场景进行选择,linux_x86或者linux_aarch64,由于我们项目要全面国产化,所以服务器用的国产华为的鲲鹏服务器(aarch64),操作系统为国产银河麒麟V10。安装步骤按官网提供的文档就行,下载后安装包里也会有一些PDF说明文档可参考。
2. 创建库,启动
安装时如果选择了图形化界面安装,则有DM数据库配置助手工具,可用此工具来创建数据库实例,配置的话中间有个大小写是否敏感配置,此配置默认选择不敏感,否则可能后面会有坑(后面说),安装时记得把客户端也选上,后面用其客户端进行操作,其他配置的话默认就行。安装完成后其中默认用户为SYSDBA,默认端口为5236。
2. 库数据处理
这一步的处理主要是将之前项目中存储的.sql文件中MySQL的表结构和表数据相关sql转换为达梦数据库所支持的sql,并且同样保存为.sql文件,后续项目运行之前直接用sql文件进行建表导数据等初始化操作。大概思想如下:
先把之前sql文件(MySQL)导入到MySQL数据库中
利用达梦的数据迁移工具把MySQL库中的数据迁移到达梦数据库中
利用达梦数据库迁移工具把达梦数据库中的数据导出到sql文件,此时sql文件中的sql语句就可在达梦数据库中执行
1. 数据迁移
如果安装时选择安装了客户端工具,则会生成一些客户端操作工具,如迁移工具、DM管理工具、SQL交互式查询工具等。迁移时选择DM数据迁移工具,按照工具内的步骤,选择MySQL服务和数据库以及要迁移的DM数据库。

新建迁移,按需选择,我这边是MySQL -> DM。
选择数据源迁移时可以指定Mysql数据库的驱动,配置一下jdbc驱动和连接参数即可。达梦的话就是用默认驱动即可。
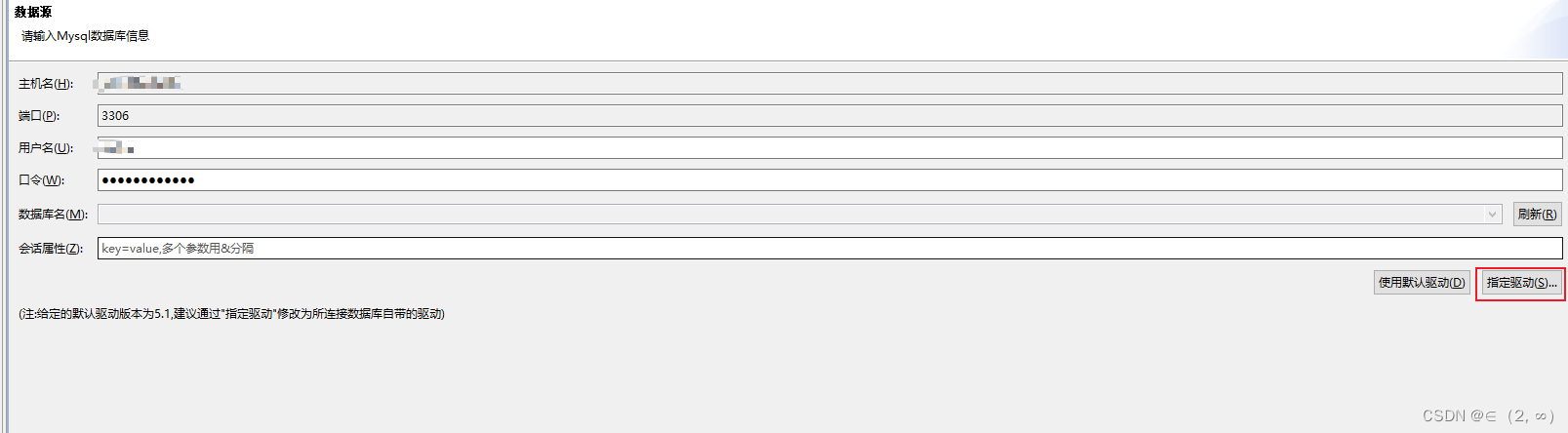
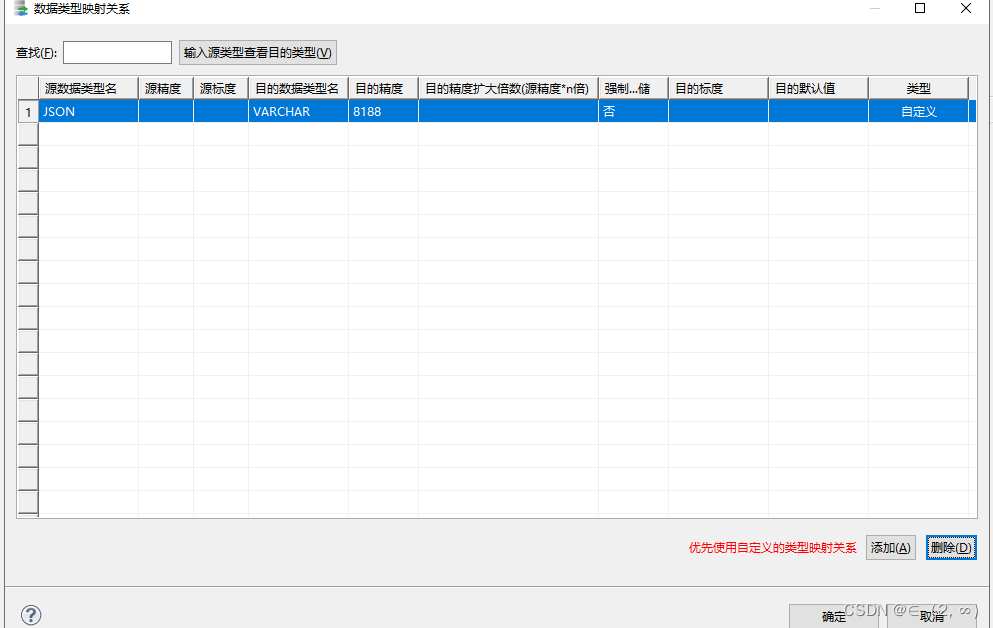
迁移策略,可选择保持对象名大小写,如果MySQL中表字段有用到json类型的字段时,需要手动配置一下类型映射关系,将JSON转成VARCHAR,并设置长度,因为达梦没不支持json类型,迁移时他会默认转成VARCHAR,但是长度会变得很大(具体忘记了),这时某些场景查询时会报错,配置成8188即可,按图配置即可
后面选择迁移模式的话全选即可,没什么需要特殊注意的点
2.数据导出
第三步迁移完成后,此时达梦数据库已经有和MySQL同名的库(dm中是schema概念)和表数据了。接下来要把库中的数据导出为.sql文件,到时候放到项目中安装时用来初始化表及数据。
此时仍然需要用达梦的数据迁移工具,新建数据迁移,选择数据迁移方式为DM -> SQL,然后指定需要迁移的数据源(达梦中的scheme),然后导出到目标文件即可。
3. 项目适配(重点)
1. 库名问题
问题:导出后的达梦sql脚本你会发现,建表语句格式为schema.table,并且主键自增关键字变成了IDENTITY。项目中如果用SYSDBA用户连接或者别的用户连接时,执行sql语句都要加上schema(可以理解为mysql的库名,后续就说库名了),如select * from “MY_DB”.“T_USER_TEST”,如不加库名则会报错,当然不可能把项目中所有的sql都改一遍
-- mysqlCREATE TABLE `T_USER_TEST`( "id" BIGINT NOT NULL AUTO_INCREMENT,//主键自增 "name" VARCHAR(255) NULL);-- 达梦CREATE TABLE "MY_DB"."T_USER_TEST"( "id" BIGINT IDENTITY(1,2) NOT NULL,//主键自增 "name" VARCHAR(255) NULL);解决方案:创建一个用户,用户名为库名,创建用户后达梦会自动创建一个和用户名相同的库,此时用此用户登录连接,执行sql语句时表名前面就不需要加库名了,因为他默认查的就是此用户下的库。语句如下(包括创建表空间、赋权等),后续连接时使用此账号和密码以及url连接中的schema(MY_DB)
-- 创建表空间MY_DBCREATE tablespace MY_DB DATAFILE 'MY_DB.DBF' SIZE 128;-- 创建用户MY_DB,密码为123456,此时会自动创建名为MY_DB的schemaCREATE USER "MY_DB" IDENTIFIED BY "123456" DEFAULT tablespace MY_DB;-- 为MY_DB用户赋权grant "DBA","RESOURCE","PUBLIC","SOI" to "MY_DB" with admin option;grant EXECUTE on "SYS"."DBMS_XMLGEN" to "MY_DB";Spring数据库连接配置参考:
#dm8连接spring.datasource.url=jdbc:dm://127.0.0.1:5236/MY_DBspring.datasource.username=MY_DBspring.datasource.password=123456spring.datasource.driver-class-name=dm.jdbc.driver.DmDriverspring.datasource.type=com.alibaba.druid.pool.DruidDataSource#如果项目中有使用到JPA,参考如下方言配置spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.DmDialectspring.jpa.properties.hibernate.hbn2ddl.auto=nonespring.jpa.properties.hibernate.temp.use_jdbc_metadata_defaults=false2. 主键自增问题
1. 问题剖析
首先,达梦数据库是支持主键自增的,DDL中自增关键字为IDENTITY,假如我们表中的id字段设置的为自增id,insert语法常见如下三种:
-- 如下建表语句,id为自增idCREATE TABLE "MY_DB"."t_user_test"( "id" BIGINT IDENTITY(1,2) NOT NULL,//主键自增 "name" VARCHAR(255) NULL);-- 1.insert的正确姿势,此时会生成则增idinsert into "t_user_test"(name) values("tom");-- 2.错误示范,此时会报错:仅当指定列列表,且SET IDENTITY_INSERT为ON时,才能对自增列赋值insert into "t_user_test"(id,name) values(1,"tom");-- 3.错误示范,此时会报错: 仅当指定列列表,且SET IDENTITY_INSERT为ON时,才能对自增列赋值或者违反列[id]非空约束insert into "t_user_test"(id,name) values(null,"tom");第一种插入没问题,无可厚非
第二种插入会报错,意思就是说,你的id设置的为自增列,但是你插入时对自增列手动赋值,这是不允许的,设置了自增就应该用数据库的自增生成。但是项目中难免有手动设置id插入的场景,此时也是有解决方案的,就是在插入之前设置IDENTITY_INSERT为ON。注意IDENTITY_INSERT关键字是表级别的关键字,语法要指定到表,不能对全库进行设置。
-- 设置t_user_test表SET IDENTITY_INSERT MY_DB.t_user_test ONinsert into("id","name") values(1,"tom");-- OFF可以不执行,不影响SET IDENTITY_INSERT MY_DB.t_user_test OFF针对IDENTITY_INSERT问题,本人做了一些测试,得出以下结论供参考:
-
如需要使用数据库主键自增特性,需要在主键列上声明IDENTITY
-
当insert语句时,如果手动设置id值,则需要设置此表的IDENTITY_INSERT为 ON
-
执行完不关闭(SET IDENTITY_INSERT MY_DB.t_user_test OFF),再次插入id为空的值还是可以自增的
-
不同会话之间执行SET IDENTITY_INSERT MY操作不会互相影响
-
同一会话同一时刻只能有一张表IDENTITY_INSERT 设置为ON,后面会覆盖前面的,同一会话多次设置只有最后一次设置生效
-
当insert语句中,如果id显示插入,并且value为null,则会报非空约束的问题
开启语句:SET IDENTITY_INSERT db.table ON
关闭语句:SET IDENTITY_INSERT db.table OFF
第三种插入报错很明显,当你没有设置IDENTITY_INSERT时,他会先报错让你对其设置为ON,如果设置完后就会报错违反id非空约束,因为id建表时为主键,自带非空约束。不能显示插入null值,此种错误只能对sql进行处理,后面会讲。
2. 问题处理
经过以上问题分析,insert某张表时,可以先设置IDENTITY_INSERT为ON,虽然只有第一种insert不需要设置,可以直接走自增,但是你设置后也不会影响insert的执行,为了偷懒不想整理项目中的sql,索性所有insert都设置IDENTITY_INSERT为ON。当然你可以写sql,修改项目中的代码,在所有insert操作之前都执行一遍INDENTITY_INSERT ON,但是代码中持久层框架用了JPA和Mybatis,并且此类sql很多,所以采用AOP的方式解决。
解决思路:在我们项目中使用JPA保存对象实现插入都是间接调用JpaRepository.save()方法,所以在此方法加一层拦截处理就行了,执行save之前先执行SET IDENTITY_INSERT ON,参考代码如下:
@Aspect@Componentpublic class JpaSaveAspect { public static final String IDENTITY_INSERT_ON = "SET IDENTITY_INSERT MY_DB.%s ON"; public static final String IDENTITY_INSERT_OFF = "SET IDENTITY_INSERT MY_DB.%s OFF"; @Autowired private JdbcTemplate jdbcTemplate; // 节点为JpaRepository.save @Pointcut("execution(* org.springframework.data.jpa.repository.JpaRepository.save(..))") public void savePointcut() { } //执行切点方法之前要进行的处理 @Before("savePointcut()") public void beforeSave(JoinPoint joinPoint) { Object[] args = joinPoint.getArgs(); if (Objects.isNull(args) || args.length != 1) { return; } Object obj = args[0]; Class<?> clazz = obj.getClass(); Annotation[] annotations = clazz.getAnnotations(); Long id = null; try { //通过反射获取save的实体对象,并通过getId方法获取里面的id值,也就是主键值 Method method = clazz.getMethod("getId"); id = (Long) method.invoke(obj); } catch (Exception e) { } // 当id(主键)为空时,不需要处理,因为此时走的数据库的自增 if (Objects.isNull(id) || id <= 0){ return; } for (Annotation annotation : annotations) { // 获取JPA实体的@Tabel注解,解析出表名 if (annotation instanceof Table) { Table tableAnnotation = (Table) annotation; //表名拼接进sql进行执行,SET IDENTITY_INSERT MY_DB.t_user ON String identityInsertOn = String.format(IDENTITY_INSERT_ON, tableAnnotation.name()); log.warn("JPA IDENTITY_INSERT_ON:{}", identityInsertOn); jdbcTemplate.execute(identityInsertOn); } } }}解决思路:Mybatis提供的有自己的拦截器,也叫插件,只需要自定义拦截器即可,使用方式是实现org.apache.ibatis.plugin.Interceptor接口并注册为Bean,并在Mybatis的SqlSessionFactory设置此拦截器使其生效。对这块不熟的可以网上看看相关资料。接下来拦截器中就可以拦截sql并在sql执行之前做处理了。参考代码如下:
代码处理的问题:
处理非法字符,如删掉sql中的`字符
处理boolean参数,达梦的bit类型对应java中的boolean类型,把sql中的true和false关键字替换为1和0
处理主键自增
在执行insert之前执行SET IDENTITY_INSERT,由于本人对Mybatis不太熟,没在拦截器中找到sqlSersion对象,也就没法通过sqlSersion来执行我自定义的sql。而通过调用jdbcTemplate等三方执行,可能导致两个sql不在一个会话中执行,也就导致可能你执行的SET IDENTITY_INSERT不在此会话生效(看上面IDENTITY_INSERT的测试结果),此时你可以通过在insert 语句所在的方法加事务尝试解决。目前我是通过拼接sql方式解决,在拦截器中把解析出来的sql前面拼接自定义sql。(会话的问题和事务我也只是猜测,并没实际验证,仅供参考)
@Intercepts({ @Signature(type = StatementHandler.class, method = "prepare", args = {Connection.class, Integer.class})})@Slf4j@Componentpublic class MybatisSqlInterceptor implements Interceptor { private static final String SQL_TRUE_PARAM_REG = "(?i)=\\s*true"; private static final String SQL_FALSE_PARAM_REG = "(?i)=\\s*false"; private static final String SQL_INSERT_REG = "(?i)(insert into|merge into)\\s+([^\\s]+)"; private static final String IDENTITY_INSERT_ON = "SET IDENTITY_INSERT MY_DB.%s ON;"; private Set<String> identityInsertExcludeTableSet;//配置,可配置库中无自增键的表,把它过滤掉,因为这些表没有主键自增问题 @Value("${mybatis.insert.exclude.table:t_no_identity_table_test}") private String excludeTable; @PostConstruct public void initExcludeTableSet() { //加载时将excludeTable的表放入HaseSet,提升后续匹配效率 identityInsertExcludeTableSet = Arrays.stream(excludeTable.split(",")) .collect(Collectors.toSet()); } @Override public Object intercept(Invocation invocation) throws Exception { StatementHandler statementHandler = (StatementHandler) invocation.getTarget(); MetaObject metaObject = SystemMetaObject.forObject(statementHandler); MappedStatement mappedStatement = (MappedStatement) metaObject.getValue("delegate.mappedStatement"); SqlCommandType sqlCommandType = mappedStatement.getSqlCommandType(); BoundSql boundSql = statementHandler.getBoundSql(); String sql = this.handleIllegalChar(boundSql.getSql()); if (sqlCommandType == SqlCommandType.SELECT) { sql = this.handleBooleanParam(sql); } if (sqlCommandType == SqlCommandType.INSERT) { sql = this.handleIdentityInsertOn(sql); } metaObject.setValue("delegate.boundSql.sql", sql); return invocation.proceed(); } private String handleIllegalChar(String sql) { return sql.replace("`", ""); } private String handleIdentityInsertOn(String sql) { String tableName = null; Pattern pattern = Pattern.compile(SQL_INSERT_REG, Pattern.CASE_INSENSITIVE); Matcher matcher = pattern.matcher(sql); if (matcher.find()) { tableName = matcher.group(2); } if (StringUtils.isNotBlank(tableName) && !identityInsertExcludeTableSet.contains(tableName)) { String identityInsertOn = String.format(IDENTITY_INSERT_ON, tableName); log.warn("Mybatis IDENTITY_INSERT_ON:{}", identityInsertOn); sql = identityInsertOn + sql; } return sql; } private String handleBooleanParam(String sql) { return sql.replaceAll(SQL_TRUE_PARAM_REG, "= 1") .replaceAll(SQL_FALSE_PARAM_REG, "= 0"); }}3. SQL语法相关问题
安装时能要求大小写不敏感尽量选择大小写不敏感,不然建表时字段都要用大写,如果用小写,查询时字段用小写查可能会报错:无效列名等
1. 字段column
字段名称关键字冲突
数据库中都有一些自己的关键字,如果建的表中有些关键字和数据库中的冲突,就有可能执行某些sql报错,此类冲突的关键字尽量手动改掉,以下是我遇到的关键字供参考:
logic、comment、domain
字段类型
1)mysql中的json类型对应dm8中的varchar类型,但尽量指定大小,不然聚合查询可能报错
2)bit类型Mysql可使用true和false进行查询,dm只能使用0和1查询
2. 函数及语法
GROUP_CONCAT语法要换成WM_CONCAT(其它函数可自行百度,资料很多,也可参考oracle语法)
如果用到group by,则select的列必须都是分组内的,报错参考:不是 GROUP BY 表达式。
可根据场景看看是否能删除group by替换为select DISTINCT xxx等
select DISTINCT对字段去重时,去重字段中不能有blob或者clob,如text类型的字段,也就是不能把text 类型的字段放到DISTINCT后面,报错参考:试图在blob或者clob列上排序或比较
如果使用到mysql的on duplicate key,在达梦8中可以用MERGE INTO语法进行替换(mybatis中批量插 入更新)。
if语句,达梦支持if语句,但只能支持简单的场景,如下
-- 支持where if(id>1,2,3)-- 不支持where if(1 = 1,status = 2 or status =3 ,1=1) 以上不支持的场景可以用逻辑解决:
where ((1 = 1 AND (status = 2 OR status = 3)) OR (1 = 1))4. 其它问题
我们项目中用到了clickhouse数据库,并且使用了clickhouse的字典表连接了外部数据库,也就是Mysql中的某些表,作用是可以吧mysql某些表里的某些数据同步到clickhouse映射表中,并且建立好映射表后,后期clickhouse中表的数据可自动同步mysql表中的数据,如不了解的可去ck官网查看 https://clickhouse.com/docs/zh/sql-reference/dictionaries/external-dictionaries/external-dicts-dict-sources#dicts-external_dicts_dict_sources-mysql
问题:clickhouse内置支持mysql的字典表,但不支持达梦8,
解决:clickhouse提供了bridge方式,如clickhouse-jdbc-bridge、clickhouse-odbc-bridge,大概意思就是提供了个中间件,它是以独立进程来启动,他来作为ck和外部数据库的桥接来自动同步数据。
1. ODBC
环境依赖:unixODBC + 达梦8的odbc驱动
其中unixODBC可根据操作系统下载rpm包或者下载源码进行编译(网上有教程)
odbc驱动可以从安装达梦8所在的服务器上找,安装目录下有个drivers文件,里面有各种驱动,包括odbc,把驱动文件(.so)以及相关依赖拷贝到ck服务器,然后在unixODBC的配置文件中添加dm的数据源和驱动配置路径,然后再ck中创建字典表,并且指定达梦数据源。
这种方式本人在x86机器验证过,是可行的,但是unixODBC有版本问题,达梦8odbc驱动是.so文件链接库,同时有依赖其他链接库,操作不好就会有链接缺失的问题。本人就是后面x86验证后,拿到aarch64架构机器去验证时,依赖的加解密so库和系统中内置的冲突了,但是又没找到法子对其进行环境隔离,故后面放弃了。
2.JDBC
实际中本人是采用这种方式,开始没采用是因为当时看到了jdbc-bridge,但还是想找一种字典表的方式,想着看看字典表支不支持配置自定义连接数据源,就越走越远,后面又用了ODBC开始踩坑,一直踩到国产环境编译动态库后冲突问题,作为java程序员已经走不动了,就蓦然回首从0开始踩坑jdbc,中间jdbc还有一些踩坑历程就不说了,下面直接说结论吧。
clickhouse-jdbc-bridge源码地址:https://github.com/ClickHouse/clickhouse-jdbc-bridge
源码地址有说明,因为是采用java代码编写的,所以没有跨平台的问题,直接下载rpm包安装即可:
wget https://github.com/ClickHouse/clickhouse-jdbc-bridge/releases/download/v2.1.0/clickhouse-jdbc-bridge-2.1.0-1.noarch.rpmrpm -ivh clickhouse-jdbc-bridge-2.1.0-1.noarch.rpm安装后需要把达梦8的jdbc驱动放入某个文件,后面配置要指定此驱动
在jdbc-bridge的安装目录(默认为/etc/clickhouse-jdbc-bridge/config/datasources),新建.json文件,里面配置你的数据库相关连接(驱动、url、账号、密码等信息)
运行启动clickhouse-jdbc-bridge(默认端口9019)
配置clickhouse的config.xml文件,配置jdbc-bridge连接,重启clickhouse服务
<jdbc_bridge> <host>127.0.0.1host> <port>9019port>jdbc_bridge>在clickhouse客户端执行建表语句,示例如下,其中dm8参数是clickhouse-jdbc-bridge数据源配置的名称,DM_DB是达梦数据库的schema名,后面是将查询的结果放入ck表,这个位置也可以直接写表名。
CREATE TABLE ck_user_test ( id UInt64, name String )ENGINE = JDBC('dm8', 'DM_DB', 'select id,name from t_dm_user_test WHERE xxx=0')建表成功后再ck中就可以查询ck_user_test这张表了,数据同步周期可配置,具体其他配置可参考官网或自行百度
来源地址:https://blog.csdn.net/qq_44898256/article/details/131834436







