
这里写目录标题
一级目录
二级目录
三级目录
1、文件IO的常见操作
| 方法 | |
|---|---|
| open | 打开 |
| read | 读取 |
| write | 写入 |
| close | 关闭 |
| readline | 行读取 |
| readlines | 多行读取 |
| seek | 文件指针操作 |
| tell | 指针位置 |
2、打开操作Open
打开一个文件,返回一个文件对象(流对象)和文件描述符,打开文件失败,返回异常
open(file,mode=“r”,buffering=-1,encoding=None,errors=None,newline=None,closefd=True,opener=None)
2.1 file 文件名
打开或者要创建的文件名,如果不指定,默认当前路径
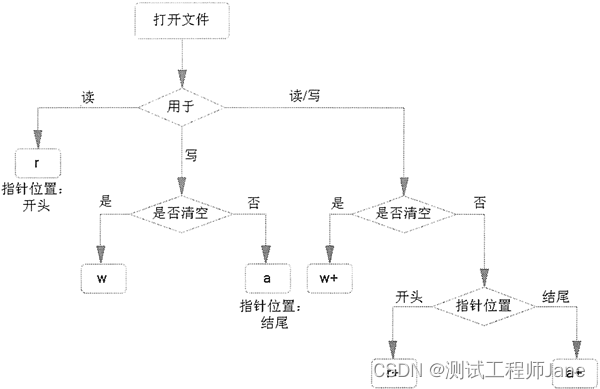
2.2 mode 模式
| 模式 | 功能 | 备注 |
|---|---|---|
| r | 缺省值,只读打开文件,指针位于文件头 | 前提:文件已创建 |
| w | 只写模式打开文件,或文件存在,会清空原有内容,即覆盖写 | 1.文件存在:清空文件。 2.文件不存在,创建新文件 |
| a | 追加,只写 | 1.文件存在:清空文件。 2.文件不存在,创建新文件 |
| x | 创建并写入一个新文件 | 注意:如果该文件已存在则会报错 |
| + | 为r、w、a、x 提供缺失的读写功能 | 前提:文件不存在 |
| b | 二进制模式,字节流 | 前提:文件不存在 |
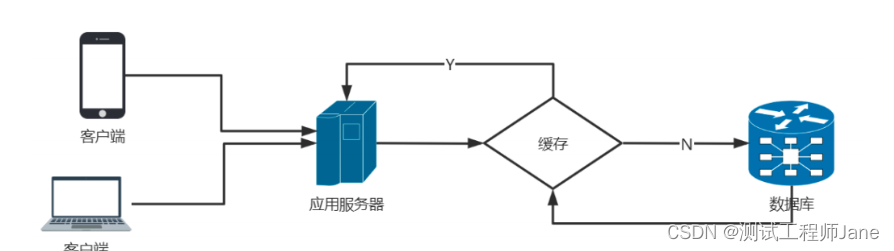
借用网上大神图示一张:
示例:
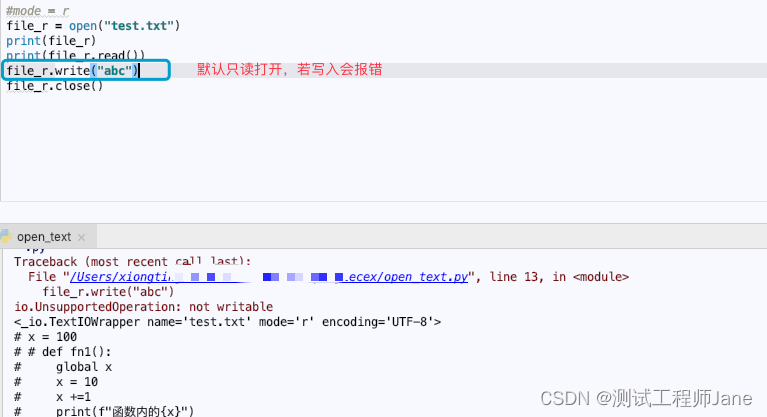
2.2.1. R模式:mode = “r”
#mode = r,文件要存在file_r = open("test.txt")print(file_r)print(file_r.read())file_r.write("abc")file_r.close()运行结果:
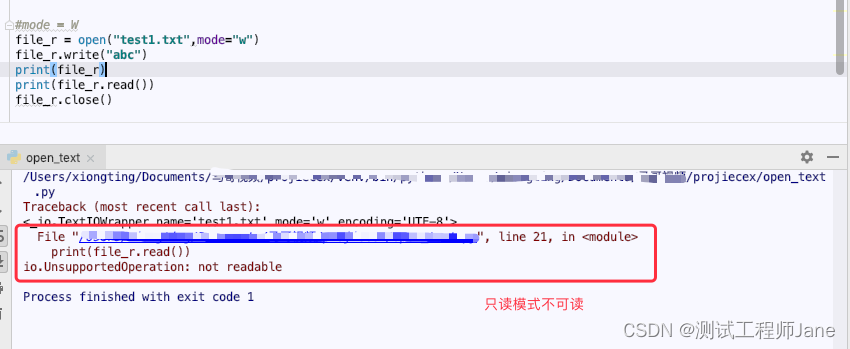
2.2.2. W模式:mode = “w”
#mode = Wfile_r = open("test1.txt",mode="w")file_r.write("abc")print(file_r)print(file_r.read())file_r.close()运行结果:
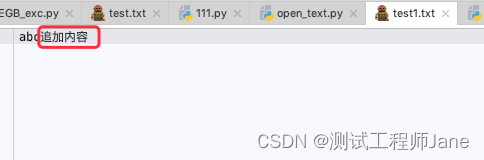
2.2.3. a模式:mode = “a”
#mode = afile_a = open("test1.txt",mode="a")file_a.write("追加内容")file_a.close()运行结果:
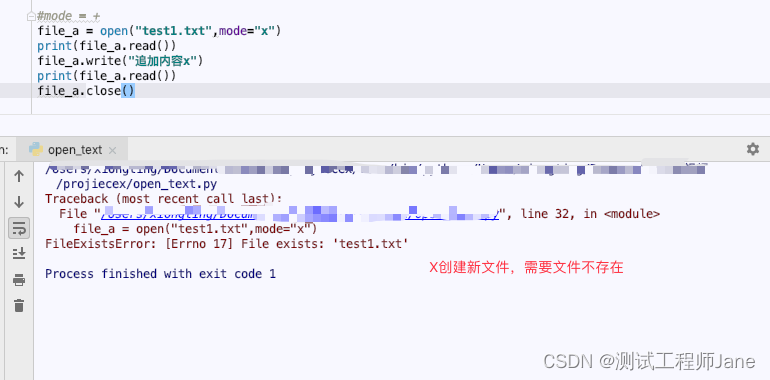
2.2.4. a模式:mode = “x”
file_a = open("test2.txt",mode="x")file_a.write("追加内容x")file_a.close()运行结果:

2.2.5. “+”模式,mode=“+”
#mode = +file_xx = open("test.txt",mode="r+")file_xx.write("test追加内容") #使用+后,原本r只读的模式,也可写入内容print(file_xx.read())file_xx.close()
2.3 encoding: 编码,仅文本模式使用
None表示使用缺省编码,Windows缺省:GBK,Linux缺省使用UTF-8
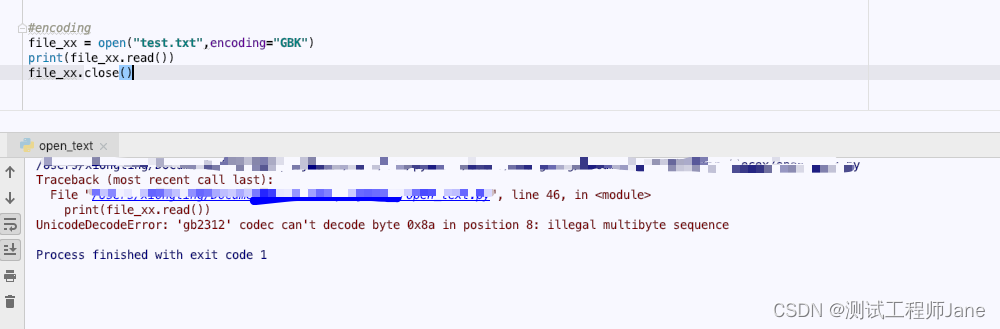
文件打开时如果报错:UnicodeDecodeError,刚使用此参数对文件进行编码读取,我们看下报错情况
#encodingfile_xx = open("test.txt",encoding="GBK")print(file_xx.read())file_xx.close()运行结果:
2.4 buffering: 缓冲区
2.4.1. 缓冲buffer与缓存Cache的区别
缓冲(Buffer):
- 常见于对数据的暂存,然后批量传输或者写入, 多使用顺序的方式,用来缓解不同设备之间频繁地、缓慢地随机写。
- 缓冲的作用就是协调上下层应用之间的性能差异,可以有效减少上层组件对下层组件的等待时间,可提升整个系统的性能
- 可以把它理解为一个蓄水池,达到一定的容量就全部释放,缓冲区的数据释放到磁盘
缓存(Cache):
常见于对已读数据的复用,通过将它们缓存在相对高速的区域,缓存主要针对的是读操作。
2.4.1. Buffering取值说明
| 取值 | 二进制 | 文本 |
|---|---|---|
| buffering=-1 | io.DEFAULT_BUFFER_SIZE(4096或8192) | io.DEFAULT_BUFFER_SIZE |
| buffering=0 | 禁止缓存,关闭缓冲区 | 不支持 |
| buffering=1 | 1 | line buffering(行缓存),遇到换行符才flush |
| buffering > 1 | buffering自设置值 | io.DEFAULT_BUFFER_SIZE |
示例:
在这里插入代码片3、seek()文件指针操作
fileObject.seek(offset[, whence])
注:
- ffset – 开始的偏移量,也就是代表需要移动偏移的字节数
- whence:可选,默认值为 0。给offset参数一个定义,表示要从哪个位置开始偏移;
0代表从文件开头开始算起,
1代表从当前位置开始算起,
2代表从文件末尾算起。
注意:
文本模式支持向后偏移,但1,2偏移量只支持0,所以没什么作用
二进制模式支持任意偏移,向后seek可以超界,向前seek不可超界,否则异常
示例:
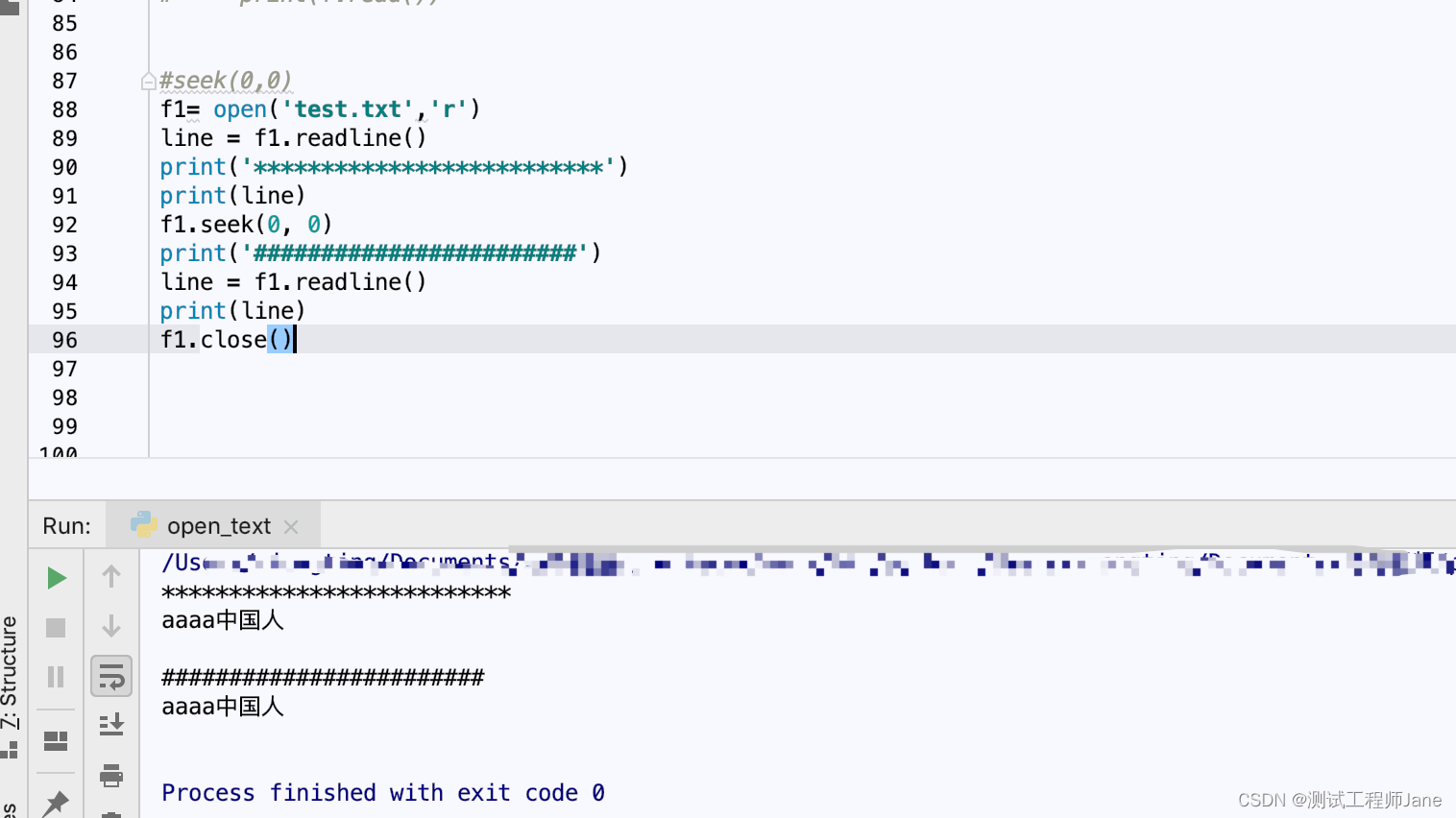
#seek(0,0)f1= open('test.txt','r')line = f1.readline()print('**************************')print(line)f1.seek(0, 0)print('########################')line = f1.readline()print(line)f1.close()运行结果:
2.seek(x,1)//从当前位置偏移x位 x 可为正负零,
f1= open('test.txt','rb')line = f1.readline()print('**************************')print(line)f1.seek(2, 1)print('########################')line = f1.readline()print(line)4、readline/readlines
- readline(size=-1):一行一行读取,size设置一次能读取行内几个字符或字节
- readlines(hint=-1):读取所有行的列表,指定hint则返回指定的行数
示例:
#readlinesf = open("test.txt")for line in f.readlines(): print(line)f.close()# #readlinef = open("test.txt")print(f.readline())print(f.readline())print(f.readline())f.close()5、with…as 上下文
写入文件时,如果忘记close或者文件使用过程中发生异常,则文件将不会正常关闭,占用系统资源,Python提供了with…as上下方管理来处理这种情况
内部处理逻辑:
def __enter__(self): return selfdef __exit__(self, type, value, traceback): self.close()示例:
with open("test.txt") as f: print(f.read())6、open总结
一个文件打开之后,会产生一个文件对象,这个文件可为:只读,只写,读写。可被seek,即文件指针来回动,seek要看模式,允许从前向后走。文件有buffer,建议默认Buffer。文件换行符可控制。文件描述符占用资源,close会自动释放掉
来源地址:https://blog.csdn.net/totorobig/article/details/127430672









