
什么是数据库与缓存一致性
- 数据一致性指的是:缓存的数据值 = 数据库中的值
为什么会出现数据一致性问题呢?
- 在高并发的业务场景下,数据库大多数情况都是用户并发访问最薄弱的环节。
- 所以,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问MySQL等数据库。
- 读取缓存步骤一般没有什么问题,但是一旦涉及到数据更新:数据库和缓存更新,就容易出现缓存(Redis)和数据库(MySQL)间的数据一致性问题。
解决数据一致性问题的常见方案
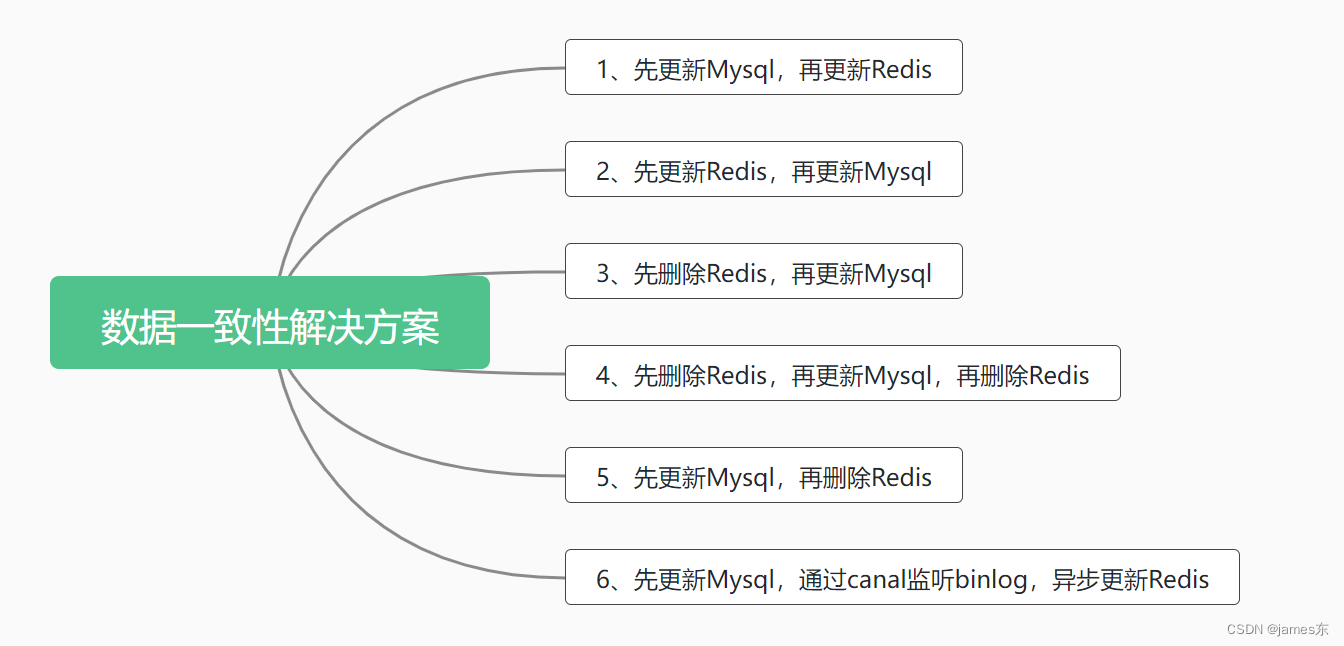
下面详细介绍
1. 先更新Mysql,再更新Redis
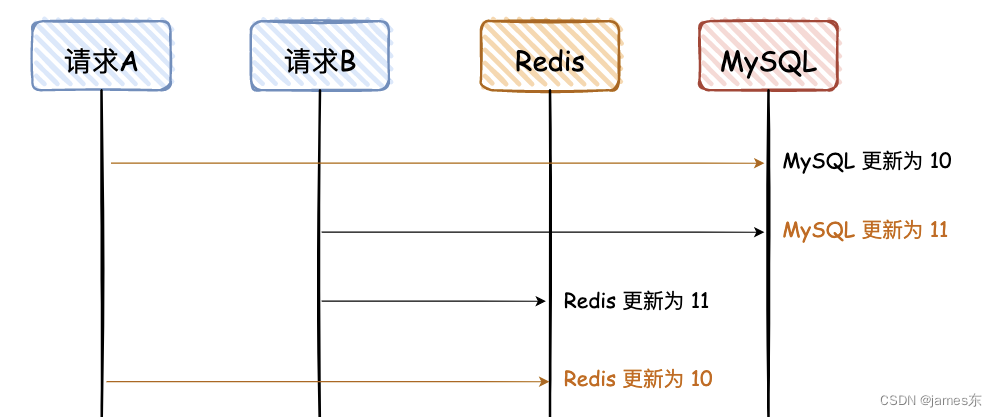
图解说明:
- 这是一副时序图,描述请求的先后调用顺序;
- 橘黄色的线是请求 A,黑色的线是请求 B;
- 橘黄色的文字,是 MySQL 和 Redis 最终不一致的数据;
- 数据是从 10 更新为 11,但是Redis中的数据还是10;
- 后面所有的图,都是这个含义,不再赘述。
请求 A、B 都是先写 MySQL,然后再写 Redis,在高并发情况下,如果请求 A 在写 Redis 时卡了一会,请求 B 已经依次完成数据的更新,就会出现图中的问题。
2. 先更新Redis,再更新Mysql
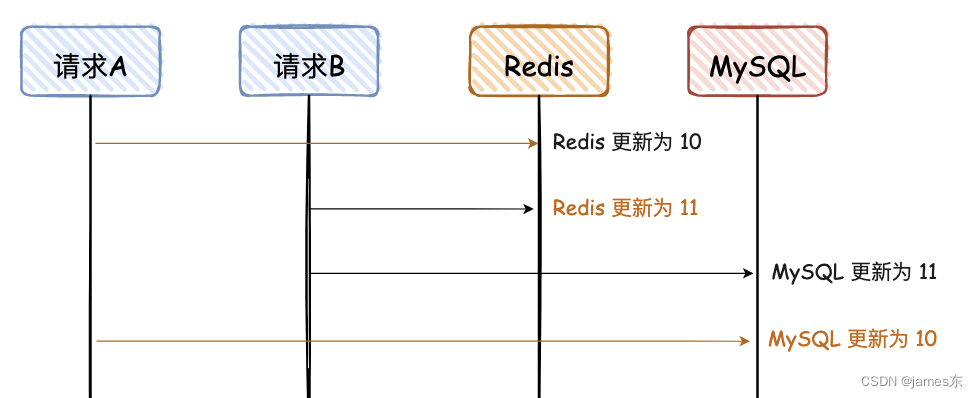
同“先写 MySQL,再写 Redis”,看图可秒懂。
3. 先删除Redis,再更新Mysql
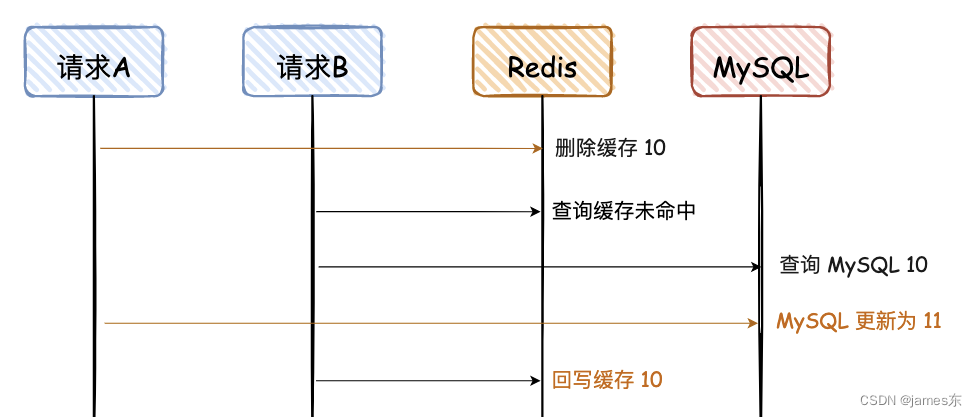
请求 A 先删除缓存,可能因为卡顿,数据一直没有更新到 MySQL,导致两者数据不一致。这种情况出现的概率比较大,因为请求 A 更新 MySQL 可能耗时会比较长,而请求 B 的前两步都是查询,会非常快。
4. 先删除Redis,再更新Mysql,再删Redis
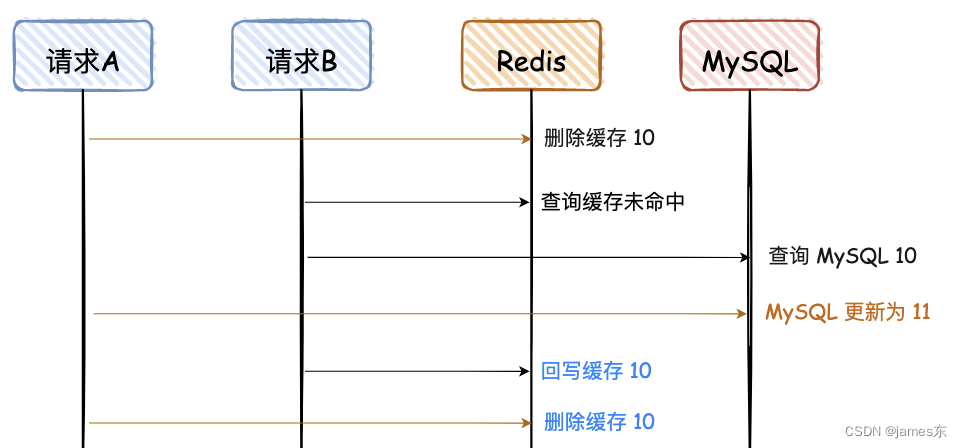
对于“先删除 Redis,再写 MySQL”,如果要解决最后的不一致问题,其实再对 Redis 重新删除即可,这个也是大家常说的“延迟双删”,不过最后一次删除Redis的时间需要评估业务逻辑执行的时间,即需要等请求B执行完毕再删除。
5. 先更新Mysql,再删Redis
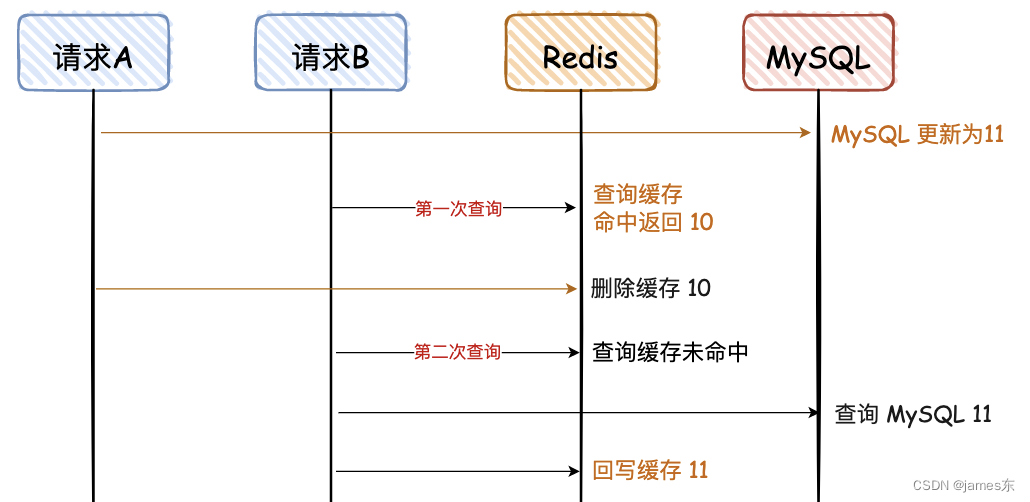
对于上面这种情况,对于第一次查询,请求 B 查询的数据是 10,但是 MySQL 的数据是 11,只存在这一次不一致的情况,对于不是强一致性要求的业务,可以容忍。(那什么情况下不能容忍呢,比如秒杀业务、库存服务等。)
6. 先更新 MySQL,通过 Binlog,异步更新 Redis
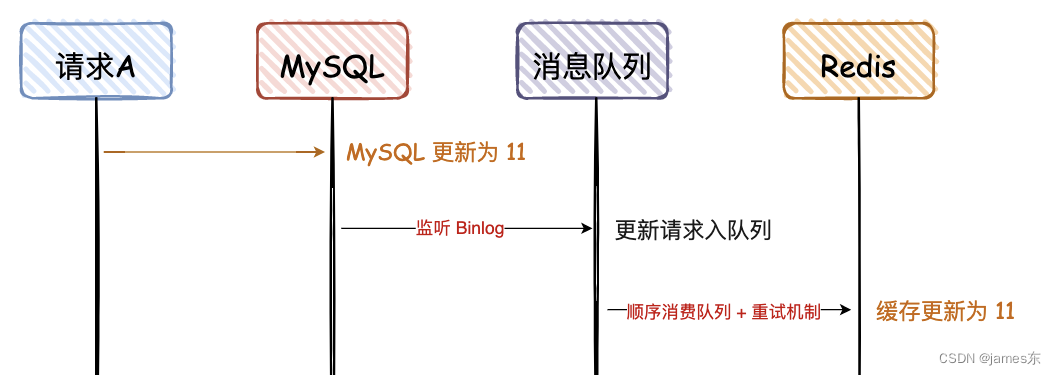
这种方案,主要是监听 MySQL 的 Binlog,然后通过异步的方式,将数据更新到 Redis,这种方案有个前提,查询的请求,不会回写 Redis,这个方案,是实现最终一致性的终极解决方案,但是不能保证实时性。
几种方案比较
-
先更新 Redis,再更新 MySQL
- 万一 DB 挂了,你把数据写到缓存,DB 无数据,这个是灾难性的;
-
先更新 MySQL,再更新 Redis
- 对于并发量、一致性要求不高的项目,很多就是这么用的,我之前也经常这么搞,但是不建议这么做;
- 当 Redis 瞬间不可用的情况,需要报警出来,然后线下处理。
-
先删除 Redis,再更新 MySQL
- 高并发场景由于更新mysql使用时间较长就会产生数据不一致。
-
先删除 Redis,再更新 MySQL,再删除 Redis
- “延迟双删” 这种方式虽然可行,但是需要去评估业务逻辑的执行时间
-
先更新MySQL,再删除 Redis
- 比较推荐这种方式,删除 Redis 如果失败,可以再多重试几次,否则报警出来;
- 这个方案,是实时性中最好的方案,在一些高并发场景中,推荐这种。
-
先更新 MySQL,通过canal监听 Binlog,异步更新 Redis
- 对于异地容灾、数据汇总等,建议会用这种方式,比如 binlog + kafka,数据的一致性也可以达到秒级;
个人结论
- 实时一致性方案:采用“先写 MySQL,再删除 Redis”的策略,这种情况虽然也会存在两者不一致,但是需要满足的条件有点苛刻,所以是满足实时性条件下,能尽量满足一致性的最优解。
- 最终一致性方案:采用“先写 MySQL,通过 Binlog,异步更新 Redis”,可以通过 Binlog,结合消息队列异步更新 Redis,是最终一致性的最优解。
来源地址:https://blog.csdn.net/qq_40782372/article/details/129115718













