

西北望乡何处是,东南见月几回圆。
月亮又慢悠悠的挂上了天空,趁着睡前梦呓,我就带领各位可爱的读者们探索MySql最后的子查询部分。
说明:有些查询结果出来结果截图与题目要求不一样会出现多余的字段是为了方便展示结果的可读性。实际操作的读者可以删除SELECT后面多余的字段得到正确的结果。
#WHERE或HAVING后面
#1.标量子查询(单行子查询)
#2.列子查询(多行子查询)
#3.行子查询(多列多行)
#特点:
# ①子查询放在小括号内
# ②子查询一般放在条件的右侧
# ③标量子查询:一般搭配着单行操作符使用
# 单行操作符: > < >= <= <> !-
# 列子查询,一般搭配着多行操作符使用
# IN,ANY/SOME(任意),ALL
# ④子查询的执行优先与主查询执行,主查询的条件用到了子查询的结果。#1.标量子查询
#案例1:谁的工资比Abel高?
#①查询Abel的工资
SELECT salary
FROM employees
WHERE last_name = "Abel";
#②查询员工的信息,满足Salary>①结果
SELECT *
FROM employees
WHERE salary>(SELECT salary FROM employees WHERE last_name="Abel");
#案例2.返回job_id与141号员工相同,salary比143号员工多的员工姓名,job_id,工资。
#①查141员工的job_id
SELECT job_id
FROM employees
WHERE employee_id="141";
#②查143员工的salary
SELECT salary
FROM employees
WHERE employee_id="143";
#③最后合并结果
SELECT CONCAT(last_name,first_name) AS 姓名,
job_id AS 工种编号,
salary AS 工资
FROM employees
WHERE job_id=(
SELECT job_id
FROM employees
WHERE employee_id="141"
)
AND salary>(
SELECT salary
FROM employees
WHERE employee_id="143"
); 
#案例3.返回公司工资最少的员工的last_name,job_id和salary。
SELECT MIN(salary)
FROM employees;
SELECT
last_name AS 姓,
salary AS 工资,
job_id AS 工种编号
FROM employees
WHERE salary=(
SELECT MIN(salary)
FROM employees
);
#案例4.查询最低工资大于50号部门最低工资的部门id和其最低工资。
#①查50部门的最低工资
SELECT MIN(salary)
FROM employees
WHERE department_id=50;
#分组后,筛选条件①.【不用排除没有部门的所以不筛选部门编号】
SELECT department_id AS 部门编号,
MIN(salary) AS 月薪
FROM employees
#WHERE department_id
GROUP BY department_id
HAVING 月薪>(
SELECT MIN(salary)
FROM employees
);
#2.列子查询(多行子查询)
#返回多行
#使用多行比较操作符
#案例1.返回location_id是1400或1700的部门中的所有员工姓名。
#①查询location_id是1400或1700的部门编号
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN(1400,1700);
#②查询员工姓名,要求部门号是①列表的某一个
SELECT CONCAT(last_name,first_name) AS 姓名
FROM employees
WHERE department_id IN (
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN(1400,1700)
);
用ANY替代IN与上面同样的结果
SELECT CONCAT(last_name,first_name) AS 姓名
FROM employees
WHERE department_id = ANY(
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN(1400,1700)
);#案例.返回location_id不是1400或1700的部门中的所有员工姓名。
SELECT CONCAT(last_name,first_name) AS 姓名
FROM employees
WHERE department_id NOT IN(
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN(1400,1700)
);
==============================
SELECT CONCAT(last_name,first_name) AS 姓名
FROM employees
WHERE department_id <> ALL(
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN(1400,1700)
);
#案例2.返回其他工种中比job_id为IT_PROG部门任意一工资低的员工工号,
# 姓名,job_id以及salary
#①把IT_PROG部门中的工资查出来
SELECT DISTINCT salary
FROM employees
WHERE job_id="IT_PROG";
#②把不是IT_PROG部门信息查出来
SELECT *
FROM employees
WHERE job_id != "IT_PROG";
#③合并①与②在员工表中查出来
SELECT employee_id AS 员工编号,
CONCAT(last_name,first_name) AS 姓名,
job_id AS 工种编号,
salary AS 工资
FROM employees
WHERE job_id != "IT_PROG"
AND salary
用MAX代替ANY与上面同样的效果
SELECT employee_id AS 员工编号,
CONCAT(last_name,first_name) AS 姓名,
job_id AS 工种编号,
salary AS 工资
FROM employees
WHERE job_id <> "IT_PROG"
AND salary<(
SELECT MAX(salary)
FROM employees
WHERE job_id="IT_PROG"
);#案例3.返回其他部门中比job_id为‘IT_PROG’部门所有工资都低的员工
#的员工号,姓名,job_id以及salary。
#①先把IT_PROG部门的工资查出来。
SELECT DISTINCT salary
FROM employees
WHERE job_id="IT_PROG";
SELECT employee_id AS 员工号,
CONCAT(last_name,first_name) AS 姓名,
job_id AS 工种编号,
salary AS 工资
FROM employees
WHERE salary "IT_PROG";
=============================
MIN替代ALL
SELECT employee_id AS 员工号,
CONCAT(last_name,first_name) AS 姓名,
job_id AS 工种编号,
salary AS 工资
FROM employees
WHERE salary<(
SELECT MIN(salary)
FROM employees
WHERE job_id="IT_PROG"
)
AND job_id <> "IT_PROG";
#3.行子查询(结果集一行多列或者多行多列)
#案例1.查询员工编号最小并且工资最高的员工信息.引入
SELECT MIN(employee_id)
FROM employees;
=================
SELECT MAX(salary)
FROM employees;
SELECT *
FROM employees
WHERE employee_id = (
SELECT MIN(employee_id)
FROM employees
)
AND salary = (
SELECT MAX(salary)
FROM employees
);
这种查询结果使用虚拟字段,单行操作符必须一致可以使用。查出来与上面同样的效果。
SELECT *
FROM employees
WHERE (employee_id,salary)=(
SELECT MIN(employee_id),
MAX(salary)
FROM employees
);#二.SELECT子查询
#仅仅支持标量子查询,结果是一行一列
#案例1.查询每个部门的员工个数
SELECT d.*,(SELECT COUNT(*) FROM employees)
FROM departments d; 
添加条件
SELECT d.*,(SELECT COUNT(*)
FROM employees e
WHERE e.department_id=d.department_id
) AS 个数
FROM departments d; 
#案例2.查询员工号=102的部门名。
SELECT department_name
FROM departments;
==============
SELECT employee_id
FROM employees
WHERE employee_id = 102;
SELECT employee_id,
(
SELECT department_name
FROM departments d
WHERE e.department_id=d.department_id
)
FROM employees e
WHERE employee_id=102;
#三.FROM 后面
注意:将子查询结果充当一张表,要求必须起别名
#案例:查询每个部门的平均工资等级。
SELECT ROUND(AVG(salary),2),department_id
FROM employees
GROUP BY department_id;
SELECT e.平均工资,j.grade_level
FROM job_grades AS j
,(
SELECT ROUND(AVG(salary),2) AS 平均工资,department_id
FROM employees
GROUP BY department_id
) AS e
WHERE e.平均工资 BETWEEN j.lowest_sal AND j.highest_sal;#1999语法,老师答案
SELECT e.*,j.grade_level
FROM (
SELECT ROUND(AVG(salary),2) AS 平均工资,department_id
FROM employees
GROUP BY department_id
) AS e
INNER JOIN job_grades j
ON e.平均工资 BETWEEN j.lowest_sal AND j.highest_sal;
#四.EXISTS后面(相关子查询)
语法:EXISTS(完整的查询语句)
备注:完整的查询语句可以是一行一列,可以使一行多列
注意:先走外查询,然后根据某个字段的值再去过滤
EXISTS 判断(布尔类型)值存不存在,结果只有两种:1有,0没有
#引入
SELECT EXISTS(SELECT employee_id FROM employees);
查询工资3W的员工信息
SELECT EXISTS(SELECT * FROM employees WHERE salary=30000);
#案例引入.查询员工名和部门名
#查员工名与部门编号
SELECT first_name,department_id
FROM employees
WHERE department_id;
#查部门名
SELECT department_name
FROM departments;
#查员工名与部门名
SELECT e.first_name,d.department_name
FROM employees e
INNER JOIN ( SELECT department_name,department_id
FROM departments
) AS d
ON e.department_id=d.department_id;
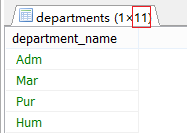
#案例1..查有员工的部门名
SELECT department_name
FROM departments d
WHERE EXISTS(
SELECT *
FROM employees e
WHERE d.department_id=e.department_id
);
使用IN代替EXISTS,同样是上面的结果
SELECT department_name
FROM departments d
WHERE d.department_id IN(
SELECT department_id
FROM employees
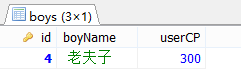
);#案例2.查询没有女朋友的男神信息
#IN方法
SELECT *
FROM boys bo
WHERE bo.id NOT IN(
SELECT boyfriend_id
FROM beauty be
);
===============
#EXISTS方法
SELECT *
FROM boys bo
WHERE NOT EXISTS(
SELECT boyfriend_id
FROM beauty be
WHERE bo.id=be.boyfriend_id
);
进阶9:联合查询
UNION 联合 合并:将多条查询语句的结果合并成一个结果。
语法:
查询语句1
UNION
查询语句2
UNION
...
应用场景:
要查询的结果来自于多个表,且多个表没有直接的连接关系,
但查询信息一致时。
网页搜索内容,内容从不同的表中检索联合起来返回给用户。
特点:
1.要求多条查询语句的查询列数是一致的。
2.要求多条查询语句的查询的每一列的类型和顺序最好一致。
3.使用UNION关键字默认去重,如果使用UNION ALL全部展示,包含重复项#引入案例1.:查询部门编号>90或者邮箱包含A的员工信息
SELECT * FROM employees
WHERE email LIKE "%a%" OR department_id>90;
联合查询
SELECT * FROM employees WHERE email LIKE "%a%"
UNION
SELECT * FROM employees WHERE department_id>90;
感谢能认真读到这里的伙伴们,MySql查询部分结束,相信屏幕前的你照着我博客里的模板可以完成一些简单的SQL查询语句,SQL既然学了,以后还是要多练习一下,SQL1992与1999语法在主流的关系型数据库都是通用的。后续我会继续进行对MySql的知识进行扩展,感兴趣的同志互相关注一呗!o(^▽^)o














