博大数据



大数据运维:大数据平台+海量数据
大数据开发独揽大权大数据技术很早就在BAT这些公司生根发芽,但直到14、15年大数据技术才广泛应用在各大互联网公司,大数据技术由此深入各行各业。 此时大数据开发人才非常紧缺,很多公司大数据从立项,到大数据平台构建,到项目整个流程开发,到后期大数据项目的运维,都

打造数据科学作品集:搭建一个数据科学博
这是「打造数据科学作品集」系列文章的第二篇。如果你喜欢该系列,而且想知道下一篇文章什么时候发布,你可以订阅我们。读完本文,你将学会如何使用 Pelican 静态网站生成器,搭建一个属于自己的博客,用来展示数据科学作品。全文大约 9500 字

python爬取微博图片数据存到Mysq
本人长期出售超大量微博数据、旅游网站评论数据,并提供各种指定数据爬取服务,Message to YuboonaZhang@Yahoo.com。同时欢迎加入社交媒体数据交流群:99918768 由于硬件等各种原因需要把大概170多万2t左右

Python爬虫如何采集微博视频数据
这篇文章主要介绍了Python爬虫如何采集微博视频数据,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。知识点requestspprint开发环境版 本:python 3.8-编

数据之剑与控制之盾:数据库访问控制的博弈
数据库访问控制是数据安全领域的关键部分,它涉及到数据所有者、管理员和用户之间的博弈,既要保证数据安全,又要满足数据访问需求。

python爬虫如何爬取微博粉丝数据
这篇文章主要介绍了python爬虫如何爬取微博粉丝数据,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。python可以做什么Python是一种编程语言,内置了许多有效的工具,P

nodejs个人博客开发第四步 数据模型
本文为大家分享了nodejs个人博客开发的数据模型,具体内容如下 数据库模型 /model/db.js 数据库操作类,完成链接数据库和数据库的增删查改 查询表 select:function(tableName,callback

nodejs个人博客开发第六步 数据分页
本文为大家分享了nodejs个人博客开发的数据分页,具体内容如下 控制器路由定义 首页路由:http://localhost:8888/ 首页分页路由:http://localhost:8888/index/2
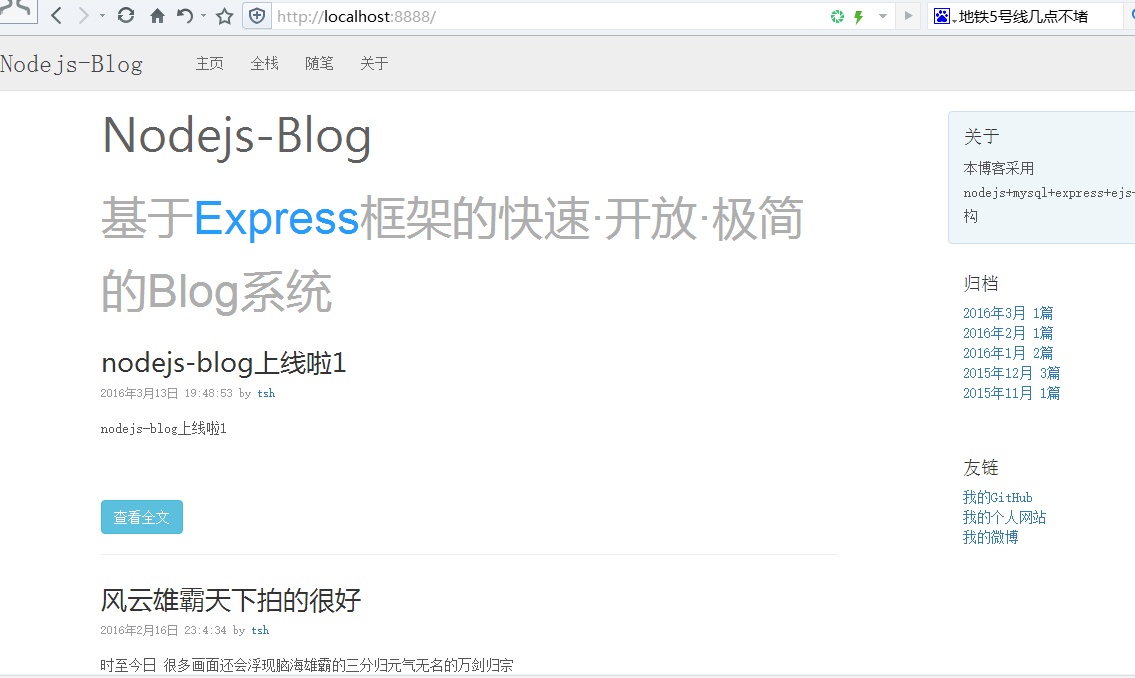
nodejs个人博客开发第五步 分配数据
本文为大家分享了nodejs个人博客开发的分配数据,具体内容如下 使用回掉大坑进行取数据 能看明白的就看,看不明白的手动滑稽 var router=express.Router(); var p


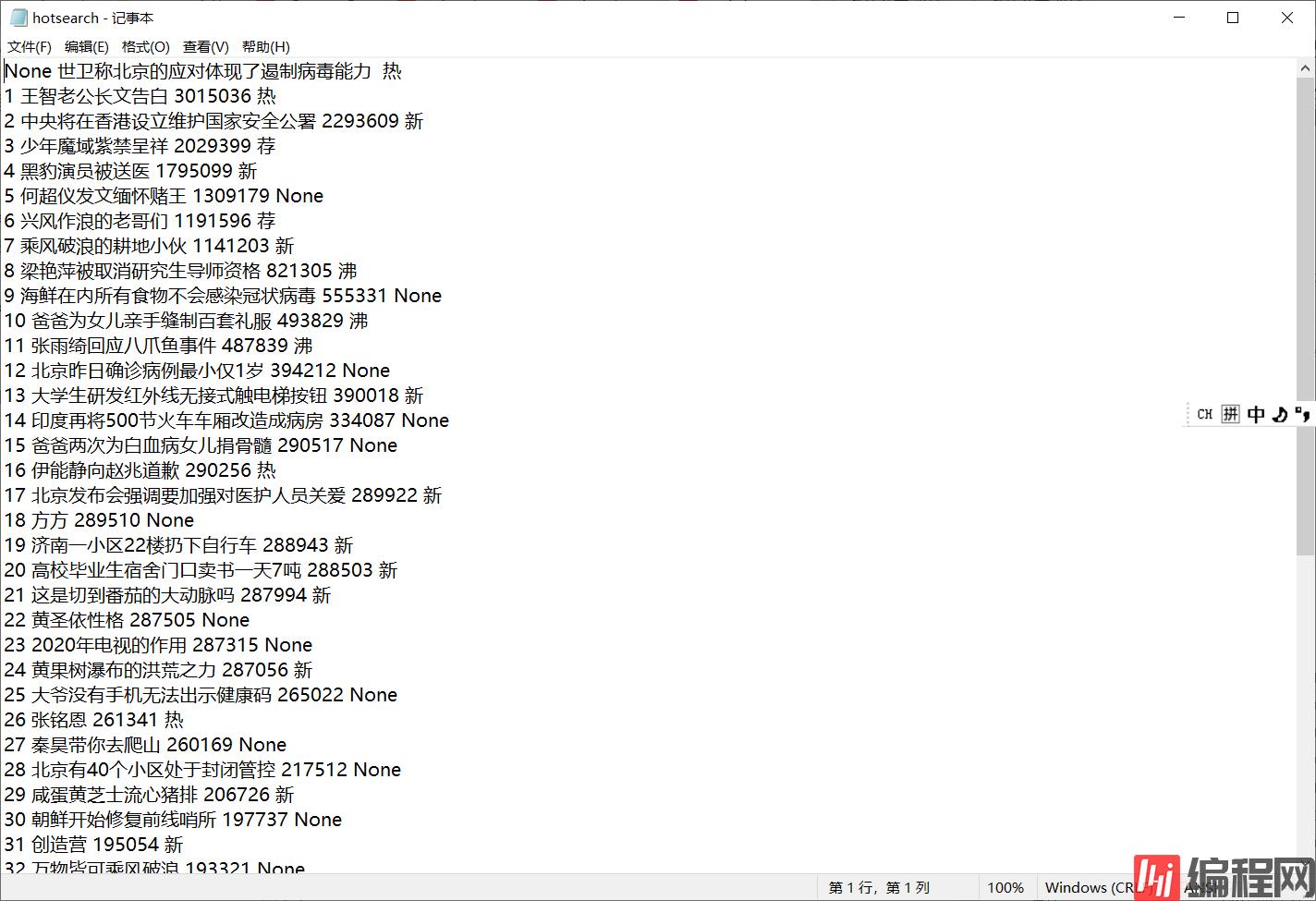
使用python怎么爬取微博的热搜数据
使用python怎么爬取微博的热搜数据?很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。主要用到requests和bf4两个库将获得的信息保存在d://hotsea
大数据Hadoop之——数据仓库Hive
目录一、概述二、Hive优点与使用场景1)优点2)使用场景三、Hive架构1)服务端组件1、Driver组件2、Metastore组件3、Thrift服务2)客户端组件1、CLI2、Thrift客户端3、WEBGUI3)Metastore详解四、Hive的工作

爬取微博图片数据存到Mysql中遇到的
由于硬件等各种原因需要把大概170多万2t左右的微博图片数据存到Mysql中.之前存微博数据一直用的非关系型数据库mongodb,由于对Mysql的各种不熟悉,踩了无数坑,来来回回改了3天才完成。 PS:(本人长期出售超大量微博数据、

大数据时代书中的大数据是什么意思
这篇文章主要为大家展示了“大数据时代书中的大数据是什么意思”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“大数据时代书中的大数据是什么意思”这篇文章吧。“大数据时代”一书中的大数据是指“全体数据或
总结新浪微博和Pinterest以及Viacom对Redis数据库
这篇文章主要介绍“总结新浪微博和Pinterest以及Viacom对Redis数据库”,在日常操作中,相信很多人在总结新浪微博和Pinterest以及Viacom对Redis数据库问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法


Python读大数据txt
如果直接对大文件对象调用 read() 方法,会导致不可预测的内存占用。好的方法是利用固定长度的缓冲区来不断读取文件内容。即通过yield。在用Python读一个两个多G的txt文本时,天真的直接用readlines方法,结果一运行内存就崩





