ETL
python ETL工具 pyetl
pyetl是一个纯python开发的ETL框架, 相比sqoop, datax 之类的ETL工具,pyetl可以对每个字段添加udf函数,使得数据转换过程更加灵活,相比专业ETL工具pyetl更轻量,纯python代码操作,更加符合开发人员习惯安装pip3 i





SQL Server怎么配置cdc进行ETL
这篇文章给大家分享的是有关SQL Server怎么配置cdc进行ETL的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。企业核心业务系统oltp的数据需要通过ETL同步到数据仓库,原始的ETL流程通过定制化从SQL


ETL工具sed进阶是怎么样的
ETL工具sed进阶是怎么样的,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。sed 详解我觉得 sed 玩到最后,应该触及的最高难度的问题,有这些:替换百万行文



ETL数据导入导出工具HData使用
注:近期因朋友的请求协助了解Hdata工具的使用,抽空进行了摸索,特整理此文;该ETL数据交换工具开发者已经有三、四年没有更新维护记录了,不确定该项目是否会继续维护,因此选择该工具应用于项目时,请考虑后续的技术支持与问题处理等所需要的解决方案成本; 1、介绍

利用SSIS进行SharePoint 列表数据的ETL
好几年前写了一篇《SSIS利用Microsoft Connector for Oracle by Attunity组件进行ETL!》,IT技术真是日新月异,这种方式对于新的SQL SERVER 数据库版本已不适用了,比如SQL SERVER 2016 的SSI

Teradata怎么处理数据集成和ETL过程
Teradata提供了一套强大的工具和技术来处理数据集成和ETL过程。以下是一些常见的方法:使用Teradata Parallel Transporter (TPT):TPT是Teradata提供的一种高性能数据传输和转换工具,可以实现快速

用于ETL的Python数据转换工具有哪些
这篇文章主要讲解了“用于ETL的Python数据转换工具有哪些”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“用于ETL的Python数据转换工具有哪些”吧!Pandas网站:https://


如何在Teradata中执行数据迁移和ETL操作
在Teradata中执行数据迁移和ETL操作通常可以通过以下几种方法:使用Teradata的内置工具:Teradata提供了一系列工具,如Teradata Parallel Transporter (TPT)、Teradata Studio


8种ETL算法汇总大全!看完你就全明白了
> 算法应用场景概览 以上共计累积了8种ETL算法,其中主要分成4大类,增量累加、拉链算法是更符合数据仓库历史数据追踪的算法,但现实中基于业务及性能考虑,往往存在全删全插、增量累全算法的数据表应用。 2 全删全插模型 即Delete/Insert实现逻辑;

递归查询在数据仓库ETL过程中的作用
递归查询在数据仓库ETL过程中扮演着关键角色,特别是在处理具有层次结构或递归关系的数据时。以下是递归查询在ETL过程中的作用及一些相关介绍:递归查询在ETL过程中的作用处理层次结构数据:递归查询能够遍历数据仓库中的层次结构数据,如树形结构

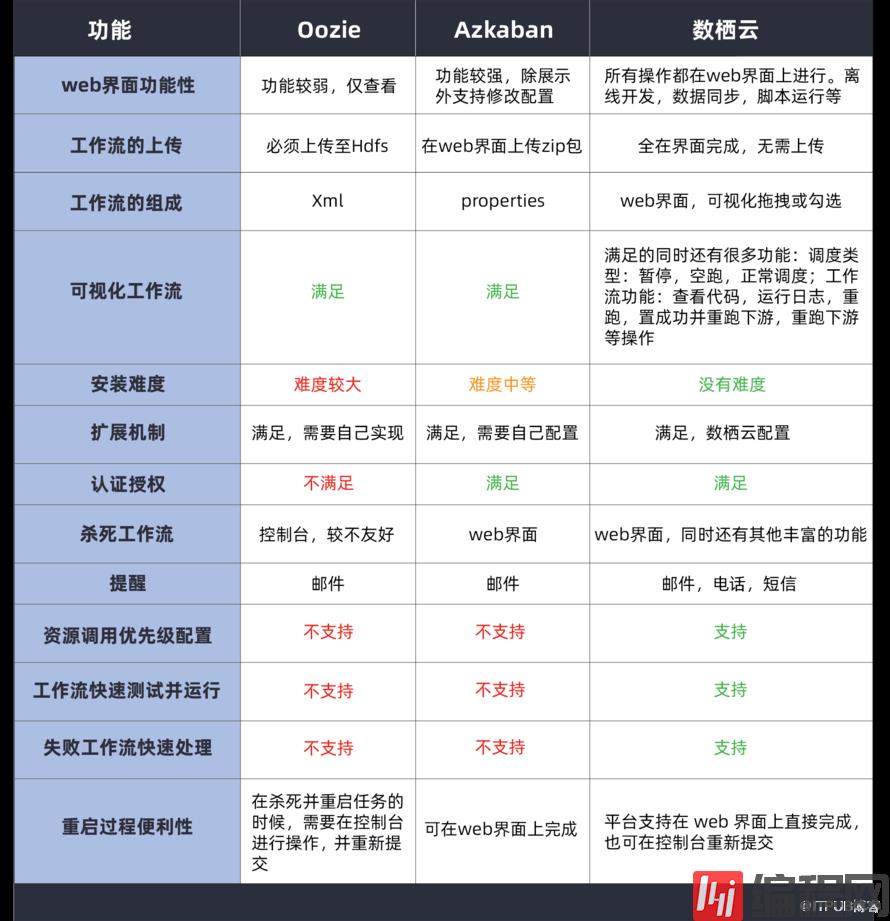
ETL调度系统及常见工具对比:Azkaban、Oozie、数栖云
最近遇到了很多正在研究ETL及其工具的同学向我们抱怨:同样都在用 Kettle ,起点明明没差异,但为什么别人ETL做的那么快那么好,自己却不断掉坑? 其实,类似于像 Kettle 这样开源的工具,已经覆盖了大部分日常工作所需的功能了,直接