PySpark


pyspark修改python版本
ubuntu自带的python 版本是2.7,我们要把pyspark默认改成anaconda python 3.6down votYou can specify the version of Python for the driver by

python实例pyspark以及pyt
%pyspark#查询认证用户import sys#import MySQLdbimport mysql.connectorimport pandas as pdimport datetimeimport timeoptmap = {

Pyspark如何读取parquet数据
这期内容当中小编将会给大家带来有关Pyspark如何读取parquet数据,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量;压缩编码可以降低磁盘存储


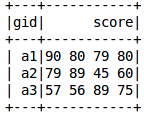
如何在pyspark中创建DataFrame
如何在pyspark中创建DataFrame?很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。pyspark创建DataFrame为了便于操作,使用pyspark时

PySpark和RDD对象最新详解
Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海量数据,PySpark是由Spark官方开发的Python语言第三方库,本文重点介绍PySpark和RDD对象,感兴趣的朋友一起看看吧



PySpark中RDD的数据输出详解
这篇文章主要介绍了PySpark中RDD的数据输出详解,需要的朋友可以参考下

如何在windowns中配置PySpark环境
如何在windowns中配置PySpark环境?相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。首先需要下载hadoop和spark,解压,然后设置环境变量。hadoop清华源下载
Linux下远程连接Jupyter+pyspark部署教程
博主最近试在服务器上进行spark编程,因此,在开始编程作业之前,要先搭建一个便利的编程环境,这样才能做到舒心地开发。本文主要有以下内容: 1、python多版本管理利器-pythonbrew 2、Jupyter notebooks 安装

pyspark dataframe列的合并与拆分实例
这篇文章主要介绍了pyspark dataframe列的合并与拆分实例,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教



pyspark dataframe列的合并与拆分方法是什么
这篇文章主要介绍了pyspark dataframe列的合并与拆分方法是什么的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇pyspark dataframe列的合并与拆分方法是什么文章都会有所收获,下面我们一起