爬虫库
爬虫笔记1:Python爬虫常用库
请求库:1、urllib:urllib库是Python3自带的库(Python2有urllib和urllib2,到了Python3统一为urllib),这个库是爬虫里最简单的库。2、requests:requests属于第三方库,使用起来比


python爬虫库有哪些
Python爬虫库有以下几个:1、Beautiful Soup一个Python的HTML/XML解析库,可以轻松地从网页中提取数据。2、Scrapy一个高效的Python爬虫框架,可以快速地构建和部署爬虫程序。3、Requests一个Pyt

有哪些python爬虫库
本篇文章给大家分享的是有关有哪些python爬虫库,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。python的数据类型有哪些?python的数据类型:1. 数字类型,包括int

【Python3爬虫】拉勾网爬虫
一、思路分析:在之前写拉勾网的爬虫的时候,总是得到下面这个结果(真是头疼),当你看到下面这个结果的时候,也就意味着被反爬了,因为一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,如果访问频率太快以至于看起来不像正

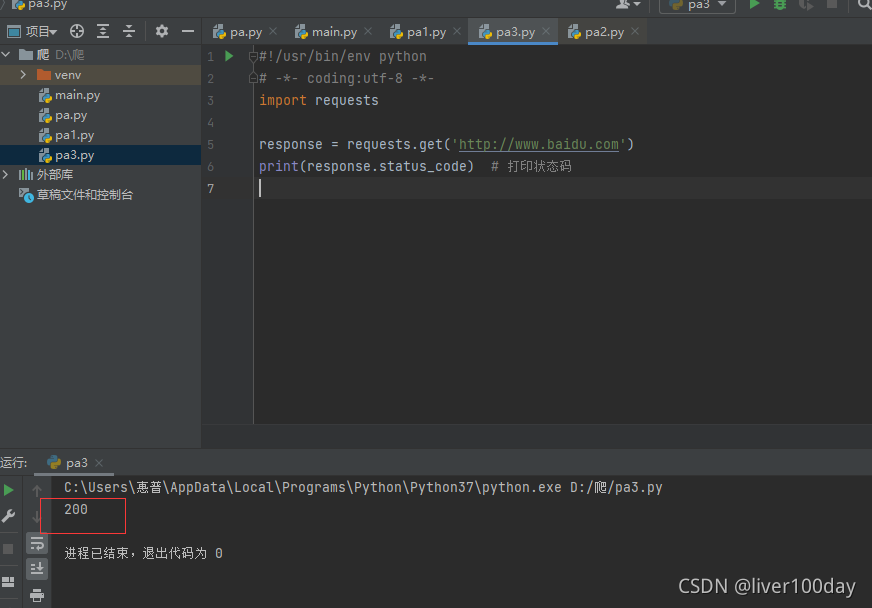
Python爬虫之Requests库的基
1 import requests 2 response = requests.get('http://www.baidu.com/') 3 print(type(response)) 4 print(response.status_

Python爬虫之必备chardet库
一、chardet库的安装与介绍 玩儿过爬虫的朋友应该知道,在爬取不同的网页时,返回结果会出现乱码的情况。比如,在爬取某个中文网页的时候,有的页面使用GBK/GB2312,有的使用UTF8,如果你需要去爬一些页面,知道网页编码很重要的。 虽


Python 爬虫库RoboBrowser怎么用
这篇文章主要介绍“Python 爬虫库RoboBrowser怎么用”,在日常操作中,相信很多人在Python 爬虫库RoboBrowser怎么用问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Python 爬虫

python爬虫怎么使用BeautifulSoup库
本篇内容介绍了“python爬虫怎么使用BeautifulSoup库”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成! BeautiSoup类

Python爬虫中urllib库怎么用
这篇文章给大家分享的是有关Python爬虫中urllib库怎么用的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。一、说明:urllib库是python内置的一个http请求库,requests库就是基于该库开发出来

Python爬虫Requests库如何使用
本篇内容主要讲解“Python爬虫Requests库如何使用”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Python爬虫Requests库如何使用”吧!1、安装 requests 库因为学习过

爬虫学习之第四章爬虫进阶之多线程爬虫
有些时候,比如下载图片,因为下载图片是一个耗时的操作。如果采用之前那种同步的方式下载。那效率肯会特别慢。这时候我们就可以考虑使用多线程的方式来下载图片。多线程介绍:多线程是为了同步完成多项任务,通过提高资源使用效率来提高系统的效率。线程是在

python爬虫中requests库怎么用
小编给大家分享一下python爬虫中requests库怎么用,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!python爬虫—requests库的用法request
Python爬虫教程-01-爬虫介绍
Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求参考资料精通Python爬虫框架Scrapy,人民邮电出版社url, httpweb前端,html,css,jsajaxre,xp







